

「AIと会話していて、前に話したことを覚えていないことにストレスを感じませんか?」
「同じ質問を繰り返したり、前の答えを踏まえていない応答にがっかりしたことはありませんか?」
その原因は、AIが会話履歴を“記憶”として保持できない仕組みにあります。そこで登場するのが RAG(Retrieval-Augmented Generation)。過去の会話をEmbeddingモデルでベクトル化し、検索して取り出すことで、あたかも記憶を継承しているような自然な対話が実現できるのです。
この記事では、このRAG環境での「Embeddingモデルによるベクトル化」の仕組みを詳しく解説していきます。
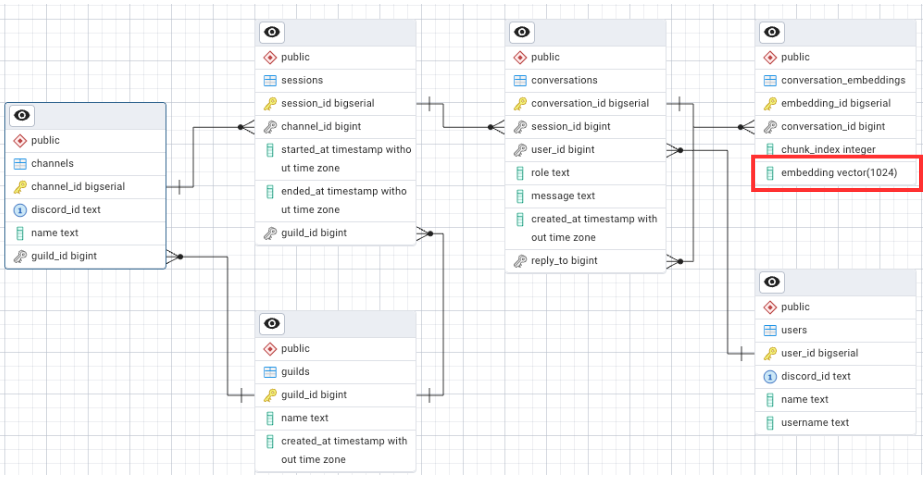
個人ローカルAI環境
🔴 個人ローカルAI環境
📌 LMStudioとpgvectorで実現するパーソナルRAG環境
└─Mac miniをAIサーバーに!LMStudioとpgvectorで作る個人ローカルAI環境
├─PostgreSQL16+pgvector導入手順|個人環境にベクトルDBを構築する方法
├─Embeddingでテキストをベクトル化|pgvectorに保存して検索可能にする手順
├─Discord Botで作るRAG環境|pgvectorとLMStudioを活用した会話システム実装
├─LMStudioをAPIサーバーとして利用|Embedding・GPTモデルを呼び出す仕組みを構築
├─RAG環境の検索精度を高める!プロンプト設計と改善テクニック
├─探しても友達は増えない。ならAIで作っちまえ!Mac miniで個人ローカルAI環境を構築
└─個人ローカルAI環境を持ち歩く|iPad miniからDiscord経由で相談する新しいワークスタイル
Embeddingモデルの基本
AIに会話の文脈を記憶させたいと考えるとき、重要になるのが「Embeddingモデル」です。Embeddingはテキストを数値ベクトルに変換し、その結果を使って文章同士の類似性を計算できるようにする技術です。これにより、単なる文字一致ではなく「意味的に近い」内容を見つけられるようになります。RAG環境では、Embeddingモデルが会話検索の基盤となっています。

Embeddingの役割
Embeddingの役割は「テキストを意味的に理解できる形に変換する」ことです。人間の言葉は曖昧さを持ちますが、Embeddingではこれを数値化することで客観的に扱えるようにします。
具体的には以下のような特徴があります。
・テキストを固定次元(例:1024次元)の数値ベクトルに変換する
・意味が似ている文章はベクトル空間上で近い位置に配置される
・ベクトル間の距離を計算することで、文章同士の関連度を定量的に判断できる
例えば「データベースのバックアップ」と「PostgreSQLの保存方法」という二つの文章を考えると、文字列一致では別物と扱われます。しかしEmbeddingを通すと、両者は「保存・バックアップ」に関わる意味合いを持つため、近い位置にマッピングされます。この仕組みこそが会話検索の要です。
「個人ローカルAI環境」で使用している埋め込みモデルは 「mxbai-embed-large-v1 」で、これは Hugging Face から無償でダウンロード可能です。こうした公開モデルが存在するおかげで、個人環境でも高度な検索機能を持ったRAGを実現できるようになっています。
今回は、マシンスペックの制約によりベクトルの次元数を 1024次元 に設定しています。本来であればより高精度なモデルを利用し、1536次元やそれ以上の次元数を持つEmbeddingを使う方が望ましいとされています。次元数が多いほど表現できる情報量が増え、文章の意味をより細かく捉えられるため、検索精度も高くなります。
Hugging Face(ハギングフェイス)は、世界中の研究者や開発者が機械学習モデルを公開・共有できるAIのプラットフォーム兼コミュニティです。特に自然言語処理(NLP)の分野で有名で、翻訳・要約・文章生成・画像処理など、多種多様なAIモデルが登録されています。いわば「AIモデルのGitHub」のような存在です。
ベクトル化の仕組み
ベクトル化の仕組みは、モデルにテキストを入力し、内部で学習された言語表現をもとに多次元ベクトルを出力するという流れです。これをデータベースに保存し、類似度検索に利用します。
処理の流れは以下の通りです。
処理の流れ
- 入力テキストをチャンクに分割(1チャンク=300〜500文字程度、重複部分あり)
- 各チャンクをEmbeddingモデルに入力し、ベクトルを生成
- 得られたベクトルをpgvector拡張を導入したPostgreSQLに保存
- 新しい入力が来たら同じ処理でベクトル化し、過去のベクトル群と比較
- 距離が近いものを「意味的に類似している」として検索結果に利用
実際にEmbeddingを取得するコード例は以下です。
def get_embedding(text: str):
url = "http://127.0.0.1:8081/v1/embeddings"
payload = {"model": "mxbai-embed-large-v1-f16", "input": text}
res = requests.post(url, json=payload)
return res.json()["data"][0]["embedding"]
得られるのは1024次元の浮動小数ベクトルです。これをpgvectorに保存すると、類似度演算子 <-> を使って効率的に検索できます。
例えば以下のようにクエリを書けば、意味的に近い過去の会話を抽出できます。
SELECT c.conversation_id, c.message,
1 - (e.embedding <-> %s::vector) AS score FROM conversation_embeddings e JOIN conversations c
ON c.conversation_id = e.conversation_id WHERE c.session_id = %s
AND c.role = 'user' ORDER BY e.embedding <-> %s::vector LIMIT 10;
このようにベクトル化は単なる補助ではなく、RAG環境における「AIに記憶を持たせる」ための根幹技術といえます。
RAG環境と会話検索
AIと会話をしていると「さっきの話を忘れてしまったのか」と思うことがあるはずです。人間なら昨日の会話や一時間前のやりとりをある程度覚えていますが、AIは残念ながらそうはいきません。AIには「記憶」という仕組みがないため、入力されたテキストを処理して答えるだけになってしまうのです。
ではどうすればAIに記憶を持たせられるのでしょうか。その解決策の一つが「RAG環境」です。RAGは過去の会話や知識を保存しておき、必要なときに検索して利用できる仕組みです。AIは自分で覚えているわけではありませんが、検索によってまるで記憶を引き継いでいるように振る舞うことができます。
ここからはRAGの概要と、会話検索においてEmbeddingモデルとベクトルがどのように使われるのかを理解できるように具体例を交えながら説明していきます。
RAGの概要
RAGは「Retrieval-Augmented Generation」の略で、日本語にすると「検索で補強した文章生成」といえます。AIが答えを作る前に、まず関連する情報をデータベースから検索し、それを材料として応答を生成するのです。
イメージしやすい例えをすると、友達から「この前一緒に見た映画のタイトルって何だっけ?」と聞かれたとき、あなたは完全に覚えていないかもしれません。しかしスマホで検索履歴をたどればすぐに思い出せますよね。AIも同じで、自分の頭に記憶がなくても、検索という「外部のメモ帳」を使って答えを導き出すのです。
このように、RAGはAIに疑似的な記憶を与える仕組みといえます。AI自身が覚えるわけではありませんが、必要なときに情報を引き出して利用することで、人間と同じように会話をつなげていけるのです。
会話検索におけるベクトル利用
では、RAG環境でどのように会話を検索するのでしょうか。ここで登場するのが「Embeddingモデル」と「ベクトル検索」です。
Embeddingモデルは、文章を数値の集合(ベクトル)に変換する仕組みです。単語や文章の意味を数字で表すので、似ている内容はベクトル空間の中で近い位置に並びます。つまり、計算で「この文章とあの文章は意味が近い」と判断できるのです。
ここで文字列検索とベクトル検索の違いを例で比べてみましょう。
| 検索方法 | 仕組み | 例え |
|---|---|---|
| 文字列検索 | 同じ単語や文章を探す | 国語辞典で「バックアップ」を調べても「保存」では出てこない |
| ベクトル検索 | 意味を数値化して近さを調べる | 図書館で「保存」に関する本を探すと「バックアップ」の棚も紹介される |
文字列検索は「同じ言葉」を見つけることに強いですが、言葉が違うと検索できません。一方でベクトル検索は「意味が似ているもの」を探せるため、表現が違っても関連性を見つけ出せます。
例えば「データベースの保存方法」と「PostgreSQLのバックアップ」という文章を考えてみましょう。文字列検索では一致しませんが、ベクトル検索なら「保存」と「バックアップ」が近い意味だと理解し、関連する会話として見つけ出せます。これが会話検索におけるEmbeddingの強みです。
つまり、「保存」と「バックアップ」という二つの言葉を比べたとき、AIはそれぞれを数値に変換して「どれくらい似ているか」を計算します。その結果が例えば85%であれば「この二つはかなり近い意味だ」と判断します。逆に20%しか似ていないなら「意味はほとんど違う」と考えるのです。
この“似ている確率”の数字が高ければ高いほど、AIは二つの言葉を同じような意味として扱えるようになります。
実際には、AIがユーザーからの新しい質問を受け取ると、まずその質問をEmbeddingモデルに通してベクトルを作ります。次に、過去に保存しておいた会話ベクトルと比較して、意味的に近いものを検索します。そして検索された結果をAIの入力に組み込み、応答を生成します。
この流れをもう少し分かりやすく例えると、学校の授業で先生が黒板にまとめた内容をノートに写すとします。後で似たような問題を解くとき、ノートを見返してヒントを探しますよね。AIにとってのノートがベクトルであり、必要なときにそこから関連する部分を取り出して活用しているのです。
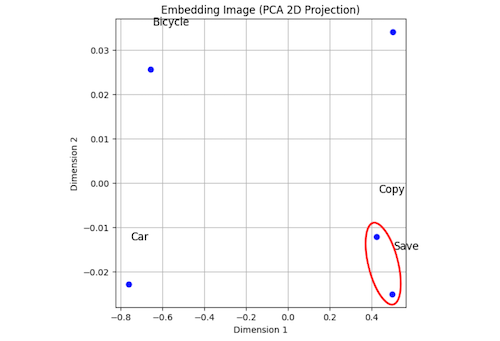
このグラフは、文章や単語をEmbeddingモデルで数値(ベクトル)に変換し、それを2次元に縮小して配置したイメージです。ここでのポイントは「意味が近い言葉ほど近くに、違う意味の言葉は離れた場所に置かれる」という点です。
例えば Save・Copy は、コンピュータ上でのデータの扱いに関連した言葉なので、図の中でも近くにまとまって表示されています。一方で Car・Bicycle は乗り物を表す単語なので、SaveやBackupとは全く異なる意味を持ち、遠くに配置されています。
この「近い・遠い」という配置が、Embeddingベクトルが持つ本質です。つまり、単語や文章を数値に変換すると、その数値は「どれくらい意味が似ているか」を表す位置情報のような役割を果たします。AIはこの位置関係を利用して「関連する会話を思い出す」ことができるのです。
実装の流れ
AIに「記憶を持たせる」ためには、単に会話を保存するだけでは不十分です。文章をそのまま丸ごと保存しても検索が難しく、似た内容を探し出すことはできません。そこで必要になるのが三つの流れです。
実装の流れ
- 文章を小さな単位に分けること、
- 数値に変換して保存すること、
- そして新しい入力と比較して似ているものを探すこと
この三つが組み合わさることで、AIはあたかも過去の会話を覚えているかのように応答できるようになります。
テキストのチャンク分割
最最初のステップは「チャンク分割」です。チャンクとは、文章を小さなかたまりに区切った単位のことを指します。文章を丸ごと保存すると長すぎて検索が難しくなるため、扱いやすい長さに分けて保存します。
例えば500文字の文章をそのまま保存するのではなく、300文字ごとに区切り、次のかたまりは前の最後の50文字を重ねて保存します。こうしておけば、文の途中で意味が切れてしまっても、重なり部分のおかげで前後のつながりを失わずに残せます。
イメージすると、高校の教科書に付箋を貼る場面に似ています。章ごとに1枚だけ付箋を貼ると範囲が広すぎて探しにくいですが、段落ごとに小さな付箋を貼れば、後から必要なところをすぐに開けます。AIにとってのチャンク分割も、文章を段落ごとに付箋をつけて整理するような工夫だと考えるとわかりやすいでしょう。
ベクトル生成と保存
AIにとって「Embeddingモデル」は、とても大事な仕組みです。これは文章を数字に変える翻訳機のようなもので、言葉の意味を数値に置き換えることができます。こうすることでAIは「言葉そのもの」ではなく「意味の近さ」を計算できるようになります。
例えば「保存」と「バックアップ」という言葉を比べると、AIはこの二つを数字に変えて「85%くらい似ている」と判断するかもしれません。逆に「保存」と「車」では20%しか似ていないと出るので、「意味はほとんど違う」と理解します。つまりEmbeddingモデルは、言葉の意味を数字に変えて、どれくらい似ているかを測る道具なのです。
世の中ではGPTのような推論モデルばかり注目されています。推論モデルは答えを作る役割を担っていますが、実はRAGを動かすうえで本当に欠かせないのはEmbeddingモデルです。AIが「どの記録を参考にすればよいか」を探し出すためには、Embeddingによる数値化がなければ成り立ちません。言い換えると、推論モデルが「話す力」だとすれば、Embeddingモデルは「思い出す力」です。
さらに大切なポイントは、このEmbeddingモデルの多くが巨大な研究機関から無償で公開されていることです。高性能な推論モデルは有料のものが多いのに対して、埋め込みモデルは無料で利用できる選択肢が数多くあります。だからこそ、個人や学校の勉強環境でもRAGを実現できるのです。
作成されたベクトルはPostgreSQLに保存され、pgvector拡張を使って意味の近さで検索できるようになります。つまり、EmbeddingモデルはAIにとっての「記憶のノート」を作る役割を担い、RAGの核心部分を支えているのです。
この「記憶のノート」が世の中のすべてを数値化しているわけではありません。Embeddingモデルは入力された文章や会話をその場で数値に変換し、保存しているだけです。人間でいうと、頭の中に百科事典を丸ごと覚えているのではなく、自分で習ったことや調べたことをノートにまとめているのと同じです。つまりAIのノートには「与えられた情報」しか残っておらず、勝手に世界中の知識を保存しているわけではありません。
実装例:個人AIローカル環境の場合
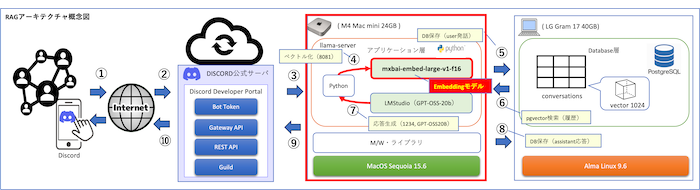
ここでは実際に構築した個人RAG環境でのEmbedding利用方法を紹介します。
| 番号 | 処理内容 | 詳細 |
|---|---|---|
| ① | Discordユーザー発話 | ユーザーがDiscordクライアントから発話 |
| ② | インターネット経由 | 発話がDiscord公式サーバに送信される |
| ③ | Discord公式サーバ → Bot | Bot(Mac mini上)へ発話が転送される |
| ④ | ベクトル化 | 8081埋め込みサーバ(llama-server, mxbai-embed-large-v1)で発話をベクトル化 |
| ⑤ | DB保存(user発話) | conversationsテーブルにユーザー発話を保存 |
| ⑥ | pgvector検索 | 類似度検索で関連する履歴会話を取得 |
| ⑦ | 応答生成 | 8080 GPT-OSS-20B(LMStudio API)で応答を生成 |
| ⑧ | DB保存(assistant応答) | conversationsテーブルにAIの応答を保存 |
| ⑨ | Bot → Discord公式サーバ | 応答がBotからDiscord公式サーバに送信 |
| ⑩ | ユーザー応答受信 | ユーザーがDiscordクライアントで応答を確認 |
うちの環境では、Mac mini 上で LMStudio を起動し、埋め込み専用サーバーとして mxbai-embed-large-v1 モデルをポート8081で動かしています。ユーザーの会話はチャンク分割された後、このモデルに送られてベクトルに変換されます。生成されたベクトルは LG Gram 上の PostgreSQL 16 に保存され、pgvector拡張を利用して意味の近さで検索できるようになっています。
要約すると下記の流れになります。
Embedding利用方法「④⑤⑥」
- Mac mini上でLMStudioを起動し、埋め込み専用サーバー(Port 8081)として mxbai-embed-large-v1 を利用「④」
- 会話はチャンク分割後にEmbeddingサーバーに送信され、数値化されたベクトルを生成
- 生成されたベクトルはLG GramのPostgreSQL+pgvectorに保存 「⑤」
- 検索時にはこのベクトルを利用して「意味の近い会話」を取り出し、Discord Botの応答に反映「⑥」
つまり「文章をベクトルに変換 → データベースに保存 → 類似検索で取り出し」という流れを通して、AIは記憶を引き継いでいるように応答できるのです。これが、うちのRAG環境でEmbeddingモデルが果たしている具体的な役割です。
この仕組みによって、AIは無限の記憶を持つ存在ではなく、ユーザーが与えた情報を効率よく整理して“思い出せるようにする”存在だと理解できます。
類似度検索の仕組み
最後のステップは「類似度検索」です。新しい質問が来たときに、その質問も同じように数値に変換し、過去に保存したベクトルと比較します。このとき距離が近いものほど「意味が似ている」と判断されます。
イメージすると、これは地図アプリで「現在地に近いコンビニを探す」ようなものです。位置が近いほど候補に挙がります。同じようにAIは「今の質問」と「過去の会話」を地図上の点のように扱い、近いものを探し出します。
例えばユーザーが「データベースを安全に残す方法を知りたい」と質問したとします。過去に「PostgreSQLのバックアップ方法」という会話が保存されていれば、AIは両者が近い内容だと判断し、その会話を検索結果として取り出します。これを参考にすることで、AIは一貫した応答を返せるのです。
この仕組みによって、AIは単発で答えるだけでなく「過去に似た話を思い出して答える」ような振る舞いが可能になります。言い換えると、AIが本当の意味で記憶を持っているわけではなくても、過去の会話をうまく活用することで“記憶しているように見える”のです。
今後の展開
ここまでRAG環境の仕組みと実装の流れを説明してきましたが、実際に使っていくといくつかの課題や改善点が見えてきます。AIに「記憶を持たせる」仕組みは完成形ではなく、今後さらに精度や利便性を高めていく必要があります。ここでは代表的な課題と、利用シーンとして注目度が高いDiscord Botとの連携について説明します。
検索精度向上の課題
現在のEmbeddingモデルとpgvectorを用いた検索は、十分に意味の近さを扱えるようになっています。しかし実際の会話では、似ている内容が複数見つかり、どれを優先するかが難しい場面もあります。例えば「バックアップ」と「保存」は近い意味を持ちますが、「コピー」とも似ているため、どこまでを正解として扱うかは状況によって変わります。
また、長い文章をチャンクに分割した場合、それぞれの区切り方次第で検索結果が変わってしまう課題もあります。小さく分けすぎれば文脈を失い、大きくしすぎれば検索が粗くなるため、適切な分割方法を試行錯誤する必要があります。
さらに検索精度を上げるためには、ユーザーが直前に入力した会話や過去のやり取りを「どの程度重視するか」を調整する工夫も必要です。今後はEmbeddingモデルの改良や、検索結果をフィルタリングするアルゴリズムの工夫が大きな課題となります。
Discord Botとの連携
RAG環境を利用する場面として、特に注目されるのがDiscord Botとの連携です。Discordはコミュニティの会話が常に流れる環境であり、過去の発言を覚えているかのように応答できるAIが実現できれば、ユーザー体験が大きく向上します。
しかし、Discord上ではコードや表の表示に制限があるため、そのまま出力すると見づらくなることがあります。そのため、テーブルをリスト形式に変換したり、長い応答を分割して表示するなどの工夫が必要です。
また、Botが複数のチャンネルに参加している場合、会話の履歴をチャンネルごとに管理する必要があります。これは「どのチャンネルの文脈を参照するか」を区別する仕組みが必須になるということです。
今後は、Discordに最適化した出力形式の工夫や、会話の文脈をより自然に引き継げるアルゴリズムの改善が求められます。こうした課題を解決していくことで、より実用的な「記憶を持つAI Bot」として活用の幅が広がっていくでしょう。




