

PostgreSQLにpgvectorを導入すると、ローカル環境でもベクトル検索が可能になります。
これはRAG(Retrieval Augmented Generation)における「記憶保存」の基盤となり、AIに会話の履歴を保持させるための必須要素です。
この記事では、RHEL系LinuxにPostgreSQL16とpgvectorを導入し、Macからも接続できる個人向けの分散構成を構築する手順を解説します。
個人ローカルAI環境
🔴 個人ローカルAI環境
📌 LMStudioとpgvectorで実現するパーソナルRAG環境
└─Mac miniをAIサーバーに!LMStudioとpgvectorで作る個人ローカルAI環境
├─PostgreSQL16+pgvector導入手順|個人環境にベクトルDBを構築する方法
├─Embeddingでテキストをベクトル化|pgvectorに保存して検索可能にする手順
├─Discord Botで作るRAG環境|pgvectorとLMStudioを活用した会話システム実装
├─LMStudioをAPIサーバーとして利用|Embedding・GPTモデルを呼び出す仕組みを構築
├─RAG環境の検索精度を高める!プロンプト設計と改善テクニック
├─探しても友達は増えない。ならAIで作っちまえ!Mac miniで個人ローカルAI環境を構築
└─個人ローカルAI環境を持ち歩く|iPad miniからDiscord経由で相談する新しいワークスタイル
なぜpgvectorが必要なのか
pgvectorはPostgreSQLにベクトル型を導入する拡張機能で、RAG(Retrieval Augmented Generation)において「記憶」を担う役割を果たします。通常のテキスト保存では検索に限界がありますが、ベクトル化した情報を保存することで、意味的な類似性を利用した検索が可能になります。
RAGにおける記憶保存の仕組み
RAGでは、AIが過去の会話や知識を検索して回答に活用する仕組みが重要です。このとき従来の全文検索では正確な文脈を拾いにくいため、テキストを数値ベクトルに変換して保存する必要があります。ベクトル検索によって、文中の単語一致ではなく「意味的に近い情報」を呼び出せるようになります。
ベクトルDBが果たす役割
ベクトルDBは、AIにとっての「長期記憶」を支える基盤です。pgvectorを導入することでPostgreSQL自体がベクトルDBとして機能し、RAGに必要な類似度検索が実現できます。これにより、個人環境でも大規模サービスと同じ仕組みを利用でき、AIの会話に一貫性と継続性を持たせることが可能になります。
PostgreSQLの導入
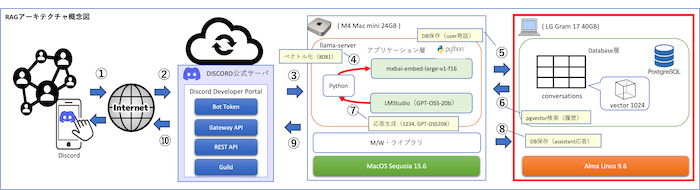
RAG環境の基盤としてベクトルDBを利用するためには、まずPostgreSQLを導入する必要があります。ここではRHEL系LinuxにおけるPostgreSQL16のインストール手順と初期化・起動方法について解説します。
RHEL系Linuxでのインストール手順
RHEL系Linuxでは標準リポジトリに含まれるPostgreSQLは古いバージョンであることが多いため、PGDGリポジトリを追加して最新のPostgreSQL16を導入します。
sudo dnf -y install https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm
sudo dnf -qy module disable postgresql
sudo dnf -y install postgresql16 postgresql16-server postgresql16-devel
PostgreSQL16の初期化と起動
インストールが完了したら、データベースクラスタの初期化を行い、サービスを起動します。起動後は自動的に常駐するように有効化しておきます。
sudo /usr/pgsql-16/bin/postgresql-16-setup initdb
sudo systemctl enable --now postgresql-16
この手順を実行することで、PostgreSQL16がシステムに常駐し、RAG環境のベースとなるデータベースが稼働する状態になります。
私の場合は、かつてメインPCとして使用していたLG Gram 2019にAlmaLinux 9.6を導入し、現在は部屋の片隅でデータベースサーバーとして活用しています。インストールには、当ブログで以前紹介した「【RHEL系Linux】PostgreSQLを自動インストールするシェルスクリプトの使い方」を利用してPostgreSQL16をセットアップしました。

pgvectorの導入

PostgreSQLをベクトルDBとして利用するためには、拡張モジュールであるpgvectorを導入する必要があります。
通常であれば、PostgreSQLの開発パッケージ(devel)を導入し、そこに含まれる「pg_config」を使ってpgvectorをビルドします。しかし、私の環境のAlmaLinux 9.6(RHEL系)では postgresql16-develがリポジトリに存在しない(まだRPMで提供されていない)ため、そのままでは pg_configを利用できませんでした。
このため、RPMで導入したPostgreSQLサーバーとは別に、開発ツールとしてのpg_configを得る目的でソースからPostgreSQLをビルドする必要がありました。
ここを誤解すると「PostgreSQLを二重にインストールするのか?」と混乱してしまいますが、実際にはDBサーバーとしてはRPM版を使い、pgvectorのビルドにはソースから得た pg_config を使う、という役割分担になります。
ソースビルドによるインストール手順
まずは、pgvectorやPostgreSQLソースのビルドに必要となるコンパイラやライブラリを導入します。これを行わないと configure や makeが途中で失敗するため、必ず最初に準備してください。
sudo dnf -y install git make gcc cmake llvm llvm-devel readline readline-devel
次に、PostgreSQL16のソースコードを公式サイトから取得し展開します。この工程の目的は「PostgreSQLサーバーをもう一度インストールすること」ではなく、「pg_configを生成して利用すること」です。
wget https://ftp.postgresql.org/pub/source/v16.4/postgresql-16.4.tar.gz
tar xvf postgresql-16.4.tar.gz
cd postgresql-16.4
展開したソースから、開発用のツール群を生成するためにビルドを行います。ここで指定する --prefix はインストール先ディレクトリで、RPM版PostgreSQLとは別の場所に入れることで共存できます。
./configure --prefix=/usr/pgsql-16
make
sudo make install
この作業を行うことで、/usr/pgsql-16/bin/pg_config が生成されます。この pg_config が後続のpgvectorビルドで必要な情報を提供します。サーバー本体の起動や利用はこれまで通りRPM版PostgreSQLを使うため、あくまで「pg_configのためのビルド」と理解してください。
続いて、pgvectorのソースコードをGitHubから取得します。これは拡張モジュール本体です。
sudo git clone https://github.com/pgvector/pgvector.git /usr/local/src/pgvector
cd /usr/local/src/pgvector
ここで、先ほどソースからビルドした pg_config を指定してpgvectorをコンパイルします。この指定がないと、システムに存在しないpg_configを探して失敗するため、必ずパスを明示する必要があります。
make PG_CONFIG=/usr/pgsql-16/bin/pg_config
ビルドが成功したら、インストールを実行し、PostgreSQLに拡張を組み込みます。
sudo make PG_CONFIG=/usr/pgsql-16/bin/pg_config install
これでpgvectorの導入が完了し、PostgreSQL環境がベクトル型を扱える状態になります。
CREATE EXTENSIONでの有効化
pgvectorを導入しただけでは利用できません。PostgreSQLにログインし、拡張を有効化する必要があります。
sudo -u postgres psql -d postgres -c "CREATE EXTENSION IF NOT EXISTS vector;"
さらに、導入が成功しているか確認するために、インストール済み拡張の一覧を表示します。ここで「vector」が出力されれば導入完了です。
sudo -u postgres psql -d postgres -c "\dx"
[ 出力例 ]
List of installed extensions
Name | Version | Schema | Description
----------+---------+------------+---------------------------------------------------
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
vector | 0.7.0 | public | Open-source vector similarity search for Postgres
(2 rows)
以上で、RPM版のPostgreSQLサーバーとソースビルドで得たpg_configを組み合わせてpgvectorを導入する手順が完了します。これでAlmaLinux環境でもPostgreSQLをベクトルDBとして利用できる基盤が整います。

テーブル設計の基本
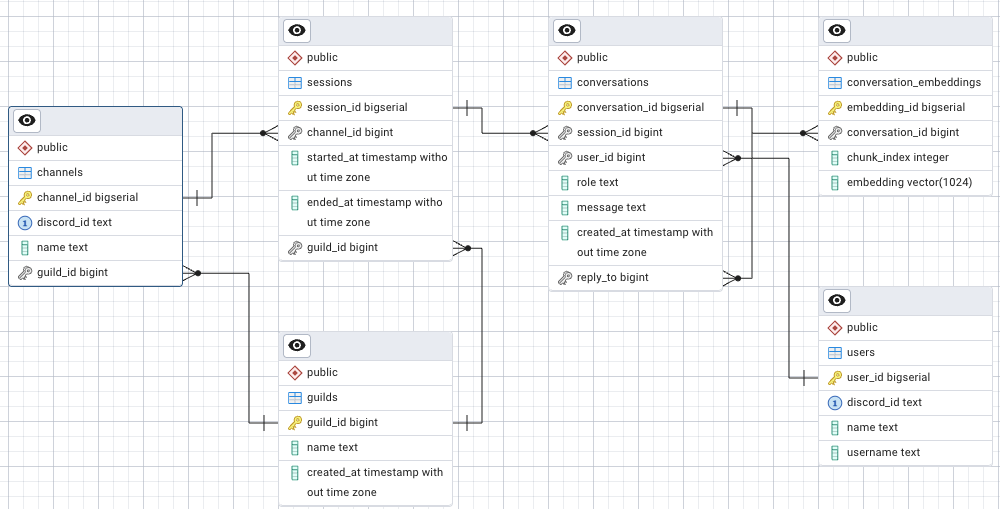
pgvectorを活用して会話を保存するには、単にベクトル型カラムを持つテーブルを作るだけではなく、ユーザーやチャンネルの情報、会話のセッション単位などを整理する必要があります。ここでは、RAG環境で実際に利用するすべての主要テーブルについて役割と定義例を示します。
conversationsテーブルの役割
conversationsテーブルは、ユーザーとAIがやり取りした発言を記録するテーブルです。誰がどのセッションでどんなメッセージを送信したのか、さらにどの発言への返信なのかを管理します。会話の流れを残す中心的な役割を持ちます。
CREATE TABLE conversations ( conversation_id bigserial PRIMARY KEY, session_id bigint NOT NULL, user_id bigint NOT NULL, role text NOT NULL, message text NOT NULL, reply_to bigint, created_at timestamp DEFAULT now() );
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| conversation_id | bigserial | PRIMARY KEY | 会話を識別する内部ID |
| session_id | bigint | NOT NULL | 紐付くセッションID |
| user_id | bigint | NOT NULL | 発言したユーザーID |
| role | text | NOT NULL | 発言の役割(user/assistantなど) |
| message | text | NOT NULL | 会話本文 |
| reply_to | bigint | NULL | 返信元の会話ID |
| created_at | timestamp | DEFAULT now() | 発言日時 |
conversation_embeddingsテーブルの役割
conversation_embeddingsテーブルは、会話のテキストをベクトル化した結果を保持します。テキスト全文を埋め込んだベクトルは高次元になるため、長文は分割(チャンク化)して保存する仕組みにします。1024次元を前提とした設計になっており、類似検索の基盤となります。
CREATE TABLE conversation_embeddings ( embedding_id bigserial PRIMARY KEY, conversation_id bigint NOT NULL REFERENCES conversations(conversation_id), chunk_index int NOT NULL, embedding vector(1024) NOT NULL );
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| embedding_id | bigserial | PRIMARY KEY | ベクトルを識別する内部ID |
| conversation_id | bigint | REFERENCES conversations(conversation_id) | 紐付く会話ID |
| chunk_index | int | NOT NULL | チャンク番号(長文を分割した順序) |
| embedding | vector(1024) | NOT NULL | 埋め込みベクトル(1024次元) |
usersテーブルの役割
usersテーブルは、会話を行うユーザーの情報を管理します。Discord環境であればユーザーIDやユーザー名を保持し、どの発言が誰によるものかを追跡可能にします。
CREATE TABLE users ( user_id bigserial PRIMARY KEY, discord_id text UNIQUE NOT NULL, username text NOT NULL, created_at timestamp DEFAULT now() );
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| user_id | bigserial | PRIMARY KEY | ユーザーを識別する内部ID |
| discord_id | text | UNIQUE NOT NULL | DiscordユーザーID |
| username | text | NOT NULL | ユーザー名(表示名) |
| created_at | timestamp | DEFAULT now() | 登録日時 |
guildsテーブルの役割
guildsテーブルは、Discordのサーバー(ギルド)の情報を管理します。複数のサーバーでBotを稼働させる場合、それぞれを識別して会話を紐付けることができます。
CREATE TABLE guilds ( guild_id text PRIMARY KEY, name text NOT NULL, created_at timestamp DEFAULT now() );
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| guild_id | text | PRIMARY KEY | DiscordギルドID |
| name | text | NOT NULL | サーバー名 |
| created_at | timestamp | DEFAULT now() | 登録日時 |
channelsテーブルの役割
channelsテーブルは、Discordのチャンネルを管理します。同じギルド内でも複数のチャンネルが存在するため、発言を正しく分類するために必要です。
CREATE TABLE channels ( channel_id bigserial PRIMARY KEY, guild_id text NOT NULL REFERENCES guilds(guild_id), discord_id text NOT NULL, name text NOT NULL, created_at timestamp DEFAULT now() );
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| channel_id | bigserial | PRIMARY KEY | 内部的なチャンネルID |
| guild_id | text | REFERENCES guilds(guild_id) | 紐付くギルドID |
| discord_id | text | NOT NULL | DiscordチャンネルID |
| name | text | NOT NULL | チャンネル名 |
| created_at | timestamp | DEFAULT now() | 登録日時 |
sessionsテーブルの役割
sessionsテーブルは、一連の会話を「セッション」としてまとめるために使います。これにより、過去の会話を単位ごとに検索したり、コンテキストを切り替えて利用することができます。
CREATE TABLE sessions ( session_id bigserial PRIMARY KEY, channel_id bigint NOT NULL REFERENCES channels(channel_id), guild_id text NOT NULL REFERENCES guilds(guild_id), started_at timestamp DEFAULT now() );
| カラム名 | データ型 | 制約 | 説明 |
|---|---|---|---|
| session_id | bigserial | PRIMARY KEY | セッションを識別する内部ID |
| channel_id | bigint | REFERENCES channels(channel_id) | 紐付くチャンネルID |
| guild_id | text | REFERENCES guilds(guild_id) | 紐付くギルドID |
| started_at | timestamp | DEFAULT now() | セッション開始時刻 |
テーブル間の関係
上記テーブルは階層的な関係を持ちます。
- 1人のユーザーは複数の会話に参加できます。
- 1つのギルドには複数のチャンネルが存在します。
- 1つのチャンネルには複数のセッションが存在します。
- 1つのセッションには複数の会話が含まれます。
- 1つの会話は複数のベクトルチャンクに分割され、conversation_embeddingsに保存されます。
このように設計することで、実際の利用環境(Discordなど)の構造を反映しながら、効率的に会話とベクトルを管理できる仕組みが整います。
動作確認
pgvectorを導入した後は、実際にベクトル型のカラムが正しく動作するか確認する必要があります。ここではサンプルデータを挿入し、類似度検索を行うことで、導入が成功していることを確認します。
サンプルINSERTの例
まずは簡単なテーブルを作成し、サンプルのベクトルデータを挿入します。ここでは3次元のベクトルを利用した例を示します。
sudo -u postgres psql -d vecdb
DROP TABLE IF EXISTS items;
CREATE TABLE items (id bigserial PRIMARY KEY, emb vector(3), note text);
次にサンプルデータを挿入します。ベクトルは配列のような形で文字列として指定します。
INSERT INTO items (emb, note) VALUES ('[0.1,0.2,0.3]', 'short vec 1'), ('[0.1,0.25,0.35]', 'short vec 2'), ('[0.9,0.8,0.7]', 'short vec 3');
この操作により、テーブルに3件のベクトルデータが保存されます。
類似度検索の実行例
続いて、あるベクトルと最も近いベクトルを検索します。pgvectorでは <-> 演算子を利用して距離(類似度)を計算します。
SELECT id, note, emb <-> '[0.09,0.21,0.31]'::vector AS dist FROM items ORDER BY dist LIMIT 3;
このクエリを実行すると、指定したベクトル [0.09,0.21,0.31] に対して最も近いデータが距離順に出力されます。出力例は以下のようになります。
| id | note | dist |
|---|---|---|
| 1 | short vec 1 | 0.017 |
| 2 | short vec 2 | 0.058 |
| 3 | short vec 3 | 1.183 |
このように距離が小さいほど意味的に近いベクトルであることを示します。ここまで確認できれば、pgvectorが正常に導入され、ベクトル検索が利用可能になっていることが分かります。
Macからのリモート接続
LG Gram側でPostgreSQLとpgvectorを導入しただけでは、外部のMacから接続できません。デフォルトではlocalhostからのアクセスしか受け付けないため、設定を変更してLAN経由で接続できるようにします。ここでは設定ファイルの修正とファイアウォールの開放、そしてMac側からの接続手順を解説します。
postgresql.conf / pg_hba.conf の設定
まずはPostgreSQLの設定ファイルを編集し、外部からの接続を許可します。
sudo vi /var/lib/pgsql/16/data/postgresql.conf
このファイル内の listen_addresses を修正します。初期状態では localhost のみになっているため、すべてのアドレスからの接続を受け付けるように変更します。
変更前:
#listen_addresses = 'localhost'
変更後:
listen_addresses = '*'
次に、クライアント認証の設定ファイル pg_hba.conf を編集します。ここではMacのIPアドレスを許可する設定を追加します。
sudo vi /var/lib/pgsql/16/data/pg_hba.conf
例として、192.168.11.0/24 のサブネット全体からのアクセスを許可する場合は次のように追記します。
host vecdb postgres 192.168.11.0/24 md5
必要に応じて /32 を指定し、Macの固定IPアドレスのみを許可する設定にしても構いません。
firewall設定
PostgreSQLが待ち受けるポート5432をファイアウォールで許可します。これを行わないとLAN経由で接続要求が届きません。
sudo firewall-cmd --add-port=5432/tcp --permanent
sudo firewall-cmd --reload
その後、設定を反映させるためにPostgreSQLを再起動します。
sudo systemctl restart postgresql-16
Mac側からのpsql接続方法
次にMac側から接続を行います。psqlコマンドが未導入の場合はHomebrewで libpq をインストールします。
brew install libpq
brew link --force libpq
インストールが完了したら、以下のように接続します。
psql -h 192.168.11.3 -p 5432 -U postgres -d vecdb
ここで 192.168.11.3 はLG GramのIPアドレスに置き換えてください。初回接続時には postgres ユーザーのパスワード入力が求められます。
これでMacから直接PostgreSQL+pgvector環境にアクセスできるようになり、分散構成でRAGを利用する準備が整います。
ハマりポイントと注意事項
PostgreSQLとpgvectorを導入する際には、公式のマニュアル通りに進めても環境によってはうまくいかないことがあります。
特にRHEL系LinuxではRPMパッケージが不足していたり、設定を忘れることで接続ができないといった問題が発生します。ここでは実際に導入する際に注意すべきポイントを整理します。
RHEL系はRPMがなくソースビルド必須
RHEL系Linuxでは、pgvectorをビルドするために必要な開発用パッケージ(postgresqlXX-devel)がリポジトリに存在しないことがあります。
この場合、公式手順に従っても「pg_configが見つからない」というエラーで止まってしまいます。そのため、PostgreSQLのソースコードを取得して一度ビルドし、 pg_config を生成してからpgvectorをビルドする必要があります。
これはサーバー本体を入れ直すためではなく、ビルドに必要な開発ツールを揃えるための工程である点に注意してください。
ベクトル次元数が増えると負荷が高まる
pgvectorでは、埋め込みモデルが出力するベクトルの次元数をテーブル作成時に固定する必要があります。ここで大きな次元数を設定すると、保存データのサイズが大きくなるだけでなく、検索時の計算負荷も増大します。
| 次元数 | 特徴 | 注意点 |
|---|---|---|
| 768 | 軽量で高速 | 一部の小型モデル向け |
| 1024 | バランスが良い | 一般的な利用に適する |
| 1536 | 高精度 | メモリ消費・検索速度に注意 |
使用する埋め込みモデルの仕様に合わせて、必要以上に大きな次元数を設定しないようにしてください。
listen_addressesやpg_hba.conf設定漏れによる接続失敗
PostgreSQLはデフォルトではローカル接続しか受け付けません。そのため、設定を変更せずにMacなど外部環境から接続しようとすると必ず失敗します。
postgresql.conf で listen_addresses を正しく設定しているか、pg_hba.conf に接続元のIPアドレスが許可されているかを確認してください。
# postgresql.conf の例 listen_addresses = '*'
# pg_hba.conf の例 host vecdb postgres 192.168.11.0/24 md5
これらの設定を忘れると、どれだけ接続先の情報を正しく指定してもエラーになります。ファイアウォールの設定とあわせて必ず確認するようにしてください。
まとめ
ここまでの手順で、PostgreSQL16とpgvectorを導入し、Macからも接続できる環境を構築しました。これにより、個人環境におけるRAGの「記憶保存基盤」が整ったことになります。導入時の注意点や設定ファイルの修正も含めて理解しておけば、同じ手順を再現することが可能です。
記憶保存基盤の完成
PostgreSQLにpgvectorを追加したことで、テキストを数値ベクトルとして保存し、意味的な検索を行える基盤ができあがりました。さらに、テーブル設計によってユーザーやセッションごとの会話を管理できるようになり、AIが過去の履歴を活用できる「記憶の仕組み」が完成しました。これにより、単なる一問一答ではなく、会話を蓄積して再利用できる環境が実現しています。
次ステップ(Embeddingモデル導入)への接続
ベクトルDBの準備が整った次のステップは、実際にテキストをベクトルに変換するEmbeddingモデルの導入です。Embeddingモデルを利用することで、ユーザーの入力をベクトル化してpgvectorに保存し、類似度検索を通じて適切な過去の会話や知識を呼び出せるようになります。これがRAG環境の本格的なスタート地点となります。
このように、PostgreSQLとpgvectorを用いた環境構築は記憶保存の第一歩であり、次回以降はEmbeddingモデルを組み合わせることで、実際にAIが会話の文脈を理解し続ける仕組みを実装していきます。




