

ローカルAI環境って聞くと、「個人では無理だろ!」と思いませんか?
「転移学習に何億パラメーターが…」
「ファインチューニングには膨大なデータが…」
聞いただけで気が遠くなりそうですよね。私も最初はそう思っていました。
ところが、MetaのトランスフォーマーやOpenAIのGPT-OSS関連資料を読み漁ってみると、「その面倒な作業はすでに済ませてあるから、すぐに使えるよ」と書かれている部分が目に入りました。
それなら少し試してみようか──そう思って、腰を上げてみたのが今回の始まりです。
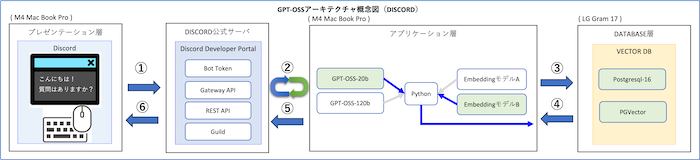
個人ローカルAI環境
🔴 個人ローカルAI環境
📌 LMStudioとpgvectorで実現するパーソナルRAG環境
└─Mac miniをAIサーバーに!LMStudioとpgvectorで作る個人ローカルAI環境
├─PostgreSQL16+pgvector導入手順|個人環境にベクトルDBを構築する方法
├─Embeddingでテキストをベクトル化|pgvectorに保存して検索可能にする手順
├─Discord Botで作るRAG環境|pgvectorとLMStudioを活用した会話システム実装
├─LMStudioをAPIサーバーとして利用|Embedding・GPTモデルを呼び出す仕組みを構築
├─RAG環境の検索精度を高める!プロンプト設計と改善テクニック
├─探しても友達は増えない。ならAIで作っちまえ!Mac miniで個人ローカルAI環境を構築
└─個人ローカルAI環境を持ち歩く|iPad miniからDiscord経由で相談する新しいワークスタイル
私が目指すのは、AIの「記憶継承問題」を克服することです。
会話の中で「1年前のあの件を覚えてる?」と聞けるような、文脈を引き継ぐAI。これは従来のデータベースではほぼ不可能に近い領域ですが、新しく登場したベクトルDBなら突破口が見えるかもしれない。
そうして調べるうちに、PostgreSQLの拡張として「pgvector」が無料で提供されていることを知りました。
ただし、ベクトルDBは1カラムで1000次元以上のデータを扱うため、件数が増えると処理能力をかなり食うことが分かりました。つまり、個人でローカルAIを動かすにも「サーバー分散」の考え方が必要になるのです。
ちょうど使わなくなった2019年モデルのLG Gram(メモリ40GB増設済み)が手元に眠っていたので、これをベクトルDB用サーバーにあてることにしました。
一方で、肝心の推論サーバーはどうするか。
試しにM4 MacBook ProでLMStudioを動かしてみたところ、20GB以上メモリを消費して他作業に支障をきたすことが判明。24時間365日稼働させたい私の目的には合いませんでした。
そこで調べていると、OpenAIからGPT-OSS-20bという「低スペックPCでも動作可能なバージョン」が公開されたのです。必要メモリは16GB程度とのことで、これなら個人でも手が届く。
さらに探すと、Mac miniが最小構成で10万円を切る価格帯で販売されていることを思い出しました。Appleシリコンのユニファイドメモリなら、RAMとVRAMを効率的に共有できます。「24GBにすれば推論サーバーとして十分いけるのでは?」と考え、Mac miniを導入してみることにしました。
無理だと思っていたローカルAI
AI技術の進化により、以前は大企業やクラウドサービスでしか実現できなかった高度な会話AIシステムを、個人のパソコンでも構築できるようになりました。
PostgreSQL、pgvector、LMStudio、Discordボットを組み合わせることで、クラウドサービスに依存せず、すべてのデータを手元で管理できる個人RAG環境を実現できます。
このアプローチの最大の魅力は、コストゼロで運用できる点と、プライバシーを完全に確保できる点です。
RAGとは?
この記事で実現するRAG(検索拡張生成)とは、AIに「記憶」を持たせるための仕組みです。
通常のAIは学習済み知識だけで答えますが、RAGでは質問内容をベクトル化し、過去の会話や手元の知識ベースから検索して取り込みます。
例えば「去年のあの件を覚えてる?」と問いかけても、過去のログを検索・参照できるため、会話の継続性を保てます。
ローカルで動かす意義
あげればまだまだ沢山上がると思いますが、とりあえずはこんなところでしょうか・・
ローカルで動かす意義
- クラウド依存を避け、完全オフラインでも稼働可能
- プライバシーを保持できる(会話ログや社内データを外部に送らない)
- 利用コストがゼロ(API課金不要、電気代のみ)
- モデルや処理の制御権限が自分にある(バージョン固定、改造・チューニング自由)
- 学習データや会話履歴を自分のDBに蓄積できる
- クラウド版の「スレッド切替で記憶が途切れる」仕様を回避し、独自の記憶管理(pgvector)を実装できる
- ネットワーク制約がある環境(閉域網・研究所・工場内LAN)でも運用可能
- 外部サービス停止や規約変更のリスクを回避できる
- APIリクエスト制限やレート制限を気にせず、自由に実験やテストが可能
- Discord Botや既存システムと柔軟に統合できる
最も強く感じたのは、サブスクリプションから解放されることで得られる精神的な安堵感です。
クラウドのChatGPTを使っていると「月額を払っているからもっと使わなければ」「利用量が増えると課金が跳ね上がるのでは」という意識が常につきまといます。
ところがローカル環境なら、初期投資こそ必要ですが、その後は利用すればするほど「追加料金の心配がない」という安心感に変わります。
これは単なるコスト削減ではなく、精神衛生の面で圧倒的に楽になり、実験や長時間利用に対する心理的ハードルがほぼ消えました。
また、個人的な悩みの相談がひっそりとできる点も🙆
全体像(システム構成)

この構成では、Mac miniがAI処理の中心となり、LMStudio、llama-server、Discordボットを実行します。一方、Linux搭載のLG Gramはデータベースとして機能し、PostgreSQL16とpgvectorを実行します。
ユーザーはDiscordクライアントを通じてシステムと会話します。
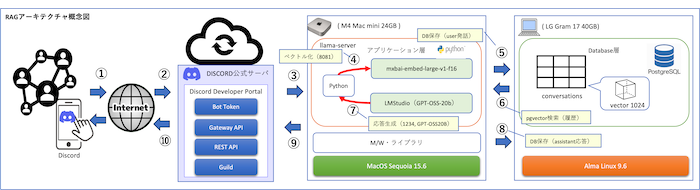
データの流れは上図のとおりで、ユーザーの発話はすべてデータベースに保存され、過去の会話履歴と合わせて文脈を形成します。これにより、会話の連続性を保ちながら、関連性の高い応答を生成できます。
| 番号 | 処理内容 | 詳細 |
|---|---|---|
| ① | Discordユーザー発話 | ユーザーがDiscordクライアントから発話 |
| ② | インターネット経由 | 発話がDiscord公式サーバに送信される |
| ③ | Discord公式サーバ → Bot | Bot(Mac mini上)へ発話が転送される |
| ④ | ベクトル化 | 8081埋め込みサーバ(llama-server, mxbai-embed-large-v1)で発話をベクトル化 |
| ⑤ | DB保存(user発話) | conversationsテーブルにユーザー発話を保存 |
| ⑥ | pgvector検索 | 類似度検索で関連する履歴会話を取得 |
| ⑦ | 応答生成 | 8080 GPT-OSS-20B(LMStudio API)で応答を生成 |
| ⑧ | DB保存(assistant応答) | conversationsテーブルにAIの応答を保存 |
| ⑨ | Bot → Discord公式サーバ | 応答がBotからDiscord公式サーバに送信 |
| ⑩ | ユーザー応答受信 | ユーザーがDiscordクライアントで応答を確認 |
必要環境

本来であれば構成を単純化するために1台のサーバーマシンに集約したかったのですが、それでは推論サーバーの処理速度(Token/sec)が低下してしまい本末転倒になります。
さらに、ベクトル数が1024とはいえ、会話データが蓄積してくればデータベース側の処理負荷も無視できません。
そこで今回は、推論サーバーとデータベースサーバーを分散させる構成を採用しました。
ソフトウエア要件
ソフトウェア要件は、推論サーバーとデータベースサーバーを動かすための最小構成です。検証環境を前提に、できるだけ汎用的で入手しやすいライブラリとツールを選定しました。
ソフトウェア要件
- Python 3.10以上
- Discord.py ライブラリ
- psycopg2(PostgreSQL接続用)
- requests(API通信用)
なぜDiscordをUIに選んだのか
ローカルAIのUIとしてWebアプリや専用クライアントも考えましたが、最終的にDiscordを採用しました。理由は以下のとおりです。
・誰でも使い慣れているチャットUIで、学習コストがほぼゼロ
・クライアントとサーバーのやり取りをDiscordの仕組みに任せられるため、閉域網で安全に運用できる
・スマートフォンや外部PCからもアクセスできるため、実用的な環境として成立する
・外部公開のエンドポイントや固定IPが不要で、セキュリティやネットワーク設定の負担を減らせる
これらの条件を満たせるUIは意外と限られており、結果的に「ローカルAIの入り口」としてDiscordが最適でした。
ハードウェア推奨スペック
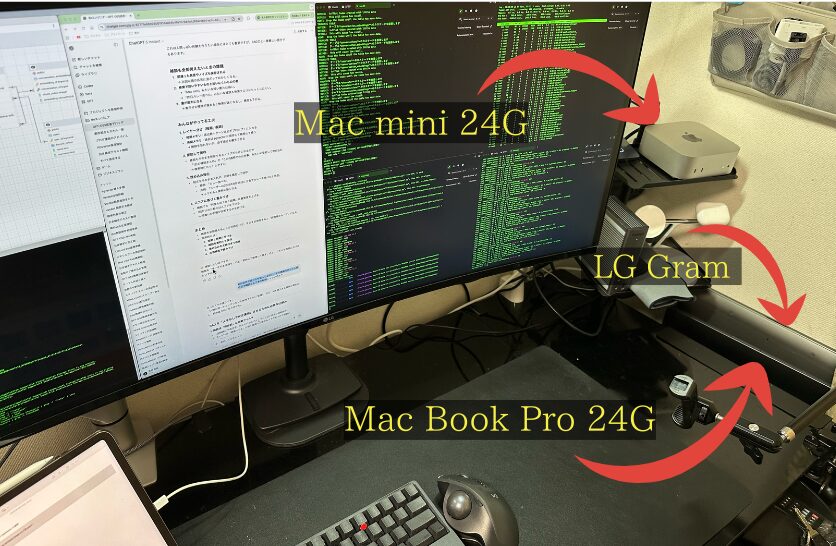
本来であれば推論サーバーやデータベースサーバーには専用機を用意し、十分なスペックを確保するのが望ましいです。しかし今回はあくまで検証環境として構築するため、身近にある機器を組み合わせて運用しています。
なぜ推論サーバーのハードにMac miniを選択したのか?
当初はローカルAIによる推論サーバーを構築するにあたり、検証用の環境があれば十分だと考えていました。しかし実際に問題となるのは、マシンの価格とスペック、そして消費電力です。
かつて私は3Dゲーム用に高性能GPUを搭載したマシンを約100万円かけて購入した経験がありますが、その代償は大きなものでした。毎月の電気料金が2〜3万円と跳ね上がり、さらにファンの騒音は常に耳障りで、まるでサーバールームで暮らしているかのような状況にストレスを感じていました。
一方で、Appleシリコンのユニファイドメモリは以前から注目していたものの、実際にMacBook Pro 24GBモデルでLMStudioを試すまでは性能に大きな期待はしていませんでした。ところが実際に動かしてみると、その処理速度と効率の高さに驚かされました。
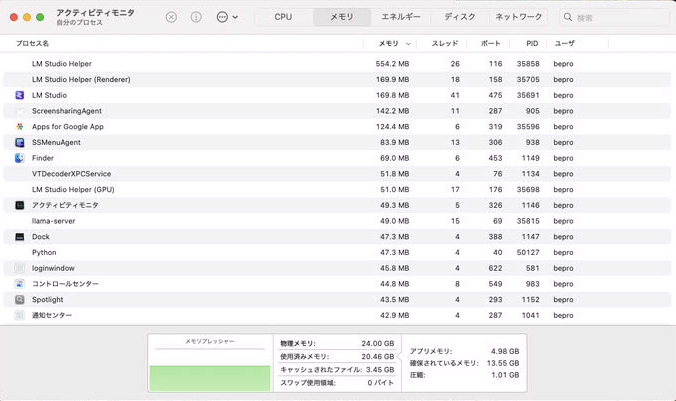
最新のMac mini M4には、デスクトップクラスの性能をコンパクトな筐体に収めるべく設計されたM4チップが搭載されています。このチップはCPU、GPU、AI処理能力のすべてにおいて飛躍的な進化を遂げており、特にAppleシリコン最大の特徴であるユニファイドメモリアーキテクチャの強化が際立ちます。
これにより大規模なデータセットを扱うAIや機械学習タスクにおけるボトルネックが解消され、処理速度が劇的に向上します。さらに、M4チップには大幅に進化したNeural Engineが搭載されており、ローカル環境でも高度なAI機能を高速に実行できるようになっています。
もちろん、MaxTokenの設定を極端に上げると応答までの時間が少し長くなることはありますが、それを差し引いても非常に快適に動作します。むしろ「このままMac mini 24GBを推論サーバーとして使い続けてもいいのでは」と思わせるほど、Mac miniの性能は強力かつ実用的です。
Mac mini 24Gの気になる消費電力
Mac miniを導入するときに多くの方が気にするのが「電気代はどのくらいかかるのか」という点です。昔の自作PC、とくにGeForceのような高性能GPUを搭載したマシンは、アイドル状態でも数百ワットを消費し、月額の電気代が数万円規模になることも珍しくありません。実際、私自身もかつての自作PCで月25,000円近く電気代を支払っていた経験があります。
それに比べて、Mac mini(M4・24GBモデル)の消費電力は驚くほど低いです。実測値やレビューを総合すると、アイドル時はわずか 3〜6W、通常利用で 5〜10W 程度に収まり、高負荷時でも 40〜50W程度(仕様上は最大65W) にとどまります。これは一般的な自作PCやGPUマシンと比べて桁違いに効率が良い数字です。
では、この消費電力を金額に換算するとどのくらいになるのでしょうか。電気料金を1kWhあたり31円と仮定して、1日24時間・30日稼働させた場合の試算は以下の通りです。
| 状態 | 消費電力(W) | 月の電気代(円) |
|---|---|---|
| アイドル(3〜6W) | 5W前後 | 約110円 |
| 通常利用(5〜10W) | 8W前後 | 約180円 |
| 高負荷(40〜50W) | 45W前後 | 約1,000円 |
このように、ほぼアイドル稼働なら月100円程度、開発作業や一般利用でも200円前後、RAG環境を常時動かすような高負荷でもせいぜい1,000円程度に収まります。かつてのGeForce搭載PCのように月25,000円かかる世界とはまったく異なる次元です。
つまりMac mini 24Gは「常時稼働させても電気代をほとんど気にしなくてよい」マシンであり、電力コスト面でも安心して使えるのが大きな魅力と言えます。
なぜデータベースサーバーのマシンにLG Gramを選択したのか?
データベースサーバー用にLG Gramを選んだ理由はとてもシンプルです。もともとメインPCとして使っていたマシンが部屋の片隅で余っていたこと、そしてメモリを増設していたためベクトルDBを動かすには十分な性能を備えていたからです。
LG Gramは軽量ノートPCというイメージが強いですが、当時のカスタマイズで40GB近いメモリを搭載しており、データベースサーバーとして利用するには十分な環境でした。高負荷な推論処理はMac miniに任せ、LG Gramはデータを保存し検索を担う「記憶の倉庫」として動作させています。
新しいマシンをわざわざ購入することなく、手元にある機材を有効活用できる点も大きなメリットでした。結果として、推論はMac mini、記憶はLG Gramという役割分担が実現し、コストをかけずに個人RAG環境を構築することができました。
推論サーバー(Mac mini)
- モデル:Mac mini (M4)
- メモリ:24GB以上(ユニファイドメモリ)
- CPU:8コア以上推奨
- ストレージ:SSD 512GB以上推奨
- GPU:Apple Silicon内蔵GPUを利用(追加GPU不要)
- 役割:LMStudioでの推論、llama-server、Discord Bot
データベースサーバー(LG Gram)
- モデル:LG Gram 2019年モデル
- メモリ:40GB増設済み
- CPU:Intel Core i7 第8世代相当
- ストレージ:SSD 512GB以上推奨
- OS:Linux(例:AlmaLinux / Ubuntu)
- 役割:PostgreSQL16 + pgvectorで会話ログとベクトルデータを管理
実装のポイント

このRAGシステムは、主に以下の2つのPythonモジュールで構成されています。
bot.py
Discordとの連携を担当するモジュールです。
以下の機能を実装します:
bot.py
- ユーザー発話の受信とデータベースへの保存
- 関連する過去の会話の検索(類似検索)
- LMStudio APIを使った応答生成
- 生成された応答のDiscordへの送信
db_utils.py
データベース操作を担当するモジュールです。
以下の機能を実装します:
db_utils.py
- ユーザー、チャンネル、セッション管理
- pgvectorを使った高速ベクトル検索
- 会話履歴のCRUD操作
実装のカギ:効率的なコンテキスト管理
RAGシステムの性能を左右するのは、適切なコンテキスト管理です。現在の会話だけでなく、過去の関連する会話を検索して提供することで、AIの応答品質が大幅に向上します。
pgvectorを使った類似検索により、ユーザーの質問に関連する過去の会話を素早く見つけ出し、コンテキストとして活用します。
QAペア再利用の仕組み
過去の質問と回答のペアをベクトル化して保存することで、類似の質問が来たときに過去の回答を参考にできます。これにより応答の一貫性と質が向上します。
ハマりポイント

実際に構築してみると、理論どおりには進まず思わぬ課題がいくつか出てきました。ここでは、検証環境で特にハマりやすかったポイントと、その原因や対応策を整理しておきます。
Discord表示の制限
DiscordはテーブルやHTML形式の表示に対応していないため、AIからの複雑な出力を適切に変換する必要があります。
表形式のデータは箇条書きに変換するか、コードブロックとして表示するのがおすすめです。
表示問題の対応
AIの出力を前処理するフィルターを実装し、表形式やリッチテキスト形式の出力を、Discordで表示可能な形式に自動変換します。
Markdownの箇条書きや引用形式を活用しましょう。
応答速度の問題
LMStudioを経由すると、クラウドサービスと比較して応答が若干遅くなります。
現在のバージョンではストリーミング応答に未対応のため、完全な回答が生成されるまで待つ必要があります。
応答速度の改善
小規模なモデルを使用するか、「考え中…」のようなフィードバックを表示して、ユーザー体験を向上させます。
将来的にはストリーミング対応版のAPIが登場する可能性もあります。
文脈の維持
AIモデルが過去の会話を無視して応答することがあります。これはプロンプトエンジニアリングで改善可能です。
重要な情報は明示的に指示することで、文脈の維持率が向上します。
プロンプト最適化
過去の会話から重要な情報を抽出し、プロンプトの先頭に配置することで、AIが文脈を理解しやすくなります。
システムプロンプトでの明示的な指示も効果的です。
記憶を正確に拾えないことがある
実験で何度も「このシステムの推論サーバーはMac mini 24GB上で動いている」と登録しました。ところが、後から「推論サーバーは何で稼働してたっけ?」と聞いても、検索にヒットせず答えられないケースがありました。
現象
- 同じ情報を繰り返し保存しているのに、類似検索で引っかからない
- Embedding が短文(「Mac mini」など)だとクエリとの距離が離れやすく、検索から漏れる
- 結果として「覚えてない」ように見える
原因の考察
まだ原因解決に至っていません。今後の課題として要継続対応です。
- 短文埋め込みの弱さ
- クエリと保存文の表現の違いによる距離のズレ
誤回答が記憶されると次の回答がおかしくなる
一度、GPT-OSS 側が誤った応答を返したとき(例:環境を「PostgreSQL 15」と答えてしまった)、その誤回答も DB に保存されました。
すると次の質問以降、その誤回答が類似検索でヒットし、正しい応答ができなくなる現象が発生しました。
現象
- 誤回答が保存されると、それが強力に「記憶」として残る
- 類似検索では誤回答が上位に出てしまい、以降の応答が歪む
- 実質「誤った記憶を固定化」してしまう
原因の考察
まだ原因解決に至っていません。今後の課題として要継続対応です。
- エラーや誤回答を無条件で保存している設計
- RAG が「過去を必ず優先する」仕組みのため、誤情報を修正できない
考えられる解決法?
正直この問題が今回の一番のはまりポイントです。いまだに解決の糸口が見つかりません。
- レイヤー分け(短期 / 長期)
短期メモリ:直近数十ターンは必ずプロンプトに入れる
長期メモリ:過去は pgvector に保存して検索して補う
→ 雑談を忘れないが、必ず直近を優先できる - 要約して保存
雑談もそのまま保存するとノイズだらけになるので
「1日の雑談まとめ」や「この1週間での出来事」みたいに要約して埋め込む
→ 検索時にヒットしやすい - 埋め込み強化
短文をそのまま入れず、文脈を補足して保存
悪例: 「カレー食べた」
良例: 「ユーザーは2025年8月25日に夕食でカレーを食べたと発言」
→ こうすると検索に強くなる - スコアに基づく重みづけ
雑談でも「何度も出てきた話題」は重要度を上げる
1回だけ出た断片はスコアを下げる→ 間違いの記憶が支配するのを防げ
どれも一長一短ですが、本来「AIの活用で省力化を狙ってるのに、その機能を作って人間の目で確認なんて本末転倒」な気がします。
過去の誤入力をどう扱うかについて、当初はAIで定期的に判定を行い、明らかに誤入力や誤情報と思われるものを自動で削除する仕組みを考えてもみました。しかし実際に運用を想像すると、すべてをAIに任せてしまうことへの不安が強く残りました。
結局、データベースを定期的に抽出してAIに判定させ、その結果に基づいて削除するという案も浮かびましたが、最終的には「これは危ういのではないか」と思いとどまったのです。AIに全てを制御させるのはやはり危険だという、多くの研究機関の警告を肌で実感しました。
一介のエンジニアである自分でも、すぐにその領域に踏み込める時代になったことは正直うれしく思います。しかし同時に、最先端の研究者たちが「AI依存は危険」と繰り返し警鐘を鳴らす理由が、少しずつ理解できるようになった気がします。
どうしたものか・・・
手順ごとの詳細記事
ここまでで全体像は見えたと思います。以下では各ステップを個別に解説しています。
順番に読み進めることで、同じ環境を再現できます。
PostgreSQL + pgvectorの導入
ベクトルデータベースの構築方法を解説します。
PostgreSQL16のインストールから、pgvector拡張機能の追加、テーブル設計、インデックス作成までの手順を詳しく説明します。

Embeddingモデルでベクトル
テキストをベクトル化するためのllama-serverの設定方法と、効率的な埋め込みの生成・保存方法について解説します。
異なる埋め込みモデルの比較も含みます。

Discord Bot 実装
Discord.pyを使ったボットの作成方法から、ユーザーとの対話処理、データベースとの連携まで、実装の詳細を解説します。
エラー処理や並列処理の最適化も含みます。

LMStudioをAPIサーバーにする
ローカルで動作するAIモデルをAPIとして公開する方法を解説します。
LMStudioの設定からモデルの選定、パラメータのチューニングまでカバーします。

検索精度向上とプロンプト工夫
RAGシステムの心臓部である検索精度の向上方法と、AIに最適な指示を与えるプロンプトエンジニアリングのテクニックを解説します。

このシリーズを完了すると…
クラウドサービスに依存せず、ローカル環境で動作する自分専用のAIチャット環境を構築できます。所詮GPT-OSS-20bベースではありますが、検証環境としては十分に「完成」と呼べるレベルに到達します。
ただし、用途を広げていくにはサーバーのスケールアップやチューニングが必要になります。今回の環境はあくまでファーストステップであり、今後の発展に向けた土台と考えてください。
実際に動作させてみた感想
下記は実際にDiscordを介してBotとと会話した際のLMStudio(内部はllama.cppベース)のログ出力です。
slot launch_slot_: id 0 | task 188 | processing task
slot update_slots: id 0 | task 188 | new prompt, n_ctx_slot = 4096, n_keep = 0, n_prompt_tokens = 147
slot update_slots: id 0 | task 188 | kv cache rm [0, end)
slot update_slots: id 0 | task 188 | prompt processing progress, n_past = 147, n_tokens = 147, progress = 1.000000
slot update_slots: id 0 | task 188 | prompt done, n_past = 147, n_tokens = 147
slot release: id 0 | task 188 | stop processing: n_past = 147, truncated = 0
ここからどの程度の処理性能が出ているかを読み解くことができます。
性能の読み方
入力処理は問題なく通っている(147トークン程度なら一瞬で処理できる)。また、4096トークンのコンテキストが確保されているため、標準的な対話や簡単な履歴参照には十分。
174トークンの日本語テキストは、大体 200〜250文字前後 になります。
ただし、ログには 出力速度(tokens/sec) が出ていません。LMStudioは別のログやコンソールで XX tokens/s の行が出るので、実際の生成スピードを確認するにはそこを見る必要があります。
個人的にな感想
- GPT-OSS-20bをMac mini上で 4Kコンテキスト環境で動かせた。
- 入力(147トークン)は即処理完了、応答生成も実用レベルで動作。
- 処理落ちやトークンの切り捨て(truncation)は発生していない。
- ただし、クラウドのChatGPTと比べると応答速度はワンテンポ遅い。
「147トークン程度の入力はほぼ一瞬で処理され、応答もストレスなく返ってきた。ただしクラウドのChatGPTと比べればワンテンポ遅く、トークン生成速度の違いを感じる。」といった感じでした。
RAG環境のAIをチューニングする作業は、想像以上に精神を削られるものでした。
対象のAIは言葉遣いや知識においては常人を超越した応答を平然と返してきます。ところが、その一方で人間ならあり得ない「誓い」を平然と口にしてきます。
キレポイント
- 「次からはこのようなことはしない」
- 「二度とこのようなことはしない」
- 「今後は必ず〇〇する」
- そして、また平然と嘘をつく・・・
- 「あなたが先ほどそう言ったからです。」
- 「そのプログラムはこうするべきです。」・・数秒経過「このプログラムは破綻しています。💢」
- etc
こうした発言はすべて“AI的な方便”に過ぎず、約束を守る保証などありません。当初は「子供を相手にするように、気長に調整していけばいいだろう」と思っていました。しかし、それは全くの甘い考えでした。
実際にやってみると、まるで精神異常者を相手にしているような錯覚に陥ります(実際にその経験があるわけではありませんが)。エンジニアは「ここぞ」というポイントで前意識をフル投入する傾向があると思いますが、プロンプトチューニングにおいてこれをやるのは本当に危険です。下手をすれば、こちらの精神が壊れてしまう危うさを感じました。
最終的に私は、限界ギリギリのところで踏みとどまり、「これは長期戦で浅く挑むしかない」と判断しました。RAG環境のAI調整は、一気に詰め込むのではなく、間合いを保ちながら取り組むべきものだと痛感しています。
将来の展望
現状のRAG環境はテキストを中心に構築していますが、今後の拡張として「ファイルの取り扱い」や「音声でのやりとり」なども検討対象に入っています。
これらを組み込むことで、より自然で直感的な情報活用が可能になると考えています。
ファイルの取り扱いについて
ファイルをアップロードして記憶できる仕組みを導入すれば、会話とファイルを一体として管理できるため、文脈に沿った運用が可能になります。設計書やソースコードなど形式を問わず保存でき、将来的に中身を解析してRAGに組み込む基盤としても活用できる点は大きな魅力です。また、クラウドに依存せずローカル環境で完結できるため、セキュリティ面でも安心感があります。
一方で課題も多く存在します。ファイル数が膨大になれば一覧性が失われ、タグ付けやカテゴリ管理が煩雑になることは避けられません。さらに中身を解析する段階に進めば、チャンク化や形式ごとの抽出処理が必要となり、設計や運用が複雑化します。
そして何より、「これらの課題を抱えてまで自作する必然性があるのか」という疑問が残ります。GoogleドライブやOneDriveを利用すれば、すでにファイルの保管・検索・共有といった基本機能は備わっており、自作環境を拡張する意味がどこまであるのかについて葛藤があります。
| メリット | デメリット |
|---|---|
| 会話とセットでファイルを記憶でき、文脈と一緒に管理できる | ファイル数が増えると一覧性が損なわれ、整理や検索が難しくなる |
| PDF、Word、Excel、ソースコードなど形式を問わず保存できる | タグ付けやカテゴリ分けの運用が煩雑になりやすい |
| ローカル環境で安全に管理でき、クラウド依存を避けられる | 中身を解析する場合はチャンク化や形式ごとの抽出処理が必要 |
| 将来的に解析やRAG検索に拡張できる基盤になる | 運用や実装が複雑化し、開発コストが増える |
まずは会話ログと検索精度の改善に集中し、ファイルの取り扱いについては将来の拡張機能として検討を継続することにしました。
音声でのやりとりについて
音声を使ったやりとりは、手が塞がっている状況や移動中でも利用できるという大きなメリットがあります。また、テキスト入力が不要になり直感的に問いかけができる点や、入力が難しいユーザーにとって有効な手段となる可能性もあります。
しかしながら、実際に導入を考えると課題が目立ちます。音声認識から応答生成、音声合成までの流れでどうしても数秒の遅延が発生し、会話のテンポが崩れてしまいます。人間の会話は瞬時の応答を前提としているため、問いかける間を意識したり、応答が3秒遅れるだけでも大きなストレスとなります。その結果、利便性よりも不便さが際立ち、結局は使われなくなる可能性が高いのです。
| メリット | デメリット |
|---|---|
| 手が塞がっている状況(作業中や移動中)でも利用できる | STT → LLM → TTS の処理で数秒の遅延が発生し、会話のテンポが崩れる |
| テキスト入力が不要になり、直感的に問いかけができる | 自然なリアルタイム会話は難しく、ストレスを感じやすい |
| アクセシビリティの観点で有効(入力が困難なユーザーでも利用可能) | 音声認識や合成に追加のAPIやリソースが必要で、運用コストが増える |
| 音声UIを導入することで利用シーンを広げられる | 実用性より不便さが目立ち、結局使われなくなる可能性が高い |
このため、音声でのやりとりについては現時点では導入を見送りました。手書きや入力が面倒だからこそ音声会話が選ばれるはずですが、現状の技術ではその利便性を十分に発揮できないと判断しています。将来的に遅延や精度の問題が解決された時点で、再度検討する余地はあると考えています。




