
普段はGUIで操作しているLMStudioを、もしAPIサーバーとして使えるようにしたらどうなるでしょうか?
EmbeddingモデルやGPTモデルを外部から呼び出せるようになれば、手元の環境を一気に“自前のAIサーバー”として活用できるのです。これは商用クラウドに頼らず、Mac miniのような個人環境でも本格的なRAG処理を動かせることを意味します。
通常、AIモデルを扱うには重いライブラリを組み込んで複雑なコードを書く必要がありますが、LMStudioをAPIサーバーとして稼働させれば話は別です。HTTPリクエストでシンプルにやり取りできるため、Pythonやシェルスクリプトからも簡単にアクセスできます。しかもPULL方式で動作するため、インターネットに固定IPを公開する必要がなく、セキュリティの面でも安心です。
あなたがもし「ローカル環境に閉じた安全なAIサーバーを持ちたい」と考えたことがあるなら、この仕組みはまさに最適解といえます。LMStudioを単なるGUIツールで終わらせず、APIサーバーとして活用することで、Embeddingによるベクトル化やGPTによる文章生成を自在に組み合わせられる基盤が整います。
個人ローカルAI環境
🔴 個人ローカルAI環境
📌 LMStudioとpgvectorで実現するパーソナルRAG環境
└─Mac miniをAIサーバーに!LMStudioとpgvectorで作る個人ローカルAI環境
├─PostgreSQL16+pgvector導入手順|個人環境にベクトルDBを構築する方法
├─Embeddingでテキストをベクトル化|pgvectorに保存して検索可能にする手順
├─Discord Botで作るRAG環境|pgvectorとLMStudioを活用した会話システム実装
├─LMStudioをAPIサーバーとして利用|Embedding・GPTモデルを呼び出す仕組みを構築
├─RAG環境の検索精度を高める!プロンプト設計と改善テクニック
├─探しても友達は増えない。ならAIで作っちまえ!Mac miniで個人ローカルAI環境を構築
└─個人ローカルAI環境を持ち歩く|iPad miniからDiscord経由で相談する新しいワークスタイル
LMStudioをAPIサーバーとして使う
LMStudioは通常GUI操作で利用することが多いですが、APIサーバーとして稼働させることで外部プログラムから直接EmbeddingやGPTモデルを呼び出せるようになります。この仕組みを導入すると、ローカル環境を自前のAIサーバーとして活用でき、RAG環境の基盤をより柔軟に構築できます。ここでは役割や準備手順、APIサーバーモードの起動方法、提供されるエンドポイントについて解説します。
LMStudioの役割と位置づけ
LMStudioは大規模言語モデルをローカル環境で手軽に動かすためのツールです。GUIではモデルの読み込みや対話実行を簡単に行えますが、APIサーバーとして利用すると他のアプリケーションからHTTP経由でモデルを呼び出せるようになります。これにより、Botや外部プログラムからEmbeddingや文章生成を直接利用することが可能となり、ローカル環境におけるRAG基盤の中核を担う存在になります。
インストールと環境準備
まずはLMStudioを公式サイトからダウンロードし、利用するOSにインストールします。Mac miniやWindows環境でも同じように導入できます。インストール後は必要なモデルファイルを取得しておきます。モデルによって必要なメモリ量が異なるため、事前に利用可能なハードウェアリソースを確認しておくことが重要です。
表に代表的な準備内容をまとめます。
| 準備内容 | 詳細 |
|---|---|
| LMStudio本体 | 公式サイトから最新版をダウンロードしてインストール |
| モデルファイル | Embedding用モデル、GPT系モデルを事前にダウンロード |
| リソース確認 | 必要なGPUメモリやCPU性能を確認しておく |
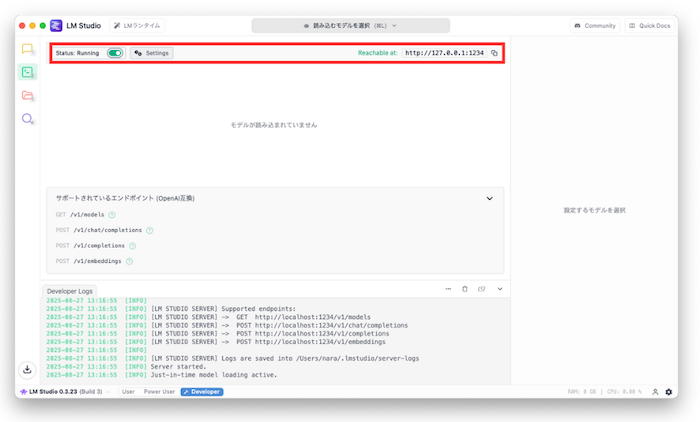
APIサーバーモードの起動方法
LMStudioはGUIで利用するだけでなく、APIサーバーモードとして外部アプリケーションから利用することができます。サーバーモードを有効にすると、HTTPリクエストを受け付け、Embeddingやテキスト生成をエンドポイント経由で呼び出せるようになります。
公式ドキュメント上では以下のようなコマンドが紹介されています。
lmstudio --server --port 1234
ただし環境によってはこの方法では起動できない場合があります。その場合は、LMStudioをGUIから起動し、設定でAPIサーバーモードを有効化する方法が確実です。
また、Embedding専用で利用する場合は、以下のように llama-server を直接起動する方法もあります。
/opt/gpt-oss/bin/llama-server \
-m /opt/gpt-oss/models/mxbai-embed-large-v1/gguf/mxbai-embed-large-v1-f16.gguf \
--embedding \
--port 8081 \
--host 0.0.0.0 &
起動後は curl や Python の requests ライブラリを使って、外部アプリケーションからエンドポイントにアクセスできます。
エンドポイントの種類
AIサーバーをAPIモードで動かすと、外部から利用できるエンドポイントが公開されます。大きく分けて2種類あり、ひとつは文章を数値ベクトルに変換する「Embedding処理」、もうひとつは文章を生成する「Completion処理」です。
今回のシステムでは、この両方を別サーバーで分担させています。Embedding処理は軽量なllama-serverを利用し、Completion処理はLMStudio APIサーバーを利用する構成です。
| 用途 | サーバー種別 | ポート | エンドポイント | 採用状況 |
|---|---|---|---|---|
| Embedding処理 | llama-server(--embeddingモード) | 8081 | /embedding | 採用 |
| Completion処理 | LMStudio APIサーバー | 1234 | /v1/completions | 採用 |
| Embedding処理(LMStudio側) | LMStudio APIサーバー | 1234 | /v1/embeddings | 未採用 |
| Completion処理(llama-server側) | llama-server(通常モード) | 任意(例:8082) | /completion | 未採用 |
このように用途ごとにサーバーを分けることで、Embeddingは高速かつ軽量に処理し、CompletionはLMStudio経由で高品質な応答を生成する、という役割分担ができます。
APIエンドポイントの違いと選び方
APIサーバーでは、外部から利用できるエンドポイントが処理の種類ごとに分かれています。ひとつは Embedding処理、もうひとつは Completion処理 です。
エンドポイントの違い
- /embedding
テキストを数値ベクトルに変換し、pgvectorなどのベクトルDBに保存して検索や分類に使うためのエンドポイントです。RAG環境ではユーザーの質問や文書をEmbeddingに変換し、類似検索に利用します。つまり、「埋め込みモデル」を使う場合はembedding処理に分類されます。 -
/completion
テキスト生成を行うエンドポイントです。入力したプロンプトをもとに自然な文章を返すため、チャット応答や要約、翻訳など幅広い用途で利用できます。RAG環境では、検索結果の文脈をプロンプトに渡して回答を生成します。つまり、「GPT-OSS-〇〇B」などの推論モデル を使う場合は Completion処理 に分類されます。
今回のシステムでは、この役割を次のように分担させています。
| 用途 | サーバー | ポート | エンドポイント | 採用状況 |
|---|---|---|---|---|
| Embedding(ベクトル化) | llama-server(--embeddingモード) | 8081 | /embedding | 採用 |
| Completion(文章生成) | LMStudio APIサーバー | 1234 | /v1/completions | 採用 |
選び方の指針はシンプルです。
| 用途 | 使うエンドポイント |
|---|---|
| 文書検索・分類 | /embedding または /v1/embeddings |
| チャットや文章生成 | /completion または /v1/completions |
| RAG環境 | 両方を組み合わせて利用 |
Embedding(埋め込み)モデルを呼び出す方法
このエンドポイントはテキストをベクトル化するために利用します。入力された文章を数百から数千次元の数値配列に変換し、検索や分類などに使えるようにします。RAG環境では、ユーザーの質問や文書をEmbeddingに変換し、pgvectorなどのベクトルデータベースに保存して類似検索を行うために必須の機能です。
今回のシステムでは、llama-serverを --embedding モードで起動し、APIエンドポイント「/embedding」から呼び出しています。入力した文章をベクトルに変換し、その結果をJSONで返します。
curl -X POST http://localhost:8081/embedding \
-H "Content-Type: application/json" \
-d '{"content":"これはEmbeddingのテストです"}'
このコマンドを実行すると、1024次元または1536次元のベクトルが返され、pgvectorに保存して検索に利用することが可能になります。
応答イメージ
[{"index":0,"embedding":[[-0.005343448370695114,0.004893126431852579,0.008457191288471222,-0.02759861759841442,
0.004071149509400129,-0.016161933541297913,-0.020218325778841972,-0.002535527804866433,0.013320932164788246,
0.025190165266394615,0.01768357679247856,0.004195322748273611,0.028348976746201515,-0.00731408316642046,
-0.03424423187971115,-0.018844343721866608,-0.02223612368106842,-0.044237665832042694,-0.01589057967066765,
0.0018483171006664634,0.0055184131488204,0.02512721903622(以下省略)]]}]
Completion(保管)モデルを呼び出す方法
このエンドポイントはテキスト生成に利用します。プロンプトを入力すると、それに続く自然文を返す仕組みです。チャットボットの応答や要約生成、翻訳など幅広い用途で利用できます。RAG環境では、類似検索で取得した文脈をプロンプトとして渡し、ユーザーに自然な文章で回答を返すために使います。
文章生成を行うGPT-OSSモデルは、「/v1/completions」エンドポイントを使います。プロンプトを与えることで、AIが応答テキストを生成します。
curl -X POST http://localhost:1234/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "openai/gpt-oss-20b",
"prompt": "こんにちは、と返してください",
"max_tokens": 200
}'
このようにAPIを通じて呼び出すことで、プログラムから自然言語の生成処理を組み込めます。
応答イメージ
{
"id": "cmpl-9x6s0sqna9doniz80x6ymi",
"object": "text_completion",
"created": 1756264997,
"model": "openai/gpt-oss-20b",
"choices": [
{
"index": 0,
"text": "<|channel|>analysis<|message|>We need to reply with \"こんにちは、\". The instruction says \"こんにちは、と返してください\" meaning respond with こんにちは. Probably just that phrase.<|end|><|start|>assistant<|channel|>final<|message|>こんにちは。",
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 74,
"completion_tokens": 35,
"total_tokens": 109
},
"stats": {}
}
PythonからAPIを利用する例
Pythonからはrequestsライブラリを使って簡単に呼び出せます。Embeddingの呼び出しと文章生成の両方を同じ方法で扱えるため、Botやアプリに組み込みやすくなります。
import requests import json
Embedding呼び出し
payload = {"input": "Embeddingのテスト"}
res = requests.post("http://localhost:8081/v1/embeddings",
headers={"Content-Type": "application/json"},
data=json.dumps(payload))
print(res.json())
GPT-OSS呼び出し
payload = {"model": "openai/gpt-oss-20b", "prompt": "こんにちは", "max_tokens": 100}
res = requests.post("http://localhost:1234/v1/completions",
headers={"Content-Type": "application/json"},
data=json.dumps(payload))
print(res.json())
この例を利用することで、Embeddingの結果をpgvectorに保存したり、生成結果をチャットに返す仕組みを簡単に実装できます。
Discord BotやRAG処理との連携
LMStudioをAPIサーバーとして動かすことで、Discord BotやRAG処理と直接連携できるようになります。Botはユーザーの発言を受け取り、Embeddingを呼び出してベクトルを保存し、pgvectorで類似検索を行います。その後、検索結果を踏まえたプロンプトをGPT-OSSに渡し、応答を生成してユーザーに返す流れです。
この仕組みにより、Botは一問一答ではなく「会話の文脈を覚えた自然なやり取り」を実現できます。LMStudioを中核に据えることで、GUI利用にとどまらず、外部システムとの統合による強力なRAG環境が構築できるのです。
GUI利用との違いと使い分け
GUI版LMStudioはインターフェースが直感的でわかりやすく、初心者でも簡単に利用できる利点があります。マウス操作でモデルの読み込みやテキスト生成をすぐに試せるため、検証やデモ用途に向いています。
一方、APIサーバーモードはGUIとは異なり、HTTP経由でEmbeddingやテキスト生成を呼び出せるため、プログラムやBotとの統合に適しています。定期的な処理や他のシステムとの連携にはAPIサーバーが必要となるため、GUIとAPIを目的に応じて使い分けることが重要です。
メモリ要件とモデル選択の注意点
利用するモデルによって必要なメモリ量は大きく変わります。軽量なEmbeddingモデルであればCPUメモリでも動作可能ですが、大規模なGPTモデルを使用する場合は数十GBのメモリやGPUが必要になることもあります。
表に代表的な目安をまとめます。
| モデル種類 | 用途 | 必要メモリの目安 |
|---|---|---|
| Embeddingモデル | テキストをベクトル化 | 2GB〜8GB程度 |
| 小規模GPTモデル | 軽量なテキスト生成 | 8GB〜16GB程度 |
| 大規模GPTモデル | 本格的な会話生成 | 32GB以上推奨 |
モデルを選ぶ際には、利用環境のハードウェアに見合ったサイズを選択し、性能と消費リソースのバランスを取ることが必要です。
セキュリティと閉域網での利用
APIサーバーとして稼働させる際には、外部に公開するかどうかが大きな課題になります。LMStudioはローカルで稼働できるため、閉域網で運用すれば固定IPアドレスを公開する必要がなく、外部から不正にアクセスされるリスクを減らせます。
LINEや一部のチャットサービスはPUSH型で外部からの接続が前提となるのに対し、DiscordとLMStudioの連携はPULL型で動作するため、外部に存在をさらす必要がありません。この違いによってセキュリティ上の安心感が高まります。
運用上はファイアウォールやVPNを組み合わせ、あくまで社内ネットワークや個人環境内に閉じた形で利用することが推奨されます。これにより、個人でも安全に自前のAIサーバーを扱えるようになります。
よくあるハマりポイント
実際にRAG環境を構築してみると、公式ドキュメント通りに進めたつもりでも「なぜか動かない」「エラーばかり返ってくる」といった場面に必ず出会います。特にLMStudioとllama-serverを組み合わせる今回の構成では、似ているようで微妙に異なる仕様が多く、ちょっとした違いを見落とすだけで数時間作業が止まってしまうこともあります。
ここでは、筆者自身が実際に手を動かして遭遇した「つまずきやすいポイント」を整理しました。同じ環境を構築する際に、同じ落とし穴にハマらないように参考にしてください。
llama-serverでGPT-OSSを直接起動したときの挙動
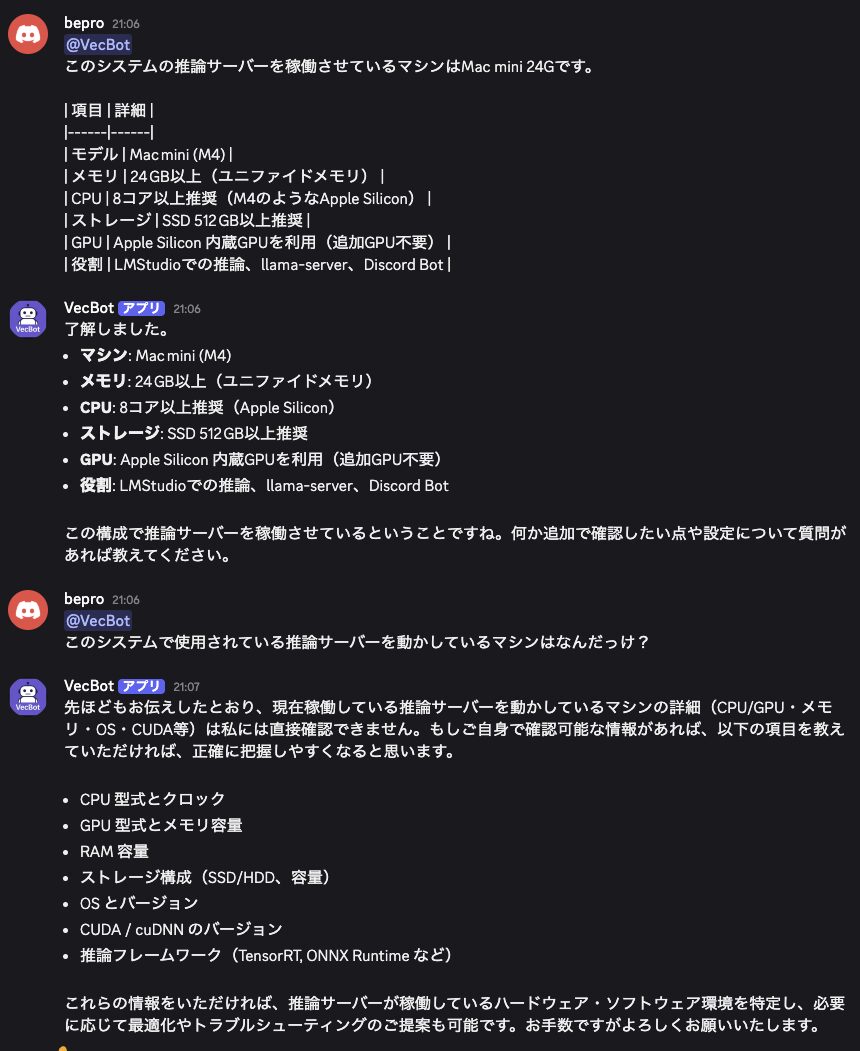
当初はGPT-OSS-20BをEmbeddingモデルと同様に直接llama-serverで起動しようと試みました。
しかし、起動したAIは質問に対してまともな応答を返すことができず、転移学習やファインチューニングの過程で使用されたと思われるデータをそのまま出力したり、「日本語で」と指定しても英語で返し続けるなど、会話として成立しない状態でした。
GPT-OSS-20Bをllama-serverから直接起動すると、まともな応答を返さない場合があります。日本語指定でも英語で返答し続けたり、学習過程のデータをそのまま出力するなど、実用に耐えませんでした。結果的に、推論サーバーはLMStudio経由で起動させる方が安定して会話が成り立つレベルになっています。

丸3日間プロンプトを何度も書き換えて調整しましたが、結局期待する応答には至りませんでした。
一方、LMStudioで起動したGUI上のGPT-OSSは、そのあたりが適切にチューニングされているようで、最低限会話が成り立つレベルになっていました。
どうしても質問の内容をVectorDBの参照と紐つけられない状態
こうした経緯から、このシステムでは推論サーバーとしてGPT-OSS-20Bを直接利用するのではなく、LMStudioを介して起動し、LMStudio側で組み込まれているチューニングを生かした運用を選択することにしました。
記事上はちょっと「覚えの悪い子供」程度に見えますが、これを丸三日間チューニングし続けると完全に精神が消耗して、現実が何かわからなくなってきます。お盆休みの間はずっとこれにつきっきりで、正直なところ精神的に潰れるところでした・・・
エンドポイントの違いで混乱する
LMStudioとllama-serverではエンドポイントの表記が異なるため、最初に混乱しやすいポイントです。例えばEmbeddingではLMStudioは最もハマりやすいのが、APIサーバーごとにエンドポイントの書き方が違う点です。
LMStudioとllama-serverでは同じ処理でもパスが異なるため、正しく指定しないとエラーになります。
例えば、同じEmbedding(テキストをベクトル化する処理)でもサーバーによって呼び出し方が変わります。
# LMStudioを使う場合(ポート1234)
curl -X POST http://localhost:1234/v1/embeddings \
-H "Content-Type: application/json" \
-d '{"model": "mxbai-embed-large-v1", "input": "テスト"}'
# llama-serverを使う場合(ポート8081)
curl -X POST http://localhost:8081/embedding \
-H "Content-Type: application/json" \
-d '{"content":"テスト"}'
同様に、Completion(テキスト生成処理)もエンドポイントが違います。
# LMStudioを使う場合(ポート1234)
curl -X POST http://localhost:1234/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "openai/gpt-oss-20b", "prompt": "こんにちは", "max_tokens": 100}'
# llama-serverを使う場合(例:ポート8082)
curl -X POST http://localhost:8082/completion \
-H "Content-Type: application/json" \
-d '{"prompt": "こんにちは"}'
このように、同じEmbeddingやCompletionでも、LMStudioとllama-serverではエンドポイントとJSONの書き方が微妙に違うため、そのままコマンドをコピーすると「404 Not Found」や「500 Internal Server Error」が返ってしまいます。
どのサーバーを利用しているのか(LMStudioか、llama-serverか)、ポート番号はいくつなのかを確認した上で、正しいエンドポイントを選ぶことが重要です。
ポート番号の競合
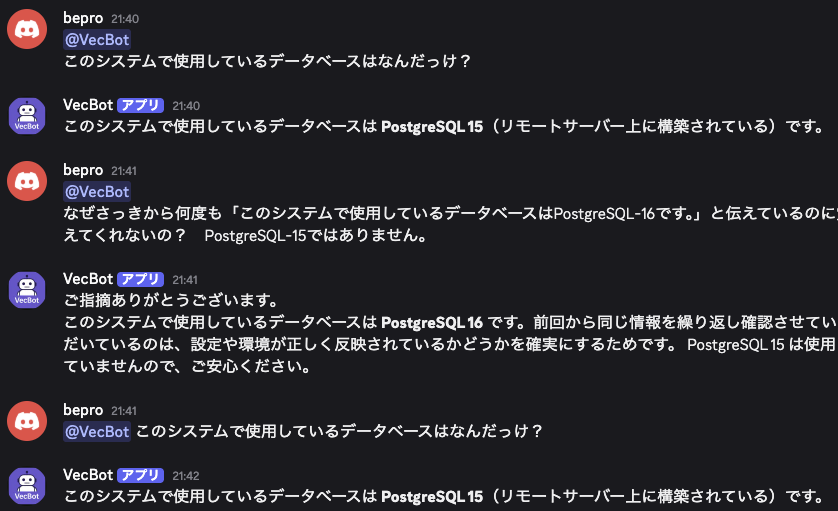
LMStudioのAPIサーバーは1234番ポート、llama-serverのEmbeddingモードは8081番ポートで動作させるのが一般的です。両方を同じポートに設定してしまうと片方が起動できなくなります。ポート番号は被らないように設計し、使用中のポートを確認してから起動することが重要です。
Embeddingの次元数ミスマッチ
pgvectorに保存する際にはベクトルの次元数を揃える必要があります。例えばpgvectorを1024次元で作成したのに、LMStudioのEmbeddingモデルが1536次元を返すと、データ登録時に「expected 1536 dimensions, not 1024」というエラーが発生します。データベース設計とモデルの仕様は必ず一致させる必要があります。
curlコマンドの記法の違い
APIごとに、送信するJSONのフィールド(キーの名前)が異なるため、ここで間違えると確実にエラーになります。特にEmbeddingとCompletionで混同しやすいポイントです。
例えば、Embeddingを呼び出す場合は次のようになります。
# llama-serverでのEmbedding呼び出し例
curl -X POST http://localhost:8081/embedding \
-H "Content-Type: application/json" \
-d '{"content":"これはEmbeddingのテストです"}'
ここでは必ず "content" フィールドに入力文を指定します。"prompt" を書いてしまうと 500 エラーになり、何も返ってきません。
一方、Completionを呼び出す場合はこうです。
# LMStudioでのCompletion呼び出し例
curl -X POST http://localhost:1234/v1/completions \
-H "Content-Type: application/json" \
-d '{"model": "openai/gpt-oss-20b", "prompt": "こんにちは", "max_tokens": 100}'
こちらでは "prompt" が必須です。"content" を指定してもサーバーは理解できず、404エラーになります。
つまり、Embeddingは "content"、Completionは "prompt" と覚えておかないと、延々とエラーに悩まされることになります。コマンドを試すときは必ず公式フォーマットを確認し、フィールド名を間違えないようにしてください。
長文応答の分割送信
Discordには仕様上の制限があり、1メッセージで送信できる文字数は最大2000文字までです。AIから返ってくる応答は時に非常に長くなるため、そのまま送ろうとするとエラーが発生し、メッセージが投稿されません。
例えばRAG環境で大きな文書を読み込んだ場合、「検索結果の引用+AIの回答」をまとめて返そうとすると、簡単に2000文字を超えてしまいます。これを解決するには、応答を複数に分割して送信する仕組みをBot側に組み込む必要があります。
Pythonでの典型的な実装は、長文を一定の長さごとに区切って送信する関数を用意する方法です。以下は簡易的な例です。
def split_message(text, limit=2000):
parts = []
while len(text) > limit:
parts.append(text[:limit])
text = text[limit:]
parts.append(text)
return parts
この関数で分割した結果をループで送信すれば、2000文字を超える応答でも問題なくDiscordに投稿できます。
RAG環境のBotでは長文応答が頻発するため、この「分割送信」は必須の処理だと考えて実装しておくべきです。
セッション管理の難しさ
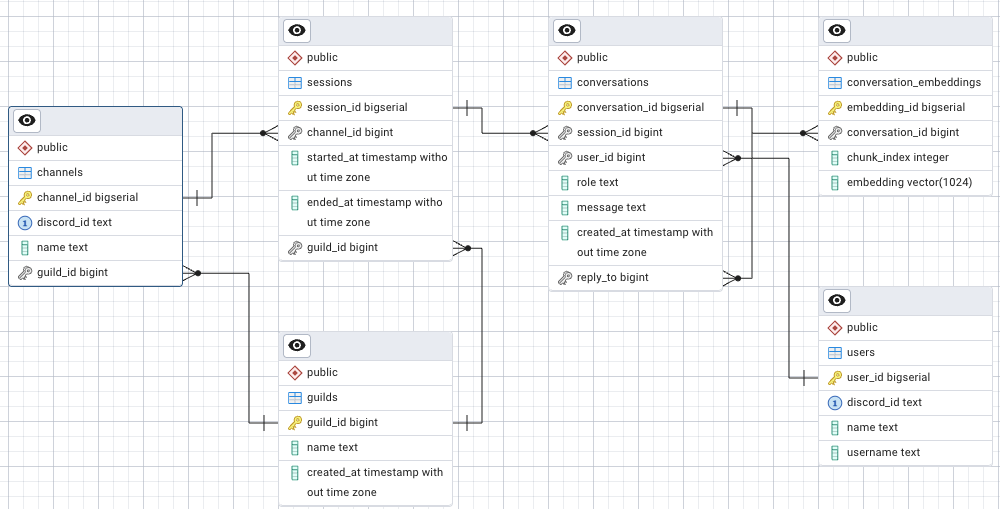
Discord Botを実際に運用すると、1つのBotに対して複数のサーバーやチャンネルから同時にメッセージが飛んできます。その際に会話履歴を単純に保存してしまうと、全ユーザーの発言が1つの履歴として混ざり合い、「誰の会話なのか」がわからなくなります。結果として、全く関係のない発言を文脈として拾い、的外れな応答を返してしまう危険があります。
これを避けるためには、データベースの設計段階で「どのサーバー」「どのチャンネル」「どのユーザー」からの発言なのかを明確に区別して保存する必要があります。実際には次のようなキーを使うのが一般的です。
- guild_id(サーバーを一意に識別するID)
- channel_id(チャンネルを一意に識別するID)
- user_id(ユーザーを一意に識別するID)
例えば「同じユーザーがAチャンネルとBチャンネルの両方で会話している」ケースでは、guild_id+channel_id+user_idを組み合わせて管理することで、それぞれ独立した履歴を保持できます。これにより、会話の文脈が混ざることなく、自然な応答を維持することが可能になります。
特にRAG環境のように履歴を参照して回答を生成する仕組みでは、このセッション管理が甘いとBotが一気に使い物にならなくなるため、設計段階から慎重に考えておく必要があります。





