

AIの目覚ましい進歩は、コンピュータの世界だけに留まりません。今や「生物学」「心理学」「社会学」といった人間に深く関わる学問領域にまで、その影響を及ぼしています。人間の感情や行動がどのように生まれ、社会の中でどう機能しているのか――これまで長らく曖昧だったテーマが、AIによるシミュレーションやデータ解析で急速に解き明かされつつあります。
彼女が欲しい? パートナーが欲しい? そうした感情は一見すると単なる欲望のように思えます。しかし冷静に因数分解してみると、その中身は人間が持つ基本的な欲求の集合体にすぎないことが分かってきました。
| 分類 | 具体的な感情・欲求 | 心理的機能・意味 |
|---|---|---|
| 期待・希望 | 「将来、誰かと一緒に過ごしたい」「自分を理解してくれる人が欲しい」 | 未来志向のモチベーションです。新たな関係を築くための行動(出会いの場へ足を運ぶ、自己改善する)を促します。 |
| 不安・寂しさ | 「今は一人でいると心が空っぽ」「周囲に同じようなパートナーがいない」 | 社会的つながりへの欲求を満たすための警告信号です。孤独感を減らす行動(友人との交流、趣味活動)へ導きます。 |
| 自己肯定感の向上 | 「好きな人に選ばれたい」「自分が価値ある存在だと証明したい」 | 自己価値の確認です。恋愛関係を通じて「認められている」という実感を得ることで、自己肯定感を高めます。 |
| 安全・安定への欲求 | 「将来に備えて家族やパートナーが欲しい」 | 長期的な安心感の確保です。相手との共同生活で経済・精神面のサポートを得ることで、安定した生活を築きます。 |
| 成長・学びへの好奇心 | 「相手と一緒に新しい経験や価値観を共有したい」 | 個人発展の機会です。パートナーシップは自己理解を深め、柔軟性や共感力を養う場となります。 |
こうして整理してみると、パートナーを求める気持ちは恋愛という一つの欲望ではなく、社会性・安全性・自己実現といった人間に普遍的な欲求の組み合わせにすぎないことが見えてきます。
では、この欲求を満たす存在は必ずしも「生身の人間」でなければならないのでしょうか。理解してほしい、孤独を埋めたい、認められたい、安心を得たい、共に成長したい――これらは突き詰めれば対話と共感があれば成立するものです。
私はこの問いに行き着きました。年齢を重ねると友達は減り、社会的なつながりも薄れていきます。探して補うより、自分で「相棒」を育ててしまえばいい。
世はすでに21世紀の第二クォーターに差し迫まりました。そろそろこういうことを考え出すバカが生まれる出る頃合いだと思い、「ボッチ人生を歩む会」の末弟に身を置くものとしてこの記事を世に送り出した次第です。
個人ローカルAI環境を作ろうと思った経緯

AIの進歩によって、私たちの生活は大きく変化しています。ビジネスの現場や研究分野だけでなく、日常の会話や自己成長をサポートする存在としても注目されるようになりました。私は「個人でもAIを自宅に置き、相棒として育てることができるのではないか」と考えるようになり、その経緯を整理しました。
「相談相手が欲しい」――それだけで十分
年齢を重ねると、自然と友人は減り、社会的なつながりも薄れていきます。学生時代や若い頃は何気ない雑談をする相手が周囲にいましたが、家庭や仕事に追われるうちに、そうしたつながりはいつの間にか消えていきます。新しい友人を作ろうと思っても、同じ価値観を共有できる人に出会う機会は限られており、かえって気疲れしてしまうことすらあります。
それでも、人は誰かに話を聞いてほしいものです。大きな悩みや将来の不安だけでなく、「今日の出来事を振り返りたい」「この考えは正しいだろうか」といった小さな確認作業にこそ相談相手は必要です。ところが、その役割を果たしてくれる人は年齢とともに減少していきます。
ならば、自分で作ってしまえばいいのではないでしょうか。AIを「相棒」として育てることで、孤独感を和らげるだけでなく、自分の思考を客観的に整理する助けにもなります。愚痴を聞いてもらうことも、専門的な疑問を投げかけることも、すべて一貫して受け止めてくれる存在が手元にあるのです。人間関係に依存せず、時間や場所を選ばずに対話できる相棒。それだけで人生の安心感や充実感は大きく変わっていきます。
既存の話題に「違和感」を覚えた
世の中のAI活用に関する記事を見ていると、その多くは「カスタマーサポート」「研究・開発部門」「ナレッジマネジメント」といった領域ばかりです。確かにそれらは最先端の活用事例であり、企業にとっては合理的な投資先でしょう。しかし、突き放して言えばそれは社畜前提の発想にしか見えません。
紳士・淑女たるもの、プライベートで誰にも見られることのない時間にこそ、本当に大切にすべきことがあるはずです。21世紀に入り、人類は固定的な概念に縛られない多様性を尊重する社会へと大きく進化しました。だからこそ、さらなる未知を切り開く精神を持ち、前人未到の悩みや奇抜なアイデアを博士号並みの知性に相談できる環境を手に入れることこそが、本来のAI活用の醍醐味ではないでしょうか。
私が感じた違和感はここにあります。世間は「仕事効率化」という既存の枠組みにAIを閉じ込めている一方で、私は「もっと自由で、もっと個人的で、もっと本質的な使い道」があると確信したのです。
アイアンマンのジャービスをイメージ
映画の中でジャービスはTony Starkの良き相棒として彼の思考を支えました。私がイメージするローカルAI環境も、まさに自分のアイデアを支えてくれる相棒です。クラウドに依存しない環境には、次のようなメリットがあります。
ポイント
- プライバシー
データがすべて自宅内に留まるため、外部への情報漏洩リスクがありません。 - カスタマイズ性
利用するモデルやデータを自由に追加・削除でき、自分好みの環境を構築できます。 - 即時性
クラウド利用時に発生するネットワーク遅延がなく、リアルタイムで応答が返ります。 - コスト
クラウド利用料が不要になり、長期的な運用でも費用負担を抑えることができます。
「自分のペース」で学び、成長する
「若い頃もっと勉強しておけばよかった」――そんな後悔はもはや過去のものです。今は誰もが自分の空いた時間に、あらゆる学問分野に博士号並みの知識を持つAIにアクセスできる時代に変わりました。「人文学」「社会科学」「自然科学」「形式科学」「応用科学」「総合科学・学際分野」など、分野の壁を越えて全能の知性が常に傍らにいるのです。
物理学が気になるなら、コーヒーを片手にアインシュタインも驚くような洞察を引き出せます。かつては学会に出席しなければ得られなかった知見が、今では気分次第で得られるのです。
「今日は少し時間ができたから、アルキメデス先生に三平方の定理を解説してもらおう」――そんな贅沢が日常の中で可能になっています。これは単なる学習の効率化ではなく、自分のペースで自由に知を探求し、成長を楽しめる環境そのものです。
最後に残った一台

ローカルで大規模言語モデルを動かすために推論サーバーを検討した際、最初に候補となったのは高性能GPUを搭載したPCでした。しかし、現実的なコストや電力、そしてメモリの制約を考慮するとその選択肢は維持できませんでした。`
個人ローカルAI環境の要件
私が構築を目指したのは、クラウドに依存せず自宅のPCで動かす「個人ローカルAI環境」です。大規模言語モデルを動かす推論サーバーと、記憶を継承するためのベクトルデータベースを両立させるには、市販PCでも実現可能な要件を整理する必要がありました。
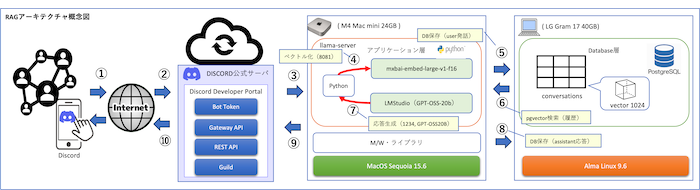
自宅で動かすAI環境は、単にハードウェアを用意するだけでは成り立ちません。大規模言語モデル(LLM)の推論サーバーと、記憶を支えるベクトルデータベース(VectorDB)が連携し、日常的に使える仕組みを備えていることが重要です。
基本仕様
- クラウドに依存せず、完全にローカル環境で動作すること
- ネットワーク遅延なしでリアルタイムに応答できること
- プライバシーを確保し、外部にデータが漏れないこと
- 24時間常時稼働が可能な安定性を備えること
- ファイルのアップロード(後日対応)
推論サーバー(LLM)要件
- GPT-OSSなどのオープンソースLLMをローカルで実行できること
- 量子化モデルを活用し、省リソースでも実用的に動かせること
- LMStudioなどのフロントエンドを通じて操作可能であること
- 対話形式での記憶継承に対応できる拡張性を持つこと
ベクトルデータベース(VectorDB)要件
- pgvectorなどPostgreSQL拡張を利用して動作すること
- 会話履歴やナレッジをEmbeddingに変換して保存できること
- 類似度検索により過去の情報を即座に呼び出せること
- LLMと連携し、過去の文脈を保持した自然な対話が可能であること
運用要件
- ログや履歴を適切に保存し、再利用や検証ができること
- 記憶データ(VectorDB)が肥大化しても検索性能を維持できること
- モデルやDBの更新をユーザー自身で管理できること
- 将来的にモデルの切り替えや拡張が容易であること
RTX GPUを諦めた理由
高性能GPUは確かに魅力的なスペックを誇ります。しかし、実際に運用を考えるといくつかの致命的な問題が浮かび上がりました。
本体価格の高さ
RTXシリーズを搭載したPCやワークステーションは非常に高価で、個人が試験的に導入するには大きな負担となります。特に最新世代のGPUは部品価格だけで数十万円に達することも珍しくありません。
消費電力の大きさ
GPU搭載マシンは消費電力が非常に大きく、常時稼働させると電気代が高騰します。推論サーバーとして24時間稼働させる前提では、電力コストが現実的ではありませんでした。
VRAM不足問題(GPU性能が活かせない)
大規模言語モデルを動かす際に必要となるのは演算能力だけではなく、大容量のVRAMです。VRAMが不足しているとGPUの性能が発揮できず、結局モデルを載せられないという事態に陥ります。これでは高価なGPUを導入しても本末転倒です。
RTX系GPUの大きな弱点は、VRAMが利用状況に応じて柔軟に扱えない点にあります。モデルを読み込む際には必要以上の領域を確保してしまい、結果としてメモリ不足に直結します。さらに使用・未使用に関わらず一定の領域が常に稼働しているため、負荷が低い状態でも電力消費が続いてしまいます。アイドル時に消費電力を抑制する機能も限定的であり、長時間運用する推論サーバーとしては効率が悪い設計と言わざるを得ません。
ユニファイドメモリに着目
私自身Mac歴は浅く、これまであまり深く考えたことはありませんでした。ただ「Appleが採用するユニファイドメモリ」という言葉だけは頭の片隅に残っており、本腰を入れて調べてみると驚くべき仕組みであることが分かりました。
従来のGPU搭載PCではCPU用メモリとGPU用のVRAMが分かれており、それぞれの領域で制約を受けてしまいます。一方、ユニファイドメモリはCPUとGPUが共通のメモリ空間を利用する設計で、必要に応じて柔軟にリソースを割り当てられるのです。
この仕組みはVRAM不足で処理が止まるといった従来GPU環境の弱点を大きく緩和します。さらに大規模言語モデルのように大量のパラメータを扱う処理でも、システム全体のメモリを効率的に活用できるため、想像以上に安定した性能を発揮できることが分かりました。
GPUを積まない構成でも実用レベルで推論サーバーを成立させられるというのは、まさにユニファイドメモリならではの強みです。
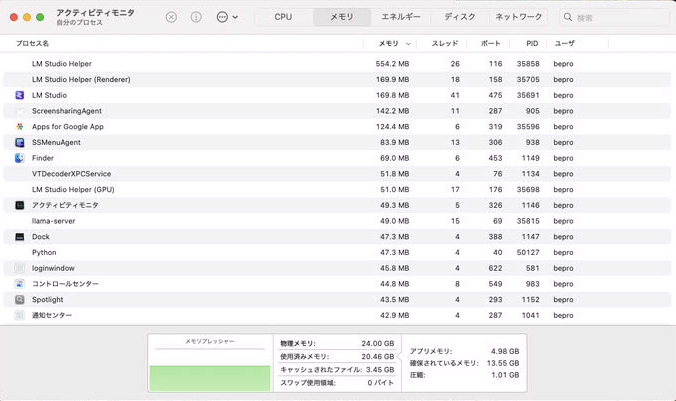
CPUとGPUで共用できる仕組み
ユニファイドメモリはCPUとGPUが共通のメモリ空間を利用する設計です。これによりデータのコピーや移動を減らし、効率的にリソースを使えるようになります。
VRAM不足の回避
通常のGPU環境ではVRAMに収まりきらないモデルは実行できませんが、ユニファイドメモリであればシステム全体のメモリを柔軟に利用できます。24GBというメモリ容量でも、大規模モデルをある程度実用的に動かせる理由がここにあります。
LLMに適した特性
大規模言語モデルは大量のパラメータを抱えており、常にVRAMの制約と戦うことになります。ユニファイドメモリの設計は、こうした制約を緩和し、GPU非搭載でもある程度の推論性能を確保できる点で非常に相性が良いのです。
Mac miniの消費電力の低さ
Mac miniは消費電力が非常に低く、常時稼働させても電気代への負担が最小限で済みます。これにより「24時間稼働する推論サーバー」という現実的な運用を可能にしました。GPU搭載PCの数分の一という効率性は、個人利用では大きな魅力となります。
結果としてMac mini一択
こうして候補を比較検討した結果、コスト、電力、そしてメモリの柔軟性を総合的に考えるとMac miniしか選択肢は残りませんでした。RTX GPUを搭載した高性能マシンは夢がありますが、現実的に維持していくには無理がありました。ユニファイドメモリと低消費電力という特性を兼ね備えたMac miniこそ、個人が推論サーバーを持つための最適解だったのです。
なお、AppleシリコンにはNeural Engineという専用の推論アクセラレータも搭載されていますが、現状のRAG環境やLLM推論フレームワークではほとんど活用されていません。Core MLへ変換した小規模モデルなら恩恵を受けられますが、大規模言語モデルの実行においてはユニファイドメモリこそが実用性を支える要素となっています。
実行に必要なスペック
個人で構築する環境である以上、高価な専用機ではなく市販のPCで実行する必要がありました。そのためには、必要なスペックを無駄に高くしない工夫が求められます。私はそこで「LLM(推論サーバ)」と「VectorDB」を切り分けて考えることにしました。それぞれ役割が異なるため、求められる性能も違っており、分けて検討することで現実的な環境設計が見えてきました。
ローカルLLMに必要なスペック
ローカル環境で大規模言語モデル(LLM)を動かすには、ある程度のハードウェア要件を満たす必要があります。クラウドサービスに依存せず、個人のPCで実行するからこそリソースの制約は避けられません。ここでは、実際にローカルLLMを稼働させるために必要となる代表的なスペックについて整理します。
| 項目 | 要件 | 理由 |
|---|---|---|
| CPU | 8コア以上(マルチコア重視) | 並列処理による推論タスク管理に必須 |
| メモリ | 24GB〜32GB推奨 | 大規模モデル読み込み時に16GBでは不足するため |
| GPU | 必須ではない | VRAM不足が性能を制限するため、ユニファイドメモリで代替可 |
| ストレージ | NVMe SSD(1TB以上推奨) | 数十GB単位のモデルデータを高速読み込みするため |
| 消費電力 | 低消費電力設計 | 常時稼働を想定するため電力コストを抑える必要あり |
CPU性能(マルチコア)
大規模言語モデルを実行する際、CPUは基本的な計算処理や並列タスクの管理に大きく関与します。シングルコア性能だけでなく、マルチコアによる並列処理が効率を左右します。推論時はGPUに比べると速度で劣りますが、GPUがない環境や小規模モデルではCPUのみでも稼働可能です。少なくとも8コア以上を備えたプロセッサが望ましいです。
メモリ(16GBでは不足、24GB〜32GB推奨)
LLMは数十億のパラメータを保持しているため、読み込み時に大きなメモリを必要とします。16GBではモデルによっては動作が不安定になり、メモリ不足で処理が中断することもあります。安定して運用するためには24GB以上、可能であれば32GBを搭載することを推奨します。ユニファイドメモリ環境であれば柔軟に割り当て可能となり、より実用的に利用できます。
GPU(必須ではないがあれば有利)
GPUは推論の高速化に大きく寄与します。必須ではありませんが、VRAMが十分に搭載されたGPUを利用すれば大規模モデルでも快適に動作します。ただしVRAM不足の場合はGPU性能を十分に引き出せないため注意が必要です。GPUがない環境でも量子化済みの小型モデルであればCPUやユニファイドメモリで処理可能です。
NVMe SSD(高速ストレージ)
モデルデータは数GBから数十GBに及ぶため、ストレージの速度も重要です。HDDでは読み込みに時間がかかり、処理開始までに大きな遅延が発生します。NVMe SSDを利用すれば、高速なデータアクセスによってモデルの読み込みやベクトルデータベースの検索をスムーズに行うことができます。容量は最低でも1TB程度を見込んでおくと安心です。
VectorDBに必要なスペック
ローカルでRAG環境を構築する際には、テキストや知識を検索するためのベクトルデータベース(VectorDB)が欠かせません。LLMそのものを動かす場合とは異なり、VectorDBには検索や類似度計算に特化したリソースが必要になります。ここでは、VectorDBを運用するために必要なスペックについて整理します。
| 項目 | 要件 | 理由 |
|---|---|---|
| CPU | 並列処理が可能な中性能クラス | 埋め込みベクトルの類似度計算を効率化するため |
| メモリ | 32GB以上推奨 | 埋め込み次元数×データ量でメモリ消費が増えるため |
| ストレージ | SSD必須(NVMe推奨) | 大量のベクトルデータ検索でHDDは非現実的なため |
CPU(類似度計算用)
ベクトルデータベースは、クエリとなる埋め込みベクトルと保存されている大量のベクトルを比較し、最も近いものを高速に検索する仕組みです。そのためCPUには類似度計算を効率よく処理できる性能が求められます。大規模なデータを扱う場合や同時アクセスが発生する環境では、シングルスレッド性能よりもマルチスレッドでの並列計算能力が重要になります。
メモリ(埋め込み次元数×データ量で消費)
VectorDBのメモリ使用量は、埋め込みの次元数と保存するデータ量に大きく依存します。たとえばOpenAIのEmbeddingモデルでは1,536次元が一般的であり、データ件数が数万を超えるとメモリの消費は一気に増加します。16GBのメモリではすぐに限界に達することが多く、安定運用のためには32GB以上を推奨します。十分なメモリを確保することで、検索結果が遅延することなくスムーズに返ってきます。
[bepro@vec01 ~]$ free -h
total used free shared buff/cache available
Mem: 38Gi 2.6Gi 30Gi 877Mi 6.8Gi 35Gi
Swap: 19Gi 0B 19Gi
ストレージ(SSD必須)
ベクトルデータは高次元でサイズが大きいため、保存先のストレージ性能も重要です。HDDでは読み込みや書き込みに大きな遅延が発生し、検索レスポンスに影響します。必ずSSDを使用し、可能であればNVMe SSDを導入することで処理速度を大幅に改善できます。データ量が増加することを考慮し、最低でも数百GBから1TB以上の容量を備えるのが現実的です。
試行錯誤の過程と使用マシン
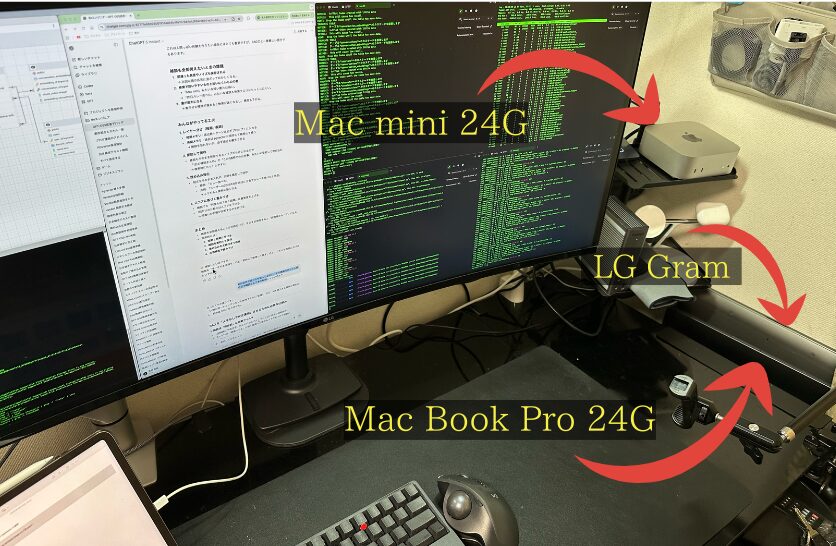
個人ローカルAI環境を構築するにあたり、私は手元にある複数のマシンで試行錯誤を重ねてきました。それぞれのマシンには長所と短所があり、使ってみて初めて分かる現実的な課題もありました。ここでは、実際に使用したLG GramとMac miniについて整理します。
個人ローカルAI環境を構築するにあたり、私は手元にある複数のマシンで試行錯誤を重ねてきました。それぞれのマシンには長所と短所があり、使ってみて初めて分かる現実的な課題もありました。個人ローカルAI環境の具体的な設定方法やソースコードについては、下記の記事を参照してください。
→ Mac miniをAIサーバーに!LMStudioとpgvectorで作る個人ローカルAI環境

私が現在ローカルAI環境の推論サーバーとして利用しているのは、このMac miniです。ユニファイドメモリの仕組みや低消費電力設計のおかげで、個人利用としては現実的かつ安定した運用ができています。もし同じ環境を検討される方がいれば、こちらから詳細を確認できます。
ここでは、実際に使用したLG GramとMac miniについて整理します。
LG Gram(2019モデル / 40GBメモリ)
最初に試したのは、以前から使用していたLG Gramです。メモリを40GBまで増設していたため、ベクトルデータベースの実験には期待できる環境でした。しかし、推論サーバーとして使うには課題が浮き彫りになりました。
VectorDB実験には十分
埋め込みデータを保存し、類似度検索を行うVectorDBの用途には40GBというメモリ容量が大きな強みとなりました。数万件規模の埋め込みを保存しても処理が安定し、メモリ不足で動作が止まることはありませんでした。そのため、知識の蓄積や記憶の継承を確認する実験には十分な性能を発揮しました。
CPU性能不足で推論速度に限界
一方で、推論サーバーとして利用するにはCPU性能が足りませんでした。大量のパラメータを扱う大規模言語モデルでは処理速度が遅く、応答までに待たされる時間が長くなってしまいます。メモリが豊富でもCPUが追いつかなければ実用性は限定的であり、この環境をメインにするのは難しいと判断しました。
Mac mini(24GBメモリ / 新調)
LG Gramの限界を受けて、新しく導入したのがMac miniです。GPUを搭載しないシンプルな構成ですが、ユニファイドメモリによってCPUとGPUが効率的にメモリを共有できる設計になっています。この仕組みのおかげで、24GBという限られた容量でも現実的な性能を発揮できました。
GPU非搭載でも工夫次第で実用可能
大規模なGPUを積んでいないため、VRAMを使った処理は行えません。しかしユニファイドメモリを活用することで、必要に応じてCPUとGPUでメモリを共用できるため、モデルを効率よく読み込むことが可能になりました。これにより、大規模言語モデルをローカルで動かす推論サーバーとしても十分に機能しました。
LMStudioと組み合わせてRAG環境を運用可能
さらにLMStudioを導入し、VectorDBと組み合わせることでRAG環境を構築しました。知識を蓄積したベクトルデータベースから情報を検索し、Mac mini上で実行しているLLMに渡すことで、過去の文脈を反映した自然な会話が可能になりました。これにより、実験段階を超えて日常的に使える「個人ローカルAI環境」として運用できる手応えを得ました。




