

普段のDiscordでの会話が、そのままAIとの知識検索に繋がったら便利だと思いませんか?
今回の記事では、pgvectorとLMStudioを組み合わせて、RAG環境をDiscord Botに実装する方法を解説します。
背景として、Discordは閉域網でも利用でき、インターフェースが洗練されているうえにUIとしての実績も十分。PC・タブレット・スマートフォンといった環境を選ばず操作がわかりやすく、履歴を遡って終えることができるため1スレッドの限界に縛られません。また、特定の目的に対応したコミュニティを作成できる柔軟さも大きな利点です。
汎用性を考えれば日本国内ではLINEに軍配が上がりそうですが、LINEはWebhookによるPUSH方式で固定IPの公開が必要になるためセキュリティ的な懸念が残ります。これに対し、DiscordはBotによるメッセージ検知をPULL方式で処理できるため、安全性と利便性を兼ね備えた選択肢として最適と判断しました。
個人ローカルAI環境
🔴 個人ローカルAI環境
📌 LMStudioとpgvectorで実現するパーソナルRAG環境
└─Mac miniをAIサーバーに!LMStudioとpgvectorで作る個人ローカルAI環境
├─PostgreSQL16+pgvector導入手順|個人環境にベクトルDBを構築する方法
├─Embeddingでテキストをベクトル化|pgvectorに保存して検索可能にする手順
├─Discord Botで作るRAG環境|pgvectorとLMStudioを活用した会話システム実装
├─LMStudioをAPIサーバーとして利用|Embedding・GPTモデルを呼び出す仕組みを構築
├─RAG環境の検索精度を高める!プロンプト設計と改善テクニック
├─探しても友達は増えない。ならAIで作っちまえ!Mac miniで個人ローカルAI環境を構築
└─個人ローカルAI環境を持ち歩く|iPad miniからDiscord経由で相談する新しいワークスタイル
Discord Bot実装の基本

Discordを活用したRAG環境の構築において、Botの実装は欠かせないステップです。ここではBotの役割から始まり、必要な環境準備、Developer Portalでの登録手順、サーバーへの招待方法までを解説します。
Botの役割
Discord Botはユーザーの発言を受け取り、RAG環境に接続して処理を行い、適切な応答を返す仲介者として動作します。単なるチャットの自動応答にとどまらず、データベースとの接続、Embedding処理、AIモデルの呼び出しを一連の流れで実現します。
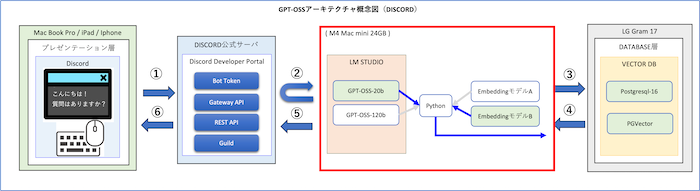
Discord Bot「②」は、ユーザーがDiscordに送信したメッセージをDiscord Developer Portal経由で検知します。
メッセージが発信されると、APサーバ(Python)がそれを都度取得し、処理の起点となります。仕組みとしては、Discord Botがメッセージを検知した際に、Developer PortalがPULL方式でメッセージを取り込み、システム内部に渡す流れです。
この方式であれば、システム側でインターネットに固定IPアドレスを公開する必要がなく、外部に存在を知られるリスクが低くなります。
さらに、LINEなどの他チャットサービスのようにPUSH型で外部に公開する方式と比べて安全性が高く、PC・タブレット・スマートフォンなど多様なデバイスから利用できるため、実運用において非常に利便性が高い仕組みといえます。
必要なライブラリと環境
Botを実装するためにはPython環境と必要なライブラリを揃える必要があります。特にdiscord.pyはメッセージを受け取って処理するために必須となります。
pip install discord.py psycopg2 requests python-dotenv
さらに、環境変数を管理するために.envファイルを用意し、Botのトークンやデータベース接続情報を記述しておきます。
DISCORD_BOT_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxx
PG_ADDR=127.0.0.1
PG_PORT=5432
PG_DB=vecdb
PG_USER=postgres
PG_PASS=xxxxxxxx
Discord Developer Portalでの登録
Botを利用するためにはDiscord Developer Portalでの事前登録が必要です。まずアプリケーションを新規作成し、その中にBotユーザーを追加します。その際、生成されるBotトークンを必ず控えておきます。このトークンは外部に漏洩すると不正利用されるため、必ず安全に管理してください。
登録手順は以下の通りです。
- Discord Developer Portal(https://discord.com/developers/applications)へアクセスします。
- 「New Application」をクリックしてアプリケーションを新規作成します。
- General Information 画面で、アプリケーションの Name(名前) と APP ICON(アイコン) を設定します。
- 作成したアプリの設定画面で「Bot」を選び、「Add Bot」をクリックしてBotユーザーを追加します。
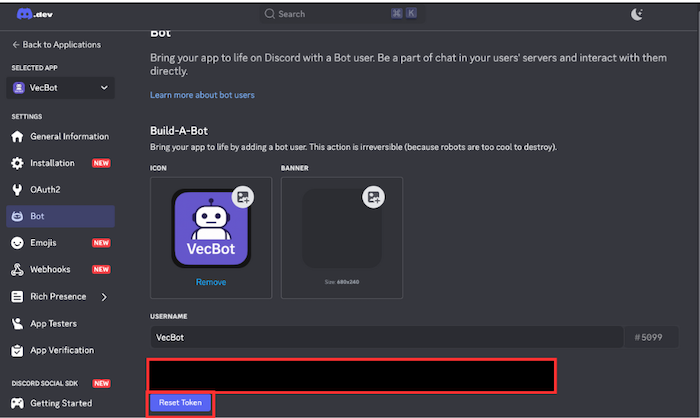
- 生成されたBotトークンをコピーして、.envファイルなど安全な場所に保存します。
DISCORD_BOT_TOKEN="XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX"
PG_ADD=XXX.XXX.XXX.XXX
PG_PORT=5432
PG_DB=vecdb
PG_USER=postgres
PG_PASS=P@ssW0rd - 「OAuth2」→「URL Generator」でスコープに「bot」を選択します。
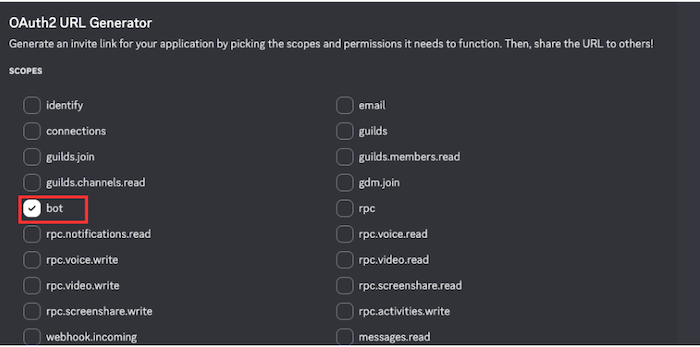
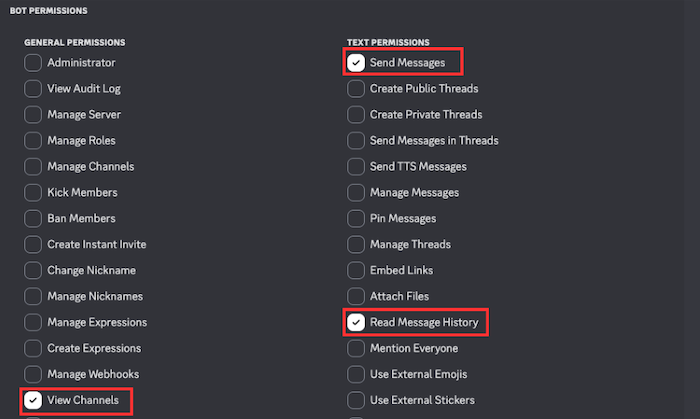
- 必要な権限(メッセージ読み取り、メッセージ送信など)にチェックを入れます。
- 生成された招待URLをコピー
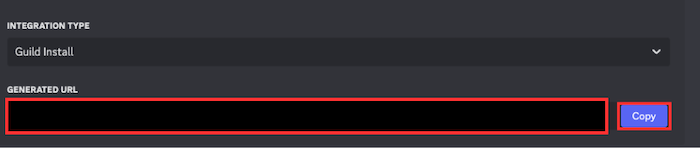
- コピーしたURLをブラウザへ貼り付け、出力されたダイアログにてBotを任意のサーバーに追加します。
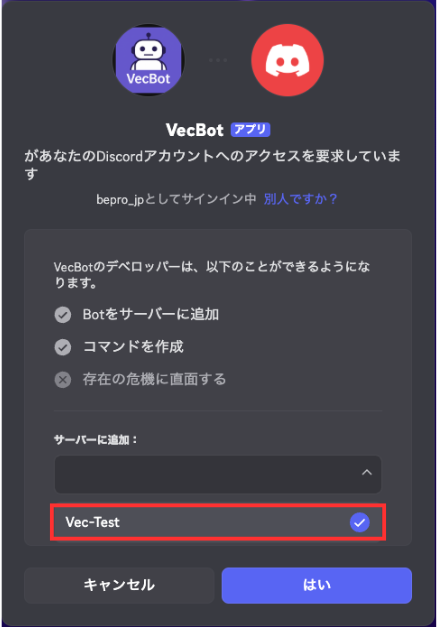
公式手順(アプリケーション管理者権限がない場合)
アプリ作成時やBot追加直後に、アプリケーション管理者権限を持っているアカウントなら、OAuth2招待を経由しなくても自分のサーバーにBotが既に所属している状態になったいるため、この作業は必要ありません。
Developer Portalで「bot」スコープを含んだURLを生成し、そのURLからサーバーに招待します。
作成したBotは適切な権限を付与した上でDiscordサーバーに招待する必要があります。Developer Portalの「OAuth2」設定からスコープに「bot」を選択し、必要な権限(メッセージの読み取りと送信)を付与して招待URLを生成します。
生成されたURLにアクセスするとBotを任意のサーバーに追加することができます。これでBotがDiscordサーバー上で稼働する準備が整います。
この設定を完了することで、BotはDiscord上でメッセージを検知し、AIとの接続を行えるようになります。
https://discord.com/oauth2/authorize?client_id=XXXXXXXXXX&scope=bot&permissions=xxxx483648
これでBotがDiscordサーバーに参加し、メッセージを受け取れる状態になります。
会話の処理フロー
Discord Botが人間らしい会話を続けられるようにするためには、単にメッセージを返すだけでは不十分です。人と話すときに「前に何を話したか」を踏まえて会話するように、Botにも過去のやり取りを覚えて参照する仕組みが必要です。
その仕組みを作るために、「発話の保存」「チャンク分割とEmbedding処理」「類似検索と文脈取得」「応答生成と返却」という4つのステップを順番に実行します。この流れを理解すると、RAG環境がどのようにして会話を成り立たせているのかが見えてきます。

ユーザー発話の保存
最初のステップは「ユーザーが話した内容を残すこと」です。これは人間で言えば日記に会話を書き残すようなものです。例えば友達と勉強の話をしていて「昨日のテストはどうだった?」と聞かれたとします。
もしその会話を覚えていなければ、「何のこと?」となってしまいます。ところが日記に残していれば「ああ、昨日の数学のテストの話か」と思い出せます。Botにとっての「日記」がデータベースです。
ユーザーがメッセージを送ると、その内容は「誰が」「どのサーバーで」「どのチャンネルで」「どんな発言をしたか」といった情報と一緒に記録されます。
これにより、後から「このチャンネルでの会話履歴」や「このユーザーの発言だけ」を呼び出すことができます。記録がなければ会話は一問一答の繰り返しになり、前後のつながりが途切れてしまうため、この保存処理はとても重要です。
チャンク分割とEmbedding処理
次のステップは「文章を小さな単位に分けて覚えやすくすること」です。人間が長文をそのまま丸暗記するのが大変なように、Botにとっても長い文章を一度に扱うのは効率的ではありません。そこで一定の文字数ごとに文章を区切り、小さなかたまりにします。これを「チャンク分割」と呼びます。
区切られたチャンクはそのままでは文字列ですが、AIにとっては数字の方が扱いやすいので「Embedding」という処理を行います。Embeddingとは、文章を数値のベクトルに変換する仕組みです。例えば「車」と「自動車」という言葉は似た意味を持っていますが、Embeddingすると数値の位置が近くなるため「意味が似ている」と判定できます。逆に「車」と「猫」は全く違う意味なので数値の位置も遠くなります。
こうして得られたベクトルは、専用のデータベース拡張であるpgvectorに保存されます。これにより、後から「似ている発言」を効率よく検索できるようになります。
テキスト → チャンク分割 → Embedding → ベクトル化 → データベースに保存
類似検索と文脈取得
次に、新しい発言が来たときの処理です。Botはただ返事をするのではなく、「これまでに似た話があったか」を探します。これは人間が「前にも同じ質問をされたな」と思い出すのと同じです。
検索の仕組みはシンプルで、新しい発言をEmbeddingしてベクトルに変換し、データベースに保存された過去のベクトルと比較します。このとき「距離」が近いほど意味が似ていると判定されます。例えば「バックアップを取りたい」と「データを保存したい」は別の表現ですが、Embeddingすると近いベクトルになるため、関連があると判断されます。
さらに、この検索では単にユーザーの過去の発言だけでなく、それに対するAIの応答も一緒に取得します。つまり「質問と答えのペア」を呼び出すのです。こうすることでBotは「以前こんな質問が来て、こう答えた」という文脈を再利用できます。これが会話の一貫性を作る仕組みです。
SELECT c.message, 1 - (e.embedding <-> %s::vector) AS score FROM conversations c JOIN conversation_embeddings e ON c.conversation_id = e.conversation_id WHERE c.session_id = %s ORDER BY score DESC LIMIT 5;
応答生成と返却
最後に、見つけた会話の文脈をもとにAIに応答を作ってもらいます。プロンプトには「新しい質問」と一緒に「過去の関連する会話」も渡します。AIはそれを参考にして答えを作るため、単なる一問一答ではなく「前にこんなやり取りをしたから、今回はこう答えよう」という自然な流れになります。
作成された応答はそのままDiscordに返されます。ただしDiscordには2000文字の制限があるため、長い文章は自動的に分割して送信されます。この仕組みにより、情報が途中で切れることなくユーザーに伝わります。さらに、この応答もEmbeddingされてデータベースに保存され、次回以降の会話に活かされます。つまり「会話の記憶」がどんどん積み重なっていくのです。
for chunk in split_message(reply): await message.channel.send(chunk)
このように、発話の保存からEmbedding、検索、応答生成という流れを繰り返すことで、Botは「前後の文脈を理解して返事ができる存在」になります。まるでノートに会話を書き続け、それを振り返りながら友達と話すようなイメージです。これがRAG環境の大きな強みであり、Discord Botを使った実装のポイントでもあります。
Bot運用の工夫
Discord Botを安定的に運用するためには、単に会話を処理するだけでなく、利用環境に応じた工夫が必要です。長文の分割送信やセッション管理、エラー処理とログ出力を取り入れることで、より実用的で信頼性の高いBotとなります。ここではその具体的な方法について解説します。
長文応答の分割送信
Discordには一度に送信できる文字数の上限があり、2000文字を超えるメッセージは送信できません。AIが生成した応答が長文になる場合、そのまま送ろうとするとエラーになります。これを防ぐためには、応答を一定の長さごとに分割して順番に送信する仕組みを導入します。
def split_message(text: str, limit: int = 1900) -> list[str]: return [text[i:i+limit] for i in range(0, len(text), limit)]
このように分割したメッセージをループ処理で送信することで、ユーザーに途切れず応答を届けることができます。
セッション管理と複数チャンネル対応
Botが複数のサーバーやチャンネルで利用される場合、会話履歴を正しく分けて管理することが重要です。セッション管理を導入することで、「どのサーバー」「どのチャンネル」での会話かを識別し、それぞれの文脈を保ったまま応答が可能になります。
データベースにはguild(サーバー)、channel(チャンネル)、session(会話単位)を紐づけて記録する構造を採用します。これにより、同じユーザーでもサーバーやチャンネルが異なれば独立した会話として扱うことができ、混乱を防ぐことができます。
| 管理対象 | 役割 |
|---|---|
| guild | サーバー単位の識別 |
| channel | チャンネル単位の識別 |
| session | 会話の区切りを識別 |
この仕組みにより、Botは複数の場所で同時に利用されても正しく会話を続けることができます。
エラー処理とログ出力
運用時にはエラーが発生することを前提に設計しておく必要があります。例えば、Embeddingサーバーが停止していたり、データベースに接続できない場合などです。これらの状況に対応するために例外処理を組み込み、問題発生時にはユーザーにわかりやすく通知します。
また、原因調査を容易にするためにログ出力も欠かせません。ログには「処理の開始と終了」「エラーの詳細」「ユーザー発言の保存状況」などを記録します。ログを残すことで、Botの動作状況を後から確認でき、障害対応のスピードを大幅に高めることができます。
try: result = call_gptoss(prompt) except Exception as e: logger.error(f"GPT呼び出し失敗: {e}") await message.channel.send("内部エラーが発生しました。")
このような仕組みを組み込むことで、Botは安定的に動作し、利用者に安心して使ってもらえる環境を提供できます。
まとめ
ここまでで、Discord Botを使ったRAG環境の実装方法について解説しました。単にBotを動かすだけでなく、データベースとの連携やEmbedding処理、会話履歴の検索と活用を組み合わせることで、実用的で一貫性のある会話システムを構築できることがわかります。最後にポイントを整理し、次の記事への流れを確認します。
実装のポイント整理
今回の内容を振り返ると、以下の点が実装のポイントとなります。
| ポイント | 内容 |
|---|---|
| Botの準備 | Discord Developer Portalで登録し、必要な権限を付与したうえでサーバーに招待すること |
| 会話の保存 | ユーザー発言をデータベースに記録し、過去の会話を参照可能にすること |
| Embedding処理 | 文章をチャンク分割してベクトル化し、pgvectorで検索できるようにすること |
| 文脈検索 | 類似度計算で関連する会話を取得し、応答の一貫性を保つこと |
| 運用の工夫 | 長文分割送信やセッション管理、エラー処理とログ出力を取り入れること |
これらのポイントを押さえておくことで、単なるチャットBotではなく、知識を活用した自然な会話を続けられるシステムが完成します。
次の記事への繋がり
今回のBot実装によって、ユーザーの発言を保存し、検索し、応答を返す一連の流れが形になりました。次の記事では、LMStudioをAPIサーバーとして活用する方法を解説します。これにより、Botが利用するAIモデルをローカル環境で安定的に稼働させることが可能になり、外部に依存しない自前の環境を完成させることができます。
この流れを理解することで、個人でも本格的なRAG環境を運用できる基盤が整い、さらに高度な検索精度やプロンプト工夫へのステップへ進めるようになります。




