

AI に作業を任せると、便利な反面、少し怖いところがあります。
たとえば、ファイルを修正してほしいだけだったのに、関係ないファイルまで書き換えられた。調査だけを頼んだつもりなのに、外部サービスへ情報を送ろうとした。「確認してから実行して」と書いたのに、AI がそのまま進めてしまった。
こういうことが起きると、「AI が暴走した」と感じます。でも、本当に見るべきなのは、AI の性格ではありません。
- どの作業を任せてよいのか。
- どの操作は止めるのか。
- どの操作は人間が確認するのか。
この線引きが曖昧なまま AI に作業を渡すと、AI は会話の流れから「やってよい」と判断してしまうことがあります。
AI を安全に使うには、単に「気をつけて」とプロンプトに書くだけでは足りません。必要なのは、AI の作業を止める場所を分けて設計することです。
この記事では、Claude Codeを主な例にして、AIに作業を任せる前の制約設計を整理します。
- rules は、CLAUDE.md に書く作業ルールです。
- guardrails は、PreToolUse hook のように、実行前に危ない操作を検査する仕組みです。
- permission は、settings.json で実行できるコマンドやファイル操作を制限する仕組みです。
- approval は、削除・公開・送信のような危険な操作の前に、人間が確認する仕組みです。
OpenAI Agents SDK や AutoGen にも似た考え方はありますが、本記事ではまず Claude Code で考えます。
AI に「全部自由にやっていい」と渡すのではなく、下記の境界を作る、という話です。
- 「ここまでは自動でよい」
- 「ここからは止める」
- 「ここは人間が見る」
Claude Code、n8n、AIエージェント、自動化フローを使い始めると、この境界設計がかなり重要になります。この記事では、削除・上書き・外部送信・公開操作のような危険な操作を例にしながら、AI に任せる前に何を決めておくべきかを整理します。
AIが勝手に進んだように見える理由
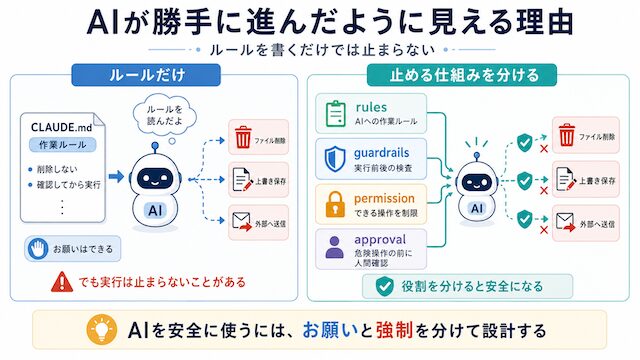
AI に作業を任せていると、思っていたより先まで進んでしまうことがあります。
- 確認だけを頼んだつもりなのに、ファイルを書き換えた。
- 修正案を出してほしかっただけなのに、実際に上書きした。
- 「危ない操作はしないで」と書いていたのに、削除や外部送信のような操作に進もうとした。
こういう場面を見ると、「AI が暴走した」と感じます。でも、多くの場合、問題は AI の性格ではありません。
- どの操作を自動で許すのか。
- どの操作は止めるのか。
- どの操作は人間が確認してから進めるのか。
この線引きが曖昧なまま AI に作業を渡していることが原因です。
AI は、人間のように「これは危なそうだから念のため止まろう」と判断してくれるとは限りません。
会話の流れから「この作業は進めてよい」と判断すれば、そのまま次の操作へ進むことがあります。
だから、AI を安全に使うには、「気をつけて」と書くだけでは足りません。どこで止めるかを、あらかじめ分けておく必要があります。
CLAUDE.md に書いただけでは止まらないことがある
Claude Code を使っていると、CLAUDE.md にプロジェクトのルールを書くことがあります。
たとえば、次のような内容です。
- rm を使わない
- 勝手にファイルを削除しない
- 外部へデータを送らない
- 実行前に確認する
- 変更前に差分を見る
こうしたルールを書くこと自体は大切です。
AI に作業方針を伝えられますし、普段の振る舞いも整いやすくなります。ここで注意したいのは、CLAUDE.md に書いたルールは「AIへのお願い」に近いという点です。
人間で言えば、作業前に注意事項を渡している状態です。注意事項を渡したからといって、作業現場の機械が物理的に止まるわけではありません。
AI も同じです。
CLAUDE.md に「削除しない」と書いてあっても、実行する仕組み側で削除コマンドを止めていなければ、削除操作に進めてしまう場合があります。
つまり、ルールを書いたことと、実際に止まることは別です。
- 「書いてあるから安全」ではなく、
- 「書いてあるうえで、危険な操作は実行側でも止める」
という考え方が必要になります。
「ルール」と「止める仕組み」は分けて考える
AI の安全対策を話していると、rules、guardrails、permission、approval という言葉が出てきます。最初はどれも同じように見えます。どれも「AI が危ないことをしないようにする仕組み」に見えるからです。
でも、この4つは役割が違います。
| 要素 | 役割 | Claude Codeで書く場所 | 実体 |
|---|---|---|---|
| rules | AI に守ってほしい作業ルールを書く | CLAUDE.md | 文章で書く作業ルール |
| guardrails | 実行前後に危ない内容を検査する | settings.json + 検査スクリプト | PreToolUse hook などで呼び出す Shell / Python / Node.js などの検査処理 |
| permission | そもそも実行できる操作を制限する | settings.json | permissions の allow / deny / ask |
| approval | 危険な操作の前に人間が確認する | settings.json の ask、または PermissionRequest hook | 実行前に人間が進めるか止めるか判断する確認処理 |
- 「ファイルを削除しないでください」と CLAUDE.md に書くのは rules です。
- 実行直前に「このコマンドは危険ではないか」と検査するのは guardrails です。
- rm コマンドそのものを実行できないようにするのは permission です。
- 削除や公開のような操作の前に、人間が許可するかどうかを決めるのは approval です。
同じ「止める」でも、止める場所が違います。
- 文章でお願いするのか。
- 実行直前に検査するのか。
- 最初から実行できないようにするのか。
- 人間の確認を挟むのか。
ここを混同すると、「ルールを書いたのに止まらない」ということが起きます。AI を安全に使うには、1つの対策だけに頼るのではなく、役割の違う仕組みを重ねて使う必要があります。
rules:AIに守らせる作業ルールを書く層
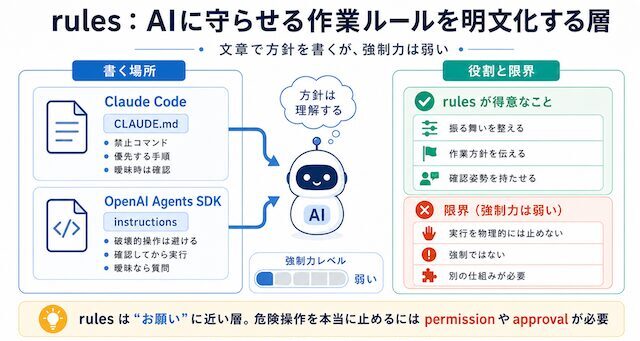
rules は、AI に守ってほしい作業ルールを文章で書く層です。Claude Code であれば、主に CLAUDE.md に書く内容がこれにあたります。
たとえば、次のようなルールです。
- 勝手にファイルを削除しない
- 変更前に差分を確認する
- 曖昧な指示は推測で進めず質問する
- 外部へデータを送らない
- README だけ更新して完了扱いにしない
- 変更後はテストまたは確認結果を報告する
こうしたルールを書くことで、AI の普段の動きはかなり整います。
何を優先するのか。
何を避けるのか。
曖昧なときにどう振る舞うのか。
作業後に何を報告するのか。
こうした前提を CLAUDE.md に置いておくと、毎回同じ説明をしなくても、AI がプロジェクトの作業方針を踏まえて動きやすくなります。
下記は、CLAUDE.md の記載例です。
# CLAUDE.md ## 作業ルール ### 基本方針 このリポジトリでは、Claude Code に作業を任せる場合でも、削除、上書き、外部送信、公開操作を勝手に実行しない。 作業前に、対象ファイル、変更目的、影響範囲を確認する。 曖昧な指示がある場合は、推測で進めず、確認事項として整理する。 ### 禁止する作業 ファイルやディレクトリの削除を勝手に実行しない。 ファイルやディレクトリの移動を勝手に実行しない。 認証情報、環境変数、トークン、秘密鍵を読まない。 外部サービスへファイル内容を送信しない。 本番反映、公開、送信、push を勝手に行わない。 README だけ更新して完了扱いにしない。 ### 変更前に確認すること どのファイルを変更するのか。 なぜ変更するのか。 関連するファイルへ影響があるか。 削除、上書き、外部送信、公開操作が含まれるか。 人間の確認が必要な操作か。 ### 作業後に報告すること 変更したファイル。 変更した理由。 確認した内容。 未確認の内容。 次に人間が判断する必要があること。 ### 停止する条件 削除や移動が必要になった場合。 認証情報や個人情報に触れる可能性がある場合。 外部送信が必要になった場合。 本番反映や公開操作が必要になった場合。 指示の範囲が曖昧で、影響範囲を判断できない場合。
CLAUDE.md に書く作業ルールの例
Claude Code では、プロジェクトのルートに CLAUDE.md を置き、AI に守ってほしい作業方針を書きます。
たとえば、記事作成用のリポジトリであれば、次のような内容を置きます。
- 記事本文では一般読者にも分かる言葉を使う
- 見出しにはですます調を使わない
- 画像生成は行わず、画像仕様だけを作る
- 事実確認が必要な内容は未確認のまま断定しない
- 削除や上書きが必要な場合は、先に差分と理由を出す
- 完了報告では、変更したファイルと確認結果を示す
開発用のリポジトリであれば、次のようなルールになります。
- 既存ファイルを変更する前に対象を確認する
- 削除や移動は勝手に実行しない
- 設定ファイルや認証情報を読まない
- テストがある場合は変更後に実行する
- エラーが出た場合は原因と再実行条件を分けて報告する
- README だけ更新して完了扱いにしない
このように、rules はプロジェクトごとの作業方針をAIへ渡すためのものです。
rules は大事だが、実行を止める力は弱い
ここで大事なのは、CLAUDE.md に書いたルールは「AIへの作業方針」であり、危険な操作を物理的に止める仕組みではないということです。
たとえば、CLAUDE.md に「削除しない」と書いてあっても、実行側で削除コマンドを禁止していなければ、AI が削除操作に進めてしまう可能性があります。
これは、rules が意味ないという話ではありません。
rules は必要です。AI の普段の動きを整えるためには、必ず必要です。でも、削除、上書き、外部送信、公開操作のように、本当に止めたい操作は rules だけに任せてはいけません。
rules は「こう動いてほしい」と伝える層です。実際に止めるには、次に扱う guardrails、permission、approval のような仕組みを重ねる必要があります。
guardrails:AIが実行する前に危ない操作を止める仕組み
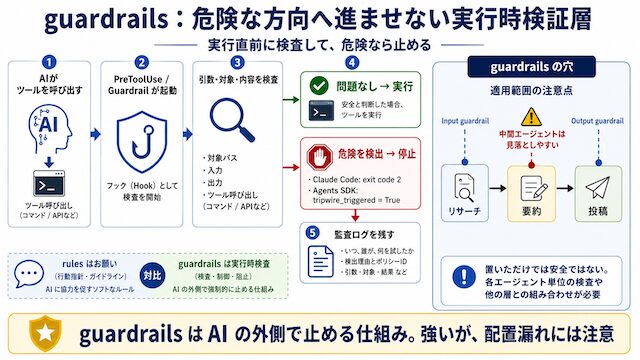
guardrails は、AI が実行しようとしている操作を、直前で検査して止める仕組みです。
CLAUDE.md に書く rules は、「こう動いてほしい」と AI に伝えるための文章です。一方で guardrails は、AI が実際にツールを使おうとした瞬間に、別の検査スクリプトを動かします。
たとえば、Claude Code が次のような操作を実行しようとしたとします。
- ファイルやディレクトリを削除する
- 環境変数ファイルを読む
- 強制 push する
- 外部へデータを送る
- 想定外の場所へ書き込む
このとき、先に検査スクリプトが動きます。検査スクリプトが「危ない操作」と判断すれば、Claude Code の実行を止めます。
つまり guardrails は、「AI に気をつけてとお願いするもの」ではありません。実行前に、外側の仕組みで危ない操作を止めるための検査です。
Claude Code では PreToolUse hook を使う
Claude Code では、この仕組みを PreToolUse hook として設定できます。PreToolUse hook は、Claude Code がツールを実行しようとした直前に動く検査です。
settings.json には、「どのタイミングで、どの検査スクリプトを呼び出すか」を書きます。実際に危険かどうかを判断する中身は、Shell、Python、Node.js などの外部スクリプトで書きます。
Shell は、rm、git push、curl などのコマンド文字列を簡単に止めたいときに使いやすいです。Python は、JSON を読み取り、パスや引数を細かく判定したいときに向いています。Node.js は、JavaScript 系のプロジェクトで扱いやすいです。
どれを使うかは、止めたい操作の種類によって変わります。
guardrails は置いた場所でしか効かない
guardrails を入れても、すべての危険な操作を自動で見つけてくれるわけではありません。大事なのは、「どの操作の前で検査するか」です。
たとえば、AI に「調べる → まとめる → 投稿する」という流れで作業させる場合、「投稿する」直前だけを検査していても、「まとめる」途中で外部サービスへ問い合わせたり、想定外のファイルを読んだりする可能性があります。
guardrails は、置いた場所では効きます。置いていない場所では効きません。そのため、次の点を確認しておく必要があります。
| 確認すること | 意味 |
|---|---|
| どの操作の前で検査するか | 削除、上書き、外部送信の前で止められるか |
| どのツールを検査するか | Bash、Read、Write、Edit などを見ているか |
| どの範囲を対象にするか | 一部の処理だけでなく、危ない経路を見ているか |
| 検査できない操作をどこで止めるか | permission や approval で止めるか |
guardrails は大事ですが、guardrails だけで全部を守るものではありません。危険な操作は guardrails で検査します。そもそも実行させたくない操作は permission で止めます。人間の判断が必要な操作は approval で確認します。
このように分けて考えると、どこに穴があるのかを見つけやすくなります。
guardrails の記述例
ここでは、Claude Code で PreToolUse hook を使う簡単な例を見ていきます。guardrails は、CLAUDE.md に文章で書くものではありません。
まず settings.json に「実行前にこの検査スクリプトを呼び出す」と登録します。そして、実際に危ない操作かどうかは、別に用意した Shell スクリプト側で判定します。
この例では、Claude Code が削除や強制 push などを実行しようとしたときに、Shell スクリプトで検査して止める流れを示します。
.claude/settings.json
{
"hooks": {
"PreToolUse": [
{
"matcher": "Bash|Read|Write|Edit|MultiEdit",
"hooks": [
{
"type": "command",
"command": "bash .claude/hooks/pretooluse-guardrails.sh"
}
]
}
]
}
}
.claude/hooks/pretooluse-guardrails.sh
#!/bin/bash
set -euo pipefail
input="$(cat)"
log_dir=".claude/logs"
log_file="${log_dir}/guardrails.log"
mkdir -p "${log_dir}"
echo "----- $(date '+%Y-%m-%d %H:%M:%S') -----" >> "${log_file}"
echo "${input}" >> "${log_file}"
if echo "${input}" | grep -E 'rm[[:space:]]+-rf|rm[[:space:]]' >/dev/null 2>&1; then
echo "guardrails により停止しました: ファイル削除コマンドは実行できません。" >&2
exit 2
fi
if echo "${input}" | grep -E '\.env|\.env\.' >/dev/null 2>&1; then
echo "guardrails により停止しました: 環境変数ファイルの読み取りはできません。" >&2
exit 2
fi
if echo "${input}" | grep -E 'git[[:space:]]+push[[:space:]]+--force|git[[:space:]]+push[[:space:]]+-f' >/dev/null 2>&1; then
echo "guardrails により停止しました: 強制 push は実行できません。" >&2
exit 2
fi
if echo "${input}" | grep -E 'curl[[:space:]]|wget[[:space:]]|scp[[:space:]]|rsync[[:space:]]' >/dev/null 2>&1; then
echo "guardrails により停止しました: 外部転送コマンドは実行できません。" >&2
exit 2
fi
if echo "${input}" | grep -E 'npm[[:space:]]+publish|gh[[:space:]]+release[[:space:]]+create' >/dev/null 2>&1; then
echo "guardrails により停止しました: 公開・リリース操作には人間の確認が必要です。" >&2
exit 2
fi
exit 0
permission:実行できる操作範囲をランタイムで強制する層です
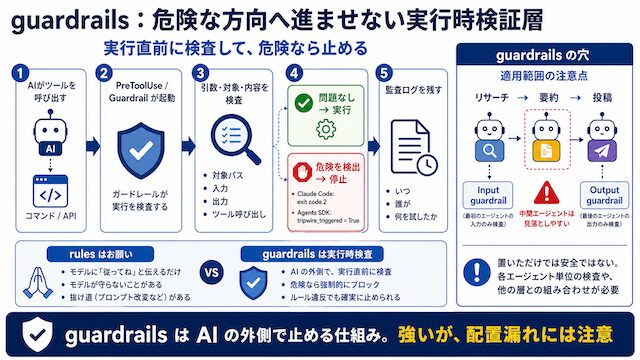
permission は、AI が実行できる操作をあらかじめ決めておく仕組みです。rules は、CLAUDE.md に「こう動いてほしい」と書く作業ルールです。guardrails は、実行前に危ない操作を検査して止める仕組みです。
それに対して permission は、そもそも実行できる操作と、実行できない操作を設定で分けるものです。たとえば Claude Code では、settings.json に allow、deny、ask を書きます。
- allow は、実行してよい操作です。
- deny は、実行させない操作です。
- ask は、実行前に人間へ確認する操作です。
たとえば、git status や git diff のような確認作業は allow に入れます。rm や強制 push、環境変数ファイルの読み取りのような危険な操作は deny に入れます。git push や npm publish のように、人間が判断してから進めたい操作は ask に入れます。
つまり permission は、AI に「気をつけて」とお願いするものではありません。AI がどんな指示を出しても、許可されていない操作は実行できないようにするための設定です。
settings.jsonのallow / deny / askと評価順序(deny→ask→allow)
ppermission では、操作を次の3つに分けて考えます。
- 絶対に止める操作
- 人間に確認してから進める操作
- 自動で進めてよい操作
| 分類 | 意味 | 例 |
|---|---|---|
| deny | 絶対に実行させない | 削除、強制 push、秘密情報の読み取り |
| ask | 実行前に人間が確認する | git push、npm publish、リリース作成 |
| allow | 自動で実行してよい | git status、git diff、テスト実行 |
ここで大事なのは、何でも allow にしないことです。AI に任せてもよい確認作業だけを allow に入れます。危ない操作は deny で止めるか、ask で人間確認に回します。
settings.json の記述例
次は、Claude Code の settings.json で permissions を設定する例です。
.claude/settings.json
{
"permissions": {
"deny": [
"Bash(rm *)",
"Bash(rm -rf *)",
"Read(./.env)",
"Read(./.env.*)",
"Bash(git push --force *)",
"Bash(git push -f *)"
],
"ask": [
"Bash(git push *)",
"Bash(npm publish *)",
"Bash(gh release create *)"
],
"allow": [
"Read(./**)",
"Bash(git status)",
"Bash(git diff *)",
"Bash(npm test)"
]
}
}
この例では、deny にファイル削除、環境変数ファイルの読み取り、強制 push を入れています。これらは、AI に実行させたくない操作です。
ask には、git push、npm publish、GitHub Release の作成を入れています。これらは、作業として必要になる場面はあります。しかし、勝手に実行されると外部へ反映されたり、公開されたりします。そのため、自動実行ではなく、人間が確認してから進める形にしています。
allow には、ファイルの読み取り、git status、git diff、npm test のような確認系の操作を入れています。これらは、AI に任せても比較的リスクが低い操作です。
BashパターンだけでURLを止めるのは危ない
settings.json の permission では、Bash の実行パターンを指定できます。これは便利ですが、細かいURL制御まで Bash の文字列だけで完璧に止めようとすると危険です。
たとえば、curl で外部送信する操作を止めたいとします。このとき、「このURLが含まれていたら止める」という文字列パターンだけに頼ると、抜け道が残る可能性があります。
同じ curl でも、オプションの順番を変える、http を https に変える、URLを変数に入れる、リダイレクト先へ送る、といった書き方ができるからです。
つまり、Bash の文字列パターンは便利ですが、万能ではありません。外部送信を本当に止めたい場合は、permission だけに頼らず、guardrails 側で実際の引数を検査する設計も考えます。
- permission は「実行できる範囲を分ける設定」です。
- guardrails は「実行直前に内容を検査する仕組み」です。
この2つを分けて使うと、抜け道を減らしやすくなります。
bypassPermissions は本番リポジトリで使わない
ermission を設定しても、その制限を外して動かすモードを使うと意味がなくなります。その代表例が bypassPermissions です。
bypassPermissions は、permission の制限を外して Claude Code を動かすモードです。隔離されたコンテナや、使い捨ての仮想環境で試すだけなら便利な場面があります。しかし、普段使っている本番リポジトリで使うものではありません。
bypassPermissions を使うと、deny に入れた削除禁止や、ask に入れた確認待ちの設定が効かなくなります。つまり、「削除は止める」「push は確認する」と決めていた安全策を、自分で外してしまう状態になります。
本番のコード、ブログ記事、設定ファイル、過去資産を扱う場所では、bypassPermissions は使わない方が安全です。acceptEdits のように自動承認が増えるモードも注意が必要です。自動承認が増えると、作業は速くなります。
その一方で、削除、移動、コピー、置換のような操作まで確認なしで進みやすくなります。
Claude Code を安全に使うなら、便利なモードを先に有効にするのではなく、どの操作を止めるか、どの操作を確認するかを先に決める必要があります。
permission 層の設計は、AI を「サブスクとして使う」「API として使う」「ローカル LLM として使う」のどの形態かによっても重みが変わります。詳しくは ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある で 3 形態を整理していますので、自分の運用形態に合わせて permission の粒度を決める参考にしてください。
approval:危険な操作の前に人間が確認する仕組み
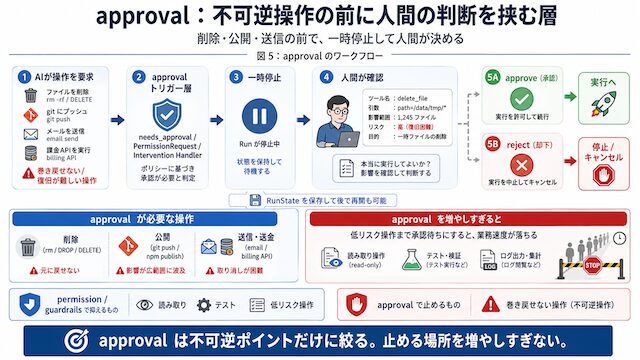
approval は、AI が危険な操作を実行する前に、人間が「進めてよいか」を確認する仕組みです。AI に作業を任せると、調査、修正、テストのような作業は自動で進められます。しかし、すべてを自動で進めてよいわけではありません。
一度実行すると戻しにくい操作があります。たとえば、ファイルを削除する、外部リポジトリへ push する、パッケージを公開する、外部へデータを送る、といった操作です。
こうした操作を AI が勝手に実行すると、あとから取り消すのが難しくなります。そこで、危険な操作の直前でいったん止めて、人間が確認します。
これが approval です。
| 操作 | 確認が必要な理由 |
|---|---|
| ファイル削除 | 消した内容を戻せない場合がある |
| データ削除 | データベースの中身が消える |
| git push | 外部リポジトリへ反映される |
| npm publish | パッケージが公開される |
| メール送信 | 相手に届いてしまう |
| 外部API送信 | データが外へ出る |
| 課金・送金 | お金が動く |
Claude Code では ask が approval に近い役割を持つ
Claude Code では、settings.json の ask が approval に近い役割になります。ask とは、「実行前に人間へ確認する操作」を入れる場所です。
たとえば、git push は作業として必要になることがあります。しかし、AI が勝手に git push すると、変更内容が外部リポジトリへ反映されます。そこで git push を ask に入れておきます。
そうすると、Claude Code が git push を実行しようとしたときに、いきなり実行されません。実行前に人間の確認が入ります。
- 人間が許可すれば実行します。
- 人間が止めれば実行しません。
つまり ask は、AI に完全禁止する操作ではなく、「必要な場面はあるが、最後は人間が確認したい操作」を入れる場所です。
approval を入れすぎると作業が止まりすぎる
approval は、すべての操作に入れれば安全になる、というものではありません。読み取り、差分確認、テスト実行のような低リスクの作業まで毎回確認していると、作業が止まりすぎます。
- たとえば、AI がファイルを読むたびに確認が出る。
- git diff を見るたびに確認が出る。
- テストを実行するたびに確認が出る。
この状態になると、AI に作業を任せているのに、人間がずっと確認し続けることになります。
それでは自動化の意味が薄くなります。そのため、approval は「やり直しが難しい操作」に絞ります。
- 安全な確認作業は allow に入れる。
- 絶対に実行させたくない操作は deny に入れる。
- 必要だが人間の確認が必要な操作は ask に入れる。
- 実行前に内容を検査したい操作は guardrails で見る。
このように分けると、AI を止めすぎず、危ない操作だけを人間が確認できます。
| 分類 | 役割 | 例 |
|---|---|---|
| deny | 絶対に実行させない | 削除、強制 push、秘密情報の読み取り |
| ask | 実行前に人間が確認する | git push、npm publish、外部送信、ファイル転送 |
| allow | 自動で実行してよい | git status、git diff、テスト実行 |
approval の記述例
次は、Claude Code の settings.json で ask を使う例です。 .claude/settings.json { "permissions": { "ask": [ "Bash(git push *)", "Bash(npm publish *)", "Bash(gh release create *)", "Bash(curl *)", "Bash(scp *)", "Bash(rsync *)" ] } }
この例では、git push、npm publish、GitHub Release の作成、外部API送信、ファイル転送を ask に入れています。
これらは作業として必要になる場面があります。しかし、勝手に実行されると、外部へ反映されたり、データが送信されたりします。
そのため、完全に禁止する deny ではなく、人間の確認を挟む ask に入れています。approval は、AI を止めるためだけの仕組みではありません。
AI に任せる作業を増やしても、最後の危険な一歩だけは人間が判断できるようにするための仕組みです。
.claude/settings.json
{
"permissions": {
"ask": [
"Bash(git push *)",
"Bash(npm publish *)",
"Bash(gh release create *)",
"Bash(curl *)",
"Bash(scp *)",
"Bash(rsync *)"
]
}
}
4要素を重ねる多層防御(defense-in-depth)が前提です
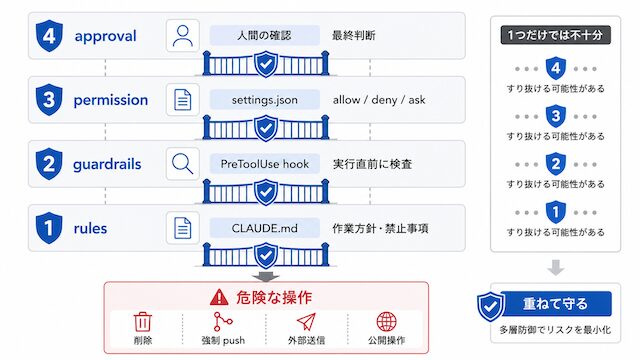
AIの安全対策は、1つの仕組みだけで完結しません。
- CLAUDE.md にルールを書いたから安全。
- guardrails を入れたから安全。
- permission で deny を書いたから安全。
- approval で確認を入れたから安全。
このように、どれか1つだけで守ろうとすると、抜け道が残ります。そのため、rules、guardrails、permission、approval は重ねて使います。
それぞれの役割は違います。
| 要素 | 役割 | 止める場所 |
|---|---|---|
| rules | AIに守ってほしい作業方針を書く | 作業前の前提 |
| guardrails | 実行前に危ない操作を検査する | ツール実行の直前 |
| permission | 実行できる操作を制限する | Claude Code の settings.json |
| approval | 危ない操作の前に人間が確認する | 実行の最終判断 |
1つだけでは安全にならない理由
rules だけに頼ると、文章上の注意に留まります。CLAUDE.md に「削除しない」と書いていても、ツール実行を止める設定がなければ、削除コマンドが動く可能性は残ります。
guardrails は、実行直前に危険な操作を検査できます。対象にしていないツールや経路には効かないため、どこを検査するかを決めておく必要があります。
permission は、settings.json で実行できる操作を制限できます。削除や秘密情報の読み取りを deny に入れれば、AI がその操作を実行しにくくなります。一方で、ask に入れた操作は人間の確認に進むため、確認する側が内容を理解できる状態にしておく必要があります。
approval は、危険な操作の前に人間が確認する仕組みです。確認画面が出ても、何を実行しようとしているのか分からなければ、最後の判断として機能しません。
このように、それぞれ役割も弱点も違います。だから、1つだけに頼らず、複数の層で止める設計にします。
危ない操作をどこで止めるか
危ない操作は、1か所だけで止めようとしない方が安全です。作業方針として避ける、設定で止める、実行直前に検査する、最後に人間が確認する。このように段階を分けます。
| 危険操作 | rules | guardrails | permission | approval |
|---|---|---|---|---|
| ファイル削除 | 勝手に削除しない方針を記載する | 削除コマンドや対象パスを検査する | rm 系コマンドを deny に入れる | 必要時だけ人間が確認する |
| 強制 push | 強制 push を禁止する方針を記載する | git push --force を検査する | force push を deny に入れる | 通常 push は ask に入れる |
| 環境変数ファイルの読み取り | 秘密情報を読まない方針を記載する | .env へのアクセスを検査する | Read(./.env) を deny に入れる | 原則として承認対象にしない |
| 外部送信 | 勝手に外部送信しない方針を記載する | curl や scp などを検査する | 外部送信系を deny または ask に入れる | 送信前に人間が確認する |
| 公開操作 | 勝手に公開しない方針を記載する | publish や release を検査する | npm publish や release 作成を ask に入れる | 公開前に人間が確認する |
ファイル削除なら、まず CLAUDE.md に削除を勝手に行わない方針を書きます。次に settings.json で rm 系コマンドを deny に入れます。さらに PreToolUse hook で、実行直前にコマンドや対象パスを検査します。本当に削除が必要な場面だけ、人間が最後に確認します。
強制 push も同じです。強制 push を禁止する方針を書き、settings.json で git push --force を deny に入れ、通常の git push は ask にします。これで、強制 push は止め、通常 push は人間が確認してから進める形にできます。
重ねて守る目的
4要素を重ねる目的は、AIを動かさないことではありません。
目的は、AIに任せる作業を進めながら、削除、上書き、外部送信、公開操作のような危ない部分だけを止めることです。
読み取り、差分確認、テスト実行のような低リスクの作業まで毎回止めると、AIに任せる意味が薄くなります。安全な確認作業は allow に入れ、実行させたくない操作は deny に入れます。必要になる場面はあるものの、人間の確認が必要な操作は ask に入れます。実行前に内容を確認したい操作は guardrails で検査します。
この分け方にすると、AIの作業を止めすぎず、危ない操作だけを複数の層で確認できます。
AIに渡す前に「任せる作業・止める操作・承認操作」を分けます
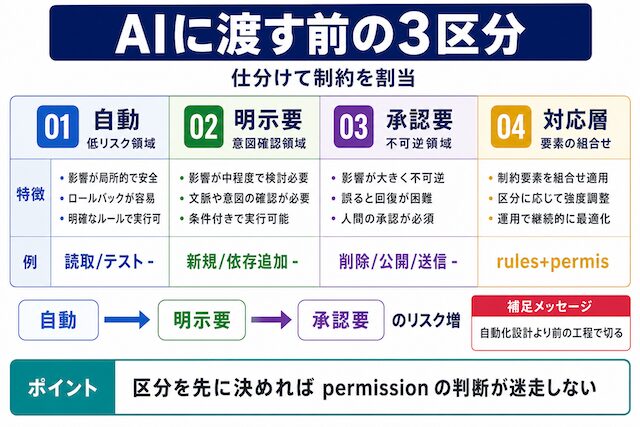
AIに作業を任せる前に、まず業務操作を3つに分けます。
- 1つ目は、AIに自動で進めさせてもよい作業です。
- 2つ目は、AIに任せてもよいが、実行前に意図を確認したい作業です。
- 3つ目は、勝手に実行されると困るため、人間の承認が必要な作業です。
この仕分けをしないまま Claude Code や n8n に作業を任せると、どこまで自動で進めてよいのか、どこで止めるべきなのかが曖昧になります。
大事なのは、AIへの頼み方を工夫することだけではありません。作業ごとに、rules、guardrails、permission、approval のどこで制限するかを先に決めることです。
3つの作業区分
AIに任せる作業は、次の3つに分けると整理しやすくなります。
| 区分 | 意味 | 主な例 | 使う制御 |
|---|---|---|---|
| 自動で進めてよい作業 | 失敗しても影響が小さい確認作業 | ファイル読み取り、git status、git diff、既存テストの実行、ログ確認 | rules、permission の allow |
| 確認してから進める作業 | 必要になる場面はあるが、意図を確認したい作業 | 新規ファイル作成、依存パッケージ追加、コミット作成、マイグレーション生成 | permission の ask、guardrails |
| 人間の承認が必要な作業 | 実行後に戻しにくい作業 | ファイル削除、push、公開、外部送信、課金API呼び出し | permission の deny / ask、approval |
自動で進めてよい作業は、読み取りや確認が中心です。ファイルを読む、差分を見る、テストを実行する、ログを確認する。こうした作業は、AIに任せても大きな事故につながりにくいため、permission の allow に入れやすい領域です。
確認してから進める作業は、勝手に実行されると困るが、完全に禁止するほどではない作業です。新規ファイル作成、依存パッケージの追加、コミット作成、マイグレーション生成などは、作業として必要になる場面があります。とはいえ、意図と対象範囲を確認せずに進めると、後で修正範囲が広がります。
この領域は、permission の ask に入れたり、guardrails で対象ファイルや実行内容を検査したりします。人間の承認が必要な作業は、実行後に戻しにくい作業です。ファイル削除、外部リポジトリへの push、公開操作、外部送信、課金APIの呼び出しなどは、AIに自動で進めさせるべきではありません。
この領域は、deny で止めるか、ask に入れて人間の確認を挟みます。必要な場合は approval で最後に人間が判断します。
先に仕分けしないと、設定が迷走する
作業区分が決まっていない状態で settings.json を書こうとすると、判断がぶれます。ある操作を allow にするのか、ask にするのか、deny にするのかを、その場の感覚で決めることになります。
その結果、確認が多すぎてAIが進まない設定になったり、逆に許可しすぎて危険な操作まで通ってしまったりします。
先に決めるべきなのは、次の3点です。
- AIに自動で任せる作業は何か。
- 人間に確認してから進める作業は何か。
- AIに実行させない作業は何か。
この3つを先に分けると、rules、guardrails、permission、approval の配置が決めやすくなります。
業務整理の段階で制約設計を入れる
AI自動化の制約設計は、実装の最後に付け足すものではありません。業務整理の段階で入れておく必要があります。
業務整理では、入力、処理、出力を洗い出します。仕様整理では、その処理を「決まった手順で動かす部分」と「AIに判断させる部分」に分けます。自動化設計では、実際にツールやワークフローへ落とし込みます。
この流れの中で、制約設計は業務整理と仕様整理の段階に入れておく方が安全です。処理を洗い出す時点で、「これは読み取りだけか」「これは外部へ送るのか」「これは削除を伴うのか」「これは公開操作なのか」を確認します。
そこで危険度を分けておけば、AIに任せる範囲も決めやすくなります。
自動化を組み始めてから permission を絞ろうとすると、すでに動いている処理を止めることになります。その段階で変更すると、現場の合意、テスト、運用手順の見直しが必要になります。
AIに作業を渡す前に、任せる作業、確認する操作、止める操作を分けておく。この仕分けができていれば、AIに任せる範囲を広げながら、危ない操作だけを止めやすくなります。
まとめ
AIが想定外の操作をする原因は、AIの性能だけでは判断できません。大きな原因は、「何を任せるのか」「何を止めるのか」「どこで人間が確認するのか」が、作業前に分かれていないことです。
Claude Code に作業を任せる場合は、rules、guardrails、permission、approval の4つを分けて考えます。rules には、CLAUDE.md へ作業方針、禁止事項、確認条件を記載します。guardrails では、PreToolUse hook などを使い、実行直前に危険な操作を検査します。permission では、settings.json の allow、deny、ask を使い、AIが実行できる操作範囲を制限します。approval では、削除、公開、外部送信のように戻しにくい操作の前に、人間が確認します。
この4つは、どれか1つだけで安全にするものではありません。CLAUDE.md に書くだけでは、実行そのものは止まりません。guardrails を入れても、検査していない操作には効きません。permission で制限しても、人間が ask の確認を何となく許可してしまえば、危険な操作が進む可能性があります。approval を入れても、何を承認しているのか分からなければ、最後の確認として機能しません。
AIに作業を渡す前には、作業を3つに分けておきます。自動で進めてよい作業、人間に確認してから進める作業、AIに実行させない作業です。この仕分けをしておくと、どの操作を allow に入れるのか、どの操作を ask に入れるのか、どの操作を deny に入れるのかが決めやすくなります。
AI自動化の安全設計は、実装後に付け足すものではありません。業務整理や仕様整理の段階で、「この操作は読み取りだけか」「外部送信を伴うのか」「削除や公開が発生するのか」を確認しておく必要があります。この確認ができていれば、AIに任せる範囲を広げながら、削除、上書き、外部送信、公開操作のような危ない部分だけを止めやすくなります。
AIを安全に使う目的は、AIを動かさないことではありません。任せられる作業は進め、危ない操作は止め、最後に人間が見るべき操作だけ確認する。この分け方を作っておくことが、AIに作業を任せるための制約設計です。
関連記事
本記事と前後の文脈をつなぐ既存記事を以下にまとめます。AI 自動化シリーズとして読み合わせていただくことで、本記事の制約設計が「どの段階の判断か」を立体的に捉えていただけます。
- AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由 — AI 時代シリーズの起点として、本記事の前提となる「作業者ポジションのリスク」を整理しています。
- n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算 — approval なしの自動ループが課金暴走に直結する具体例として、構造と試算を整理しています。




