

ChatGPTやClaudeをブラウザで触ったことはあるけれど、「自分のPCでAIを動かす」という話になると一気にハードルが高くなります。ブラウザに文字を入れたら返事が返ってくる、という体験までは想像できても、「自分のパソコンの中でAIが動く」と聞いた瞬間に何が起きているのか分からない方は多いはずです。この記事は、その「分からない」を解消する入口として書いています。
ローカルLLMという言葉だけ見ても、何をするものか分かりにくいですよね。難しい用語で言われると身構えてしまいますが、整理してみると話はわりとシンプルでした。ふだんブラウザで使っているChatGPTやClaude、Geminiは「インターネットの向こうにあるAIに話しかけている」状態です。一方で今回扱うローカルLLMは、「自分のパソコンの中で動くAI」のことを指します。同じAIでも、動いている場所が違うわけです。
この記事はAI一般層の方向け入口シリーズの「ローカルLLM入口記事」として書いています。専門用語をなるべく使わず、できるだけ普段の言葉で進めます。先に出てくる名前だけ短く言い換えておくと、「Ollama」「LM Studio」は自分のPCでローカルLLMを動かすための道具です。「GPT-OSS」「Qwen」「Gemma」「Llama」は、その道具にダウンロードして動かせるAIファイル、と思ってください。それぞれの細かい違いは後の章でゆっくり整理します。
この記事を読むときの判断軸は2つだけです。1つ目は「自分の作業に役立つかどうか」、2つ目は「ChatGPTの代わりとして期待しすぎていないか」。この2つの目線で読み進めてもらえれば、ローカルLLMが自分にとって試す価値があるかどうかが見えてくるはずです。最初に見るべき画面や設定の話は出てきません。判断材料を揃えることだけに集中します。
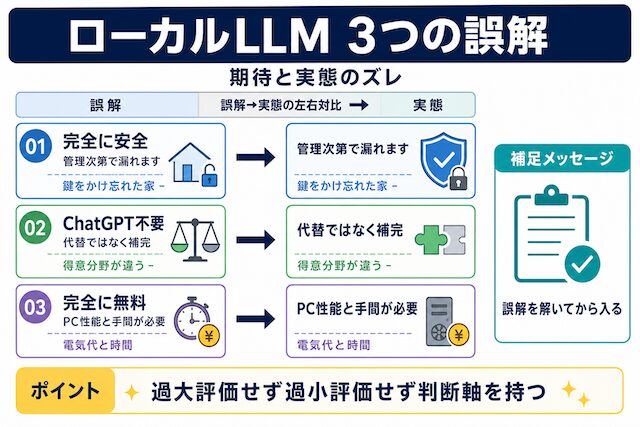
なお、本文では「ローカルLLMは絶対安全」「ChatGPTより優れている」「完全に無料」といった煽る話はしません。逆に「クラウドAIは危険」と脅すこともしません。手元で動かすことの利点と、手元では難しいことを並べて、自分の使いどころを判断できる状態を目指します。
ローカルLLMで迷う理由
「自分のPCでAIを動かせるらしい」と聞いて、便利そうだけど具体的に何ができるのか分かりにくいですよね。ここでは、ふだんブラウザで使っているChatGPTやClaudeとは別に、自分のPCで動くAI(ローカルLLM)について整理します。クラウドのAIサービスがブラウザで完結するのに対し、ローカルLLMは「自分のPCの中でAIを動かす」という別の使い方になります。
自分のPCでAIを動かせるという期待
自分のPCでもAIが動くらしい、と聞いて「便利そうだから試したい」と感じる場面が増えています。ここでは、その期待が具体的に何を指しているのかを整理します。
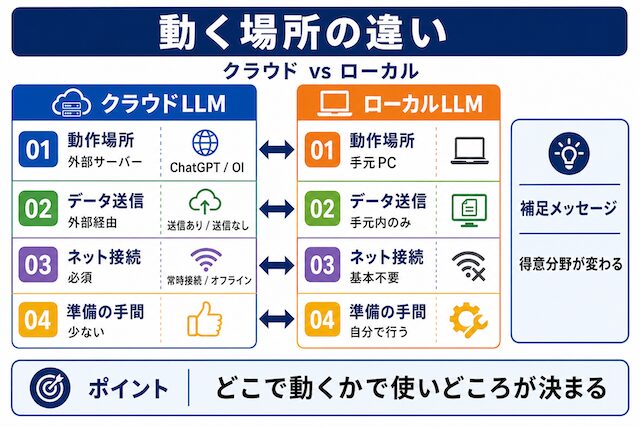
そもそも「自分のPCで動く」と聞いてピンとこない方も多いと思います。普段の使い方を思い返すと、ChatGPTもClaudeもブラウザを開いて入力欄に文字を打つ流れですよね。あの場合、入力した文章は一度インターネットを経由して外部のサーバーに届き、そこで返事が作られて画面に戻ってきます。ローカルLLMは、そのやりとりが自分のパソコンの中だけで完結する仕組みのことです。
つまり、ローカルLLMは「ネットの向こうのAI」を「自分の手元のAI」に置き換える話だと考えると、最初のイメージはつかみやすくなります。試したくなる気持ちの中身を分解すると、「機密の文章を外に出したくない」「ネットが繋がらない場所でも使いたい」「自分の作業に組み込みたい」あたりが多いはずです。この記事では、その期待のうち「現実的に応えられるもの」と「期待しすぎると挫折するもの」を分けて見ていきます。
ChatGPTの代わりになるという誤解
ローカルLLMはChatGPTの代わりになるのか、は一般層の方がいちばん気にしているところですよね。ここでは、両者を「同じもの」と捉えるとどこで止まるかを整理します。
結論から書くと、現時点ではChatGPTやClaudeの完全な置き換えにはなりません。ブラウザで使っているクラウドのAIは、巨大なサーバーで動く大きなAIです。一方、自分のPCで動かすAIは、家庭用のパソコンに収まる範囲のサイズになります。同じ「AI」と呼んでいても、扱える文章の長さや、難しい問いへの粘り強さが違ってきます。
「同じものの安いバージョン」と思ってしまうと、思っていた答えが返ってこないときに「壊れているのでは」「設定が悪いのでは」と止まりがちです。同じ役割を期待するのではなく、「得意な作業が違うAIがもう一種類ある」と捉えると、判断は楽になります。
動かすことと仕事に使えることの違い
PCで動かせることと、仕事に使えることは別の話です。ここでは、両者を分けて考える理由を整理します。
手順通りにダウンロードして起動すれば、ローカルLLMは案外あっさり動きます。ただ、動いたからといって、すぐに仕事の現場で使えるとは限りません。動かすところは「環境構築のゴール」で、仕事に使うのは「業務フローのスタート」だと考えると整理しやすいです。
動かしただけの段階で評価を決めてしまうと、「思ったほど賢くなかった」「結局ChatGPTでよかった」という感想で終わりやすくなります。逆に「どの作業に当てはめるか」を決めてから動かすと、向いている場面・向かない場面の判断がはっきりしてきます。この記事の後半は、その「当てはめどころ」の話に時間を使います。
ローカルLLMという手元で動かすAI
ローカルLLMという言葉だけ見ても、何をするものか分かりにくいです。簡単に言うと「自分のPCの中で動くAI」のことで、クラウド上のAIサービスに毎回送らずに手元で処理する考え方を指します。難しい技術用語を使わずに「どこで動くか」「何を手元で処理するか」という観点で整理します。
自分のPCやサーバーで動かすAI
ローカルLLMは、自分のPCや社内サーバーで動くAIです。クラウド上のAIサービスに毎回送るのではなく、手元の環境で処理する考え方を見ていきます。
イメージとしては、「いつもブラウザ越しに話していたAIを、自分の机の上の箱の中に住まわせる」感覚に近いです。ブラウザのAIに話しかけると、文章は一度外のサーバーまで旅をしますが、ローカルLLMの場合は自分のPCの中だけで会話が完結します。途中で外を経由しないので、ネットに繋がっていなくても返事が返ってきます。
会社で運用する場合は、自分の机のPCではなく、社内の共有サーバーに置く形もあります。いずれにしても「自分たちの管理下にある機械の中で動かす」点が共通しています。判断の入口としては、「外に文章を出すかどうか」「ネットがなくても動かしたいか」の2点で考えると分かりやすいです。
クラウドLLMとの基本的な違い
クラウドLLMとローカルLLMの違いは、突き詰めると「どこで動くか」「誰の環境で処理するか」に整理できます。一般層の方が判断しやすい違いだけを取り上げます。
クラウドLLMはサービス提供会社のサーバーの中で動きます。代表例がChatGPTやClaude、Geminiです。利用者は専用の画面に文章を入れるだけで、難しい準備はいりません。返ってくる答えの幅も広く、複雑な文章にも比較的柔軟に対応します。ただし、入れた文章はサービス提供側の環境を経由する前提になります。
ローカルLLMはその逆で、自分のPCや社内サーバーで動きます。動かすための準備は自分でする必要がありますが、入れた文章は手元の機械を出ません。ネット接続も基本的には不要です。代わりに、動かすPCの性能や、AIファイル自体のサイズに合わせた現実的な使い方を選ぶことになります。「どこで動くか」が変わると、「何が得意か」も変わってくる、と押さえておくと整理しやすいです。
AIの使い方を「サブスク (ChatGPTやClaudeの月額)」「API」「ローカル」の3区分で整理した記事として、ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある があります。本記事と合わせて読むと、自分の用途がどの区分に当てはまるかが見えやすくなります。
外部サービスに送らず処理する考え方
機密性のある文章を外部サービスに送ることに不安を感じる人にとって、手元で処理するという選択肢が登場した経緯を整理します。
仕事で扱う文章には、社外秘の議事録、顧客名簿、社内のチャットログのように、本来は外に出したくない情報が含まれます。ブラウザのAIに貼り付けて要約させたい場面はあっても、「機密情報を外部に送ってもよいのか」と立ち止まる方も多いはずです。手元のPCの中だけで処理できるなら、その不安はかなり軽くなります。
ただし、ここで気をつけたいのは「ローカルLLMだから絶対安全」とは言えない点です。PC自体が誰でも触れる場所にあったり、ファイルが整理されないまま残っていたりすれば、別の経路で情報が漏れる可能性は残ります。手元で処理する考え方は「外部に送らない選択肢を持てる」という意味で価値があり、それでも管理は必要、というのが現実的な見方です。判断軸としては、「外に出したくない文章を抱えているかどうか」を起点にすると分かりやすくなります。
ローカルLLMを動かす実行環境
OllamaやLM Studioという名前を聞いたとき、これがAIそのものなのか、AIを動かすための道具なのか分かりにくいですよね。ここでは、両者を「ローカルLLMを動かすための実行環境」として整理し、一般層の方が判断できる粒度で位置づけを見ていきます。
Ollamaの位置づけ
Ollamaは、コマンド操作中心の実行環境です。一般層の方に判断しやすい立ち位置を整理します。
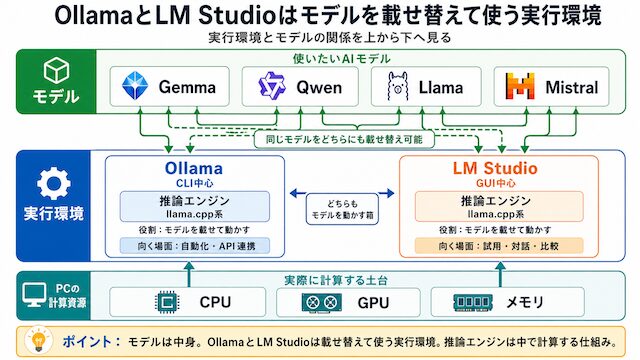
Ollamaという名前だけ見ると、AIそのもののように見えるかもしれません。中身としてはAIファイルを動かすための土台で、自動車に例えるなら「エンジンを載せる車体」に近い役割を持ちます。AIモデル自体は別に用意して、それをOllamaの上で動かす形です。
操作は基本的にコマンド入力が中心になります。普段ターミナル画面を触らない方にはやや敷居が高めですが、軽量で、別のプログラムから呼び出して使うのに向いています。「自動化や仕組み作りに組み込みたい」という方には、選択肢として残しておく価値があります。
LM Studioの位置づけ
LM Studioは、画面操作中心の実行環境です。一般層の方に判断しやすい立ち位置を整理します。
LM Studioは、Ollamaと同じく「AIモデルを載せて動かすための道具」です。違いは操作画面で、こちらはマウスで触れる普通のアプリ画面が用意されています。AIファイルを選んで、入力欄に文章を打って試す、という流れがブラウザのAIに近い感覚で進められます。
一般層の方が「まず触ってみたい」と感じている場合は、こちらから入ると挫折しにくい印象です。難しい設定を覚えなくても画面に従って操作できますし、複数のAIファイルを切り替えて試すのも簡単です。あとで自動化や仕組み作りに組み込みたくなった段階で、Ollamaに乗り換える流れもよくあります。
実行環境とAIモデルの違い
実行環境とAIモデルが別物だという区別がつかないと、何を選べばよいか判断できません。両者の役割の違いを整理します。
ここで一度、用語を整理しておきます。OllamaやLM Studioは「実行環境」、AIファイル本体は「モデル」です。実行環境は乗り物の本体、モデルはガソリンや積み荷のような関係に近いです。乗り物だけあっても走れず、積み荷だけあっても運べません。両者がそろって初めて動きます。
この区別がついていないと、「Ollamaを入れたのに頭が悪い」「LM Studioを変えたら賢くなるはず」といった迷い方になりやすいです。実際には、賢さに関わるのはモデル側で、実行環境はあくまで「動かすための器」です。選ぶ手順としては、「まず使う実行環境を1つ決める → その上に置くモデルを選ぶ」の順にすると、判断がぶれにくくなります。
代表的なローカルLLMモデル
GPT-OSSやQwen、Gemmaという名前を聞いても、それがサービスなのかモデルなのか分かりにくいですよね。ここでは、一般層の方が判断に使える粒度で、代表的なローカルLLMモデルの位置づけを整理します。
GPT-OSS・Qwen・Gemmaの位置づけ
GPT-OSS、Qwen、Gemmaはローカル環境で広く使われる代表的なモデルです。それぞれの位置づけだけを軽く整理します。
これらの名前を初めて聞くと、ChatGPTのようなブラウザサービスを連想する方もいると思いますが、いずれも「ローカルLLMとしてダウンロードして動かせるAIファイル」を指します。OllamaやLM Studioに読み込ませて使う、というイメージです。
一般層の方の判断としては、それぞれの細かい順位を覚える必要はありません。「公開されていて、手元で動かせる選択肢が複数ある」という事実を押さえておけば十分です。実際に試すときは、使っている実行環境の画面でおすすめされているものから入る形でも問題ありません。
Llama系モデルの位置づけ
Llamaはオープンに公開されている代表的なモデル系統です。ここでは「Llama系」という言葉が指す範囲を整理します。
Llamaは、ローカルで動かせるAIの中でも歴史が長く、派生したモデルが数多く存在します。「Llama系」と呼ばれるとき、本家そのものだけでなく、それをもとに別の組織や個人が調整したモデルも含まれることが多いです。日本語の扱いに強化されたもの、特定の分野向けに調整されたものなど、種類は幅広く存在します。
一般層の方が選ぶときは、「Llama本家」と「Llama系の派生」を厳密に区別しなくても困りません。実行環境のおすすめ一覧の中で、自分の用途 (例: 日本語の文章を整える) に合いそうなものを選ぶだけで、最初の試行には十分です。
性能比較より用途で見る考え方
性能ランキングや細かい比較で選ぼうとすると、一般層の方は止まりやすいです。ここでは、用途で見るという選び方を整理します。
ネット上には「どのモデルが最強か」を比べる情報がたくさんあります。情熱的な比較は読み物としては面白いのですが、一般層の方が最初に判断材料にするには情報が多すぎて、ほぼ確実に止まります。性能ランキングは半年で順位が入れ替わることも珍しくなく、追いかけ続ける作業自体に時間が取られます。
代わりに、「自分は何を任せたいか」から考えると判断が早くなります。日本語の議事録を要約したいのか、英文メモを分類したいのか、コードのちょっとしたメモを書かせたいのか。用途を先に決めて、実行環境のおすすめ一覧から1つ選んで試す。物足りなければ次の候補に切り替える。この流れの方が、一般層の方の入口としては現実的です。
ローカルLLMでできる作業
ローカルLLMを動かせたとして、何ができるのかが見えないと一歩を踏み出せません。ここでは、一般層の方が実際に手を動かす範囲で「できる作業」を整理します。
要約・分類・整形
要約、分類、整形のように「答えの正確性より作業補助が中心の用途」は、ローカルLLMの得意分野です。ここでは、代表的な作業を整理します。
長い文章を短くする要約、メールや問い合わせを種類ごとに振り分ける分類、箇条書きや一覧表に整える整形。これらは「最終的な品質より、下処理の手間を減らす」性質の作業です。多少不完全でも、人が最終確認すれば成立しますし、繰り返し量が多い分、自動化の恩恵が大きい領域でもあります。
ローカルLLMはこういった「正解が1つに決まらない、たたき台作り系の作業」に向いています。クラウドのAIに毎回送るほどではないが、自分で全部手作業でやるとしんどい、という中間の領域に居場所があるイメージです。
ログやメモの下処理
ログやメモなど、外部に出しにくい文章の下処理にローカルLLMを使うと、整形や分類の手間を減らせます。ここでは、代表例を整理します。
具体例として、サーバーのエラーログから要点だけ抜き出す、長い会議メモを節ごとに分けて見出しを付ける、雑に書いた走り書きを整った文に直す、といった作業があります。いずれも「中身は社外秘だが、整理だけはしたい」という性質を持っていて、外部AIに送るには気が引ける文章です。
手元で処理すれば、機密性を保ったまま下処理を進められます。返ってきた結果は完璧でなくて構いません。「人が最終チェックする前のたたき台」として使う前提で組むと、ローカルLLMの実力に合った業務設計になります。
クラウドLLMへ渡す前の準備
クラウドLLMに渡す前に、いったん手元で整形・分類・要約しておく使い方もあります。ここでは、その併用イメージを整理します。
クラウドのAIに長文をそのまま投げると、文字数の都合や品質のばらつきで思った結果が出ないことがあります。そこで、ローカルLLMで先に要約や分類をしてから、本当に判断が必要な部分だけクラウドのAIに渡す、という二段構えがあります。下処理を手元で済ませることで、外に出す情報を最小限に抑えられますし、クラウド側の利用量も減らせます。
この使い方は、後の「仕事で使うときの現実的な位置づけ」の章で詳しく取り上げます。ここでは「手元での下準備にローカルLLMを使う選択肢がある」とだけ覚えておけば十分です。
ローカルLLMが向いている場面
ローカルLLMがいちばん力を発揮するのは「外に出しにくい文章を、手元で整える場面」です。ここでは、向いている使い方を整理します。
外部に出しにくい文章の事前整理
外部サービスに送りたくない文章を、手元で要約や分類しておく使い方を整理します。
社外秘の議事録、顧客の問い合わせ履歴、まだ公開していない企画書のメモなど、扱いに気を使う文章は意外と多いです。これらを「整理だけはしたい」と思ったとき、手元で動くAIに任せれば、外部のサービスに渡さずに進められます。要約、見出し付け、不要部分の削除、箇条書きへの整形あたりが代表的な使い方です。
最終的な仕上げを人が確認する前提なら、品質が完璧でなくても作業時間は大きく短縮できます。社内の文書整理のような「地味だが量が多い」作業との相性は良好です。
定型処理やフォーマット変換
定型処理やフォーマット変換は、ローカルLLMが繰り返し処理しやすい得意分野です。代表的な業務を整理します。
たとえば、自由記述で書かれた問い合わせ内容を「対応カテゴリ」「優先度」「担当部署」に振り分ける処理、CSV形式の表をMarkdownの一覧表に直す処理、英文メモを日本語の要約に変える処理などが該当します。一度ルールを決めれば、繰り返し当てはめるだけで作業が進む種類の業務です。
こうした処理は、外部AIに毎回送るとコストが積み上がりやすく、社内データを外に出す不安も伴います。手元で動かすローカルLLMに任せると、コストの増減を気にせず数をこなせる利点があります。最初は1日ぶんから試して、納得できる結果が出るようなら範囲を広げる流れが現実的です。
検証環境でAI処理を試す用途
いきなり本番に投入する前に、検証環境でAI処理を試したい場面でローカルLLMが役立ちます。試し方の考え方を整理します。
「業務にAIを組み込みたいけれど、いきなり本番に出すのは怖い」という場面は多いです。クラウドのAIで試そうとすると、サンプルデータでもどこかに送信される前提が気になります。そこでローカルLLMの出番です。手元の環境で、本番のデータに似せた検証用データを使って、処理の流れや結果の傾向を確認できます。
検証の段階で「思ったほど精度が出ない」「想定外のパターンが多い」と気付ければ、本番運用に進む前に方針を見直せます。試験運用のための土台として、ローカルLLMはコストが追加で発生しない点も向いています。
ローカルLLMに向かない使い方
ローカルLLMを過大評価すると、期待と現実の差で挫折しやすいですよね。ここでは「向かない使い方」を一般層の方向けに整理します。
ChatGPTやClaudeと同じ品質への期待
ChatGPTやClaudeと同じ品質をローカルLLMに求めると、思った通りの回答にならず止まります。なぜそうなるかを整理します。
ブラウザで使うクラウドのAIは、巨大なサーバーの上で動いています。家庭用のPCに収まるサイズのAIと比べると、扱える情報の量や粘り強さに差があります。これは性能の優劣というより、サイズの違いから来る得意分野の違いに近い話です。
同じ品質を求めると、「やっぱり物足りない」と感じて手を引いてしまいがちです。判断軸を「同じ品質を出せるか」から「自分の作業の下処理に使えるか」に切り替えると、ローカルLLMの居場所が見えやすくなります。
最新情報調査や高度な判断の丸投げ
最新情報の調査や、複雑な判断の丸投げはローカルLLMには向きません。なぜそうなのかを整理します。
ローカルLLMが知っているのは、AIファイルが作られた時点までの情報です。新しいニュースを聞いたり、最近の制度変更を調べたりする用途には向きません。検索機能を内蔵しているわけでもないため、リアルタイムの情報源としては期待しないほうが無難です。
また、「全体方針を決めてほしい」「重要な意思決定を任せたい」といった丸投げにも向いていません。下処理や分類のように作業の一部を切り出して任せるのは得意でも、責任の重い判断を担わせると外れた答えを返す確率が上がります。仕事で使うときは、人間が判断する部分とAIに任せる部分の境目を先に決めてから組むのが安全です。
PC性能や運用負荷を無視した導入
PC性能や運用にかかる手間を考えずに導入すると、動かない・遅い・止まる結果になりやすいです。注意したいポイントを整理します。
ローカルLLMは、動かすPCの性能をそのまま使います。古いノートPCで重いAIファイルを動かそうとすると、返事が返ってくるまで長く待たされたり、途中で止まったりします。「動かないから諦めた」となる前に、自分のPCで現実的に動かせるサイズのAIファイルから試す、という発想が必要です。
また、AIファイルは数ギガ単位の容量があり、ディスク空き容量を圧迫します。複数試したくなって次々ダウンロードしていくと、すぐにストレージが満杯になります。動かすこと自体の負担と、保存容量の負担、両方を見越して始めると挫折しにくくなります。
このあたりの「現実とのギャップで疲れる話」は、個人開発の文脈ですが 個人開発でローカルLLMを主役にしなかった理由──クラウドLLMとの知能差・APIコストの誤解 にもまとめられています。実際に主役として運用しようとして直面したつまずきが書かれているので、合わせて読むと「向かない使い方」の解像度が上がります。
仕事で使うときの現実的な位置づけ
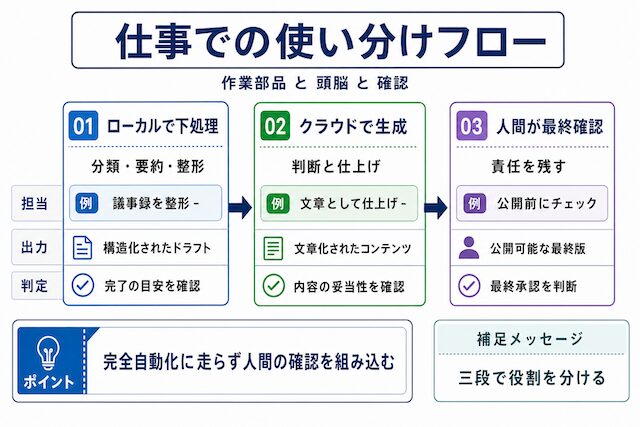
ローカルLLMを仕事で使うとき、ChatGPTの完全な代替として考えるのではなく「役割分担」として捉えると判断がしやすくなります。ここでは、現実的な位置づけを整理します。
クラウドLLMの完全な代替ではない
ローカルLLMはクラウドLLMの完全な代替ではありません。両者が補完関係であることを整理します。
「ChatGPTの代わりにローカルLLMを使えば、月額料金もデータ送信も不要になる」と期待したくなる気持ちは分かります。ただ、実際に置き換えてみると、複雑な相談、長い文章を踏まえた判断、最新情報を含む問い合わせなど、クラウド側が得意な領域がいくつも残っているのに気付きます。
そこで現実的な選択肢として出てくるのが、「両方を役割分担で使う」やり方です。完全な置き換えではなく、それぞれの得意分野を生かす形にすると、片方だけでは難しかった業務も回しやすくなります。
前処理・分類・整形に置く使い方
前処理・分類・整形はローカルLLMに置く、最終的な文章生成や判断はクラウドLLMに置く、という二段構成を整理します。
具体的なイメージは次のような流れです。手元の文書や問い合わせメモを、まずローカルLLMで分類・要約・整形しておきます。整形済みの素材から、本当にクラウド側の判断が必要な部分だけを抜き出し、ChatGPTやClaudeに渡します。最後に、返ってきた答えを人間が確認して使う。これが「作業部品=ローカル / 頭脳=クラウド」と呼んでいる二段構えです。
この設計のいいところは、外に出す情報を最小限に抑えられる点と、クラウド側の利用量が無駄に増えない点です。Beエンジニアでも、社内の下処理や分類はローカルで動かす運用を試しており、最終判断や仕上げの文章作成はクラウドのAIに任せる組み合わせで進めています。1社にとっての最適解は仕事内容によって変わりますが、二段構えの考え方自体は応用が利きやすい形です。
人間の確認を残す運用
ローカルLLMを使っても、最終的な確認は人間が担うのが安全です。なぜそうした方がよいかを整理します。
AIは下処理の自動化に向きますが、出てくる結果は常に正しいとは限りません。要約で重要な部分が落ちることもありますし、分類のラベルが期待と違うこともあります。クラウド側のAIに任せた最終出力にも、当然ながら見落としやハズレは出ます。
そのため、AIに任せる箇所と人間が確認する箇所の境目を、運用に組み込んでおくのが安全です。「AIが整えて、人が確認する」というシンプルな流れにしておけば、責任の所在が曖昧になりません。完全自動化に走らず、人間の確認をどこに置くかを最初に決めておくと、運用の安定度が上がります。
まとめ
ここまでで、ローカルLLMが「何のためのAIか」が見えてきました。一般層の方が判断に使える要点を、最後にまとめます。
ローカルLLMは手元で動かすAI
ローカルLLMは「手元で動かすAI」という1点を押さえれば、入口としては十分です。
クラウドのAIサービスは外部のサーバーで動き、ローカルLLMは自分のPCや社内サーバーで動く。この一行を押さえておけば、用語に振り回されずに話を読み進められます。OllamaやLM Studioは「動かす道具」、GPT-OSSやQwen、Gemma、Llamaは「動かすAIファイル」と分けて覚えておくと、誰かに説明する場面でも軸がぶれません。
使いどころは下処理・分類・整形
使いどころは「下処理・分類・整形」に集約されます。
要約、分類、整形、フォーマット変換、検証用の試運転、外に出しにくい文章の事前整理。いずれも「最終回答そのもの」ではなく「最終回答にたどり着くための作業の一部」です。ここを任せる前提で組むと、ローカルLLMの実力にかみ合った業務設計になります。
クラウドLLMと分けて考える必要
ChatGPTやClaudeと分けて考えると、判断がぶれません。
クラウドのAIとローカルLLMは、同じ「AI」でも得意分野が違います。完全な代替ではなく役割分担として捉え、「作業部品=ローカル / 頭脳=クラウド」の二段構えに、人間の最終確認を組み合わせる。この三つを軸にすれば、過大評価で挫折することも、過小評価で見送ることも避けられます。試したい場面が浮かんだら、まずは小さな範囲で動かしてみるところから始めてみてください。




