
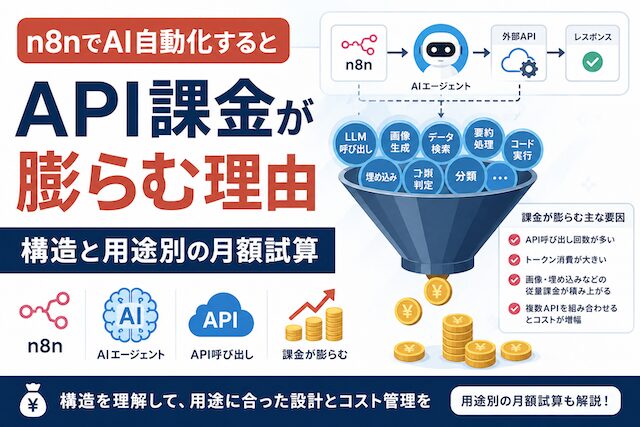
n8nを使って「Gmail分類を自動化したい」「ニュース要約を毎時回したい」と組み始めたところ、月末に届いた OpenAI や Anthropic の請求額を見て初めて「思っていた金額と桁が違う」と気付く。そんな経験をしている個人エンジニアや小規模事業者は少なくありません。n8n 自体の月額は数千円で済んでいるのに、AI API 側だけが数万円単位に跳ね上がっている、というケースが特に多く起きています。
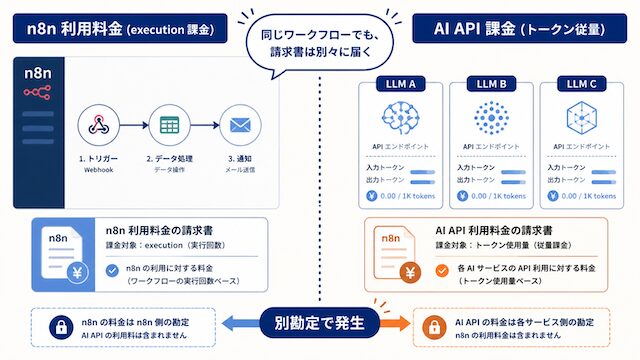
ここで多くの方が混乱するのは、n8n の execution 課金と AI API の従量課金が「同じワークフローを動かしているのに、まったく別の勘定で動いている」という構造です。さらに 1 execution の中で AI API が何回呼ばれるかは設計次第で大きく変わるため、n8n の execution 数だけを見ていてもコストはまったく読めません。この「読めなさ」が、自動化の楽しさと裏返しの不安を生んでいます。
この記事では、まず n8n と AI API の課金が別勘定であることを切り分け、その上で「1 execution ≠ API呼び出し回数」という構造を分解します。続いて月額 API 課金の計算式・モデル別単価・用途別×頻度別の試算表を一気に並べ、課金が膨らみやすい失敗パターンと、それを抑える設計を実装レベルで提示します。
最終的に読み終えたとき、あなたの手元に残るのは「自分のワークフローが月いくらになるかを概算できる計算式」と、「どこを締めれば桁単位でコストが下がるかという判断軸の地図」です。自動化を止めるのではなく、設計とコスト管理を前提に置いたうえで安心して回すための土台を作るのがこの記事のゴールになります。
n8nは安いのに、なぜAI自動化で月額が跳ねるのか
n8n は、ワークフローを GUI で組めるオープンソース寄りの自動化プラットフォームです。Cloud 版でも Starter プランは月額 €20 (年契約) で 2,500 executions/月、セルフホスト (Community Edition) なら本体無料で execution 数の上限もありません。これだけ見ると「自動化のインフラとしては十分安い」という印象を持つはずです。
しかし、ワークフローの中で OpenAI ノードや AI Agent ノードを呼んだ瞬間から、別の請求書が動き始めます。OpenAI、Anthropic、Google といった各 AI プロバイダーの API は、入力トークンと出力トークンの量に応じて従量課金されるため、n8n の月額とは独立して跳ね上がります。
この記事では、その「跳ね方」を構造として捉え直します。「使ってみたら高かった」を「事前に概算できる」へ変える地図を一緒に組み立てていきます。
結論:API課金が膨らむ5つの構造的理由
先に結論から共有します。n8n で AI 自動化を組むと API 課金が膨らむ理由は、次の 5 点に整理できます。
- n8n の execution 課金と AI API 課金は完全に別勘定で、n8n にいくら払っても AI API は別途従量課金が発生する
- 1 回の execution の中で AI API が複数回呼ばれる構造がある (AI Agent のツールループ、Memory による履歴累積、複数件の一括処理)。execution 数だけ見ても実際の API 消費は読めない
- モデル選択と実行頻度の組み合わせで月額が桁違いに変動する (同一処理で gpt-4o-mini と Claude Sonnet 4.6 で約 15 倍差、1 日 1 回と 1 分 1 回で 1,440 倍差)
- n8n 標準には API 課金の可視化機能が事実上ないため、動かして月末に各社の請求が来て初めて気付く
- Memory・AI Agent・フィルタなしフルテキスト送信が「便利な初期設定」のまま使われやすく、入力トークンが線形〜指数的に増える
n8n 料金と API 料金を混同したまま「1 日 1 回が 1 分 1 回になっても大した差はない」と感覚で運用すると、軽量モデルでも月数千円、上位モデルなら月数万円に跳ねます。自動化は楽になる手段ではなく、設計とコスト管理を前提とする仕組み、と捉え直す必要があります。
n8nの利用料金とAI API課金は別勘定
最初に押さえておきたいのは、n8n が提供しているのは「ワークフローを動かすプラットフォーム」だけだという点です。ワークフローの中から呼び出される OpenAI / Anthropic / Google などの AI API は、それぞれのプロバイダー側でトークン従量課金が別途発生します。
2026-05-08 時点の n8n 本体の課金は次の通りです。
| 区分 | 月額 (年契約) | execution 上限 | 備考 |
|---|---|---|---|
| n8n Cloud Starter | €20 | 2,500回/月 | 同時実行 5 |
| n8n Cloud Pro | €50 | 10,000回/月 | 同時実行 20 |
| n8n Cloud Business | €667 | 40,000回/月 | 同時実行 30 |
| n8n Community Edition (セルフホスト) | 無料 | 無制限 | Sustainable Use License、自社内部業務での商用利用可 |
セルフホスト版は本体が無料ですが、AI API は同様に別途課金されます。サーバー代 (VPS など) は別建てです。なお n8n の VPS 構築手順そのものはこの記事のスコープ外で、別記事「n8n を VPS に Docker + SSL で構築する手順」に分離しています。
ノード別に発生するAPI課金の出どころ
n8n の中で AI API 課金を発生させるノードと機能は、次のように分類できます。
| ノード/機能 | 発生する API 課金 | 注意点 |
|---|---|---|
| OpenAI ノード | OpenAI API トークン | プロンプト長・モデルで変動 |
| Anthropic ノード | Anthropic API トークン | Tool use 時はシステムトークンが追加 (Sonnet/Opus で約 346T) |
| Google Gemini ノード | Gemini API トークン | 無料枠超過後から課金 |
| HTTP Request ノード | 呼び出し先 API 次第 | OpenAI 互換エンドポイントを直接叩く場合 |
| AI Agent ノード | LLM API × ループ回数 | デフォルト Max Iterations = 10 |
| LangChain ノード群 (Tools / Memory / Vector Store) | 接続中 LLM のトークン課金 | 1 execution で複数回呼ばれる |
| Simple Memory ノード | 履歴分のトークンが入力に追加 | 履歴が増えるほど線形に増加 |
ここでまず「n8n のサブスクに入っているから AI 自動化もそのまま動く」という感覚を切り分けてください。サブスク型 (ChatGPT Plus 等) と API 型 (n8n から呼び出すもの) はそもそも別の課金体系です。この前提整理は別記事「AI の使い方は 3 種類ある:サブスク型・API 型・ローカル LLM 型」で詳しく扱っているので、まだの方はそちらを先に読むと位置付けがクリアになります。
1 execution ≠ API呼び出し回数
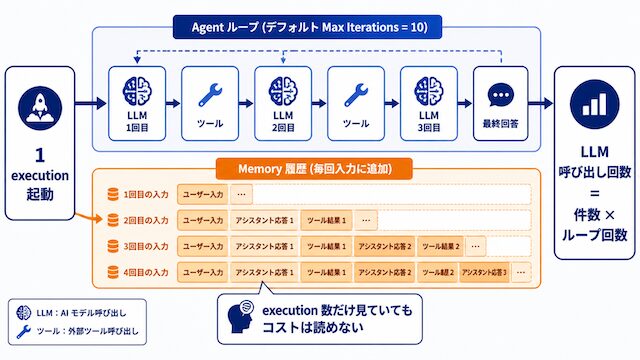
n8n の「1 execution」は、ワークフロー全体の 1 回起動を指します。1 execution の中で何回 AI API が呼ばれるかは、設計に依存します。ここを見落とすと、execution 上限内に収まっていても API 請求だけが膨張します。
バッチ件数でAPI呼び出しが線形に増える
例えば「1 日 1 回、Gmail 新着 30 通を分類するワークフロー」を組んだ場合を考えます。
- n8n execution: 1 回/日 (30 回/月)
- OpenAI API 呼び出し: 30 回/日 (900 回/月)
n8n Starter の 2,500 execution 上限から見れば余裕ですが、API 側では 900 回分のトークン課金が別途発生します。「1 execution = 1 API 呼び出し」と感覚的に思い込むと、ここで桁を 1〜2 個読み間違えます。
AI Agentのツールループで1 executionに4〜10回呼ばれる
n8n の AI Agent ノードは、デフォルトで最大 10 回のイテレーションまで内部ループします。3 つのツールを使うエージェントタスクでは、1 execution あたり最低 4 回以上の LLM 呼び出しが発生します。
ユーザー入力 → LLM (1 回目: ツール選択) → ツール実行
→ LLM (2 回目: 次手判断) → ツール実行
→ LLM (3 回目: 次手判断) → ツール実行
→ LLM (4 回目: 最終回答生成)
毎回の入力にはそれまでの会話履歴全体が含まれるため、後段ほど入力トークンが増えていきます。
Simple Memoryによる入力トークンの累積
Simple Memory ノードは Window Buffer Memory 方式で、会話履歴がウィンドウサイズ分だけ毎リクエストの入力に毎回送られます。
| ターン数 | 1 ターン入力トークン量 (仮定: 履歴 1 ターン 500T) | 基準比 |
|---|---|---|
| 1 | 500 | 1.0× |
| 5 | 2,500 | 5× |
| 10 | 5,000 | 10× |
| 20 | 10,000 | 20× |
バッチ処理や 1 回完結の変換系フローに Memory を入れると、不要なトークン累積が発生します。「とりあえず Memory ノードを繋いだ」状態で長期運用していないか、最初に確認してください。
API課金の基本式とモデル別単価
ここからは、月額 API 課金を概算する計算式と、主要モデルの単価を整理します。これがこの記事の中心パーツです。
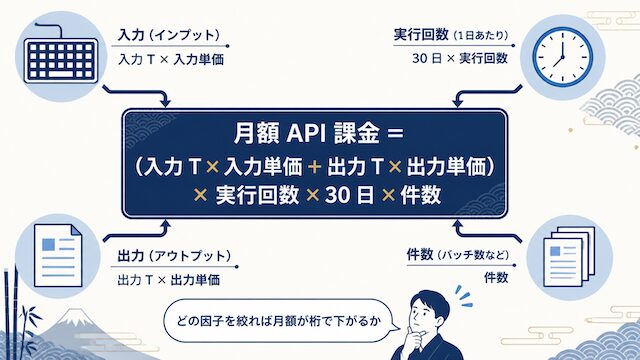
月額API課金の計算式
月額 API 課金は、次の式で概算できます。
月額 API 課金 = (入力トークン数 × 入力単価/1M + 出力トークン数 × 出力単価/1M) × 1日の実行回数 × 30 日 × 1 実行あたり処理件数
簡単な計算例として、gpt-4o-mini で Gmail 分類 (入力 500T・出力 50T・1 日 30 回実行) を回す場合を概算します。
入力: 500 × ($0.15 / 1,000,000) × 30 回 × 30 日 = $0.0675 出力: 50 × ($0.60 / 1,000,000) × 30 回 × 30 日 = $0.0270 月額: 約 $0.09 (約 14 円、概算)
参考までに primary 資料では出力 150T で「約 22 円/月」と試算されており、出力トークンの設計次第で月額は数倍動きます。出力単価は入力単価の 3〜5 倍が一般的なため、出力長の制御が効くかどうかでコストが大きく変わります。
主要モデル単価早見 (OpenAI / Anthropic / Gemini)
2026-05-08 時点の主要モデル単価は次の通りです (単位: $/1M tokens)。
| モデル | 入力 | 出力 | 備考 |
|---|---|---|---|
| gpt-4o | $2.50 | $10.00 | grandfathered |
| gpt-4o-mini | $0.15 | $0.60 | 軽量主流 |
| gpt-4.1 | $2.00 | $8.00 | 4o の後継として推奨 |
| gpt-4.1-mini | $0.40 | $1.60 | 中位 |
| gpt-4.1-nano | $0.10 | $0.40 | 最軽量 |
| o3-mini | $1.10 | $4.40 | 推論モデル軽量版 |
| Claude Opus 4.7 | $5.00 | $25.00 | 新トークナイザーで最大 35% トークン増 |
| Claude Sonnet 4.6 | $3.00 | $15.00 | バランス型 |
| Claude Haiku 4.5 | $1.00 | $5.00 | 軽量 |
| Gemini 2.5 Pro (≤200k) | $1.25 | $10.00 | 大コンテキストは $2.50/$15.00 |
| Gemini 2.5 Flash | $0.30 | $2.50 | 軽量バランス |
| Gemini 2.5 Flash-Lite | $0.10 | $0.40 | 最安、Batch でさらに半額 |
OpenAI の公式価格ページが調査時に直接取得しにくいタイミングがあるため、最終確認は公式サイトでお願いします。本記事末尾「参考資料」に各社の公式ページをまとめています。
割引機構 (Prompt Caching / Batch API)
主要なコスト割引機構として、次が利用可能です。
- Anthropic Batch API: 全モデル 50% 割引 (非同期処理)
- Anthropic Prompt Caching: キャッシュヒット時、入力単価の 10% (90% 割引)
- OpenAI Prompt Caching: gpt-4o 以降で自動適用、最大 90% 割引
- Gemini Batch / Flash-Lite の組み合わせ: 最安レンジ
「同じシステムプロンプトを毎回送っている」「即時応答を要求していない」のどちらかに該当するなら、これらの割引で月額を半分以下に圧縮できる余地があります。
用途別・頻度別の月額試算
ここから具体的な月額試算に入ります。以下の数値はすべて推定で、実際のプロンプト構成・モデル設定で大きく変動します。あくまで「桁感」を掴むための概算として扱ってください。
仮定したトークン量は次の通りです。
| 用途 | 入力 T | 出力 T | 仮定根拠 |
|---|---|---|---|
| Gmail 分類 | 500 | 50 | 本文 300T + システム 200T、ラベルのみ出力 |
| 問い合わせ返信下書き | 800 | 300 | 本文 + 指示、返信本文 |
| ニュース要約 | 1,500 | 200 | 記事本文 1,200T、3〜4 行要約 |
| 記事リライト候補抽出 | 3,000 | 500 | 記事全文 + 指示、改善箇所リスト |
| WordPress 記事下処理 | 4,000 | 800 | 長文記事 + 詳細指示、構造化出力 |
| Slack/Discord 要約通知 | 1,200 | 150 | チャンネル履歴 + 指示、3〜5 行通知 |
gpt-4o-miniを基準にした用途別試算
軽量モデルである gpt-4o-mini ($0.15/$0.60) を基準にした月額の概算は次の通りです。
| 用途 | 1 日 1 回 | 1 時間 1 回 | 10 分 1 回 | 1 分 1 回 |
|---|---|---|---|---|
| Gmail 分類 | $0.003 / 0.4 円 | $0.08 / 12 円 | $0.46 / 68 円 | $4.6 / 690 円 |
| 問い合わせ返信下書き | $0.005 / 0.8 円 | $0.13 / 20 円 | $0.77 / 115 円 | $7.7 / 1,155 円 |
| ニュース要約 | $0.009 / 1.3 円 | $0.21 / 31 円 | $1.26 / 189 円 | $12.6 / 1,890 円 |
| 記事リライト候補 | $0.016 / 2.4 円 | $0.38 / 57 円 | $2.3 / 345 円 | $23 / 3,450 円 |
| WP 記事下処理 | $0.021 / 3.2 円 | $0.51 / 76 円 | $3.0 / 450 円 | $30 / 4,500 円 |
| Slack/Discord 通知 | $0.007 / 1.1 円 | $0.17 / 25 円 | $1.0 / 150 円 | $10 / 1,500 円 |
Claude Sonnet 4.6に切り替えた場合の差
同じ用途を Claude Sonnet 4.6 ($3.00/$15.00) に切り替えると次のようになります。
| 用途 | 1 日 1 回 | 1 時間 1 回 | 10 分 1 回 | 1 分 1 回 |
|---|---|---|---|---|
| Gmail 分類 | $0.046 / 7 円 | $1.1 / 165 円 | $6.6 / 990 円 | $66 / 9,900 円 |
| 問い合わせ返信下書き | $0.077 / 12 円 | $1.8 / 270 円 | $11 / 1,650 円 | $110 / 16,500 円 |
| ニュース要約 | $0.138 / 21 円 | $3.3 / 495 円 | $20 / 3,000 円 | $200 / 30,000 円 |
| 記事リライト候補 | $0.244 / 37 円 | $5.8 / 870 円 | $35 / 5,250 円 | $350 / 52,500 円 |
| WP 記事下処理 | $0.312 / 47 円 | $7.5 / 1,125 円 | $45 / 6,750 円 | $450 / 67,500 円 |
| Slack/Discord 通知 | $0.107 / 16 円 | $2.6 / 390 円 | $15 / 2,250 円 | $150 / 22,500 円 |
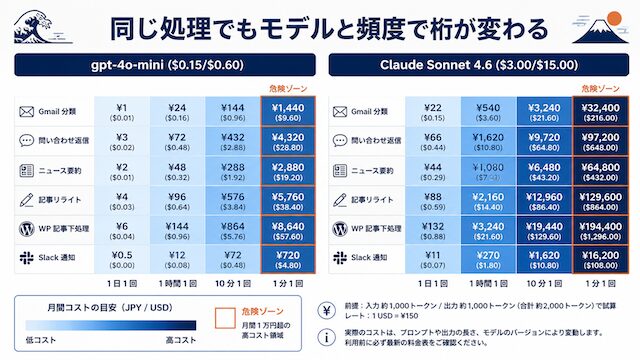
同じ Gmail 分類 (入力 500T・出力 50T) を「1 日 1 回」実行する条件で並べると、gpt-4o-mini が 0.4 円/月、Claude Sonnet 4.6 が 7 円/月で、約 17.5 倍の差になります。出力を 150T まで伸ばしてもう少し実運用に近づけた条件 (1 日 30 回相当) でも、gpt-4o-mini が約 22 円/月、Sonnet 4.6 がその約 14〜15 倍という桁感は変わりません。「同じ処理を Sonnet 4.6 にするだけで月額が約 15 倍になる」という肌感をまず覚えておいてください。
モデル × 頻度で月額が桁違いに変わる
ニュース要約 (入力 1,500T・出力 200T、Memory・Agent なしの単純フロー) を例に、頻度差を並べると次のようになります。
| 実行頻度 | 月間実行数 | gpt-4o-mini 月額 | Claude Sonnet 4.6 月額 | 月額差倍率 |
|---|---|---|---|---|
| 1 日 1 回 | 30 | $0.009 / 1.4 円 | $0.135 / 20 円 | 約 15× |
| 1 時間 1 回 | 720 | $0.21 / 31 円 | $3.24 / 490 円 | 約 15× |
| 10 分 1 回 | 4,320 | $1.26 / 189 円 | $19.4 / 2,910 円 | 約 15× |
| 1 分 1 回 | 43,200 | $12.6 / 1,890 円 | $194 / 29,100 円 | 約 15× |
頻度差: 1 日 1 回 → 1 分 1 回で 1,440 倍。モデル差: gpt-4o-mini → Sonnet 4.6 で約 15 倍。組み合わせで「1 日 1 回 / gpt-4o-mini」と「1 分 1 回 / Sonnet 4.6」では約 2 万倍の差 (1.4 円 vs 29,100 円) が生まれます。
課金が膨らみやすい失敗パターン
ここまでの試算は「最小構成」での話です。実運用で課金を跳ね上げる典型的な失敗パターンを見ていきます。
全文渡す / 不要メールまで読ませる
テストでは 500T だったメールが、本番では署名や引用込みで 18,000T を超えた事例も報告されています (出典: hatchworks)。広告メールや通知メールまで AI で読ませてしまうと、LLM 呼び出し回数自体が 3〜4 倍に膨らみます。
AI Agent Max Iterations放置とMemory全保持
AI Agent ノードの Max Iterations をデフォルト 10 のまま運用すると、1 execution で LLM が 5〜10 回呼ばれます。さらに Memory を「とりあえず全履歴保持」にすると、500 回/日の Agent で月 $400 の請求が来た事例もあります (出典: towardsai)。
n8n AI Agent ノードでは、Max Iterations を必要最小に絞るのが第一手です。設定例としては次の値を初期値として置き、実タスクの完了率を見ながら調整します。
n8n AI Agent ノード設定例: - Max Iterations: 2 (単純な単発分類タスクの場合) - Max Iterations: 3 (1 ツール呼び出し + 最終回答が必要な場合) - Max Iterations: 5〜7 (複数ツールを順に呼ぶ複雑タスクの場合のみ)
Memory についても、Simple Memory ノードのウィンドウサイズを次のように絞り込みます。
n8n Simple Memory ノード設定例: - Context Window Length: 3 (短い対話、直近 3 ターンで十分な用途) - Context Window Length: 5 (5 ターン程度の往復が必要な対話) - Memory ノード自体を外す (バッチ処理・1 回完結の変換系フロー)
「会話履歴が要らないのに Memory を繋いでいないか」を最初にチェックしてください。
max_tokens未指定と上位モデル一択
出力長が制御されないまま運用すると、出力単価は入力の 3〜5 倍であることが効いて課金が一気に跳ねます。さらに「分類でも整形でもとりあえず Sonnet / Opus」と上位モデル一択にすると、6 段階パイプライン全 Sonnet/Opus 化で月 $31,800 だった構成をモデル層最適化で $4,200 まで下げた事例も報告されています (推定・原典は事例報告)。
n8n の OpenAI ノードでは、max_tokens を必ず指定します。
n8n OpenAI ノード設定例: - Model: gpt-4o-mini - Temperature: 0.2 - Max Tokens: 200 (Gmail 分類でラベル出力する用途) - Max Tokens: 400 (ニュース要約 3〜5 行の用途) - Response Format: json_object (構造化出力で後処理を簡略化)
想定出力長 + 20% 程度で上限を切るのが目安です。出力暴走を物理的に止められます。
課金を抑える設計
失敗パターンの裏返しとして、課金を抑える設計を 1 本のフローで整理します。
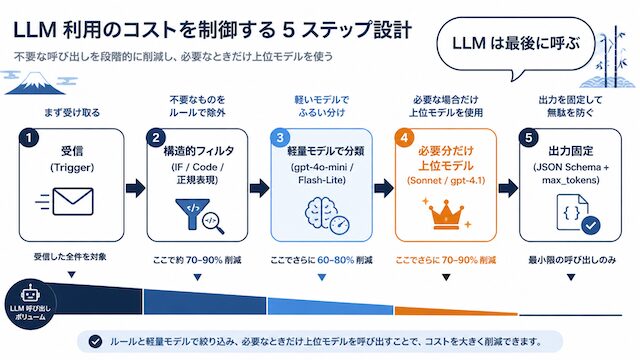
図 5: 受信 → 構造的フィルタ → 軽量モデル分類 → 必要分だけ上位モデル → 出力固定の流れ
前段フィルタ → 軽量モデル分類 → 必要分だけ上位モデル
最初に IF ノード・Code ノード・正規表現で構造的に絞り込み、属性 (差出人・件名・キーワード) で対象を限定します。次に gpt-4o-mini や Gemini Flash-Lite で重要度判定を行い、上位モデルが必要な対象だけ Claude Sonnet 4.6 や gpt-4.1 にルーティングします。
ある物流企業の事例では、この設計で処理対象を 72% 削減し、LLM 呼び出し回数を 1/3.6 に圧縮しています (出典: clixlogix)。「すべて LLM に投げる」のではなく「LLM は最後に呼ぶ」設計に倒すのが軸です。
定型分類 (3 ラベル前後の単純分類) はそもそも API ではなく、ローカル LLM (Ollama + Gemma3 / Qwen2.5 系) に寄せる選択肢もあります。Mac mini など対象ハードを既に持っている場合は実用圏に入りますが、新規購入が前提だと損益分岐に時間がかかります。詳細は別記事「AI の使い方は 3 種類ある」で前提を整理してから検討してください。
Prompt Caching / Batch API / 実行頻度の調整
同じシステムプロンプトを毎回送っているなら、Anthropic の Prompt Caching でキャッシュヒット時の入力単価を 10% (90% 割引) まで落とせます。Prompt Caching が効くシステムプロンプト構造は、次のように「変わらない部分」を先頭に固めて分離するのがコツです。
擬似コード: Anthropic Prompt Caching が効くシステムプロンプト構造
system_prompt = [
{
"type": "text",
"text": "<役割定義 + ルール + 出力フォーマット仕様>",
"cache_control": { "type": "ephemeral" } // ここまでをキャッシュ可能ブロックとして固定
},
{
"type": "text",
"text": "<参照ナレッジ・FAQ・社内辞書など、変動の少ない長文>",
"cache_control": { "type": "ephemeral" } // 2 つ目のキャッシュ可能ブロック
}
]
user_message = "<毎回変わる入力 (メール本文 / 記事本文など)>"
「変わる部分」と「変わらない部分」を物理的に分け、変わらない部分にキャッシュ制御を付けるのがポイントです。OpenAI の Prompt Caching は gpt-4o 以降で自動適用 (最大 90% 割引) のため、システムプロンプト先頭固定だけでも効果が出ます。
即時応答が要らないバッチ用途なら、Anthropic Batch API で 50% 割引が効きます。さらに「リアルタイム化が本当に必要か」を見直し、1 時間 1 回や 1 日 1 回のバッチに倒せるなら、頻度を下げるだけで月額が 1〜3 桁下がります。
出力形式固定とmax_tokens上限
JSON Schema や Structured Output で出力形式を固定し、max_tokens / max_output_tokens を必ず指定します。出力単価は入力の 3〜5 倍なので、出力長を絞れば絞るほど効きます。後処理 (Code ノードでのパース) も簡略化できる副次効果があります。
可視化と運用設計
設計を整えたら、最後に「請求書が来る前に気付ける」運用を仕込みます。
Track LLM costsテンプレで月末請求前に把握する
n8n コミュニティには「Track LLM costs and usage across OpenAI, Anthropic, Google and more」というワークフローテンプレートが公開されています。トークン消費とコストを Google Sheets に書き出して可視化する構成で、まずはこれをコピーして各ワークフローに挟むのが現実的です。
各社 (OpenAI / Anthropic / Google) の Usage ダッシュボードを定期確認するルーチンも合わせて回すと、月末請求で初めて知る状態を防げます。
ロギング・閾値アラートを最初から仕込む
n8n 標準には API 課金の可視化機能が事実上ないため、ロギング設計はワークフローを組む段階から入れる前提で考えてください。最低限、次の 3 点を最初の 1 ワークフローから仕込んでおくと、後追いコストが激減します。
- 各 LLM 呼び出しの input / output トークン数をログに残す
- 1 日あたりの推定コストを Google Sheets / DB に蓄積する
- 月間予算 (例: 5,000 円) を超えたら Slack / Discord に通知する
実装の参考としては、別記事「GA4 × n8n × GPT で記事リライト判定を自動化する」のフロー構成が、外部データを n8n で受けて Sheets に書き出す動線として近い形です。
ハマりどころ・注意点
最後に、運用に入る前に押さえておきたい注意点を並べます。
- AI Agent ノードは、ツールを呼ばないケースで token usage が出力されない既知問題があります (n8n Community Issue #178236)。ロギングで「数値が出ていない execution」を見落とさないでください
- サブワークフローを多用すると、親と子で別の execution としてカウントされるケースがあります (公式明記は確認できず、コミュニティ情報ベース)。n8n Cloud の execution 上限と AI API 課金の双方に効いてくるので、サブワークフロー化は構造化のメリットとコストを天秤にかけて判断してください
- Webhook トリガーでリトライ・ループ上限を入れていないと、例外時に無限ループで API を連打して請求が跳ねます。Webhook 重複処理で 20〜30% の execution が無駄になっていた事例も報告されています
- Anthropic Tool use ではシステムトークンが追加で約 346T 加算されます (Sonnet / Opus)。Tool 数が多い Agent では入力トークンが見かけより増えます
- Claude Opus 4.7 は新トークナイザーで最大 35% トークン増との報告があります。同じ文章でも入力トークン数が増えるため、Opus を使うときは試算を一段保守的に取ってください
- 為替変動の影響を忘れがちです。n8n Cloud はユーロ建て、各社 API はドル建てなので、円換算は月初と月末で数% 動きます
まとめ
整理し直すと、n8n × AI 自動化のコストを読むには次の順で考えます。
- n8n の execution 課金と AI API 課金を別勘定で切り分ける
- 1 execution の中で AI API が何回呼ばれるかを設計から逆算する (バッチ件数 × Agent ループ × Memory 履歴)
- 月額 API 課金 = (入力 T × 入力単価 + 出力 T × 出力単価) × 1 日の実行回数 × 30 日 × 1 実行あたり処理件数 で概算する
- モデル × 頻度の組み合わせで桁が変わることを意識し、「上位モデル一択 × 高頻度」を避ける
- 前段フィルタ → 軽量モデル分類 → 必要分だけ上位モデル + Prompt Caching / Batch / max_tokens で抑える
- ログと閾値アラートを最初から仕込み、月末請求で初めて知る状態を防ぐ
自動化はやめずに、設計とコスト管理を前提に置く。これが「動くものを作れた人」が次に進むためのステップです。
n8n は「API 型」の自動化に分類されます。サブスク型・API 型・ローカル LLM 型の違いをまだ整理していない方は、本記事の前提として次の解説記事を先に読むと、課金構造の位置付けがクリアになります。
参考資料
本記事の数値・事例の出典は次の通りです (2026-05-08 確認)。
n8n 公式・料金・仕様
- n8n Plans and Pricing
- New plan, no active workflow limits — n8n's new pricing explained
- Sustainable Use License | n8n Docs
- Community edition features | n8n Docs
- Executions | n8n Docs
- AI Agent node | n8n Docs
- Tools AI Agent node | n8n Docs
- LLM Tool Calling – n8n Blog
- Memory in AI | n8n Docs
- Simple Memory node | n8n Docs
n8n コミュニティ・テンプレート
- Token usage in AI Agent | n8n Community
- AI Agent token usage missing | n8n Community Issue #178236
- Track LLM costs across providers | n8n workflow template
- n8n AI Agent Memory Setup Guide 2026 | Towards AI
各社 LLM API 単価
- OpenAI API Pricing
- OpenAI API Pricing (developers.openai.com)
- Claude API Pricing | Anthropic
- Gemini Developer API Pricing | Google AI
- Gemini 2.5 Flash-Lite GA | Google Developers Blog




