
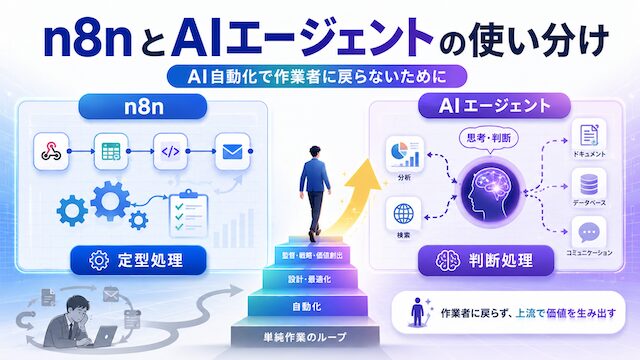
n8n を入れて自動化を組み始めたものの、結局自分が「実行ボタンを押す係」「結果を確認する係」「失敗をリカバリする係」に戻っている。AI エージェントを試したけれど判断の精度がぶれて毎回手直しが必要になり、自動化したはずなのに作業時間がむしろ増えている。そんな違和感を抱えている SES・社内 SE・業務系エンジニア・インフラ寄りエンジニアは少なくありません。
混乱の根は、n8n と AI エージェントを「どちらも自動化ツール」として横並びで比較してしまうところにあります。Anthropic / OpenAI / LangGraph / n8n 公式が揃って打ち出している立場は明確で、n8n は決まった処理を再現性高く回す道具、AI エージェントは曖昧な入力を文脈で判断する道具、そして人間は責任を伴う判断を引き受ける役、という三分割です。役割を混ぜると後で誰がどこを直すかが分からなくなり、自動化を組んだはずの本人が作業者ポジションに戻ります。
この記事では、n8n と AI エージェントを優劣で比較するのではなく、処理・判断・例外対応・責任分界の 4 観点でどこを誰に振るかという設計軸を提示します。ツール優劣論や Human Review の具体的な設定手順、ローカル LLM 文脈は本記事では扱いません。n8n / AI / 人間の三分割で、自動化を組んだのに作業者から抜けられない構造を一段抜けることに絞ります。
読み終えたときに手元に残るのは、自分の業務を 1 枚の役割分担表として書き出せる枠組みと、設計担当に回るために明日から手を付けられる入口です。手順実行で価値を出す側に残るのではなく、業務整理 / 責任分界 / 例外設計を引き受ける側に回るための地図として読んでください。
n8n と AI エージェントは別の道具です
「n8n を入れたら自動化できる」「AI エージェントを使えば全部判断してくれる」と一括りに語られがちですが、両者は同じ自動化ツールではありません。役割が違うため、混同したまま設計すると壊れやすい仕組みになります。本セクションでは最初に両者の輪郭を分けます。
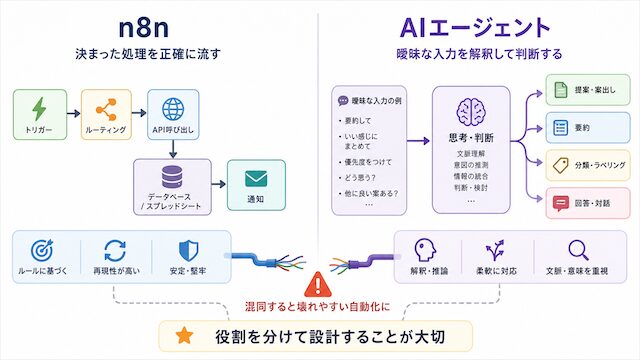
n8n は決まった流れを実行する道具です
n8n はワークフロー実行基盤として、決まった入力・処理・分岐を再現性高く実行します。判断主体ではなく、処理を固定して回す場所です。
たとえば毎朝 8 時に Gmail を取得して、件名に特定文字列が含まれていれば Slack に通知し、含まれていなければ Google Sheets に追記する、といった「条件と動作が事前に決まっている流れ」を回すのに向いています。決定論ノード (Webhook / Cron / IF / Switch / API 呼び出し / 失敗時のリトライ) を組み合わせて、同じ入力からは同じ出力が返るところに価値があります。
n8n に「文章の内容を読み取って判断してほしい」「曖昧な入力を分類してほしい」を直接書き込もうとした瞬間、ノードの分岐が爆発して保守不能になります。n8n はあくまで「決まった流れを再現性高く実行する」場所であり、判断主体ではない、と最初に言語化しておきます。
AI エージェントは曖昧な入力を判断する道具です
AI エージェントは入力が定型化しきれない場面で、文脈を読んで分類・要約・次の行動の選択を行います。Anthropic / OpenAI / LangGraph の公式定義はいずれも「動的に判断する主体」として整理しています。
具体的には、自然言語の問い合わせメールを 5 つのカテゴリに振り分ける、長いニュース記事から重要な変更点だけを抜き出して 200 字に要約する、過去のやり取りを踏まえて返信下書きを作る、といった「入力の形が毎回違う」「答えが一意に決まらない」場面に向いています。ワークフロー (固定パス) と区別して、エージェント (動的判断) と呼び分ける整理が公式の立場です。
裏返すと、AI エージェントに「毎朝 8 時に Gmail を取得する」「指定 API を呼び出す」のような決定論的な処理を任せると、再現性が落ちて運用コストが跳ねます。AI エージェントは判断のための道具であって、処理のための道具には向きません。
同じものとして扱うと自動化は壊れます
n8n に AI 判断を詰め込みすぎるとメンテナンス不能になり、AI エージェントに定型処理を任せると再現性が落ちます。役割を混ぜると、後で誰がどこを直すかが分からなくなります。
「n8n の中で AI ノードを呼んでいるから AI エージェントを組んでいる」「AI に全部任せれば n8n は不要」のような単純化は、後で必ず作業者ポジションに戻る原因になります。両者は対立する選択肢ではなく、組み合わせて使う前提の別の道具です。次のセクション以降、組み合わせ方の設計軸を整えていきます。
自動化は処理・判断・例外・責任分界を分けて設計します
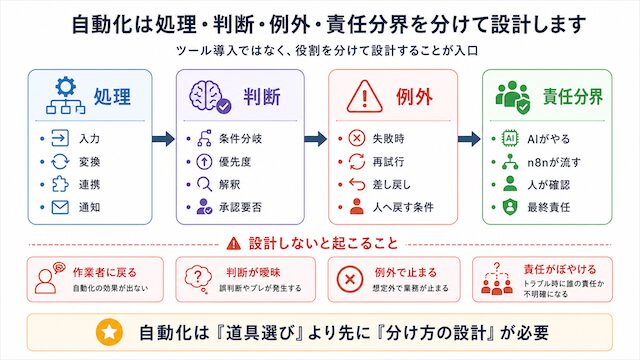
自動化を「ツール導入」として捉えると、必ず作業者に戻ります。自動化は処理・判断・例外対応・責任分界を分けて設計する仕事です。本セクションでは設計の入口を整えます。
入力・処理・判断・出力・失敗時対応の 5 層で書き出す
業務を 5 層に書き出すと、どこに何を置くかが見えます。n8n に向くのは処理と出力、AI に向くのは判断と一部の曖昧な入力解釈、人間に残すのは例外対応と最終判断です。
たとえば「Gmail 分類」「ニュース要約」「記事下書き」を 5 層で書き出すと、次のように振り分けが見えてきます。
| 業務 | 入力 | 処理 | 判断 | 出力 | 失敗時対応 |
|---|---|---|---|---|---|
| Gmail 分類 | Gmail からの新着取得 (n8n) | カテゴリ振り分けの実行ルート (n8n) | カテゴリ判定と要約 (AI) | Slack / Sheets への書き込み (n8n) | 信頼スコアが低い案件を Human Review に回す (n8n + 人間) |
| ニュース要約 | RSS / API からの記事取得 (n8n) | 取得結果の整形・重複排除 (n8n) | 重要箇所の抽出と 200 字要約 (AI) | Notion / Sheets への書き込み (n8n) | 取得失敗時の再実行と通知 (n8n) |
| 記事下書き | テーマ・参考資料の収集 (n8n + 人間) | 構成テンプレ適用 (n8n) | 見出し案・本文ドラフト生成 (AI) | ドラフトの保存 (n8n) | 公開判断は人間ゲート (人間) |
5 層を書き出さないまま「AI に投げよう」「n8n でつなごう」と進めると、後で例外が出たときに誰がどこを直すかが決まっておらず、結局自分が全部見ることになります。設計の最初の一歩はここです。
役割分担 10 軸表で自業務を当てはめる
固定手順 / 判断 / 再現性 / 失敗影響 / 入力曖昧度 / 出力検証 / 人間承認 / 業務フロー運用 / 作業者に戻る危険 / 自立につながるか の 10 軸で自業務を採点すると、振り分け先が決まります。
下記は n8n / AI エージェント / 人間に振るべき軸を整理した一覧です。自分の業務がどの列の特徴に近いかで振り先を決められるようにしています。
| 軸 | n8n に向く | AI エージェントに向く | 人間に残す |
|---|---|---|---|
| 固定手順 | 手順が固定で書ける | 手順が毎回変わる | 手順自体を再設計する判断が要る |
| 判断 | 判断は条件分岐で書ける | 文脈を読む必要がある | 責任を伴う最終判断 |
| 再現性 | 同じ入力から同じ出力 | ばらつきが許容される | 一回性のある合意形成 |
| 失敗影響 | 失敗してもロールバック可 | 失敗しても再実行可 | 失敗が不可逆な処理 |
| 入力曖昧度 | 入力が定型化できる | 入力が定型化しきれない | 入力自体を整理しないといけない |
| 出力検証 | スキーマで自動検証できる | 構造化出力 + サンプル検証 | 公開・送信前の人間チェック |
| 人間承認 | 不要 | 信頼スコアで分岐 | 公開・受注・課金・削除前は必須 |
| 業務フロー運用 | スケジュール / 再実行 / 監視に強い | 定型運用は弱い | フロー自体の見直し判断 |
| 作業者に戻る危険 | 低 (固定処理に閉じる) | 中 (検証なしだと毎回確認に戻る) | 設計次第で高にも低にもなる |
| 自立につながるか | 単独では自立しにくい | 単独では自立しにくい | 業務整理・責任分界・例外設計が自立につながる |
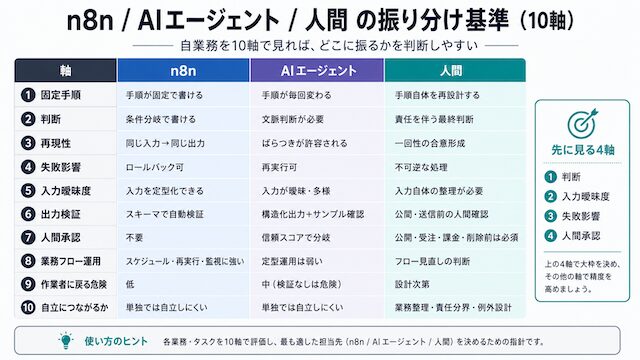
10 軸全部を毎回採点する必要はありません。判断 / 入力曖昧度 / 失敗影響 / 人間承認 の 4 軸だけ先に当てると、振り分けの 8 割が決まります。
シンプルで済むなら LLM を使わないのが公式の立場です
Anthropic「Building Effective Agents」/ OpenAI「A Practical Guide to Building Agents」/ LangGraph 公式 / n8n「Production AI Playbook」は揃って「シンプルな解決策で済むなら LLM を使うな」と書いています。ベンダー利益と逆方向の主張です。
決定論で書ける処理を AI に任せると、再現性が落ちる・コストが上がる・例外が増える・運用負荷が跳ねる、の 4 つが同時に起きます。AI を使う前に「ここは IF 分岐で書けないか」「正規表現で抽出できないか」「スキーマ検証で済まないか」を確認する順番を、設計の前提に置きます。
入力検証 (必須フィールド・PII・インジェクション検出) → AI 判断 → 出力スキーマ検証 → 信頼スコア分岐 → 人間ゲート、というハイブリッド構造を後ろのセクションで擬似コードとして示します。AI を中心に置くのではなく、決定論の前後で AI を挟む設計が、公式の立場とも揃います。
n8n に任せる処理と AI エージェントに任せる判断
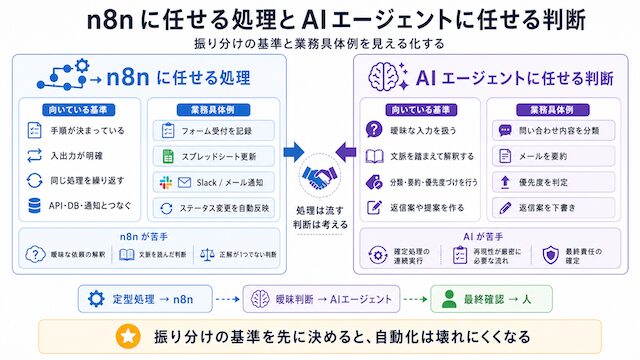
役割を分けたら、それぞれの向き・不向きを具体化します。本セクションは振り分けの基準と業務具体例を扱います。
n8n に向く処理 (時刻・API・分岐・連携・再実行)
決まった時刻に実行する、決まった API から取得する、条件で分岐する、Slack / Discord / Gmail / Google Sheets に渡す、成功・失敗・再実行を管理する。これらは n8n の決定論ノードで組むほうが、再現性も運用負荷も低くなります。
具体的には、Cron / Webhook / HTTP Request / IF / Switch / Set / Merge / エラートリガー / リトライ設定が n8n の主戦場です。これらは「同じ入力から同じ出力が返ること」が前提のノード群で、テストもしやすく、失敗時のロールバックも明示的に組めます。AI を挟まず n8n だけで完結できる部分は、極力 AI を挟まない方が、後の保守と監視が軽くなります。
n8n の強みは「処理を固定して再現性高く回す」ところであって、「文脈を読んで判断する」ところではありません。判断を n8n の IF / Switch だけで書こうとして分岐が爆発し始めたら、その判断は AI エージェントに振るべき領域です。
AI エージェントに向く判断 (文脈・曖昧分類・たたき台)
文脈を読む、曖昧な文章を分類する、下書きを作る、判断材料を整理する、Claude Code への指示文を作る、人間が判断する前のたたき台を作る。これらは AI に任せたほうが、自分の手間が大きく減ります。
たとえば、問い合わせメールを「見積依頼 / クレーム / 採用問い合わせ / 営業案内 / その他」の 5 つに振り分けるとき、件名や本文の表現は毎回違います。これを n8n の IF / Switch で正規表現を積み上げて書くと、想定外の言い回しが来た瞬間に分類が外れます。文脈を読む必要があるのなら、AI エージェントに「カテゴリ + 信頼スコア + 根拠」を構造化出力で返させるほうが、保守性も精度も安定します。
ただし AI エージェントを「最終判断者」にしてはいけません。AI には判断のたたき台を作らせ、最終的な公開・送信・課金・削除のような不可逆処理は人間または明示的な人間ゲートが押す、という構造で組むのが公式の立場です。
業務具体例で振り分けてみる (Gmail / 要約 / 記事下書き / Claude Code 指示)
Gmail 分類 / ニュース取得と要約 / ブログ記事設計 / 問い合わせ返信下書き / cc-wiki のようなナレッジ蓄積 / Claude Code への作業指示生成 / n8n でのスケジュール実行 / AI による分類補助、それぞれを処理側と判断側に振り分けます。
下記は具体例の振り分けです。
| 業務 | n8n 側 (処理) | AI 側 (判断) | 人間側 (責任) |
|---|---|---|---|
| Gmail 分類 | 取得・カテゴリ別書き込み・通知 | カテゴリ判定・信頼スコア付与 | 低スコア案件のレビュー |
| ニュース要約 | RSS / API 取得・整形・保存 | 重要箇所抽出・200 字要約 | 公開可否の判断 |
| 記事下書き | 参考資料収集・構成適用・保存 | 見出し・本文ドラフト生成 | 公開判断 |
| 問い合わせ返信下書き | 受信トリガー・送信処理 | 返信文面ドラフト生成 | 送信前レビュー |
| ナレッジ蓄積 | 取り込み・整形・索引化 | カテゴリ分類・要約 | カテゴリ体系の設計 |
| Claude Code への作業指示 | 入力フォーマット整形・保存 | 指示文ドラフト生成 | 指示の最終確定 |
実装レベルの具体例として、GA4 と n8n と GPT を組み合わせてリライト対象記事を自動抽出する構成は 【AI編集長】GA4×n8n×GPTでリライト記事を自動抽出する構成記録(前編) にまとめています。本記事は設計原則の上位レイヤを扱うため、実装記録はそちらを参照してください。
ここで強調したいのは、振り分けの軸は「n8n でできるか / AI でできるか」ではなく「処理か / 判断か / 責任を伴うか」という 3 軸であるという点です。「できるかどうか」で考えると n8n にも AI にも何でも書けてしまうため、判断軸を「向いているか / 残すべきか」に置き換えます。
人間が残す判断と「作業者に戻る」5 + 1 パターン

自動化は人間を消すための仕組みではなく、人間が残す判断を絞り込むための仕組みです。本セクションでは残すべき判断と、自動化したのに作業者に戻ってしまう構造を扱います。
人間に残すべき判断 (公開・受注・責任を伴う停止判断)
最終判断 / 仕様確定 / 公開判断 / 受注判断 / 責任を伴う判断 / 失敗時の停止判断。責任が発生する場所は人間に残します。AI に渡すべきではない判断を切り分けることが、自動化設計の土台になります。
具体的には、ブログ記事の公開ボタン、見積回答の送信、受注可否の返答、課金処理の確定、データの削除、対外的な謝罪文の送信、業務停止の判断は、すべて人間ゲートを通します。これらは失敗したときに取り戻せない (不可逆) 処理であり、AI の信頼スコアが高くても自動実行に回さないのが安全側の設計です。
不可逆処理を人間ゲートで止めることは「AI を信じていないから」ではなく「AI に責任を取らせる構造になっていないから」です。責任を取れる立場の人が最終判断を押す、という構造を崩さないことが、自動化を長く回すための前提になります。
作業者に戻る 5 + 1 パターン (モニタリング不足・例外人手集中ほか)
モニタリング不足 / 例外人手集中 / 例外所有者不在 / 単一エージェント依存 / 委譲過剰 / プロンプト管理不在。これらが揃うと、自動化を組んだのに自分が確認・修正・実行係に戻ります。
それぞれが何を意味するかを並べます。
- モニタリング不足: 自動化が裏で何をしているか観測できておらず、毎回手元で確認しないと不安になる。結果として「実行ボタンを押してから結果を覗きに行く係」に戻る。
- 例外人手集中: 例外が出るたびに自分が一次受けして対応している。ルーティングが組まれていないため、例外件数が増えると自動化全体が止まる。
- 例外所有者不在: 例外を「誰が」「いつまでに」「どう処理するか」が決まっていない。グレーゾーンに落ちた案件が手元に積み上がる。
- 単一エージェント依存: 1 つの AI エージェントに全部任せている。1 ヶ所のモデル変更や仕様変更で全体が止まる。
- 委譲過剰: 本来人間が判断すべき公開・送信・課金・削除を AI に渡している。事故が起きると後始末に時間が取られ、結局手動運用に戻す。
- プロンプト管理不在: プロンプトをコードで管理しておらず、いつ誰が変更したかが追えない。挙動が変わったときに原因が特定できず、結局毎回出力を目視確認する。
このうち 1 つでも当てはまる自動化は、すでに作業者ポジションが残っています。6 つ全部当てはまっているなら、自動化を組み直す前に設計を見直す段階です。
「自動化したのに後始末が増えた」が起きる構造
人間が毎回確認しないと動かない構造は、自動化ではなく作業補助です。仕組みに見える形でも、判断と例外の所有者が決まっていないと作業者ポジションは残ります。
たとえば、AI が分類した結果を毎回自分が目視確認してから Slack に転送している場合、自動化されているのは「取得」と「転送」だけで、判断と例外対応は自分が引き受けています。これは自動化ではなく、自動化に見える作業補助です。後始末が増えたと感じる場面の多くは、判断と例外の所有者が決まっておらず、グレーゾーンに落ちた案件を本人が引き受けているケースです。
抜けるための条件は、判断には信頼スコア + 人間ゲート、例外には所有者 + ロールバック、を設計時点で組み込むことです。次のセクションで 6 つの設計原則として整えます。
作業者に戻らない 6 つの設計原則
5 + 1 のパターンを避けるための設計原則を 6 つの形で提示します。読者が自分のフローに当てはめてチェックリスト化できる形にします。
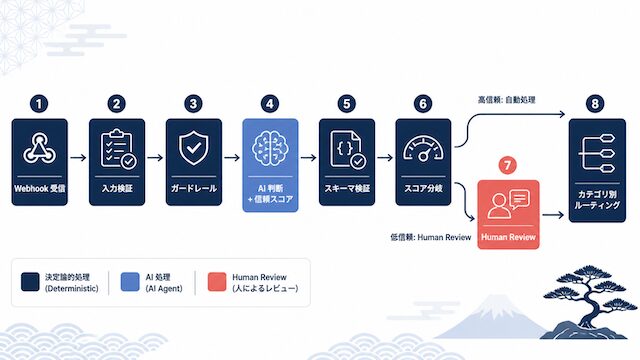
下記は本記事で前提に置く擬似コードです。n8n の決定論ノードと AI エージェントを組み合わせた、ハイブリッド設計の最小骨格として読んでください。
# ハイブリッド設計フロー (擬似コード)
on webhook(payload):
# 1. 入力検証 (n8n: 決定論)
assert required_fields_present(payload)
assert no_pii(payload)
assert no_prompt_injection_pattern(payload)
# 2. AI 判断 (AI エージェント: 動的判断)
result = ai_agent.classify_and_draft(payload)
# result は構造化出力: {category, draft, confidence_score, evidence}
# 3. 出力スキーマ検証 (n8n: 決定論)
assert schema_valid(result)
# 4. 信頼スコア分岐 (n8n: 決定論)
if result.confidence_score >= HIGH_THRESHOLD:
# 5a. 自動処理 (n8n: 可逆処理に限定)
execute_reversible_action(result)
else:
# 5b. Human Review ゲート
review = human_review.request(result)
if review.approved:
execute_action(result)
else:
notify_agent_with_feedback(result, review)
route_to_exception_owner(result, review)
# 6. カテゴリ別ルーティング (n8n: 決定論)
route_by_category(result.category)
この骨格を前提に、6 つの設計原則を並べます。
可逆処理は自動化、不可逆処理は人間ゲートで止める
取り戻せる処理は自動化、取り戻せない処理 (公開 / 送信 / 課金 / 削除) は人間ゲートで止める。Anthropic は「介入できる立場が監視」と表現し、これを設計の前提に置いています。
可逆処理の例: ステージング環境への保存、下書きの追記、Slack の自分専用チャンネルへの通知、Sheets への追記。これらは間違っていてもロールバックや訂正で済みます。
不可逆処理の例: 公開ボタンの押下、対外送信、課金確定、データ削除。これらは間違うと取り戻せないため、AI の信頼スコアが高くても人間ゲートを通します。
「AI が高精度だから自動でいい」ではなく「失敗が不可逆かどうかで分ける」という置き方が、長く回せる自動化の最初の原則です。
例外所有者を明示し監視・介入・ロールバックを事前に置く
検出 / 通知 / ルーティング / タイムアウト / ロールバック / 学習ループ の 6 要素を、設計段階で誰が持つかを決めます。無主のグレーゾーンは作業者ポジション固定の温床になります。
具体的には、例外が出たときに「誰の Slack に通知するか」「何分以内に対応するか」「対応されないときに誰にエスカレーションするか」「どこまで巻き戻すか」「同じ例外が再発しないように何を学習させるか」を、設計時点で書き出して合意しておきます。これが書かれていない自動化は、例外が出るたびに最も近くにいた人 (多くの場合は組んだ本人) に集中します。
例外所有者は AI ではなく人間で持ちます。AI に「例外を判断して対応する」を任せた瞬間、責任の所在が曖昧になり、不可逆処理に踏み込んだときに後始末が誰の手元にも残らなくなります。
Human Review は設計の失敗ではなく公式機能として使う
n8n は 2025 年に Human-in-the-loop のツール呼び出し承認機能を公式実装しました。Human Review を挟むことは設計の失敗ではなく、公式ベンダーが推奨する設計パターンです。
「Human Review を入れたら自動化じゃない」という捉え方は、自動化の定義を狭く取りすぎています。実務で長く回る自動化は、信頼スコアが高い案件だけを自動処理し、低い案件を Human Review に回す構造を最初から設計に含んでいます。これは「人間を消すための仕組み」ではなく「人間が見るべき案件だけを上げてくる仕組み」を作る設計です。
Human Review を公式機能として組み込んだ瞬間に、自動化の品質と、人間の判断対象の絞り込みが両立します。設計の失敗どころか、設計が成立した形と捉えてください。
設計担当に回るために、明日から手を付けられること
設計を語れても自分の業務に当てはまっていないと意味がありません。本セクションは読み終わった直後に手を動かせる入口を提示します。
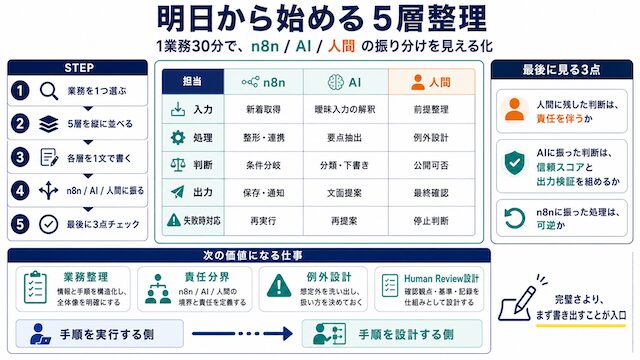
自分の業務を 5 層で書き出して振り分ける
1 ページに 入力 / 処理 / 判断 / 出力 / 失敗時対応 を書き出し、それぞれを n8n / AI / 人間に振ります。1 業務 30 分で十分です。手を動かすまで設計は身につきません。
書き出し方の手順は次のとおりです。1 つの業務を選ぶ。5 層の見出しを縦に並べる。各層に何が起きているかを 1 文ずつ書く。横に「n8n / AI / 人間」の列を作って当てはめる。最後に「人間に残した判断は本当に責任を伴うものか」「AI に振った判断は信頼スコアと出力検証が組めるか」「n8n に振った処理は可逆か」をチェックする。これだけで、自動化の入り口が見えます。
最初は完璧に振り分けようとしないでください。1 業務 30 分で粗く書き出して、半分は AI に振れる、半分は n8n に振れる、と気づくところまで来れば十分です。書き出さないと頭の中だけで混ざり続けます。
業務整理・責任分界・例外設計が次の価値になる場所
手順実行で価値を出す時代は終わりつつあります。エンジニアが残せる価値は、業務整理 / 責任分界 / 例外設計 / AI 採否判断 のような「自動化を成立させる側」の仕事です。
裏返すと、5 層振り分け / 役割分担 10 軸 / 例外所有者 6 要素 / Human Review ゲート設計を引き受けられる人は、これからの数年で希少な役回りになります。手順を覚えて再現する側ではなく、手順を設計する側に回るほうが、AI の進化と相反しません。
自動化を組んだのに作業者から抜けられないと感じている方には、業務整理から自動化設計までを一度第三者と整理することをおすすめします。本記事で扱った設計フローと責任分界の整理を主訴に、Beエンジニアのお問い合わせフォームよりご相談ください。相談時には、業務整理 / AI 自動化設計 / n8n フロー設計 / Claude Code 指示設計 / 仕様整理 のいずれの入口からも入れる形で受け付けています。
まとめ
n8n と AI エージェントは別の道具です。処理・判断・例外・責任分界を分けて設計し、人間が残す判断を絞り込むことで、自動化したのに作業者に戻る構造から抜けられます。本記事では、役割分担 10 軸表 / 5 層振り分け表 / ハイブリッド設計フロー / 作業者に戻る 5 + 1 パターン / 6 つの設計原則 の 5 点セットで、自分の業務をそのまま当てはめられる粒度に整えました。
最後に強調したいのは、自動化の価値は「人間を消すこと」ではなく「人間が残す判断を絞り込むこと」にある、という置き方です。Human Review は設計の失敗ではなく公式機能、例外所有者は AI ではなく人間で持つ、不可逆処理は信頼スコアが高くても人間ゲートで止める。この三点を崩さなければ、自動化したのに作業者に戻る構造からは抜けられます。
本記事を読み終えた段階で「自分の業務にどう当てはめるかが見えない」「設計フローと責任分界を一度第三者と整理したい」と感じた方は、Beエンジニアのお問い合わせフォームよりご相談ください。設計フローと責任分界の整理を主訴とした相談として受け付けています。
関連記事
n8n × AI のコスト構造を扱う相互補完記事として、月額 API 課金の構造と用途別試算をまとめています。設計と並行してコスト面も見直したい方は、こちらを参照してください。




