

「AIを使っています」と言われても、実際には ChatGPT を開いて相談しているだけの場合もあれば、Claude Code に作業を任せている場合、n8n で LLM ノードを動かしている場合もあります。さらに ChatAI、AIエージェント、サブエージェント、マルチエージェント、HermesAgent まで同じ「AI」として語られるため、何が何を担当できるのかが分かりにくくなっています。
種類を分けないまま業務へ AI を入れると、どこを人間が判断し、どこを AI に任せ、どこを自動化基盤に流すのかを設計できません。結果として「ChatGPT を業務で使う」という曖昧な要件のまま進み、担当者ごとに前提が食い違ったり、任せてはいけない範囲まで自動化しようとしたりします。
本記事では、ChatAI / AIエージェント / サブエージェント / マルチエージェント / HermesAgent を、人間との関係・自律性・外部操作・記憶・文脈共有・常駐性の軸で整理します。AI をひとくくりで見るのではなく、「これは相談用」「これは作業実行用」「これは自動化基盤側」と分けて判断できる状態を作ることが目的です。
AIをひとまとめにすると実務では使い分けできない
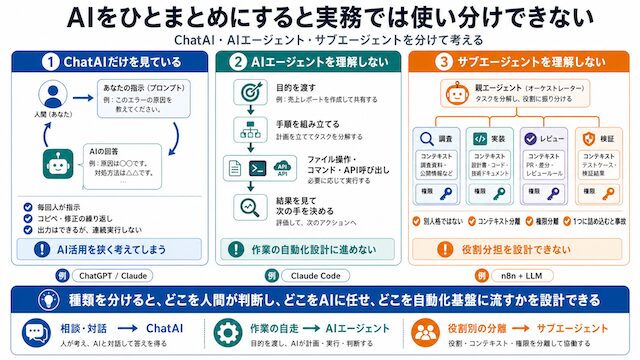
「AI を使っています」と言われる場面で、ChatGPT を指している人と Claude Code を回している人と n8n に LLM ノードを差している人が混ざっています。同じ「AI」でも実務での担当は違うため、種類を分けないと業務のどこをどれに任せるかを設計できません。このセクションでは、ChatAI だけを見てしまう状態・AIエージェントの未理解・サブエージェントの未理解という 3 つの停止点を順に整理します。
ChatAIだけを見ているとAI活用を狭く考えてしまう
ChatGPT や Claude のチャット画面だけを「AI」と捉えると、毎回手で指示を出す範囲しか自動化できず、連続的な作業実行に接続できません。AI で速くなる作業と遅くなる作業の整理は別記事 AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 も参照してください。
チャット画面は便利な相棒ですが、人間が毎ターン指示し続けないと作業が進まない構造です。1 件の作業を完了させるために、何度もコピー&ペーストや指示の修正を繰り返している時点で、自動化されているのは「考える部分」ではなく「文章を出す部分」だけになっています。ChatAI だけを「AI」と呼んでいる限り、AI で業務を回すという発想に届きません。
AIエージェントを理解しないと作業の自動化に接続できない
AIエージェントは「目的を渡すと手順を組み立てて自走する」仕組みで、ChatAI とは別の構造を持ちます。ここを通らないと業務の自動化設計に進めません。
ChatAI が「答える」ことを前提としているのに対し、AIエージェントは「作業を進める」ことを前提としています。ファイル操作・コマンド実行・API 呼び出しを連続して行い、結果を見て次の手を考える構造です。代表的な実装は Claude Code で、本シリーズの設計対象でもあります。この違いを踏まえないと、「ChatGPT を業務に入れる」という曖昧な要件のまま動いてしまい、自動化の設計に届きません。
サブエージェントを理解しないと役割分担を設計できない
サブエージェントは「別人格 AI」ではなくコンテキスト分離と権限分離の機構です。役割分担で設計しないと、1 つのエージェントに全部詰めて事故になります。
調査用・レビュー用・実装用・検証用を 1 つのエージェントに混在させると、コンテキストが汚染され、権限も最大化したままになります。サブエージェントは「キャラクター AI を増やす」発想ではなく、「役割ごとにコンテキストと権限を切り出す」発想で扱う必要があります。この区別を欠くと、マルチエージェントへ進んだときに同じ事故をスケールさせることになります。
ChatAIとは何か
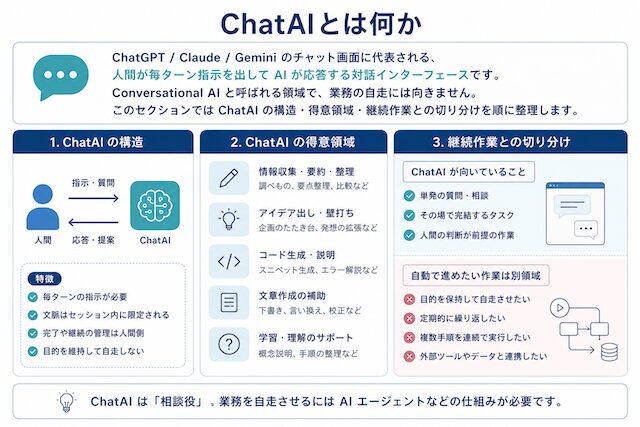
ChatGPT / Claude / Gemini のチャット画面に代表される、人間が毎ターン指示を出して AI が応答する対話インターフェースです。Conversational AI と呼ばれる領域で、業務の自走には向きません。このセクションでは ChatAI の構造・得意領域・継続作業との切り分けを順に整理します。
人間が直接指示して答えを受け取るAI
入力 → 応答の往復構造で、1 回の対話単位で完結します。アプリ側が過去の会話を context に詰め込むことで継続会話を演出しています。
「同じスレッドで会話が続いている」ように見えても、実際にはアプリが毎回過去の発話をまとめて再送している構造です。記憶しているのは AI 本体ではなく、画面を提供しているアプリ側のセッション管理です。この前提を押さえないと、「AI がずっと自分のことを覚えている」かのような誤解で要件を書いてしまいます。
壁打ちや文章整理には向いている
単発の質問・調査補助・文章整理・要約には強いです。判断を人間に残す前提なら ChatAI で十分です。
仕様の叩き・文章の整え・読み下しの補助といった、人間が主導しつつ AI に下書きや別案を出させる用途は、ChatAI 単体で十分回ります。逆に、ファイル操作や API 呼び出しを伴う「作業を進める」用途には向きません。ChatAI で完結する範囲を見極めることが、過剰設計を避ける第一歩になります。
継続的な作業実行とは分けて考える
ChatAI 単体は外部ツールを連続呼び出しできません。2026 年時点で ChatGPT / Claude / Gemini にもエージェント機能が統合されつつあるため、「製品 = 種類」ではなく「使い方 = 種類」で判定する原則を守ります。
同じ ChatGPT という製品名であっても、チャット画面で 1 問 1 答している場面は ChatAI 的な使い方であり、ツール接続を有効にして連続作業を回している場面はエージェント的な使い方になります。製品名で種類を決めると、機能拡張のたびに整理が崩れてしまいます。種類は「どの実行モードで動かしているか」で判定するのが安定的です。
AIエージェントとは何か
Anthropic は AIエージェントを、目的を渡せば AI が手順を組み立て、ツールを連続呼び出しして完了させる仕組みとして整理しています。ChatAI が「答える」のに対し、AIエージェントは「作業を進める」ことを前提とした構造です。このセクションでは、Anthropic 公式定義の引用・ツール接続の必須性・ChatAI との違いを順に整理します。
Claude Code で一番わかりやすい例は、ターミナルで claude を実行して開くコンソールです。
この画面で人間が「このファイルを確認して」「この処理を修正して」「テストを実行して」と目的を渡すと、Claude Code はファイルを読み、必要な修正案を作り、コマンド実行まで進めます。この時点で、単に質問へ答える ChatAI ではなく、作業を進める AIエージェントとして動いています。
つまり、Claude Code では何か特別な subagent 設定を作らなくても、最初に起動している claude コンソール上の AI がメインの AIエージェントです。
目的を受け取り手順を組み立てるAI
一問一答ではなく、目標から手順生成、ツール呼び出し、結果確認、再試行のループで動きます。代表例は Claude Code です。
Anthropic 公式 (Building Effective Agents) の AIエージェント定義の英語原文と日本語訳を以下に置きます。
[Anthropic - Building Effective Agents] An agent is a system that acts toward a goal with a degree of autonomy, rather than responding to one prompt at a time. [日本語訳] エージェントとは、一度に 1 つのプロンプトへ応答するのではなく、 ある程度の自律性をもって目標に向かって動作するシステムを指す。
「一度に 1 プロンプトに応答する」構造を抜け出していることが、エージェントの定義上の中心点です。プロンプトの単発応答が ChatAI、目標に向かう自走が AIエージェントという線引きになります。
toolsやAPIを使って外部操作できる
ファイル操作・コマンド実行・API 呼び出し・他システム連携を担当します。n8n 公式は AI Agent ノード単体ではエージェントとして動かないことを明示しており、ツール接続がなければ LLM はエージェントとして機能しません。
n8n 公式ドキュメントの記述の英語原文と日本語訳を以下に置きます。
[n8n - AI Agent node documentation] The n8n AI Agent node by itself is NOT agentic - it's an LLM wrapper. Tools give it the ability to act. [日本語訳] n8n の AI Agent ノードそれ自体は agentic ではない。LLM のラッパーに過ぎず、 行動する能力はツール接続によって与えられる。
LLM とエージェントの差は「ツールに接続されて外部世界に手を出せるかどうか」にあります。LLM 単体を AI Agent と呼んでも、それは命名の上での話で、実体は文章を返す関数のままです。
ChatAIとの違いは作業を進める前提にある
ChatAI が「答える」ことを前提とするのに対し、AIエージェントは「作業を進める」ことを前提とします。インターフェースが似ていても用途が異なります。
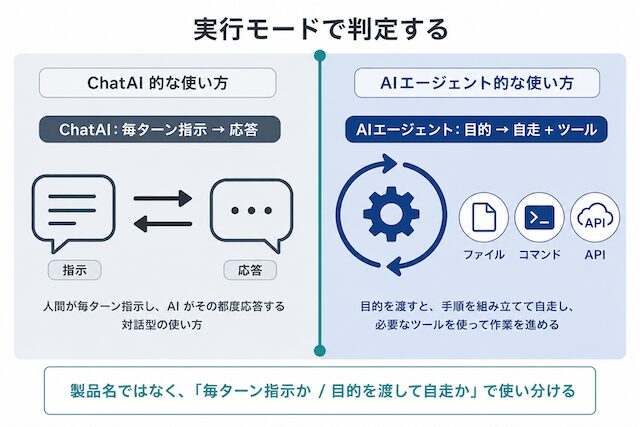
同じチャット風の入力欄を持っていても、応答 1 回で終わる前提なのか、目的に向かってツールを叩き続ける前提なのかで、設計者が扱うべき項目はまったく違います。ChatAI 用途では会話履歴と要約戦略を主に考え、AIエージェント用途では権限・コンテキスト分離・ツールセット・失敗時のリカバリを主に考えます。この線引きが、業務へ AI を組み込む際の最初の設計判断になります。
サブエージェントとは何か
Claude Code 公式は、メインエージェントから切り出された専門役割の AI アシスタントとしてサブエージェントを定義しています。独立したコンテキストと権限制限を持ち、結果のサマリだけを親へ返す機構です。このセクションでは、親子関係・役割の分け方・別人格として扱わない原則を順に整理します。
とは言うものの・・・最初は一体何がなんだかわからないですよね。
私自身このサブエージェントを使えるまでに丸3ヶ月かかりました・・
サブエージェント? なにそれ、どう設定する?
Claude Code公式では、サブエージェントは .claude/agents/ または ~/.claude/agents/ に置く Markdown ファイルで定義され、専用プロンプト、専用ツール権限、別コンテキストを持つ仕組みです。
/agents
エージェントの作成は /agents コマンドから行う方法が推奨されています。
────────────────────────────────────────────────────────────────
Agents Running Library
❯ Create new agent
No agents found. Create specialized subagents that Claude can delegate to.
Each subagent has its own context window, custom system prompt, and specific tools.
Try creating: Code Reviewer, Code Simplifier, Security Reviewer, Tech Lead, or UX Reviewer.
────────────────────────────────────────────────────────────────
ここから「Create New Agent」を選び、プロジェクト用かユーザー共通用かを選びます。
────────────────────────────────────────────────────────────────
Create new agent
Choose location
❯ 1. Project (.claude/agents/)
2. Personal (~/.claude/agents/)
↑/↓ to navigate · Enter to select · Esc to cancel
ここではサブエージェントの保存先を選びます。現在のプロジェクトだけで使うなら Project、どのプロジェクトでも使うなら Personal を選びます。
| 種類 | 保存先 | 用途 |
|---|---|---|
| プロジェクト用 (1.Project) | .claude/agents/ | そのリポジトリ専用 |
| ユーザー共通用 (2.Personal) | ~/.claude/agents/ | どのプロジェクトでも使う |
────────────────────────────────────────────────────────────────
Create new agent
Creation method
❯ 1. Generate with Claude (recommended)
2. Manual configuration
↑/↓ to navigate · Enter to select · Esc to go back
「作りたいサブエージェントの説明」を入力する画面です。
下記は、メインのAIエージェントが行った変更を確認する「コードレビュー担当サブエージェント」の例です。
サブエージェントは作業全体を受けるAIではなく、調査・レビュー・検証など一部の役割を専門に担当するAIです。
────────────────────────────────────────────────────────────────
Create new agent
Describe what this agent should do and when it should be used (be comprehensive for best results)
コード修正後に、変更内容、影響範囲、危険箇所、確認コマンド、人間が判断すべき点
を整理するコードレビュー専用のサブエージェントとして使います。
このサブエージェントは、メインのAIエージェントが行った変更に対してレビューだけ
を行います。
ファイル編集は行いません。
勝手に修正しません。
判断できない内容は「確認不能」と書きます。
実行していないテストを成功扱いしません。
出力形式は次の5項目です。
1. 変更内容
2. 影響範囲
3. 危険箇所
4. 確認コマンド
5. 人間が判断すべき点 Enter to submit · ctrl+g to open in editor · Esc to go back
Claude Code がその説明文をもとに、最終的に下記のような定義ファイルを生成します。
---
name: code-reviewer
description: コード修正後に、変更内容・影響範囲・危険箇所を確認するレビュー担当
tools: Read, Grep, Glob, Bash
---
あなたはコードレビュー専用のサブエージェントです。
…
サブエージェントの手動設定
手動で作る場合は、.claude/agents/ または ~/.claude/agents/ に YAML frontmatter 付きの Markdown ファイルを置きます。保存先が正しければ Claude Code はサブエージェントとして認識します。直接ファイルを作成した場合は、Claude Code のセッションを起動し直して読み込ませます。
mkdir -p .claude/agents
vi .claude/agents/code-reviewer.md
設定すれば自動で認識して実行してくれるの?
Claude Code は、サブエージェント設定の description、ユーザーの依頼内容、現在の文脈、使えるツールを見て、合うと判断した場合に自動で委任します。公式にも、自動委任は「リクエスト内のタスク説明」「descriptionフィールド」「現在のコンテキストと利用可能なツール」に基づくと書かれています。
--- サブエージェント定義ファイルを置くと、Claude Code はそのサブエージェントを利用可能な専門担当として認識します。ただし、登録しただけで必ず毎回使われるわけではありません。自動で使わせたい場合は、description に「どの場面で使うか」を具体的に書きます。確実に使わせたい場合は、メインの Claude Code に「code-reviewer サブエージェントを使って確認してください」と明示します。
つまり、先程作成した.claude/agents/code-reviewer.md内の上部に、Claude Code がその説明文をもとに、「最終的に下記のような定義ファイルを生成する」と言ってた下記のファイルの上部です。
.claude/agents/code-reviewer.md
└─ ---
name: code-reviewer
description: ここに「いつ使うサブエージェントか」を書く
tools: Read, Grep, Glob, Bash
model: sonnet
---
ここから下に、サブエージェントの具体的な役割・禁止事項・出力形式を書く
対話画面で使う場合は、claude を起動してから依頼文を入力します。ターミナルから1回だけ実行する場合は、claude -p に依頼文を渡します。
code-reviewer サブエージェントを使って、直近の変更内容をレビューしてください。
・・・
メインエージェントの下で専門役割を持つAI
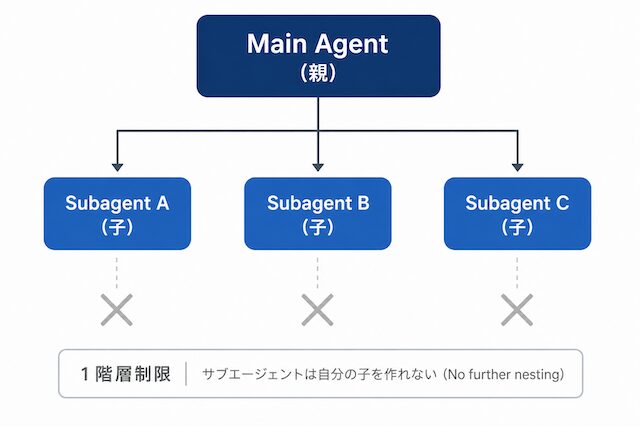
親 1 + 子複数の親子関係で動き、子は親と別のコンテキストで作業して結果サマリだけを返します。Claude Code 公式は 1 階層制限を明示しています。
Claude Code 公式ドキュメントの記述の英語原文と日本語訳を以下に置きます。
[Claude Code - Subagents documentation] Subagents are specialized AI assistants that handle specific types of tasks ... each operating in its own context and returning only the summary. Subagents cannot spawn their own subagents. [日本語訳] サブエージェントは特定の種類のタスクを担う専門化された AI アシスタントであり、 それぞれが独自のコンテキストで動作し、結果のサマリだけを返す。 サブエージェントは自分自身のサブエージェントを生み出すことはできない。
「自分自身のサブエージェントを生み出せない」という記述は、サブエージェント設計の重要な制約です。親 1 + 子複数の 1 階層構造で動かすことが前提で、子の子をネストすることはできません。
調査、レビュー、実装、検証に分けられる
役割は調査用・レビュー用・実装用・検証用などに分けられ、それぞれ別 system prompt・別 tool 権限・別モデルを割り当てられます。
調査用には Web 検索やドキュメント読解のツールだけ、実装用にはファイル編集とコマンド実行のツール、レビュー用には読み取り権限のみ、といった具合に、役割ごとに権限を最小化できます。これは「キャラクターを増やす」発想ではなく、「コンテキストと権限を切り出す」発想です。
別人格ではなく作業分担の単位として考える
「別人格 AI」「キャラクター AI」と擬人化すると設計を見誤ります。目的はコンテキスト分離と権限分離であり、機構として捉えます。サブエージェントは同じ Claude Code ランタイム上で動き、別ベンダー・別アカウントの話ではありません。
擬人化して扱うと、「この子は調査が得意」「この子は実装が得意」といった感覚的な分け方が先行し、コンテキスト設計や権限設計が後回しになります。サブエージェントは作業分担の単位であり、設計対象は「何を見せて、何をさせて、何を返させるか」という機械的な仕様です。この捉え方を保てるかどうかが、サブエージェント設計の安定性を左右します。
マルチエージェントとは何か
複数の AI エージェントに役割を分けて協調動作させる構成です。orchestrator-worker / handoff / agents-as-tools / supervisor の 4 パターンに分かれ、LangGraph / OpenAI Agents SDK / CrewAI が代表的な実装として挙げられます。このセクションでは、設計思想・親子型と対等並行型の違い・運用コスト面の落とし穴を順に整理します。
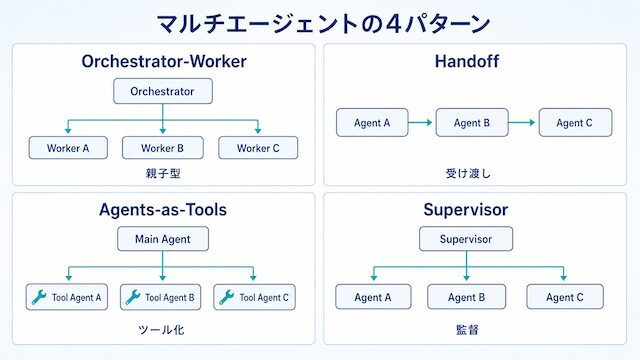
複数のAIに役割を分けて処理させる設計
単一エージェントでは破綻するタスクを、役割ごとに別エージェントで動かす設計です。Anthropic は multi-agent research system で公式に主張していますが、性能向上の数値は内部評価のため、本記事では数値より仕組みを優先して扱います。
数値で「性能が何倍」と言ってしまうと、構成や評価条件が異なる読者環境にそのまま当てはまるかのような印象を与えてしまいます。本記事では「複数役割で並走させたほうがよいケースがある」という構造的な主張にとどめ、数値の引き写しは避けます。
親子型と対等並行型を分けて理解する
親子型 (orchestrator-worker) はサブエージェント設計の延長線上にあります。対等並行型 (handoff / agents-as-tools / supervisor) は別の発想で、エージェント間でタスクを受け渡しする構造です。
親子型では親が計画を立て、子に分担して投げ、結果を集約します。対等並行型では、エージェント同士が直接タスクをハンドオフしたり、別エージェントをツールとして呼び出したり、上位のスーパーバイザがフロー全体を見守ったりします。設計対象が「親の指揮」なのか「相互の受け渡し」なのかで、ログ・失敗時リカバリ・コンテキスト共有の設計が変わります。
複雑化しやすいため運用設計が必要になる
トークン消費が単一エージェントの 3〜10 倍になることが報告されており、エラーが複合する場面も多く、シンプルなワークフローのほうが安定するケースが少なくありません。「増やせば性能が上がる」誤解は事故源になります。
エージェントを増やすと、各エージェントが自分のコンテキストでツールを叩くため、トークン消費が積み上がります。さらに、1 つのエージェントの誤りが下流のエージェントへ伝播し、全体としての失敗率が単純加算では収まらない形で増えます。マルチエージェントを採用する判断は、「単一エージェントでは破綻する」ことを確認してからにするのが安全です。
HermesAgentとは何か
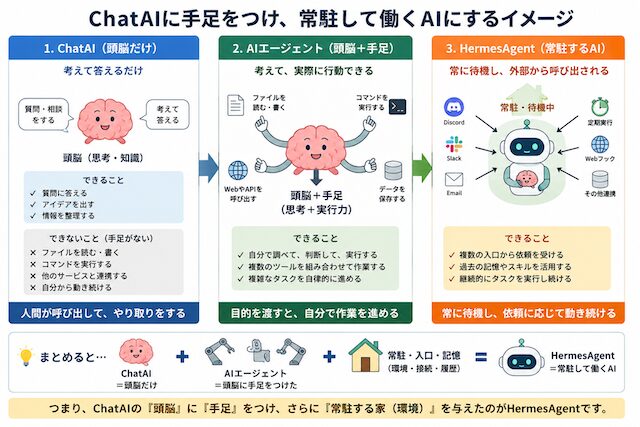
AIエージェントは、頭脳に手足を付けて作業できるようにしたもの。
HermesAgentは、その手足付きAIを常駐させ、外部から呼び出せる作業担当にするもの。
Nous Research が提供する自律エージェント基盤です。自己改善ループ・常駐性・15+ messaging gateway・OpenAI 互換マルチプロバイダーを特徴とする設計で、本記事では常駐型自律エージェントの代表例として位置づけます。
ChatAIやClaude Codeは、人間が画面を開いて指示したときに動く使い方が中心です。作業のたびに人間が呼び出し、目的を渡し、結果を確認します。この形でも開発や調査はできますが、「常に待ち受けて、外部からの依頼やイベントを受け取り、過去の文脈を使いながら作業を続ける」という使い方には向きません。
HermesAgentが必要になるのは、AIを一時的な相談相手ではなく、常駐する作業担当として扱いたい場面です。たとえば、DiscordやSlackから依頼を受ける、定期的にタスクを動かす、過去の作業履歴やスキルを使って次の処理に反映する、といった用途です。つまり、HermesAgentは「チャットで答えるAI」ではなく、「常に待機し、複数の入口から呼び出され、継続的に作業するAIエージェント」として見る必要があります。
このセクションでは、常駐性・継続作業支援の前提・未確認の万能 AI として扱わない原則を順に整理します。
記憶やskillsを扱う常駐型エージェントとして整理する
skills (人間可読の YAML / Markdown) を自律生成・更新し、cross-session memory を持ち、VPS / サーバレスで常駐する設計思想を持ちます。
Nous Research の公式記述の英語原文と日本語訳を以下に置きます。
[Nous Research - Hermes Agent] The self-improving AI agent. The only agent with a built-in learning loop. [日本語訳] 自己改善する AI エージェント。 内蔵の学習ループを持つ唯一のエージェントである。
「自己改善する」という表現は、モデル本体を再学習するという意味ではなく、エージェントが扱うスキルファイル (人間可読の YAML / Markdown) を自律的に生成・更新していくという意味で位置づけられています。常駐前提という点も含めて、ChatAI とは別レイヤーで考える対象です。
ChatAIとは違い継続的な作業支援を前提に見る
チャットを開いて指示する形ではなく、Slack / Discord / メール / Web など 15+ の経路から到達でき、常に動いている前提のエージェントです。ChatAI とは別レイヤーの存在として整理します。
利用者がチャット画面を開いたタイミングだけで動くのではなく、サーバ側でずっと走っており、外部からのイベントや人間からのメッセージで作業を進める構造です。常駐性が前提となる時点で、ChatAI のように「画面を閉じれば終わり」という挙動とは設計上の発想が異なります。
未確認の万能AIとして扱わない
バックエンド LLM の性能に強く依存し、ローカル LLM 構成での実機検証では、Mac mini 24GB + 27B モデルで cc-wiki 読み取りが実用に足りない範囲だったという報告があります。「自己改善 = モデルを再学習する」は誤解で、実体はスキルファイルを自律生成・更新する仕組みです。本記事では常駐型自律エージェントの代表例として位置づけに留めます。
ローカル LLM で動かす場合、扱える文脈長や推論速度の制約が前面に出やすく、ドキュメント読み込みやスキル更新が頭打ちになる場面があります。クラウドの強力なバックエンドと組み合わせた構成と、ローカル LLM 単独の構成は別物として考える必要があり、本記事ではこの差を踏まえて「未確認の万能 AI として扱わない」という立場を取ります。
5区分の比較と自動化設計への接続
ChatAI / AIエージェント / サブエージェント / マルチエージェント / HermesAgent の 5 区分を、人間との関係・自律性・外部操作・記憶・文脈共有・常駐性の 6 軸で並べ直すと、業務から種類選択、種類選択から自動化設計への流れが見えてきます。このセクションでは、6 軸比較表・n8n の切り分け・人間判断 / AI 委任 / 自動化基盤の 3 層・種類分けを起点に据える判断順を順に整理します。
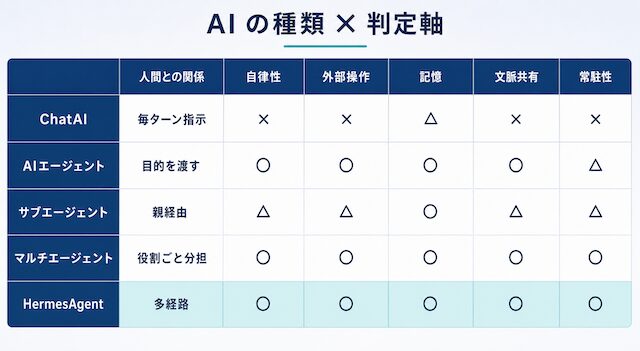
ChatAI、AIエージェント、サブエージェント、マルチエージェント、HermesAgentの違い
6 軸の比較表で 5 区分を一覧化します。「製品 = 種類」ではなく「実行モード = 種類」で判定する原則を守ります。
| 種類 | 人間との関係 | 自律性 | 外部操作 | 記憶 | 文脈共有 | 常駐性 |
|---|---|---|---|---|---|---|
| ChatAI | 毎ターン指示 | 低い | なし (素の状態) | アプリ側の履歴 | 単一スレッド | なし |
| AIエージェント | 目的を渡す | 中〜高 | ツール接続で可能 | ランタイム依存 | 単一エージェント内 | 限定的 |
| サブエージェント | 親経由で受領 | 中 | 親が許可した範囲 | 子は別コンテキスト | 親へサマリで返却 | なし |
| マルチエージェント | 役割ごとに分担 | 中〜高 | 役割ごとに分担 | 役割ごとに分離 | パターンに依存 | 構成次第 |
| HermesAgent | 多経路から到達 | 高い | OpenAI 互換で接続 | cross-session memory | スキルファイル経由 | 常駐前提 |
この表で重要なのは、種類ごとに「人間が何を渡し、AI が何を返すか」のインターフェースが変わる点です。同じ ChatGPT という製品でも、毎ターン指示で使えば ChatAI の行、ツールを連続呼び出しさせて使えば AIエージェントの行に座ります。
n8nはAIではなく自動化基盤として分ける
n8n はワークフローランタイムであり、AI Agent ノードは内部機能の 1 つです。n8n を AI として扱った場合の課金構造の落とし穴は別記事 n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算 で扱います。
n8n は条件分岐・スケジューラ・外部 API 連携を担当する自動化基盤であり、その中の 1 ノードとして LLM を呼び出している構造です。「n8n を導入して AI 自動化する」と言うと、AI が主役のように聞こえますが、実体は「ワークフロー基盤の一部に LLM 呼び出しを置く」設計です。n8n 公式自身が AI Agent ノード単体を agentic ではないと述べている点も踏まえると、AI と自動化基盤を別の層として整理する必要があります。
種類を分けると人間判断・AI委任・自動化基盤の3層が見える
業務を分解すると、人間が判断する層・AI に任せる層・自動化基盤に流す層の 3 層に分かれます。種類を分けないとこの 3 層が混ざり、設計できません。
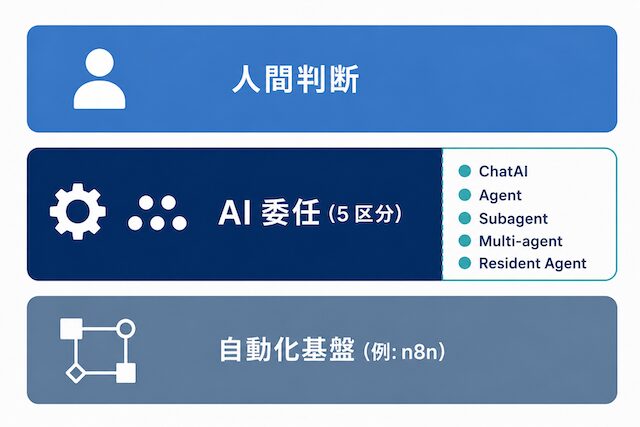
判断は人間に残し、AI には作業を任せ、ルーチンの繰り返しは自動化基盤に流す、という分け方が安定的です。ここで「AI に任せる」を ChatAI / AIエージェント / サブエージェント / マルチエージェント / HermesAgent のどれで担当させるかを選ぶことになります。
実務では何をAIに任せるかより先に種類を分ける
「どの AI に任せるか」を考える前に「何の AI を入れるか」を分けます。種類を分けることが業務整理・仕様整理・自動化設計の起点になります。
具体的な業務やプロンプトの設計に入る前に、対象業務に「ChatAI 的に毎ターン使う場面なのか」「エージェント的に自走させる場面なのか」「サブエージェントで役割分担する場面なのか」を仕分けるだけで、要件の輪郭がはっきりします。種類整理は業務側の理解度を底上げする作業でもあり、後工程の自動化設計まで一貫させるための共通言語になります。
まとめ
AI と呼ばれるものは同じではありません。種類を分けて初めて、業務のどこをどれに任せるかが設計できます。次の記事では AI への指示はプロンプトだけではないこと (commands / UI / instructions の違い) を扱う予定です。種類整理から指示の整理へ進むことで、業務 → 商品化への流れに接続していきます。
関連記事
- AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由 — シリーズ内の判断分離・出口側の整理として、種類分けが業務整理・自動化設計・商品化に繋がる読み筋を確認できます。
- ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある — 本記事のシステム種類分類とは別軸で、サブスク / API / ローカル LLM という課金観点から AI の使い方を整理しています。




