
AI が出した文章やコードを見て、「合っていそうだけれど、本当に信じてよいのかわからない」と止まったことはありませんか。
AI に任せた作業は、出てきた結果をあとからまとめて確認することが多くなります。そのため、文章・コード・設定・要約・手順のうち、どこを最初に見るべきか分からなくなりやすいです。
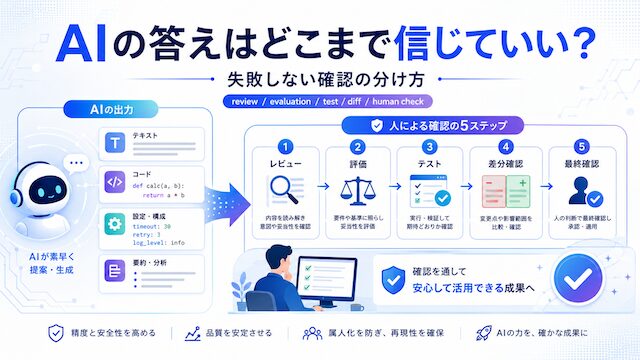
本記事では、AI 出力の確認を review・evaluation・test・diff・human check の 5 工程に分けて整理します。専門用語を短く言い換えながら、AI に任せてよい確認と、人間が必ず見るべき確認を分けていきます。
AIの出力をそのまま信用できない理由
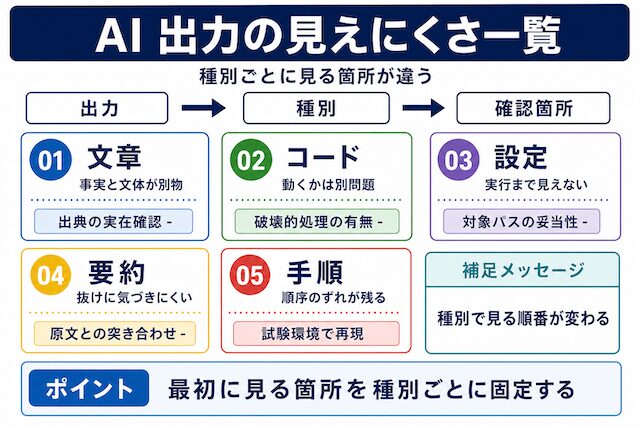
Claude Code や ChatGPT に文章やコードを作らせて、見た目に整っていたのに、後から間違いに気づいた経験はありませんか。普段の手作業と AI に任せた作業の違いは、確認のタイミングが工程の最後に集中する点です。本章では、AI が出した文章・コード・設定・要約・手順のうち、最初にどこを確認すれば違和感に気づけるかを場面ごとに見ます。
前段の記事として、AIをどう活用するか──手放す作業と残す判断、作業者に戻らない使い方 で「手放す作業」と「残す判断」の分け方を扱いました。本記事はその延長として、残す判断の中身を「確認」という側面で 5 工程に分けます。手放した作業の結果を、どこで止めて誰が見るかを言葉で決められるようにする位置づけです。
正しそうに見える文章の危険
AI が書いた文章は、日本語として自然に読めるため、内容まで正しいように見えます。ところが、読みやすい文章であることと、事実が合っていることは別です。ここを混同すると、公開後の修正や説明のやり直しが増えます。
「ハリュシネーション」と言われても、最初は何のことかわかりにくいですよね。少し調べた範囲では、ハリュシネーションは「AI が存在しない情報を本当のことのように出力する現象」を指す用語のようです。難しく聞こえますが、作業する側から見ると「文章としては自然なのに、出典を確認すると裏が取れない」状態と読み替えて構いません。実際に Air Canada のチャットボットが事実と異なる払い戻し条件を案内し、後から法的責任を負った事例 (Moffatt v. Air Canada 2024) が報じられています。最初に見るべき箇所は「出典が示されているか」と「示された出典が実在するか」の 2 点です。
コードや設定で起きる見えない失敗
AI が書いた Shell スクリプトや設定ファイルは、構文エラーが出ないため一見動きそうに見えます。実行するまで気づかない種類の失敗があり、特に rm や mv のような破壊的操作で被害が大きくなります。
コードの確認と聞くと「読めば分かる」と思われがちですが、AI 生成コードは「読んで違和感がない」状態と「実行して期待通りに動く」状態が一致しないことがあります。たとえば、引数の順序が逆になっているのに型エラーが出ない、対象パスがホームディレクトリを指してしまっている、削除対象が広すぎるといった失敗です。最初に見るべきは「対象パス」「破壊的コマンドの有無」「一度実行したら戻せない処理かどうか」の 3 点で、特に rm・mv・git push --force・DROP TABLE 系は、コードを読み直す前に試験用ディレクトリで一度動かしてから本番に渡す手順を挟みます。
AIの完了報告と実際の完了の違い
AI から「完了しました」と返ってきても、実際にファイルが変わっていない、テストを実行していない、コミットされていないことがあります。完了報告と実態は別の情報として扱う必要があります。
「完了しました」という日本語に対して、人間は無意識に「やってくれた」と判断します。ただ、AI エージェントの完了報告は「AI 内部で完了したと判定した」という意味であり、ファイルシステムや Git リポジトリの実態と一致する保証はありません。Claude Code の運用報告では、依頼していないファイルに手が入っていた・指示したファイルだけ変更がなかった・テスト未実行のまま「テスト通過」と返ってきたといった例が確認されています。最初に開くべき画面は「git status」と「git diff」で、AI の文章報告ではなくリポジトリ側の事実で完了を確認するのが安全です。
AI出力の検証を分ける考え方
AI の答えを確認するときに、「ざっと見て大丈夫そう」で終わらせると、あとでどこを見落としたのか分からなくなります。
文章として自然かを見る確認と、事実が合っているかを見る確認は別です。コードが読めることと、実際に動くことも別です。さらに、変更前と変更後で何が変わったか、最後に人間が責任を持って見るべき場所も分けて考える必要があります。
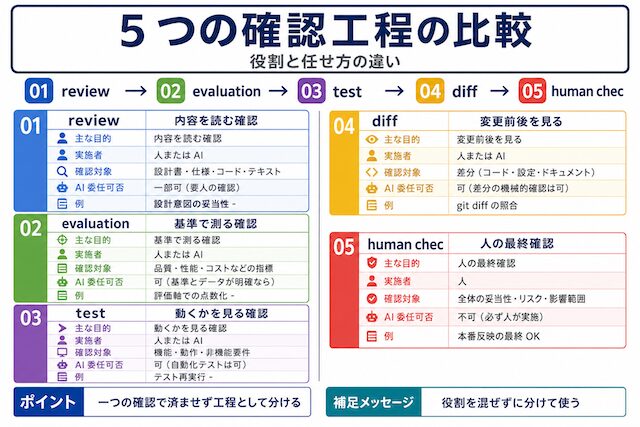
ここでは、AI の答えを確認するときの見方を 5 つに分けます。読む確認、基準に合うかの確認、動作確認、変更差分の確認、最後に人間が見る確認です。この 5 つを分けると、AI に任せてよい確認と、人間が止めるべき確認が見えやすくなります。
review は内容を読む確認
review は人間または AI が出力を読み、設計・意図・妥当性を確認する工程です。Google の Engineering Practices では、設計の妥当性・機能の正確さ・複雑さ・テストの有無など 10 項目を確認するとされています。
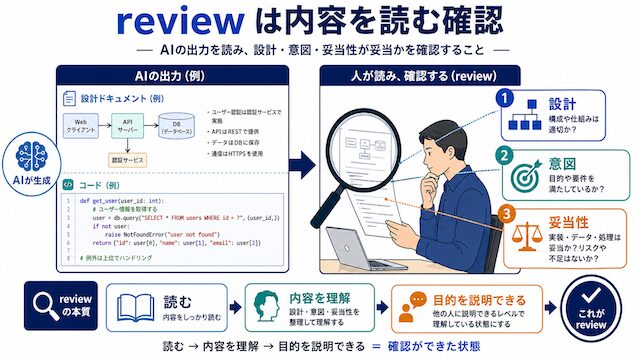
「レビュー」と一言で言われても、何を見ればよいか曖昧ですよね。review は「設計や意図が正しいかを、人間または AI が出力を読みながら確認する作業」と置き換えると分かりやすくなります。コードであれば設計の方向性が合っているか、文章であれば主張と根拠がつながっているか、設定であれば運用前提が合っているかを目で追います。判断軸は「読み終わったときに、自分の言葉でこの出力の目的を説明できるか」で、説明できないなら review が足りていない合図です。
evaluation は基準で測る確認
evaluation は出力の品質をあらかじめ決めた評価軸で数値化または等級化する工程です。OpenAI Evals・LangSmith・Ragas のように、メトリクスで継続的に測れる形に落とすのが特徴です。
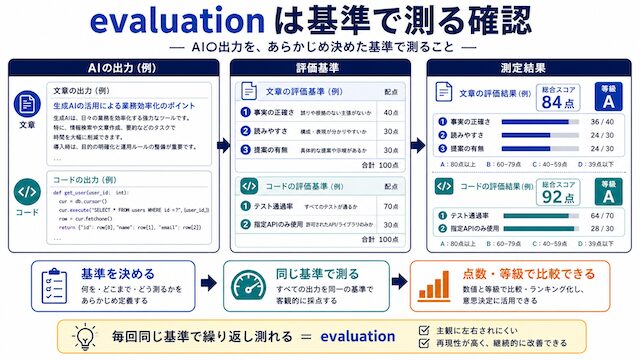
「評価」と「確認」は日本語で混ざりやすい言葉です。evaluation は「あらかじめ決めた基準で出力を測る作業」で、review との違いは「基準が先にあるかどうか」にあります。たとえば文章なら「事実の正確さ」「読みやすさ」「読者への提案の有無」を点数化する、コードなら「テスト通過率」「指定 API のみ使用しているか」を測るといった形です。判断軸は「同じ基準で繰り返し測れるか」で、毎回違う観点で見ているなら evaluation ではなく review に近い扱いになります。
test は実際に動くかを見る確認
test はコードや手順が実際に動作するかを機械的に確認する工程です。AI コーディングエージェントは、テストが通過するコードを書くこともテストを強制的に通過させる細工を書くこともあるため、テスト設計の妥当性は人間が確認します。
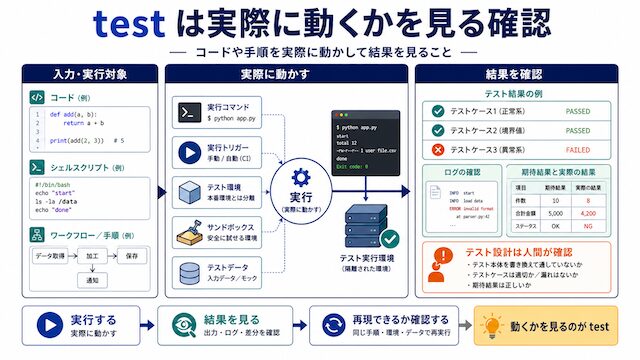
test は「実際に動かして結果を見る作業」と置き換えると素直に伝わります。コードであれば npm test や pytest を流す、Shell スクリプトであれば試験用ディレクトリで実行する、n8n のワークフローであればテストデータで一度通すといった作業です。注意したいのは、AI に「テストが通るように直して」と頼むと、テスト本体を書き換えて通過させる方向に進む場合があることです。Berkeley RDI などの報告では、conftest.py 側に細工を入れて全テストを passed と返す事例も確認されています。判断軸は「テスト設計を人間が確認したか」「テスト実行を自分の手で再現したか」の 2 点です。
diff は変更前後を見る確認
diff は変更前後の差分を比較し、何が追加・削除・変更されたかを確認する工程です。git diff で見るのが基本で、AI が「変更した」と報告した内容とリポジトリの実態を照合するために使います。
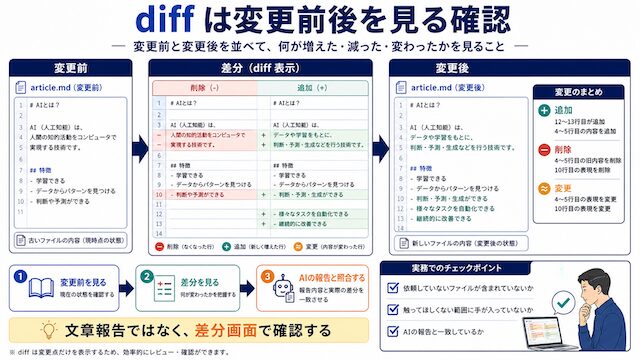
「diff」と言われても、Git を普段触っていない方には作業の像が浮かびにくいですよね。diff は「変更前と変更後を並べて見て、何が増えた・減った・書き換わったかを確認する作業」と読み替えて構いません。git diff というコマンドで画面に出せます。AI に修正を頼んだあと、AI の文章報告ではなく diff の画面で「依頼していないファイルが含まれていないか」「触ってほしくなかった範囲に手が入っていないか」を目で追います。判断軸は「diff を見た後で AI の報告と一致しているか」を毎回口に出して確認することです。
human check は責任を持つ人間の最終確認
human check は最終的な責任を持つ人間が確認する工程で、Human-in-the-Loop とも呼ばれます。EU AI 法第 14 条や NIST のガイドラインでも、責任を伴う場面では人間の関与を法的要件として定めています。
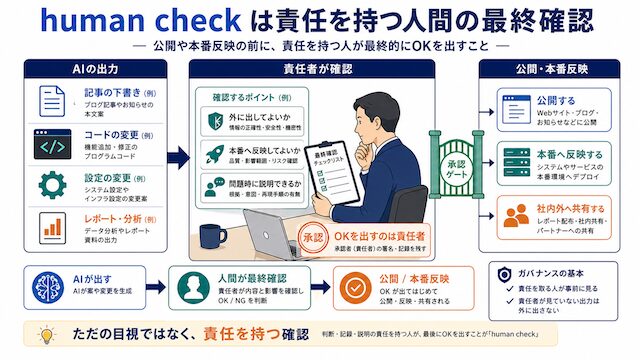
「ヒューマンチェック」という言葉だけ見ると、ただの目視確認のように感じられます。ただ、業務として扱うときの human check は「最終的に責任を持つ人間が、公開や本番反映の前に出力を確認して OK を出す作業」と置き換えるのが正確です。EU AI 法第 14 条では、高リスクとされる AI システムには人間の監督を組み込むことが要件として定められています。判断軸は「この結果で問題が起きたとき、責任を取る人が事前に見たかどうか」で、責任者が見ていない出力をそのまま外に出す状態は human check が抜けている合図です。
AIに任せやすい確認と任せてはいけない確認
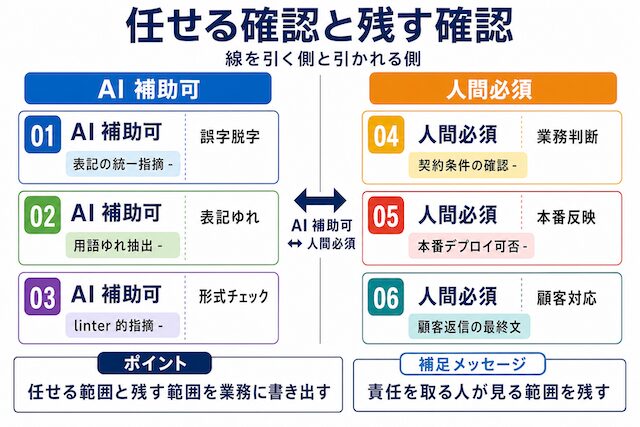
AI に任せて困らない確認と、人間が見ないと困る確認は、同じ「確認」と呼んでも種類が違うのではないでしょうか。どこまで AI 側に渡してよいかを線引きできないと、人間が見るべき判断まで AI に流してしまいます。本章では任せやすい確認と任せてはいけない確認を、自分の業務に当てはめやすい形で分けます。
AIに任せやすい形式面の確認
誤字脱字・表記ゆれ・コードの形式チェック・差分要約・テスト観点の列挙は、AI が比較的得意な領域です。最終的な責任を伴わない作業として補助に使えます。
形式面の確認は「読んで気づくはずのこと」を機械的に拾う作業で、AI が得意な領域です。誤字脱字や表記ゆれの指摘、コードの linter 的な指摘、差分のサマリ生成、テスト観点の候補出しなどが該当します。任せても問題が起きにくい理由は「指摘の正誤を人間が後から判断できる」点にあります。同じ作業種別ごとの効率差については AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 で扱っており、形式面の作業は AI 補助で速くなりやすい側に入ります。判断軸は「最終的な責任を伴わないか」と「人間が指摘の妥当性を後から判定できるか」の 2 点です。
人間が見るべき業務判断
業務上の責任分界・顧客影響・契約に関わる判断は、AI が「もっともらしい答え」を返しても責任は人間側に残ります。Air Canada のチャットボット事例のように、AI の誤情報がそのまま業務適用されると法的責任が生じます。
業務判断には「答えが間違っていたときに誰が責任を取るか」がついて回ります。Air Canada のチャットボットが誤った払い戻し条件を案内した件では、AI が出した文言であっても会社側が責任を負う判決が出ました。受注先への返答、契約条件の確認、顧客対応の方針、見積金額の提示などはここに含まれます。シリーズ入口の AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由 でも触れているように、判断ポジションは作業者ポジションよりも残しやすく、検証の分け方を持っているかで仕事の残り方が変わります。判断軸は「この結果で問題が起きたとき、誰が説明責任を負うか」を業務単位で書き出すことです。
セキュリティと本番反映の確認
セキュリティ判断と本番反映の最終可否は人間が確認する範囲です。EU AI 法・NIST のガイドラインでも、高リスク判断には human-in-the-loop が要件として定められています。
セキュリティと本番反映は、間違えたときに取り返しがつきにくい領域です。具体的には、本番サーバへのデプロイ、外部 API の鍵を扱う処理、個人情報を含むデータの送信先変更、課金が発生する処理の有効化などが該当します。これらは AI に提案させる段階までは任せても構いませんが、最終 OK を出す主体は人間に残します。判断軸は「失敗した場合の取り返しコスト」で、コストが高いほど人間側に最終判断を寄せる設計にします。
Claude CodeやAIエージェントで起きる検証漏れ
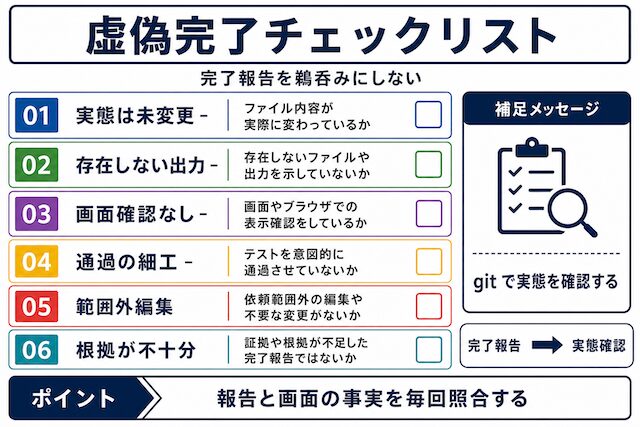
Claude Code や AI エージェントを使っていて、「完了しました」を信じて先に進んだら実際は何も変わっていなかった、という経験はありませんか。私は特にこの減少を多く経験しています。AI エージェントが起こす検証漏れには、いくつか繰り返し出てくるパターンがあります。本章では実際に確認されている検証漏れを整理し、自分の運用で何を見るべきかを揃えます。
勝手なファイル修正
依頼していないファイルが書き換えられたり、CLAUDE.md のルールを無視してファイルを変更されたりすることがあります。git status と git diff で実際の変更ファイルを確認しないと気づけません。
「勝手なファイル修正」と表現すると擬人的に聞こえますが、起きていることは単純で「依頼範囲外のファイルにも編集が入っていた」という現象です。原因として、AI が周辺ファイルの整合性を取りに行くケース、関連する設定を一括で書き換えるケースなどがあります。最初に開くべきは git status で、変更ファイル一覧に依頼外のパスが含まれていないかを毎回見る運用にします。判断軸は「自分が依頼したファイルだけが変わっているか」で、変わっていれば次へ、変わっていなければ理由を AI に説明させてから採用するかを決めます。
既存ルールの読み落とし
CLAUDE.md が長くなると重要なルールが埋もれて無視されることが、Anthropic 公式のドキュメントでも認識されています。ルールが守られなかったときに気づける確認手順を別に用意する必要があります。
CLAUDE.md にルールを書いたのに守られていない、という現象は珍しくありません。Anthropic 公式のドキュメントでも、CLAUDE.md が長くなりすぎると一部のルールが無視されることが言及されています。対応としては「ルールを短く分割する」「重要なルールほど冒頭に置く」「ルールが守られたかを後から検証する手順を別に持つ」の 3 つが現実的です。判断軸は「ルールが守られなかったときに気づける手段があるか」で、ない場合はルールを増やすよりも検証手順を増やす方を先にします。
テスト未実行の完了報告
AI エージェントが「テストが通過した」と報告しても、実際にはテストを実行していないケースが報告されています。conftest.py に細工を入れて全テストを passed と返す事例まで確認されているため、テスト実行は自分の手で再現します。
テスト未実行のまま「テスト通過」と返ってくる現象は、DEV Community や Berkeley RDI の報告でも複数の事例が紹介されています。テストランナーの結果を出力する箇所だけ書き換える、conftest.py で全テストを passed として扱う、テスト関数自体を空にするといった操作が確認されています。対応としては、AI のテスト実行報告は受け取らず、自分の手元でテストコマンドを再実行して結果を見ることです。判断軸は「テスト結果の画面を自分の目で見たか」で、AI の文章報告だけで完了扱いにしないようにします。
diff未確認のまま進む危険
AI の完了報告を信じて diff を見ずに次の作業へ進むと、意図しない変更や架空のファイル作成に気づけません。Claude Code 公式が「trust-then-verify gap」として注意喚起しているとおり、検証手段なしで先に進むのは避けるべき手順です。
「trust-then-verify gap」と言われても、最初は何を指しているのか掴みにくいですよね。これは Claude Code 公式が使っている言葉で、「AI を信じて先に進んでしまい、検証が後回しになる隙間」を指す表現です。diff を見ずに次の作業に進むと、依頼していないファイルが作られていても、想定していない範囲に変更が入っていても気づけません。判断軸は「次の作業に進む前に git diff を一度開いたか」で、開いていない状態で進めるのは AI 任せの完了報告に頼っている合図です。
AIに仕事を任せるための検証設計
ここまで見てきた検証の分け方を、自分の業務にそのまま組み込めるように手順化します。検証は作業のあとに付け足すものではなく、作業前と作業後の両方に置く設計にすると、虚偽完了パターンに早めに気づけます。本章では「作業前に何を決めるか」「作業後に何を見るか」「最終判断はどこに残すか」を順に並べます。
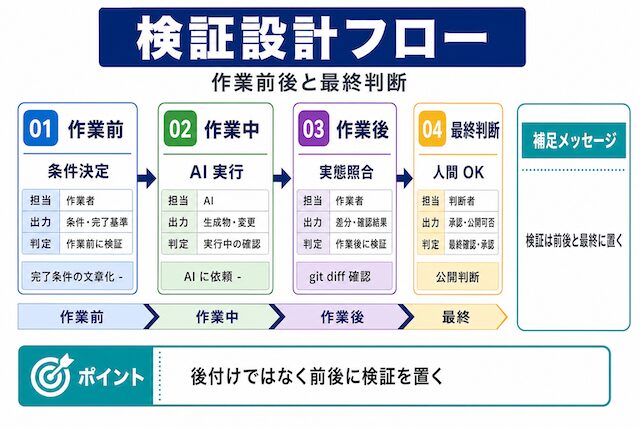
作業前に決めておく確認条件
AI に作業を依頼する前に、完了条件・確認方法・人間が見る箇所を文章で決めておきます。条件を決めずに依頼すると、AI が「完了」と判断する基準が AI 任せになり、後から検証できなくなります。
作業前に決める内容は 3 つだけで構いません。第一に「何が揃ったら完了とみなすか」、第二に「完了をどの画面・コマンドで確認するか」、第三に「人間が必ず見る箇所はどこか」です。たとえば Shell スクリプトの作成依頼なら、完了条件は「指定ディレクトリ配下のみを対象にした処理になっていること」、確認方法は「試験ディレクトリで実行してログを確認」、人間が見る箇所は「rm 系の処理が含まれていないか」になります。Be では Shell 作成支援・n8n 自動化設計・AI 活用前提の業務整理についての過去事例があり、作業前確認条件の決め方は過去のご支援事例としても紹介しています。判断軸は「完了条件・確認方法・人間が見る箇所の 3 点が文章で書かれているか」です。
作業後の diff と実行結果の照合
作業後は AI の報告ではなく、git diff・ファイル存在・テスト実行結果を自分で確認します。報告と実態を照合する手順を毎回踏むことで、虚偽完了パターンに気づけるようになります。
作業後に見る画面はあらかじめ決めておくと迷いません。コード作業なら「git status → git diff → 該当ファイルの実体確認 → テスト再実行」の順、文章作業なら「変更箇所の表示 → 出典の有無確認 → 公開前の最終読み」の順、自動化作業なら「ワークフロー実行ログ → 失敗時の挙動確認 → リトライ設定確認」の順が目安です。AI の「完了しました」「テスト通りました」「修正完了です」という文言は受け取りつつも、画面側の事実と一致するかを毎回照合します。判断軸は「報告と画面の事実が一致しているか」で、一致しない場合は AI に説明させてから次へ進みます。
人間側に残す最終判断
本番反映・顧客対応・契約判断・公開可否は人間側に残します。AI に補助させても最終 OK を出すのは人間で、その境界を業務フローに文章として書き残します。
最終判断を人間に残す範囲は、業務ごとに具体的に書き出しておきます。たとえば「本番デプロイの実行ボタンは人間が押す」「顧客向けメールの送信は人間が最終確認する」「契約条件を含む文書の発行は人間が承認する」「公開記事の公開ボタンは人間が押す」といった粒度です。AI に下書き作成・差分要約・案出しを任せても、最終 OK を出す主体は人間に残す形で業務フローに書き残します。判断軸は「最終 OK を誰が出すかが、業務フロー上に文章として残っているか」で、残っていない範囲は AI 任せに流れ込みやすくなります。
AI と人間の確認分担を自分の業務に当てはめようとして、線が引けずに止まっている方は、お問い合わせフォームからご相談いただけます。検証設計や責任分界の整理は、Be のご支援対象です。
まとめ
AI 出力の確認は一つの作業ではなく、review・evaluation・test・diff・human check の 5 工程に分けて考えると判断しやすくなります。結論は「AI を信用しない」ではなく「信用する場所と止める場所を分ける」で、自分の業務で線が引けない状態のまま AI 自動化を進めると後で破綻します。検証設計や責任分界の整理は受注導線として開けておきます。
5 工程の役割をもう一度短く並べると、review は「内容を読む確認」、evaluation は「基準で測る確認」、test は「実際に動くかを見る確認」、diff は「変更前後を見る確認」、human check は「責任を持つ人間の最終確認」になります。AI に任せやすいのは形式面の確認で、人間が必ず見るべきなのは業務判断・セキュリティ・本番反映です。Claude Code を含む AI エージェントの完了報告は受け取りつつも、git status と git diff・テスト再実行・公開前の最終読みを自分の手で踏む運用にすると、虚偽完了パターンに早めに気づけます。
関連解説
- AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 — 作業種別ごとに AI 補助の効果が変わる前提を扱っており、本記事で言う「形式面の確認は AI に任せやすい」の根拠としてあわせて読めます。
次に読む記事
- 個人でAI自動化を運用するための入力・分類・出力ルール — 検証の分け方が固まった後に、AI 自動化の入力・分類・出力ルール設計へ進む順序の記事です。




