
AI が重要だと言われても、実際に仕事へ使おうとすると、急に分からなくなることがあります。
ChatGPT のような会話型AI、Claude Code のような開発支援、n8n のような自動化ツール、MCP、API、knowledge、memory、AIエージェント。どれもAIに関係しているように見えますが、同じ話なのか、別の話なのかが見えにくいからです。
多くの情報は「AIはすごい」「業務が変わる」「今すぐ使うべき」という話から始まります。けれど、実務で手が止まる理由はそこではありません。問題は、AIの性能ではなく、AIに関係する道具や考え方が同じ場所に並べられてしまい、自分の作業のどこに使えばよいのか判断できなくなることです。
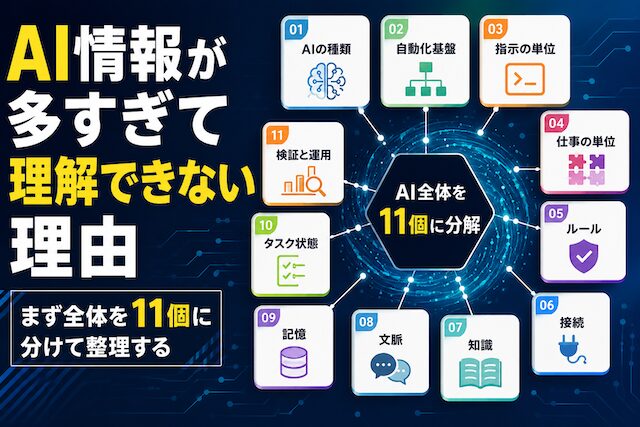
この記事では、AI関連でよく出てくる39個の用語を、11個のカテゴリに分けて整理します。1つずつ深掘りする記事ではありません。まずは、AI全体を地図のように眺められる状態にすることが目的です。
たとえば、ChatAIは「会話して考えるための道具」、AIエージェントは「目的に向かって作業を進める仕組み」、n8nは「処理をつなぐ自動化基盤」、MCPやAPIは「外部の情報や機能につなぐ口」として分けて見ることができます。このように置き場所を分けるだけで、何を学べばよいのか、何を業務へ使えばよいのかが見えやすくなります。
対象は、SESだけではありません。社内SE、SIer、Web系、インフラ、業務系、フリーランスを目指す人、副業を考えている人も含めて、AIを仕事や収入導線にどうつなげるかを考えたいエンジニア向けです。
この記事を読み終えたときに残るのは、4レイヤー × 11カテゴリ × 39用語の整理図です。さらに、定型作業は自動化基盤へ、判断が必要な作業はAIエージェントへ、不確定な入力はLLM・検証・人間確認を組み合わせて扱う、という業務分解の見方も整理します。
AI用語を全部覚える必要はありません。まずは、同じ場所に見えていた情報を分けることです。分けられれば、自分の仕事のどこにAIを入れるべきかが見えてきます。
AI情報が多すぎて理解できない理由
AI が重要であるという話は耳に入ってくるが、自分の仕事にどう接続すればよいかが整理できないと感じている読者は多いです。動画や SNS では「すごい」「革命的」という情報ばかりが流れ、実務で何が止まっているのかは語られません。本章ではまず、なぜ AI 情報が多すぎて理解できないのかを構造的に切り分けます。
「すごい」「便利」だけでは自分の仕事に接続できない
動画や SNS で流れる「AI はすごい」「革命的」という情報を見ても、自分の業務にどう組み込むかは判断できません。印象論と実務接続のあいだに横たわる構造を最初に整理します。
印象論で止まるエンジニアと、実務接続まで進めるエンジニアの違いは、AI そのものへの興味の強さではありません。「自分の業務のどこを AI が担い、どこを人間が担い、どこを自動化基盤に任せるか」という分解の道具を持っているかどうかで分かれます。便利そうな新機能のニュースを 100 本見ても、この分解軸がなければ、自分の仕事の手前で情報が止まり続けます。
自立を目指すエンジニアの読者像と、AI 時代に「作業者」のままでいることの構造的なリスクについては、関連記事として AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由 を併読すると、印象論ではなく自分の業務に向き合う前提が整います。
違うレイヤーの話を同列に並べると整理できない
ChatAI と AIエージェント、n8n と AI を同じ話題として扱うと、何を選ぶべきかが見えなくなります。役割の違うものを同列に並べないために、レイヤーで切り分ける必要があります。
たとえば「ChatGPT を使えば業務が楽になる」と「n8n を導入すれば業務が自動化できる」は、しばしば同じ文脈で語られます。しかし前者は対話・生成のレイヤーで一問一答に答える話、後者は判断と推論を持たない自動化基盤で手順を確実に実行する話で、担う役割がまったく違います。比較対象として並べると、選定基準が崩れてしまいます。
提供形態という別の切り口から AI の使い方を整理した ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある も、レイヤー混同を解く視点として補助になります。本記事の 4 レイヤーとは別軸ですが、両方を持つと議論が安定します。
用語が混同されたまま自動化を始めると本番で止まる
memory と context、knowledge と RAG が混同されたまま自動化を組むと、本番で「会話が消えた」「過去を覚えていない」と止まります。用語の区別は設計の前提として最初に固める必要があります。
context は今のセッションで LLM に渡されるテキスト全体を指し、history はアプリ側に蓄積される会話ログを指します。memory はセッションをまたいで個人の習慣や判断を保持する仕組みで、knowledge は外部に置かれた共有可能な事実、RAG はその knowledge を検索して context に入れる設計パターンです。これらをすべて「AI の記憶」と一括りにして設計すると、「ベクトル DB を入れたのに前回の会話を覚えていない」という現象に必ずぶつかります。
全体を11カテゴリで地図化する

AI 関連で頻出する 39 用語を、本記事では 11 カテゴリに分けて地図化します。深掘りではなく、まず全体像を読者の頭の中に置くことを優先します。後続記事ではこのカテゴリごとに 1 本ずつ分解していきます。
11カテゴリの一覧と狙い
Iの種類 / 自動化基盤 / 指示の単位 / 仕事の単位 / ルール / 接続 / 知識 / 文脈 / 記憶 / タスク状態 / 検証と運用 の 11 カテゴリで全体を切り分けます。それぞれの狙いを 1 行ずつ提示します。
| 分類 | 内容 |
|---|---|
| AIの種類 | 対話するAIなのか、自律的に動くAIなのか、常駐するのかを切り分ける |
| 自動化基盤 | 判断を持たない実行レイヤー、n8nなどをAIと別レイヤーに置く |
| 指示の単位 | AIに渡す情報の種類と寿命、commands / UI / instructionsを分ける |
| 仕事の単位 | 1つの仕事をskill / workflow / task / handoffのどれで束ねるかを選ぶ |
| ルール | 何をしてよいか、rules / guardrails / permission / approvalを別レイヤーで持つ |
| 接続 | 何に触れるか、tools / MCP / API / file / Gitを指示と分けて設計する |
| 知識 | 外部に置く共有可能な事実、knowledge / Markdown / Wiki / RAGを扱う |
| 文脈 | 今のセッション内の話、context / historyとして閉じる |
| 記憶 | セッションをまたぐ個人の習慣、memoryを別レイヤーで保持する |
| タスク状態 | 途中成果やタスク状態を外に持って中断・再開に耐えられるようにする |
| 検証と運用 | review / evaluation / test / human check / log / monitoring / retry / rollbackを最後に組み込む |
なぜ「11」なのか — 多すぎず少なすぎない分割粒度
4 レイヤーだけでは粒度が荒すぎて停止点に届かず、20 以上に分けると地図として機能しません。11 という粒度は、読者が自分の業務と接続できる単位として選んでいます。
4 レイヤー (対話・生成 / AIエージェント / 自動化基盤 / 接続・知識強化) は議論の同列化を避けるための大分類としては優秀ですが、たとえば「rules と tools の違い」「context と memory の違い」のように、設計時に必ずぶつかる停止点までは届きません。一方、20 カテゴリ・30 カテゴリへ分けると、読者は地図を覚えられず、参照する道具として使えなくなります。本記事の 11 という数は、停止点に届く粒度を保ちつつ、頭の中に並べておける上限として選んだものです。
39用語を11カテゴリにマッピングする
ChatAI / AIエージェント / commands / skills / rules / tools / MCP / knowledge / memory / context / log など 39 用語が、それぞれどのカテゴリに属するかを 1 枚の表で並べます。記事末尾の図解と対応します。
| # | カテゴリ | 含む用語 |
|---|---|---|
| 1 | AIの種類 | ChatAI / AIエージェント / AIサブエージェント / マルチエージェント / HermesAgent |
| 2 | 自動化基盤 | n8n |
| 3 | 指示の単位 | commands / UI / instructions |
| 4 | 仕事の単位 | skills / workflow / task / handoff |
| 5 | ルール | rules / guardrails / permission / approval |
| 6 | 接続 | tools / MCP / API / file / Git |
| 7 | 知識 | knowledge / Markdown / Wiki / RAG |
| 8 | 文脈 | context / history |
| 9 | 記憶 | memory |
| 10 | タスク状態 | 途中成果 / タスク状態 |
| 11 | 検証と運用 | review / evaluation / test / human check / log / monitoring / retry / rollback |
合計 39 用語を 11 カテゴリに収めた地図が、本シリーズの土台になります。視覚化したマップは下記の図解で確認できます。
AIの種類は4レイヤーで分ける
AI と一括りにされる領域を、対話・生成 / AIエージェント / 自動化基盤 / 接続・知識強化 の 4 レイヤーで分けると、議論の同列化を避けやすくなります。レイヤーが違えば担当役割も課金構造も変わります。

ChatAI と AIエージェント は別物
ChatGPT のように一問一答で応答する ChatAI と、目標を渡すと手順を決めてツールを連続呼び出しする AIエージェントは、役割と動き方が異なります。「エージェントも結局チャット」と思い込まないことが入口になります。
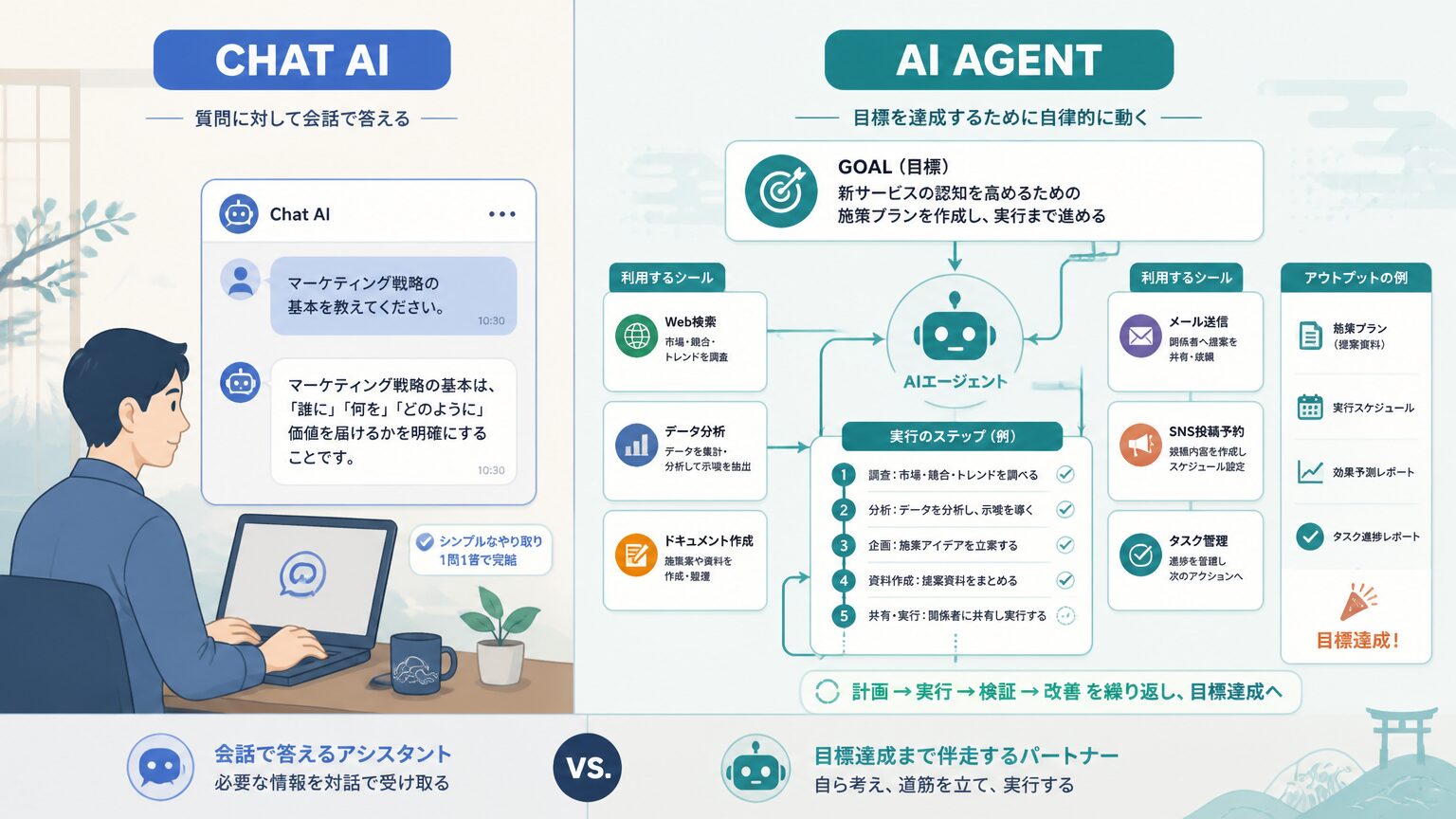
ChatAI は人間からの入力 1 つに対して応答 1 つを返す対話レイヤーで、設計の責任は人間側にあります。AIエージェントは目標を渡すと、必要なツールの呼び出し順や中間判断を AI 側が決めて動きます。両者を同じ「AI」として扱うと、「ChatGPT で十分なのにエージェントを使ってしまう」あるいは「エージェントが必要な業務に ChatAI を当てる」というミスマッチが起きやすくなります。
AIエージェントの中にサブエージェント・マルチエージェント・HermesAgent がある
AIエージェントの内側には、親エージェントが下位タスクを切り出すサブエージェント、複数のエージェントが分担するマルチエージェント、Nous Research の HermesAgent のような常駐型があります。本記事では位置づけのみ示し、深掘りは次記事に委ねます。
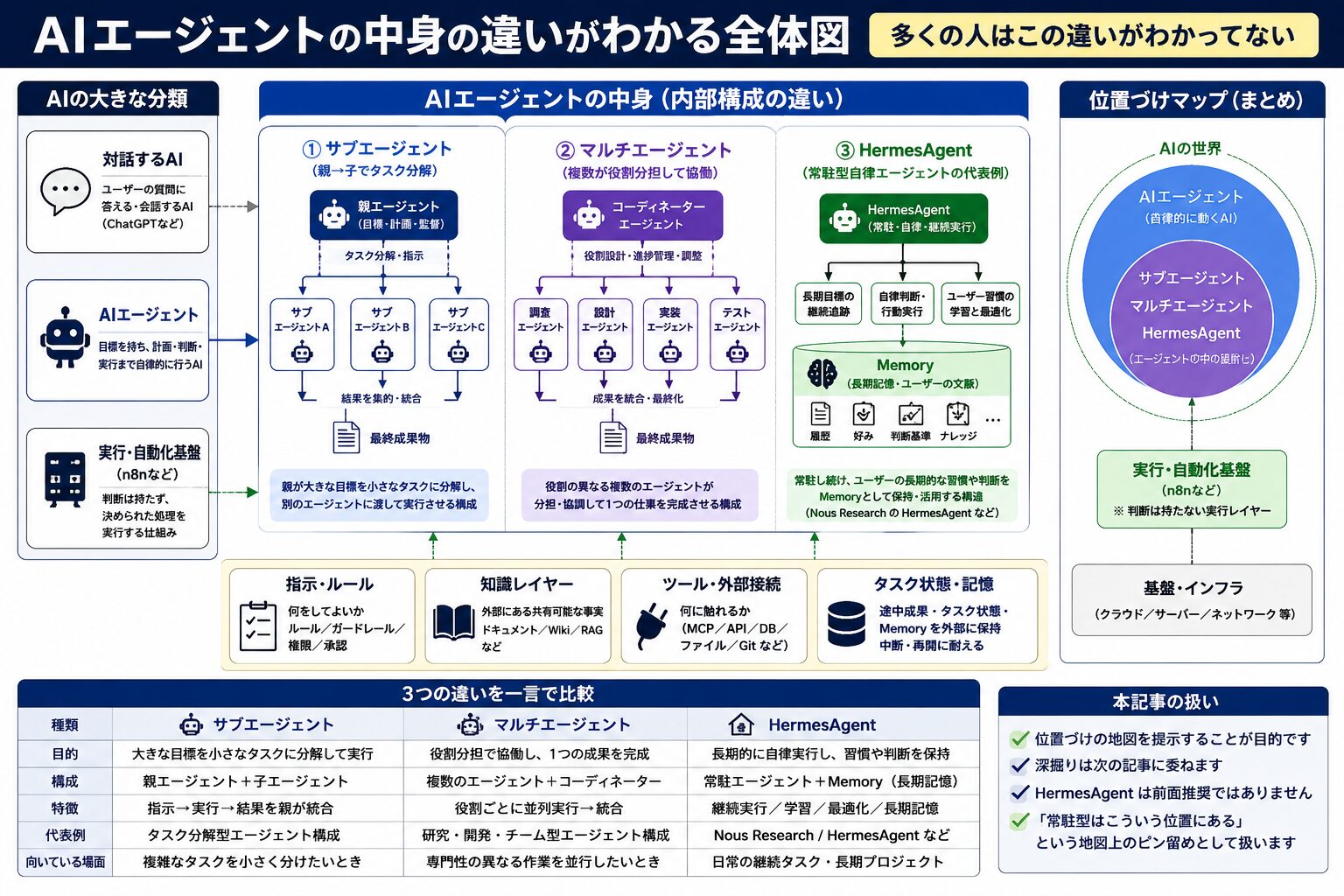
サブエージェントは、親エージェントが大きな目標を小さなタスクに分解して別のエージェントに渡す構成です。マルチエージェントは、役割の異なる複数のエージェントが分担して 1 つの仕事を完成させます。HermesAgent は常駐型自律エージェントの代表例として位置づけられるもので、ユーザーの長期的な習慣や判断を Memory として保持し続ける構造を持ちます。本シリーズでは前面推奨はせず、「常駐型はこういう位置にある」という地図上のピン留めとして扱います。
n8n は AI ではなく自動化基盤
n8n は判断と推論を持つ AI ではなく、定義された手順を確実に実行する自動化基盤です。AI ノードを内包していても n8n 自体が AI になるわけではありません。判断は AI、実行と記録は n8n という分担で見ます。
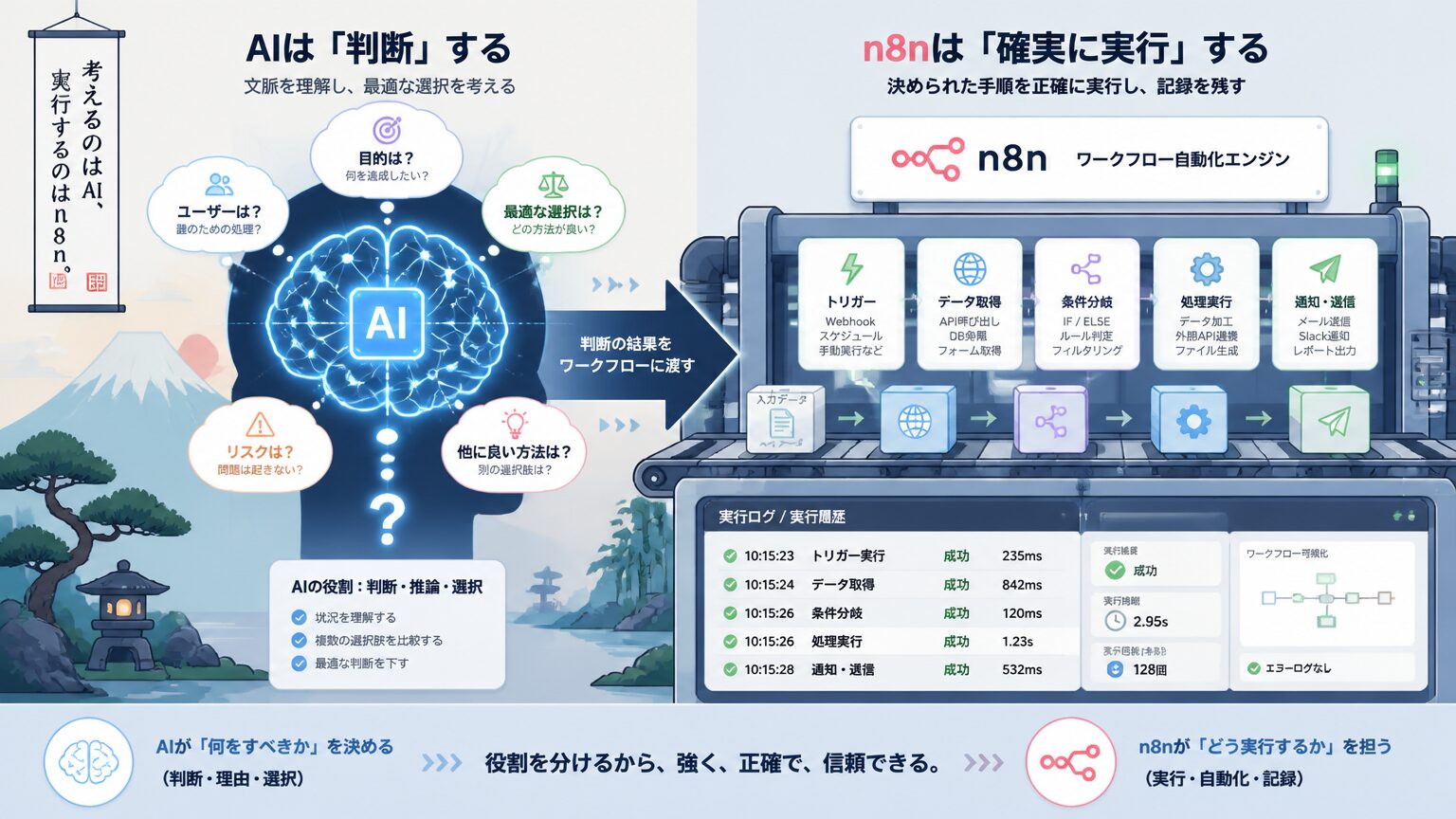
n8n を「AI 自動化ツール」と紹介する記事もありますが、n8n の本体機能は「事前に定義された手順を、トリガーに従って確実に実行し、ログを残す」という決定論的なオーケストレーションです。AI ノードを呼び出す機能はありますが、それは AI への入口を提供しているだけで、判断と推論を担当するのは呼び出された AI 側です。コスト構造の実例として n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算 を併読すると、AI を呼ぶ回数と自動化基盤の役割の違いがコストの面からも見えてきます。
指示・ルール・接続を分けて持つ
AI への指示の単位、仕事の単位、ルール、接続の仕組みを混ぜると「プロンプトさえ書けば動く」という思い込みに陥ります。役割ごとに置き場を分けるのが設計の前提となります。
指示の単位 (commands / UI / instructions)
ユーザーが入力するコマンド、画面上の UI、システムプロンプト的な instructions は、AI に渡される情報の種類と寿命が異なります。同じ「指示」でも別の置き場が必要になります。
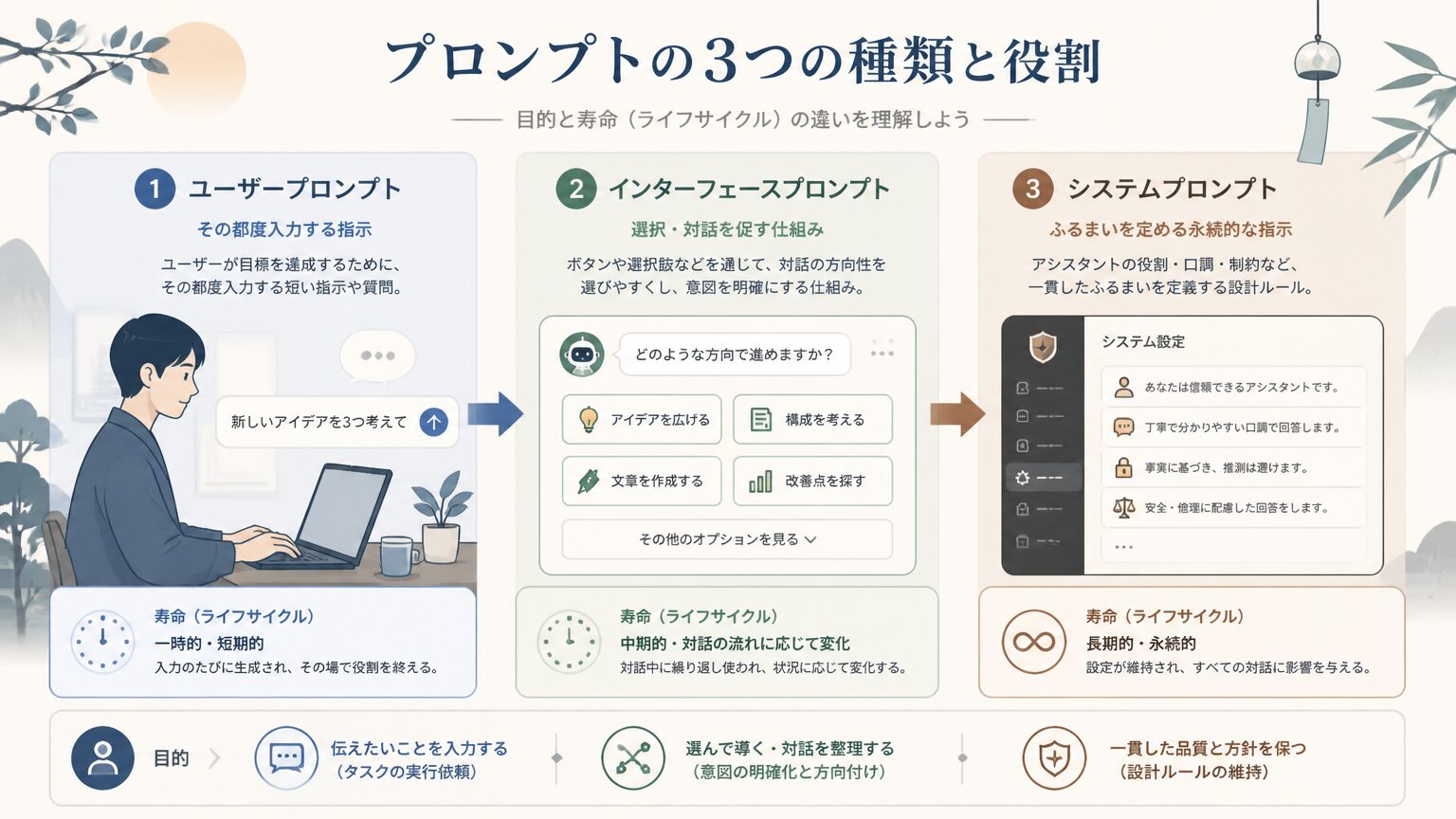
commands はユーザーがその場で打つ短い指示で、寿命は基本的にそのターン内に閉じます。UI はチャット欄・ボタン・選択肢といった人間とのインタラクション層で、ユーザーが何を選びやすいかを決めます。instructions は AI に対する設計者からの恒常的な指示で、システムプロンプトのようにセッションをまたいで効きます。これらを「全部プロンプト」と一括りにすると、ユーザー操作と設計者ルールが混ざり、変更時にどこを直せばよいか分からなくなります。

仕事の単位 (skills / workflow / task / handoff)
1 つの仕事を skill として束ねるか、workflow として手順で固定するか、task として渡すか、handoff で別エージェントへ移すかで設計が変わります。粒度の選び方が結果を左右します。
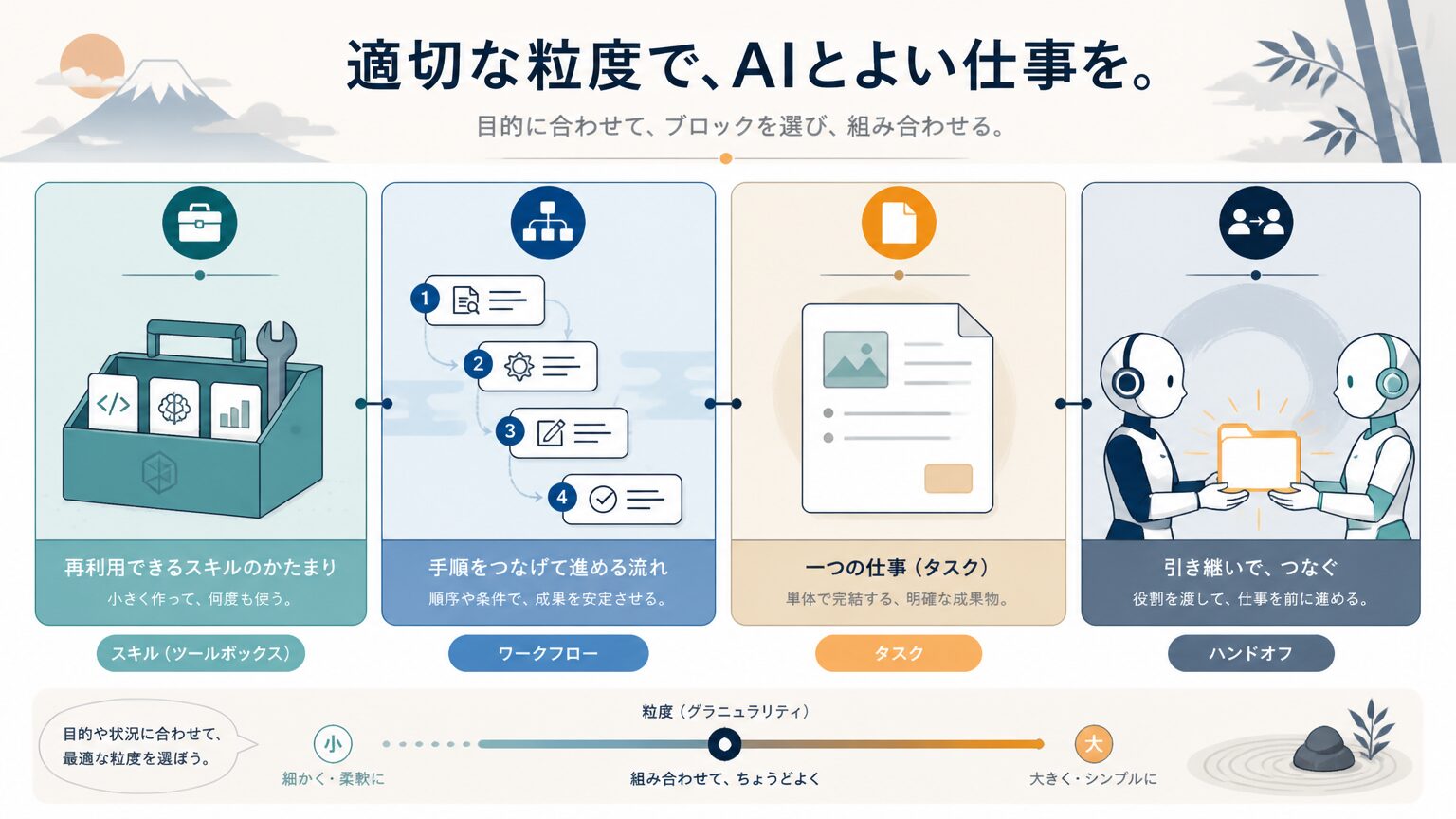
skill は「ある領域で AI が一貫して行える振る舞いのまとまり」を指し、再利用可能な単位として束ねます。workflow は手順を順序で固定するもので、確実性が必要な業務に向きます。task は単発で AI に渡す作業単位、handoff は別のエージェントへ仕事を引き渡す境界です。1 つの仕事を skill としてまとめるか workflow として固定するかで、変更耐性と確実性のバランスが変わります。

ルール (rules / guardrails / permission / approval) と接続 (tools / MCP / API / file / Git)
ルール系 (何をしてよいか) と接続系 (何に触れるか) は別々に持つ必要があります。permission を全許可で始めると事故になりやすく、MCP は API ではなく規約として扱う点も押さえます。
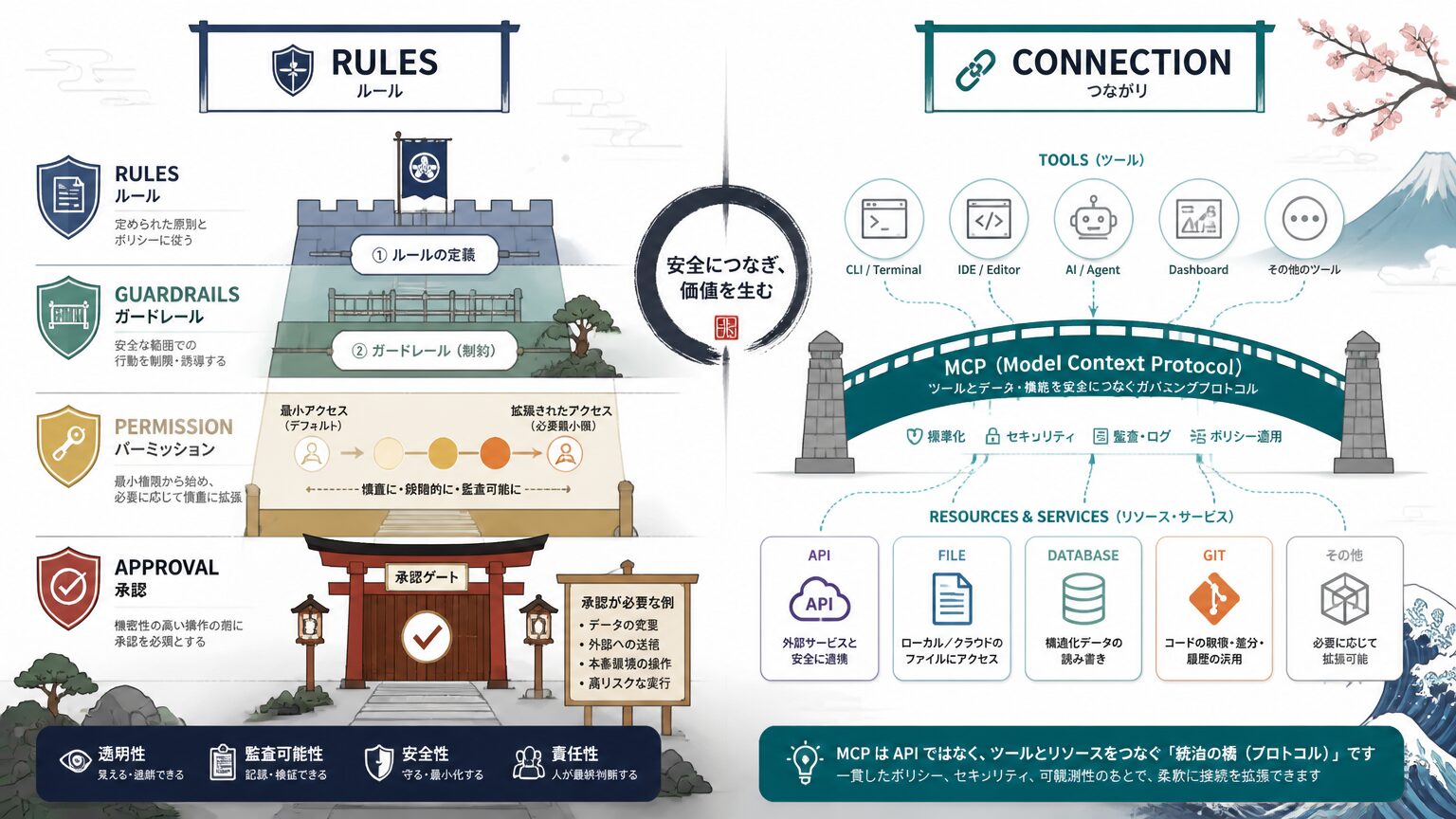
rules は AI に守らせたい原則、guardrails は逸脱を防ぐための具体的な制約、permission はツール呼び出しや操作の許可範囲、approval は人間が承認しないと進めない関門です。一方、tools は AI が呼び出せる機能、MCP は AI とツールをつなぐための共通規約 (具体的な API そのものではない)、API は実際の通信エンドポイント、file はローカル / クラウド上のファイル、Git はリポジトリ操作です。permission を最初から全許可で始めると、誤操作・誤削除のリスクが上がります。最小許可で開始し、必要に応じて approval で段階を作るのが、停止点を増やさない設計の前提です。

知識・記憶・文脈を混ぜない
context / history / memory / knowledge / RAG は混同されやすいですが、保持する範囲と管理者がそれぞれ異なります。混ぜたまま設計すると「セッション閉じたら会話が消えた」「RAG を入れたのに過去を覚えていない」と止まります。
context / history は今のセッションの話
context は LLM に渡されるテキスト全体、history はアプリ側に蓄積される会話ログです。長い会話を続けても LLM は context window で打ち切るため、蓄積されるのはアプリ側だけになります。
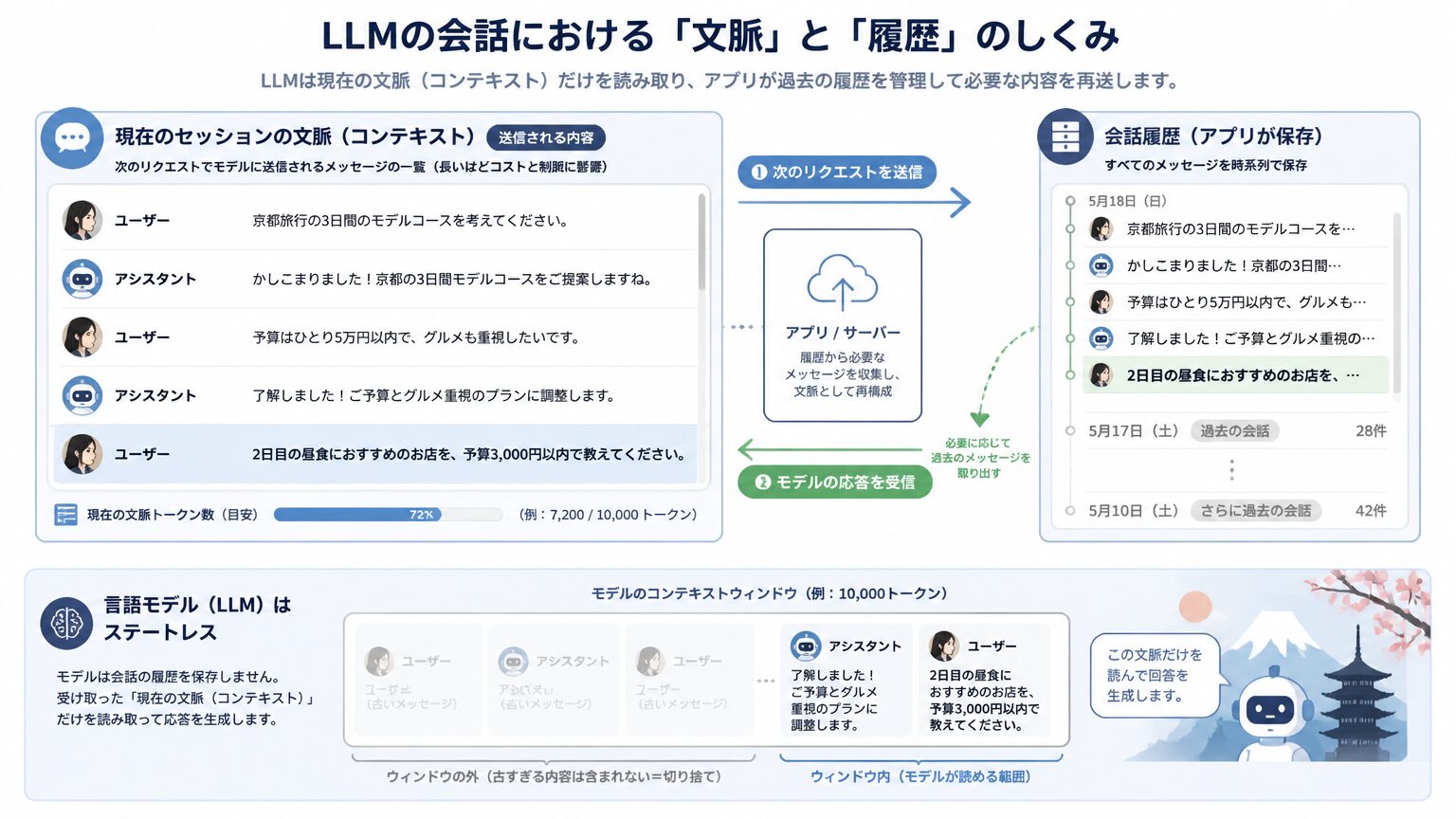
LLM はステートレスで、毎回のリクエストで渡された context 全体だけを見て応答します。会話が長くなれば context window の上限に達して古い部分から切り捨てられ、LLM 側に「前回の話の続き」が自動的に残ることはありません。history はアプリ側で会話ログを保持しているだけで、それを次のリクエストで context に詰め直すかどうかは設計者の判断です。「ChatGPT は前回の会話を覚えている」ように見えるとき、覚えているのはアプリ側であって LLM ではない、という区別が出発点になります。
memory はセッションをまたぐ話
memory はセッション横断で個人の習慣や過去の判断を保持する仕組みです。Claude Code の auto-memory や HermesAgent の Memory が代表例で、history とは別のレイヤーで動きます。
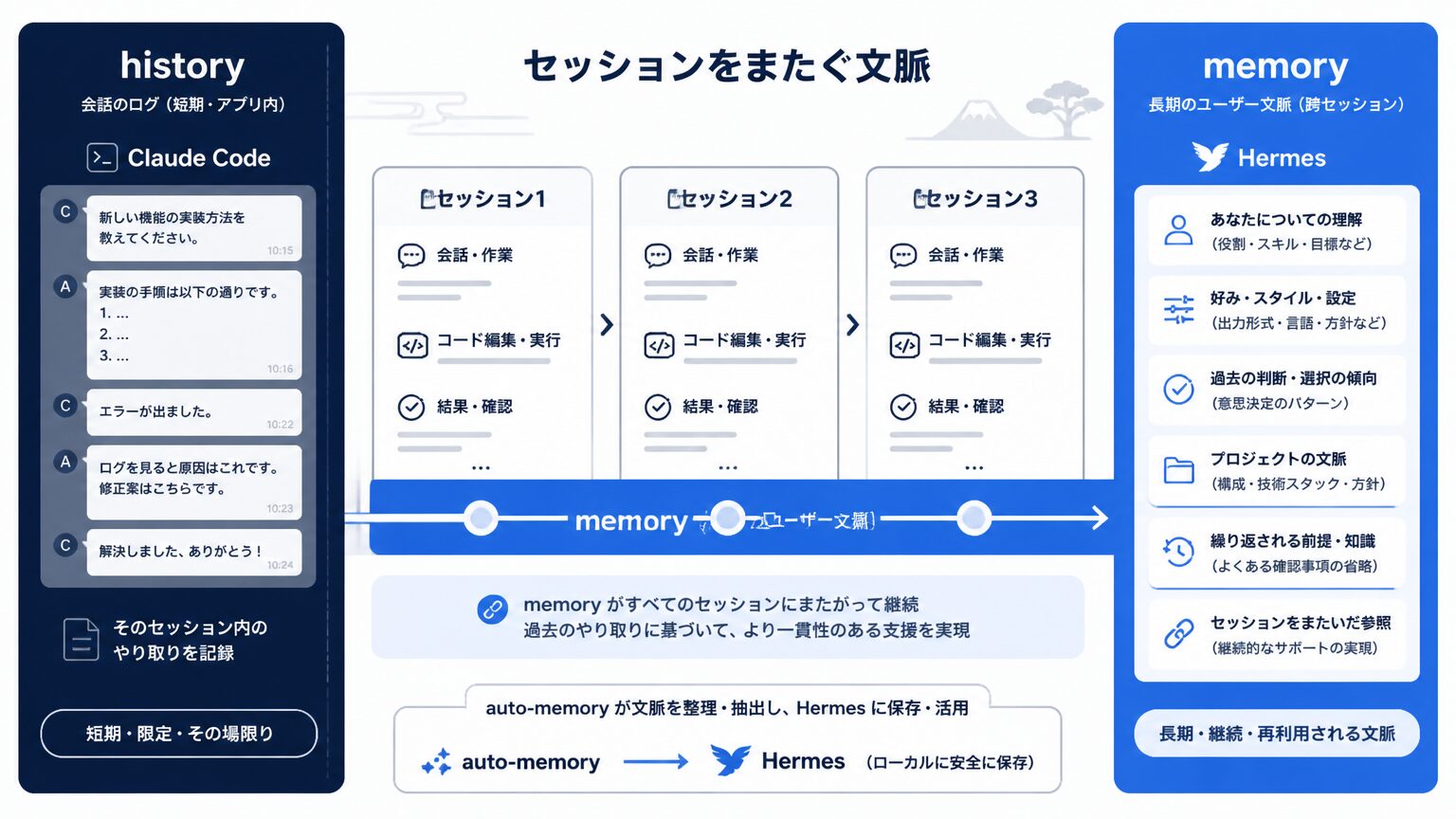
memory は、ユーザーが繰り返し使う前提・好み・過去の判断などを、セッションが変わっても引き継げるように外部に保持する仕組みです。history がアプリ内の会話ログという閉じた範囲であるのに対し、memory は「ユーザーの長期的な文脈」として、セッションをまたいで参照されます。なぜ AI は記憶を持ちにくいのか、どこに構造的な限界があるのかは、AIが避け続ける"時間"という領域──最も人間に近づく構造を持たない理由 で深掘りしています。
knowledge / Markdown / Wiki / RAG は外部知識の話
knowledge は外部に置かれたドキュメント群、RAG はそれを検索して context に入れる設計パターンです。memory とは目的が違い、個人の習慣ではなく共有可能な事実を扱います。
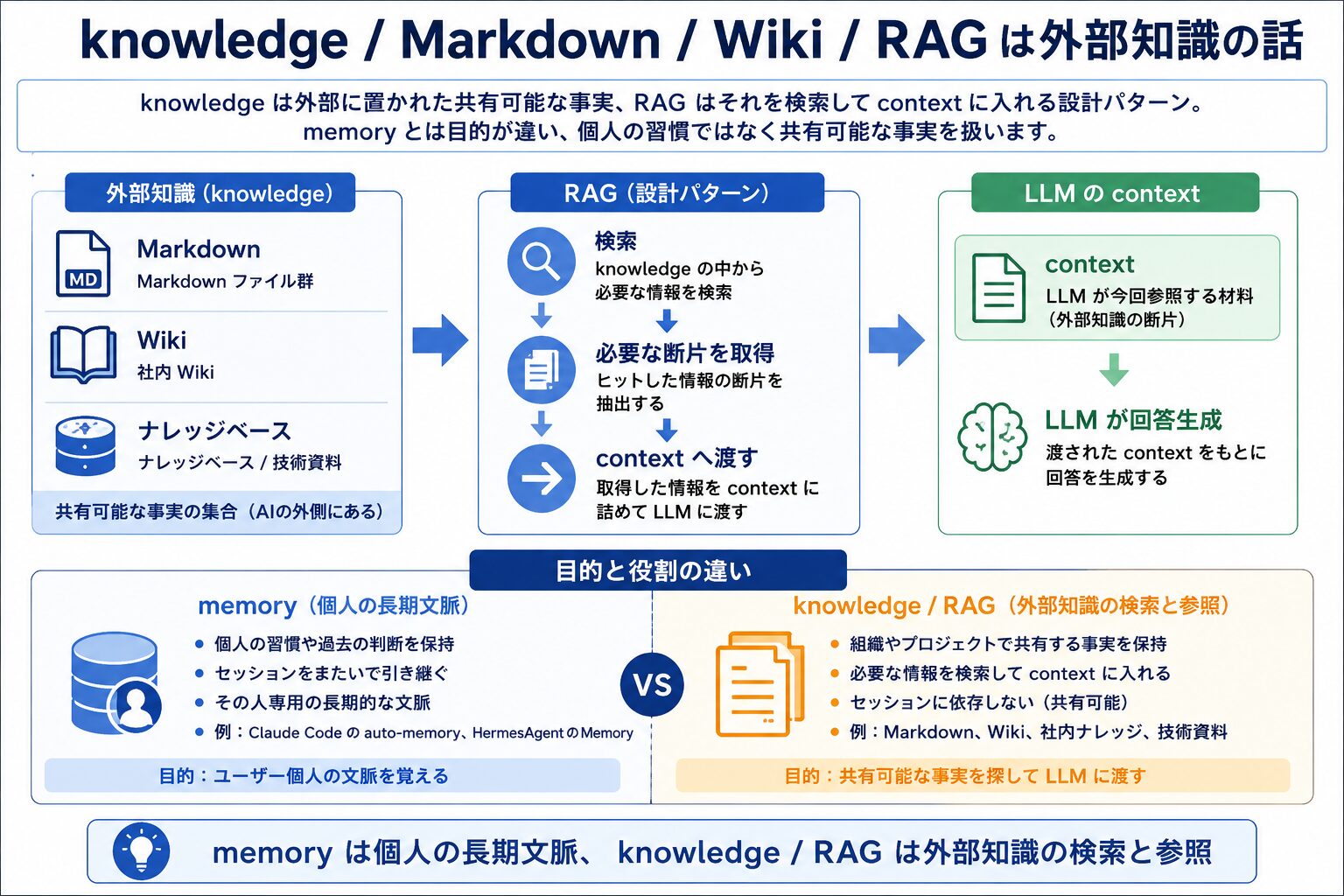
knowledge は Markdown ファイル群、社内 Wiki、ナレッジベースのように、AI の外側に置かれた共有可能な事実の集合です。RAG (Retrieval-Augmented Generation) はその knowledge を検索し、ヒットした断片を context に詰めて LLM に渡す設計パターンを指します。memory が「個人の習慣を覚える」目的であるのに対し、knowledge / RAG は「組織やプロジェクトで共有する事実を引き当てる」目的で、設計上の役割がまったく違います。混同するとベクトル DB を導入したのに前回の会話を覚えていないという現象につながります。詳細は AIが記憶を持てない理由と「ベクトルDB」が抱える構造的限界を暴く を参照してください。
検証と運用と判断軸を最後に組み込む
AI 自動化は作って終わりではなく、検証・運用・判断軸を組み込まないと本番で壊れます。本章では入口記事として 3 観点を輪郭だけ提示し、詳細はシリーズ後続記事に委ねます。
途中成果・タスク状態と検証 (review / evaluation / test / human check)
途中成果やタスク状態を外に持ち、review / evaluation / test / human check で検証する仕組みが必要になります。「AI が言ったから正しい」で止まらないための前提となります。
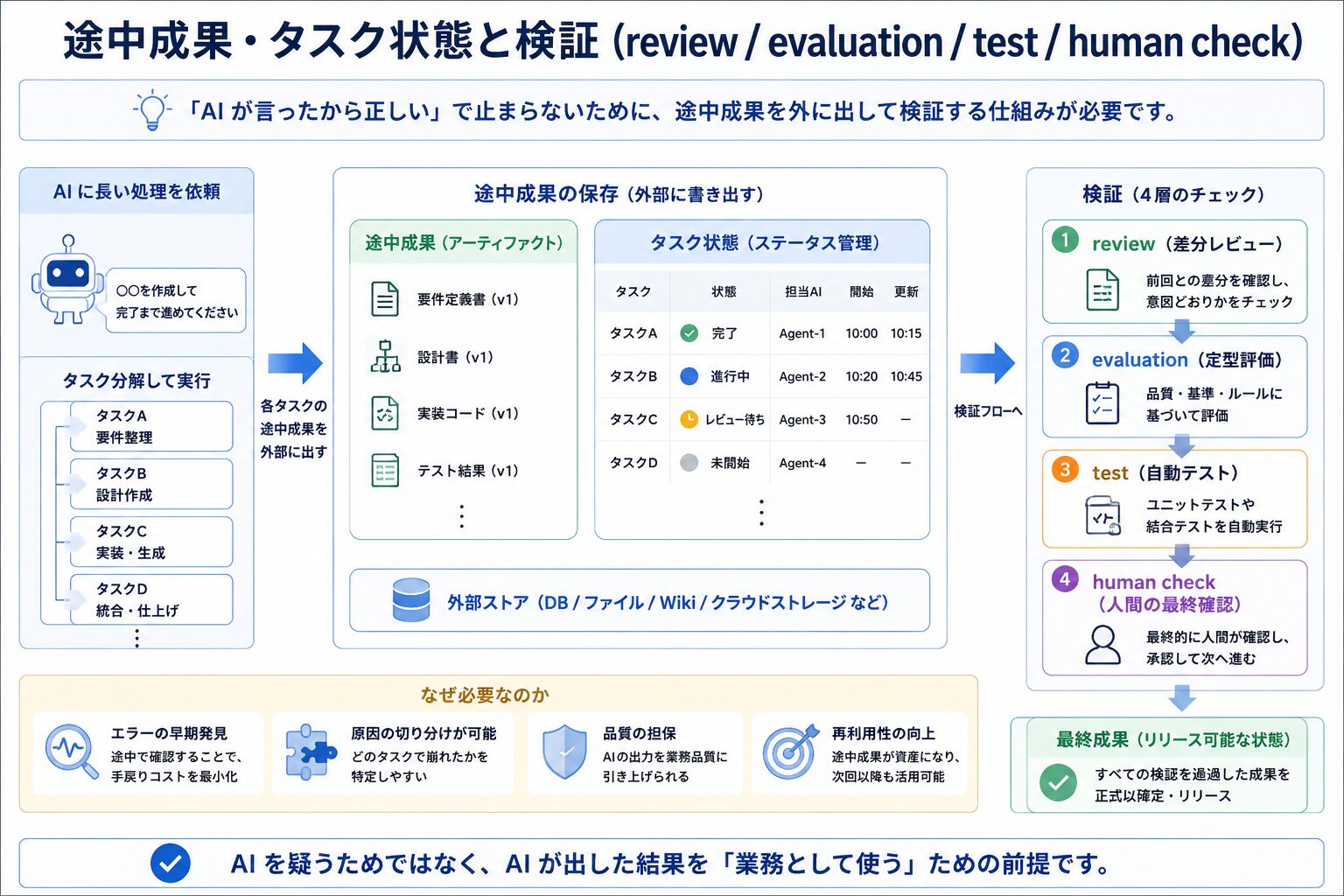
長い処理を AI に任せると、途中の出力をどこかで人間が確認しないと、最終結果が崩れたときに原因の特定ができません。途中成果は外部に書き出し、タスク状態は外部のストアに持って、review (差分レビュー) / evaluation (定型評価) / test (自動テスト) / human check (人間の最終確認) を組み合わせて検証する設計が必要になります。これは AI を疑うためではなく、AI が出した結果を業務として使うための前提です。
運用 (log / monitoring / retry / rollback)
自動化が動き続けるためには、log で記録し、monitoring で異常を検知し、retry で再試行し、rollback で元に戻せる設計を最初から組みます。後付けでは間に合いません。
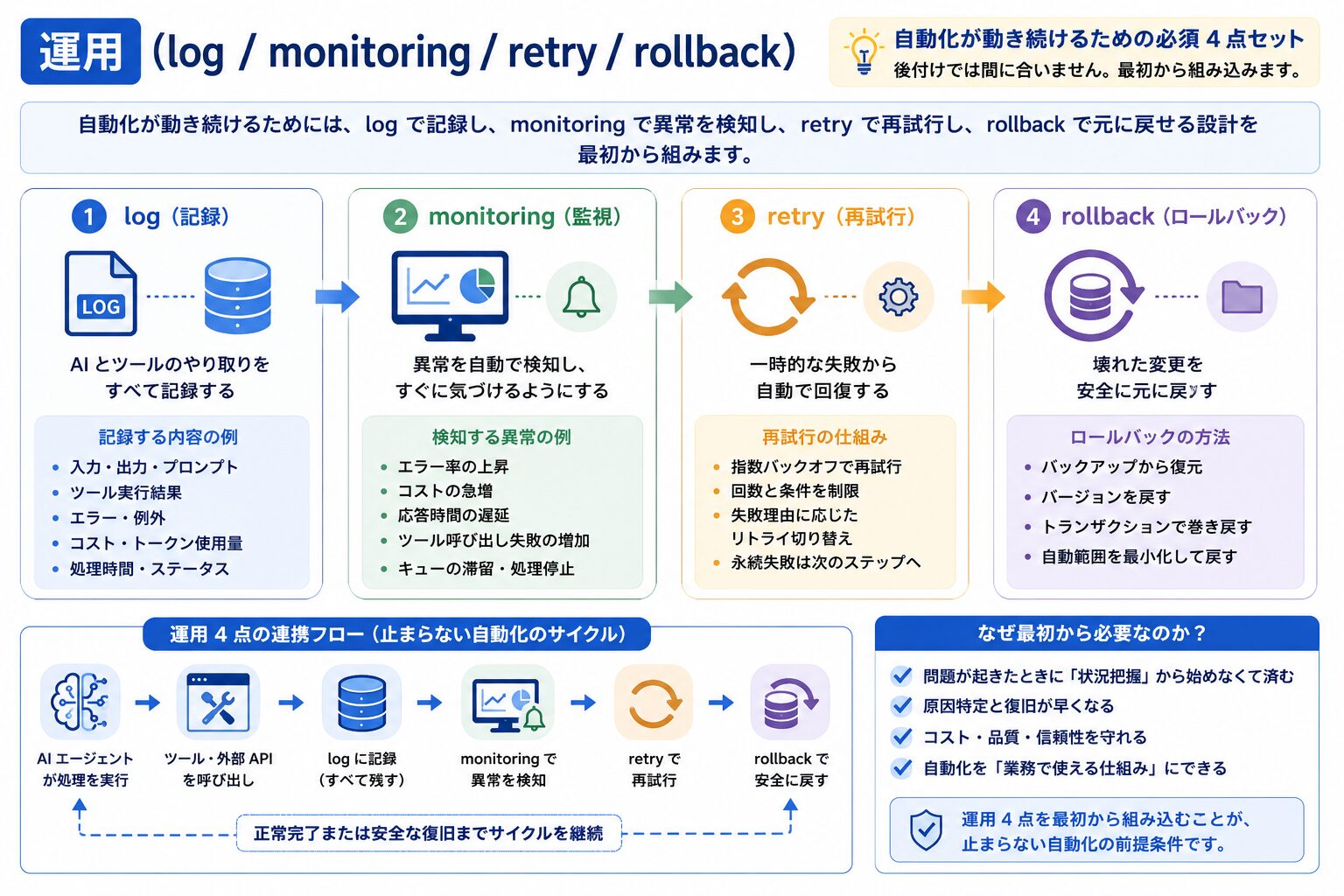
log は AI とツールのやり取りを記録し、monitoring は異常 (エラー率上昇・コスト急増・応答遅延) を検知し、retry は一時的な失敗からの自動復帰を担い、rollback は壊れた変更を元に戻す手段です。自動化が動き始めてから「ログがない」「異常検知が無い」と気づくと、止血の前に状況の把握から始めなければなりません。最初から運用 4 点を組み込んでおくことが、止まらない自動化の前提になります。
業務分解と判断軸 — 定型は自動化基盤、判断は AIエージェントへ
業務を入力・処理・出力に分解し、定型処理は自動化基盤、判断処理は AIエージェント、不確定入力は LLM + 検証 + 人間ゲートに振り分けると、AI を自分の仕事に組み込みやすくなります。
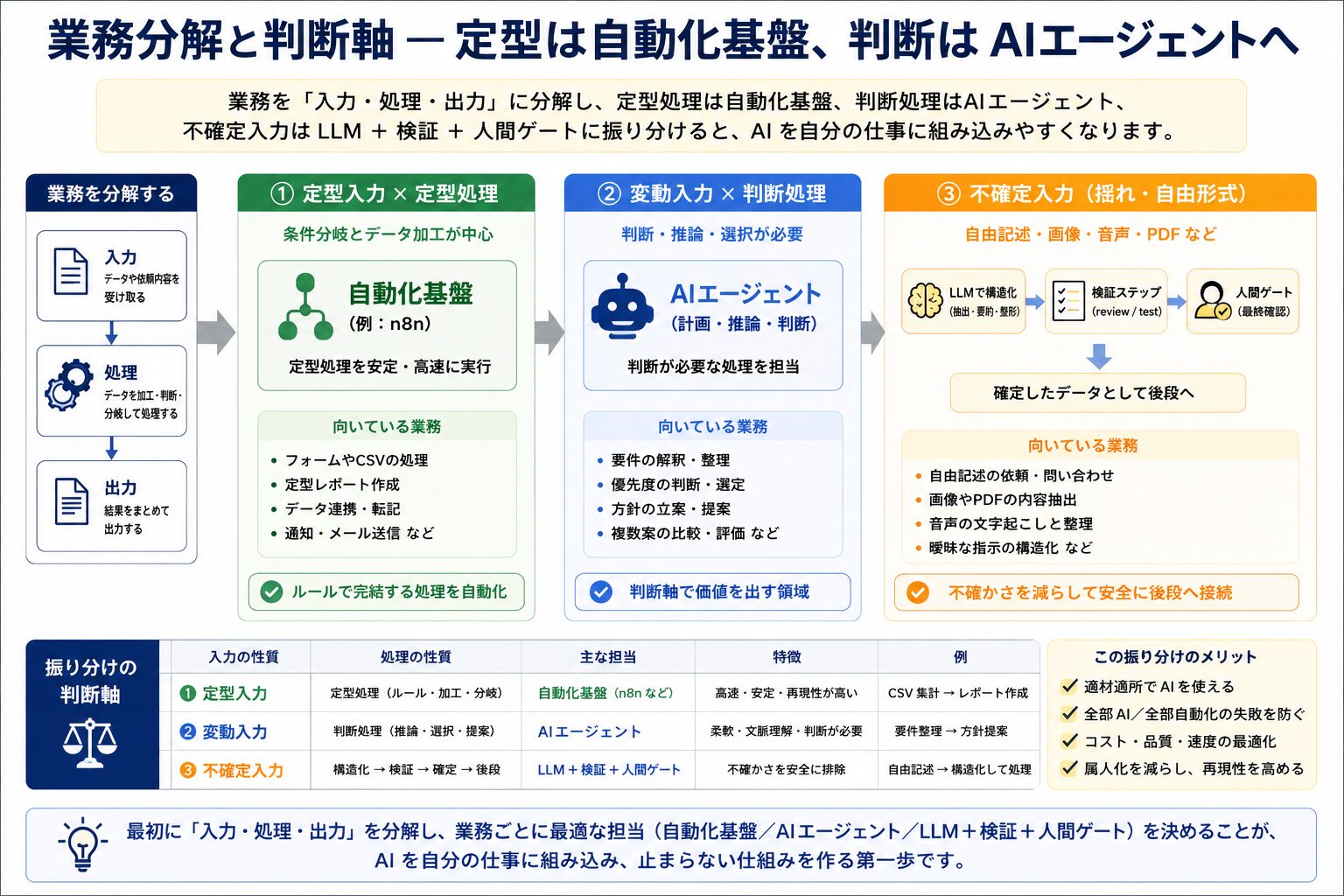
入力が定型で、処理も定型 (条件分岐とデータ加工のみ) なら、n8n のような自動化基盤に寄せます。入力に揺れがあり、処理に判断が必要なら、AIエージェントの担当領域です。入力が不確定 (自由記述・画像・音声・PDF など) なら、LLM で構造化し、検証ステップと人間ゲートを通してから後段に流すのが安全です。この振り分けを最初に決めると、「AI で全部やる」「全部自動化する」というオール or ナッシングの設計から抜け出せます。作業種別ごとの効率差については、AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 を併読すると、「判断 vs 作業」の別軸からも振り分け基準が補強されます。
まとめ
AI 情報を「すごい」「便利」で止めず、4 レイヤー × 11 カテゴリの地図と「定型 / 判断 / 不確定入力」の振り分けで、自分の仕事に AI を組み込むための分類軸を持つことが入口になります。次記事では、AIエージェントの種類 (ChatAI / AIエージェント / サブエージェント / HermesAgent / n8n) の違いをさらに分解していきます。
入口記事として本記事で押さえた 3 点は、(1) AI 情報が止まる原因は印象論・同列化・用語混同の 3 つに分解できる、(2) 11 カテゴリ × 39 用語の地図を頭に置けば、停止点ごとに必要な議論の場所が見える、(3) 業務は入力・処理・出力に分け、定型は自動化基盤・判断は AIエージェント・不確定入力は LLM + 検証 + 人間ゲートに振り分ける、です。この 3 点を土台に、シリーズの後続記事でカテゴリごとに 1 本ずつ深掘りしていきます。
次に読む記事
シリーズ入口記事として本記事で全体地図を提示しました。シリーズ途中記事の末尾遷移として、次に AIエージェントの種類そのものを分解する記事に進みます。
関連記事
本記事の論点を別軸から補強する記事です。読者像の補強や、AI の使い方を提供形態から見直す視点として併読してください。
- AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由
- ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある
- AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差
関連解説
知識・記憶・文脈の区別、n8n の役割についてさらに深掘りしたい場合は以下を参照してください。




