

ネットワークの現場では、通信トラブルの原因を迅速に特定し、効率よく対応する力が求められます。
そのために欠かせないのが、ARPとICMPという2つの基本的なプロトコルです。
ARPはIPアドレスとMACアドレスの対応関係を管理し、ICMPはネットワークの疎通状況や経路の問題を把握するための重要な役割を担っています。
この記事では、それぞれの仕組みや使い方、代表的な診断コマンドの操作方法について実践的に解説していきます。
読了後には、現場で即座に使える知識として、ネットワークの保守・運用に役立てることができるようになります。
ネットワークの基礎知識
🔴 ネットワークの基礎知識
📌 ゼロから理解する、実務に活かせるネットワーク思考
└─【ネットワークの基礎知識】ゼロから学ぶ|仕組み・構造・通信の基本を完全理解
├─【ネットワークの基礎知識】基本的な概念とネットワークの重要性
├─【ネットワークの基礎知識】IPアドレスとサブネット: 実務で活かせるネットワーク技術の基本
├─【ネットワークの基礎知識】MACアドレスとブロードキャスト: 通信の基礎と活用法
├─【ネットワークの基礎知識】ポート番号とトランスポート層の基本: TCP/UDPの使い分け
├─【ネットワークの基礎知識】DNSと名前解決の仕組み: IPアドレスとの関連性を理解する
├─【ネットワークの基礎知識】ルーティングの基礎: デフォルトゲートウェイと経路選択
├─【ネットワークの基礎知識】ネットワーク機器の役割と構造: ルータ・スイッチ・ハブの違い
├─【ネットワークの基礎知識】NATとプライベートIPアドレスの活用: グローバルIPとの変換技術
├─【ネットワークの基礎知識】ARPとICMPの基本操作: ネットワーク診断コマンドを使いこなす
├─【ネットワークの基礎知識】無線LANと有線LANの違い: 物理層における通信手段の選択
├─【ネットワークの基礎知識】帯域とレイテンシの理解: ネットワーク性能を支える基礎用語
└─【ネットワークの基礎知識】ネットワーク分離とVLANの概念: セキュリティと構成の最適化
ARPとICMPの役割と重要性
ネットワークの保守・運用において、通信経路の確認やエラーの原因特定は欠かせません。
その中でも、ARPとICMPは基礎でありながらも非常に重要なプロトコルです。これらは普段は意識されにくい存在ですが、トラブル対応時にはその本質が見えてきます。
ここではARPとICMPの基本的な役割と、実務でどのように利用されているのかについて解説します。
ネットワーク通信におけるARPの役割
ARP(Address Resolution Protocol)は、IPアドレスからMACアドレスを解決するためのプロトコルです。
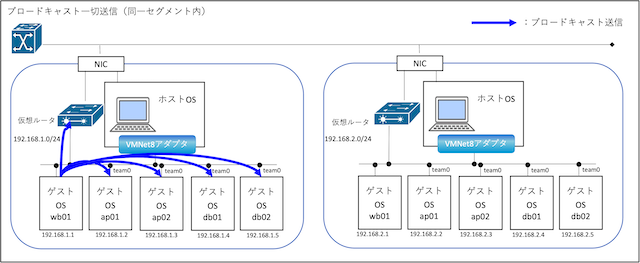
TCP/IPネットワークでは、通信の宛先を決定する際にMACアドレスが必要になります。IPアドレスしかわからない状況では、ARPによって対応するMACアドレスを取得します。
たとえば、PCが同一ネットワーク内の別の端末にパケットを送る場合、まずARPリクエストをブロードキャストで送信します。
ARPの仕組みを理解するために、MACアドレスやブロードキャスト通信の基本も併せて確認しておくと理解が深まります。
▶︎ 詳しくは「【ネットワークの基礎知識】MACアドレスとブロードキャスト: 通信の基礎と活用法」をご覧ください。

このリクエストに対して、該当するIPアドレスを持つ端末がARPリプライを返し、送信元PCはそのMACアドレスを取得して通信を開始します。
このように、ARPはローカルネットワーク内での通信を成立させるための鍵となる仕組みです。
ARP情報は一時的に「ARPテーブル」として保持され、再度の解決コストを削減しています。
ICMPによる通信エラー検知と経路把握
ICMP(Internet Control Message Protocol)は、IPネットワークにおいて通信状況やエラー情報を通知するための補助プロトコルです。
IPパケットの配送に失敗した際や、宛先に到達できない場合などに、その理由を通知するために使われます。
ICMPの代表的なメッセージには、次のようなものがあります。
| メッセージタイプ | 目的 |
|---|---|
| Echo Request / Echo Reply | pingで使用され、対象ノードの疎通確認 |
| Destination Unreachable | 到達不可の理由を通知 |
| Time Exceeded | ループやTTL超過などの経路問題を通知 |
ICMPは主にpingやtracerouteなどのネットワーク診断ツールの裏側で利用されており、普段目にすることは少ないですが、通信状態を把握するうえで不可欠なプロトコルです。
実務における活用シーンとその影響範囲
ARPとICMPは、ネットワークトラブルの初期調査や保守運用時に非常に役立ちます。
たとえば、LAN内の特定の端末にアクセスできない場合、ARPテーブルを確認することで正しいMACアドレスが設定されているかどうかをチェックできます。
必要に応じて手動でエントリを追加したり削除したりすることで、迅速な復旧が可能です。
一方、ICMPは疎通可否の確認だけでなく、ルーティングループやフィルタリングの有無を把握するのにも使われます。
ファイアウォールの設定やACL(アクセス制御リスト)によってICMPがブロックされていると、意図しない通信断が発生する場合があります。
以下のような簡単なコマンド操作で、ARPやICMPの効果を確認できます。
arp -a
ping 192.168.1.1
traceroute www.google.com
このように、ARPとICMPはネットワーク診断の基礎として非常に有効であり、理解しておくことで現場対応のスピードと正確性が大きく向上します。
ARPの基本動作と確認方法
ネットワーク上でデバイス同士が通信を行う際、ARPは欠かせない基盤技術です。
ARPの仕組みを理解することで、ネットワークトラブル時の解析や調査をより的確に行えるようになります。
ここでは、ARPの動作原理からコマンドによる確認方法、エントリ操作の注意点までを順に解説します。
ARPリクエストとARPリプライの仕組み
ARP(Address Resolution Protocol)は、IPアドレスに対応するMACアドレスを取得するために使用されるプロトコルです。
特に、イーサネットベースのローカルネットワークにおいて必須の機能です。通信を開始する際、送信元のデバイスは宛先IPアドレスに対応するMACアドレスが不明な場合、ARPリクエストをネットワーク上にブロードキャストします。
このパケットには、「このIPアドレスを持っているデバイスは、自分のMACアドレスを教えてください」という内容が含まれています。
対象のIPアドレスを持つデバイスがこのARPリクエストを受け取ると、自身のMACアドレスを含めたARPリプライをユニキャストで返します。これにより、送信元は宛先MACアドレスを把握できるようになり、データの送信が可能となります。
この一連のやりとりは、ネットワーク内部で自動的に行われるため、通常の利用者が意識することはほとんどありません。
しかし、トラブルが起きたときには、この仕組みを理解しているかどうかで対応の精度が変わってきます。
ARPテーブルの表示と内容の読み方
ARPによって解決されたIPアドレスとMACアドレスの対応関係は、一時的に「ARPテーブル」に保存されます。
このテーブルはキャッシュの役割を持っており、次回以降の通信時には再びARPリクエストを送らなくても通信が可能になります。
ARPテーブルの内容は、OSによって異なるコマンドで確認できます。たとえば、WindowsとLinuxでは以下のように確認します。
$ arp -a
? (192.168.1.1) at 00:1a:2b:3c:4d:5e on eth0 [ether]
? (192.168.1.10) at 00:11:22:33:44:55 on eth0 [ether] STALE
表示される内容には、以下のような情報が含まれます。
| IPアドレス | MACアドレス | インタフェース | 状態 |
|---|---|---|---|
| 192.168.1.1 | 00:1a:2b:3c:4d:5e | eth0 | REACHABLE |
| 192.168.1.10 | 00:11:22:33:44:55 | eth0 | STALE |
ip neigh show は、Linux環境における ARPテーブルの表示コマンドです。
$ ip neigh show
192.168.1.1 dev eth0 lladdr 00:1a:2b:3c:4d:5e REACHABLE
192.168.1.10 dev eth0 lladdr 00:11:22:33:44:55 STALE
「REACHABLE」や「STALE」といった状態は、ARPキャッシュの有効性を示しています。
| 状態 | 説明 |
|---|---|
| REACHABLE | 最近通信があり、接続が確認できている状態。MACアドレス情報が有効。 |
| STALE | 通信履歴はあるが、しばらくアクセスがなく状態不明。次の通信時に再確認される。 |
| DELAY | STALEの状態から通信が発生し、状態確認のために少し待機している。 |
| PROBE | 通信がないためARPを再送して応答を待っている状態。 |
| FAILED | ARP応答がなく、ホストが到達不能と判断された状態。 |
REACHABLEは最近通信があったことを示し、STALEは少し時間が経過したがまだキャッシュされていることを示します。
このテーブルを定期的に確認することで、意図しないMACアドレスの変更やARPスプーフィングといったセキュリティ上のリスクにも気づきやすくなります。
ARPエントリの手動操作とその注意点
ARPエントリは基本的に自動で管理されますが、特定の用途では手動で追加・削除を行うこともあります。
たとえば、一時的に通信相手のMACアドレスを固定したい場合や、ネットワーク機器の挙動を調査するために固定エントリを設定したい場合などが挙げられます。
Windowsの場合、手動でエントリを追加するには次のようなコマンドを使用します。
arp -s 192.168.1.1 00-11-22-33-44-55
Linux環境では次のように追加できます。
ip neigh add 192.168.1.1 lladdr 00:11:22:33:44:55 dev eth0
ただし、これらの手動設定は再起動やネットワーク再接続時に消失するため、一時的な対応策として使用することが多いです。永続化が必要な場合は、スクリプトに記述して起動時に実行されるよう設定する必要があります。
また、ARPエントリを手動で操作する際には誤設定に注意が必要です。誤ったMACアドレスを指定すると、意図しない通信断やルーティングエラーの原因になります。
特に複数の端末で同じIPアドレスを設定するような状況では、競合が発生してネットワーク障害を引き起こす可能性もあります。ARP操作は便利である反面、影響範囲が広いため、必ず慎重に行うことが求められます。
ICMPプロトコルの基本理解
ICMP(Internet Control Message Protocol)は、IP通信において状態通知やエラー報告を行うための補助的なプロトコルです。
通常のアプリケーション通信には直接使われませんが、ネットワークトラブルの発見や原因究明には欠かせない存在です。
このセクションでは、ICMPの仕組みと主要メッセージ、そして実務で注意すべきブロックのケースについて解説します。
Echo RequestとEcho Replyの仕組み
ICMPの中で最もよく使われているのが、Echo Request(エコーリクエスト)とEcho Reply(エコーリプライ)です。
これらは、ネットワーク上の端末同士の疎通を確認するために使用されます。
Echo Requestは「あなたは生きていますか?」という問い合わせに相当し、これに対するEcho Replyが「はい、生きています」という応答になります。
この仕組みは、pingコマンドを使用することで簡単に試すことができます。
ping 192.168.1.1
PING 192.168.1.1 (192.168.1.1) 56(84) bytes of data.
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.452 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.421 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.440 ms
64 bytes from 192.168.1.1: icmp_seq=4 ttl=64 time=0.436 ms
--- 192.168.1.1 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3060ms
rtt min/avg/max/mdev = 0.421/0.437/0.452/0.011 ms
上記のように、対象のIPアドレスを指定して実行すると、そのデバイスが応答可能であれば、一定の遅延時間(RTT: Round Trip Time)とともに返信が返ってきます。
これにより、通信経路の正常性や対象機器の生存確認が行えます。 Echo Request/ReplyはTCPやUDPとは異なり、状態を保持しないため、非常に軽量かつリアルタイム性が高いのが特徴です。
ICMPメッセージの種類と意味
ICMPには多数のメッセージタイプがあり、それぞれが異なる通信状況やエラー状態を示しています。
以下の表は代表的なICMPメッセージタイプとその意味をまとめたものです。
| メッセージタイプ | 名称 | 用途 |
|---|---|---|
| 0 | Echo Reply | 疎通確認への応答 |
| 3 | Destination Unreachable | 宛先への到達不可 |
| 5 | Redirect | より適切な経路を通知 |
| 8 | Echo Request | 疎通確認の要求 |
| 11 | Time Exceeded | TTL(生存時間)超過 |
特に「Destination Unreachable」や「Time Exceeded」は、ネットワーク経路における問題を示す重要な指標となります。
たとえば、ルーティングが誤っていたり、途中でフィルタリングされている場合にこれらのメッセージが返されます。
pingでICMPメッセージタイプ(Echo Reply)を確認する方法
pingコマンド単体では、ICMPメッセージのタイプ番号(例:Echo Request=タイプ8、Echo Reply=タイプ0)を確認することはできません。これらの詳細を確認するには、パケットキャプチャツールを用いる必要があります。代表的な方法は以下の通りです。
tcpdumpを使った確認方法
LinuxやmacOS環境であれば、ターミナルから以下のように入力します。
sudo tcpdump -n -v icmp
この状態で別ターミナルから ping コマンドを実行すると、送信されたICMPエコーリクエスト(タイプ8)と、応答として返ってくるエコーリプライ(タイプ0)が表示されます。
出力例:
IP 192.168.1.10 > 192.168.1.1: ICMP echo request, id 42, seq 1, length 64
IP 192.168.1.1 > 192.168.1.10: ICMP echo reply, id 42, seq 1, length 64
このように、"ICMP echo reply" の記述から、メッセージタイプが Echo Reply(タイプ0) であることがわかります。
より視覚的に確認したい場合は、Wiresharkが有効です。
ICMP通信にフィルタをかけることで、該当するICMPパケットのタイプが「Type: 0」や「Type: 8」として表示されます。
なぜping単体ではメッセージタイプが確認できないのか
pingはユーザ向けに疎通有無を表示するシンプルなツールであり、ICMPのメッセージタイプ番号までは表示しません。
内部的にICMP応答は処理されていますが、詳細なタイプ情報はツール側が省略しています。そのため、tcpdumpやWiresharkなどの補助ツールが必要になります。
Wiresharkを使った具体的な操作手順は以下の通りです。
Wiresharkでの確認方法
- Wiresharkを起動し、キャプチャを開始
- フィルター欄に icmp と入力してEnter
- pingコマンドを実行
- 表示されたパケットを選択し、詳細ペインで ICMP セクションを展開
- Typeの値を確認(Echo Requestなら8、Echo Replyなら0)
また、「Redirect」メッセージは、送信元に対して「より適切なゲートウェイが存在します」と伝える仕組みであり、ネットワーク設計の誤りや再構成を促すヒントになることがあります。
ICMPがブロックされるケースとその対処
ICMPは便利な反面、セキュリティ上の理由から企業ネットワークなどではブロックされることもあります。
これはDDoS攻撃やネットワーク探索(スキャン)にICMPが悪用される可能性があるためです。 代表的なブロックパターンとしては、以下のようなケースがあります。
| ブロック対象 | 影響 |
|---|---|
| Echo Request | pingが応答しない |
| Time Exceeded | tracerouteが途中で止まる |
| Destination Unreachable | ルーティングエラーの原因が不明になる |
このようなケースでは、ネットワークトラブルが起きたときに診断が困難になるため、完全なブロックは推奨されません。
代替手段として、内部向けのICMP通信だけを許可したり、特定のセグメントからのみICMPを受け付けるといった方法があります。
ファイアウォールやルーターの設定で、必要最小限のICMPメッセージを許可しておくことが現実的な対策となります。Linuxでの確認には以下のようなコマンドが使用できます。
iptables -L -v -n | grep icmp
また、企業内ネットワークにおいてICMPを全て遮断している場合は、代替手段としてSNMP監視や専用の死活監視ツールを導入することも検討すべきです。
tracerouteコマンドの基本と応用
ネットワークの問題を調査する際に、通信の経路を確認できる「traceroute」コマンドは非常に有用です。
本記事では、tracerouteの仕組みや基本的な使い方、TTLやICMPとの関係性、実行結果の見方までを体系的に解説します。
加えて、実務での応用例や注意点にも触れながら、ネットワーク診断にどう活かせるかを明らかにしていきます。
tracerouteとは何か?
tracerouteは、ネットワーク経路を確認するためのコマンドで、あるホストに到達するまでに経由するルーター(ホップ)を順番に表示する役割を持ちます。
pingが到達確認に使われるのに対し、tracerouteは途中経路の可視化が目的です。
このコマンドは各中継ルーターに対しTTL(Time To Live)を制限しながらICMPやUDPパケットを送信し、TTLの寿命が尽きた時点で返ってくるICMPエラーを利用して経路を確認しています。
TTLが1で送信された場合、最初のルーターで寿命が尽きるため、そのルーターの情報が取得できる、という仕組みです。
実行コマンドの構文と基本例
tracerouteコマンドはOSごとに若干の違いはあるものの、基本的な使い方は共通しています。
以下はLinuxおよびWindows、macOSにおける基本的な実行例です。
# Linux & MacOS
traceroute www.google.com
# WindowOS
tracert www.google.com
LinuxやmacOSではtracerouteコマンド、Windowsではtracertコマンドを使用します。
下記はLinux上での実行結果です。
traceroute to www.google.com (142.250.199.100), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 1.123 ms 0.987 ms 1.005 ms
2 10.20.30.1 (10.20.30.1) 3.456 ms 3.401 ms 3.377 ms
3 203.0.113.1 (203.0.113.1) 10.234 ms 10.189 ms 10.143 ms
4 *
5 142.250.199.100 (142.250.199.100) 23.456 ms 23.411 ms 23.367 ms
この出力から、通信がどのIPアドレスを経由して目的地に到達しているか、またそれぞれのホップでどれだけの応答時間がかかっているかが把握できます。アスタリスク(*)は応答が返ってこなかったことを示します。
WindowsとLinuxで出力形式が異なりますが、基本的な原理は同じです。
この出力では、目的のホストに到達するまでに4つのホップ(経路上のルーター)を通過していることがわかります。各ホップに対しては3回の試行が行われ、その応答時間(ms単位)が記録されています。
TTLの仕組みとICMPとの関係
tracerouteは、IPパケットに設定されるTTL(Time To Live)という値を意図的に1ずつ増やしながら送信することで、経路上のルーターを一つずつ特定する仕組みです。
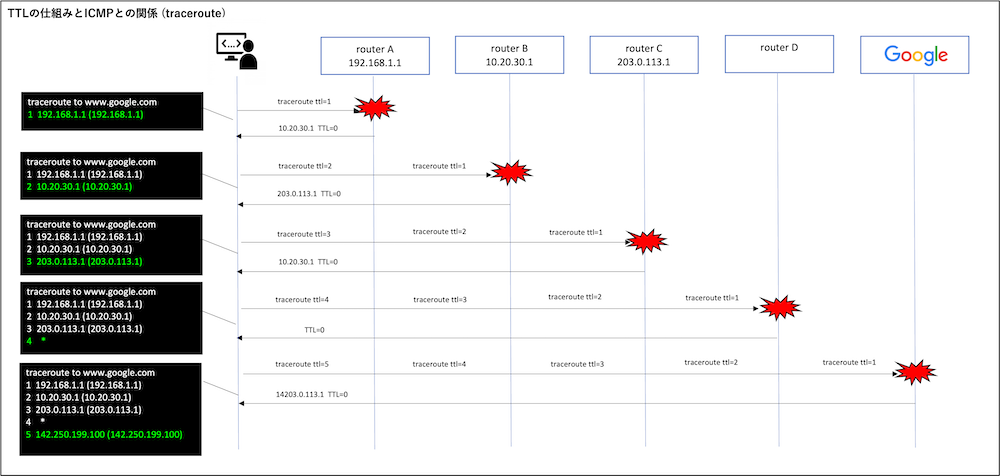
TTLとは、IPパケットが通過できるルーターの最大数を表す値で、各ルーターはこのTTLを1減らして転送します。
TTLが0になると、そのパケットは破棄され、「ICMP Time Exceeded(時間超過)」というエラーメッセージが送り返されます。
なぜTTL=1でエラーが返るのか?
TTL(Time To Live)は「パケットが通過できるルーターの最大数」を制限するカウントダウンタイマーのような仕組みです。
TTLが0以下で通過できるルーターは存在しないため、「パケットが消える」とICMPはエラー返すため、tracerouteはそれを受信して逆算的にルーターのIPを知ることが出来るのです。
tracerouteはこの特性を逆手に取り、以下のような操作を順番に行います:
TTL=1 の場合の通信フロー
- tracerouteはGoogleのIPアドレス宛にパケットを送る
- TTLを1に設定して送信する
- 最初のルーター(たとえば家庭内のルーターやISPの入り口)でTTLが1 → 0に減る
- TTLが0になると、パケットは「生存期限切れ」とみなされて破棄される
- ルーターは「TTLが尽きたこと」を通知するために、ICMPの「Time Exceeded」エラーを送信元に返す
このように、TTL=1,2,3…と順番に送ることで、そのTTL値に応じた位置のルーターからICMPエラーが返ってくるため、「どこを通って目的地に届いているか」が一目でわかるのです。
ちなみに下記のフローはTTL=2からのステップを記載しています。
TTL=2 の場合の通信フロー
- tracerouteが送信先(例:Google)に対してTTL=2のパケットを送る
- 最初のルーターでTTLが 2 → 1 に減少(TTL=1 の通信フロー)
- パケットは次のルーターへ転送される(まだTTLは残ってる)
- 2番目のルーターでTTLが 1 → 0 に減少
- TTL=0になったので、この2番目のルーターがパケットを破棄
- 破棄されたことを示すために、ICMP Time Exceeded エラーが送信元に返る
- tracerouteは、このICMPエラーの送り主のIPアドレスから、2番目のルーターの存在を把握
TTLの役割をひと言で言うと…
TTLは「無限ループや暴走を防ぐために、パケットに寿命を持たせるための仕組み」です。そのTTLをわざと1から増やしていくことで、ルーターを1個ずつあぶり出していくのがtracerouteです。
通信経路確認によるメリットと注意点
tracerouteの最大の利点は、どこで遅延や通信断が発生しているかを具体的に突き止められる点にあります。
例えば、特定のホップで応答が著しく遅かったり、* * *のように応答がまったくない場合、そのルーターやその先に問題がある可能性が高くなります。
ネットワーク診断における実用的な活用
tracerouteは、以下のような用途で有効に活用できます。
| 利用目的 | 活用方法 |
|---|---|
| 経路障害の特定 | どのルーター間で通信が途絶しているかを特定 |
| 遅延の発生箇所の可視化 | 特定ホップでの応答時間の上昇を確認 |
| VPNやNATの経路チェック | パケットが期待通りの経路を通過しているかを確認 |
また、トラブルが発生した際には、pingとtracerouteを併用することでより具体的な診断が可能になります。pingで応答がない場合に、tracerouteでどこまで到達しているかを見ることで、問題の切り分けがスムーズになります。
tracerouteによる経路の可視化と診断
ネットワークに障害や遅延が発生した際、その通信経路を把握することは非常に重要です。
tracerouteコマンドは、パケットが目的地に到達するまでのルート上の経路と遅延を可視化するために用いられます。
複雑なネットワーク構成や外部サイトとの接続不具合の原因追跡において、極めて有効な診断手段です。
中継ポイントの特定と応答時間の分析
中継ポイントとは、送信元から宛先へ向かう途中で通過するルーターのことです。tracerouteでは、これらのポイントとそこにかかる応答時間を一覧で取得できます。
traceroute to www.google.com (142.250.207.68), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 2.5 ms 2.4 ms 2.6 ms
2 10.10.0.1 (10.10.0.1) 10.3 ms 10.2 ms 10.1 ms
3 203.0.113.1 (203.0.113.1) 25.6 ms 25.7 ms 25.5 ms
4 203.0.113.2 (203.0.113.2) 28.1 ms 28.0 ms 28.2 ms
5 203.0.113.3 (203.0.113.3) 30.5 ms 30.4 ms 30.3 ms
6 198.51.100.1 (198.51.100.1) 33.8 ms 33.7 ms 33.6 ms
7 198.51.100.2 (198.51.100.2) 35.0 ms 35.2 ms 35.1 ms
8 198.51.100.3 (198.51.100.3) 39.6 ms 39.5 ms 39.4 ms
9 142.250.207.68 (142.250.207.68) 42.8 ms 42.6 ms 42.9 ms
上記のような実行により、以下のような出力が得られます。
このように、各中継ルータの応答時間を通して、ネットワークのどの地点でボトルネックが生じているかを把握することができます。
特定の地点で極端に遅延が発生している場合は、その機器の障害や輻輳が疑われます。
可視化とネットワーク診断への応用
tracerouteの出力は、ネットワークトポロジを図示するための基礎データとしても活用できます。ツールによってはこの情報をグラフ化し、視覚的に経路の全体像を把握することも可能です。
また、クラウドやグローバル通信環境においては、どの地域の中継地点が通信遅延の原因かを突き止める上で非常に効果的です。
ただし、tracerouteの結果は完全ではなく、ファイアウォールやルーターの設定によってICMP応答がブロックされている場合もあります。
これにより「*」が連続する場合や、経路の一部が非表示になることがあるため、結果の解釈には注意が必要です。
コマンド操作の実践例と出力の見方
ネットワーク診断コマンドは、単に実行するだけでは効果が半減してしまいます。
実際の出力内容を正確に読み取り、どのような状態であれば正常か、逆に異常かを見極める力が求められます。
このセクションでは、代表的なコマンドの出力例とその読み取り方、トラブルシューティングへの応用、ARPキャッシュの異常への対応方法について具体的に解説していきます。
pingとtracerouteの典型的な出力例
まずは、ネットワーク診断の代表格であるpingとtracerouteの出力例を見ていきます。
以下はpingコマンドの実行例です。
ping 192.168.1.1 出力例:
64 bytes from 192.168.1.1: icmp_seq=1 ttl=64 time=0.432 ms
64 bytes from 192.168.1.1: icmp_seq=2 ttl=64 time=0.410 ms
64 bytes from 192.168.1.1: icmp_seq=3 ttl=64 time=0.415 ms
この場合、通信は正常に行われており、RTT(応答時間)も安定しています。
応答がなく、"Destination Host Unreachable" や "Request timed out" などが出た場合は、通信経路のどこかで問題が発生していることを意味します。
続いて、tracerouteの出力例を見てみましょう。
traceroute www.google.com 出力例:
1 192.168.1.1 0.512 ms 0.478 ms 0.451 ms
2 10.10.0.1 1.205 ms 1.102 ms 1.110 ms
3 203.0.113.1 12.312 ms 12.501 ms 12.414 ms
4 * * *
5 142.250.224.78 23.301 ms 22.994 ms 23.100 ms
4ホップ目で応答が途切れていますが、その後のホップで応答があるため、途中のルーターがICMP応答を抑制しているだけと考えられます。
すべてのホップが「*」になる場合は、経路上の通信障害が強く疑われます。
トラブルシューティングへの応用方法
pingやtracerouteの結果をもとに、ネットワークトラブルを特定することが可能です。以下のようなシナリオに応じて、出力の意味を読み取る必要があります。
| 現象 | 診断コマンド | 想定される原因 |
|---|---|---|
| pingが通らない | ping | 機器停止、ファイアウォール遮断、IPアドレス誤設定 |
| traceroute途中で途切れる | traceroute | ルーター障害、経路ミス、ACLやICMPフィルタ |
| pingは通るが通信できない | ping, netstat | ポートフィルタ、サービス停止、ARP不整合 |
また、pingのRTT値が大きくばらつく場合は、通信経路の帯域不足や輻輳が発生している可能性があります。
その場合、tracerouteと組み合わせて遅延が発生しているホップを特定するとよいでしょう。
ARPキャッシュの異常時の対応例
ネットワークのトラブルでは、ARPキャッシュが原因となることも少なくありません。
特に同一ネットワーク内でIP重複がある場合や、スイッチの誤動作によりMACアドレスが書き換わるようなケースでは、ARPエントリが不正になることがあります。
以下は、ARPキャッシュの内容を確認するコマンドです。
arp -a
ip neigh show
ここで表示されるMACアドレスが、実際に意図したものと異なっている場合は、ARPスプーフィングや誤動作の可能性があります。
異常が見つかった場合の一時的な対処方法は、手動でARPキャッシュを削除または更新することです。
arp -d 192.168.1.100
ip neigh flush 192.168.1.100
このようにすることで、次回通信時に再度ARPリクエストが発行され、正しいMACアドレスが再取得される可能性があります。
ただし、再発が続く場合はスイッチや端末の構成ミス、またはセキュリティ攻撃を疑って調査を継続する必要があります。
継続的に問題が発生する場合は、ARPスプーフィング防止のためのスイッチ設定(動的ARP検出など)を見直すことも重要です。
ARPとICMPを活かしたネットワーク保守の実務
ネットワークの保守や運用では、トラブル発生時にいかに迅速かつ正確に原因を特定し、対処できるかが求められます。
その際に重要となるのが、ARPとICMPといった基礎的なプロトコルの活用です。
このセクションでは、社内ネットワークのトラブルシュート、セキュリティの観点、そして実務に役立つスクリプトの活用例について解説します。
社内LANのトラブル調査における利用例
社内LANでは、突発的に「通信できない」「プリンタが見つからない」「ネットが重い」といった問題が発生することがあります。
このようなときに、ARPとICMPを活用することで、問題の切り分けが効率よく行えます。 まず、pingによって対象機器の生存確認を行います。
ping 192.168.1.50
応答がない場合は、次にARPテーブルを確認し、MACアドレスの関連付けができているかを見ます。
arp -a
または、
ip neigh show ARP
テーブルに対象のIPアドレスが存在しない、もしくは不明なMACアドレスになっている場合、ネットワークスイッチの不具合やIP重複などが疑われます。
さらに、tracerouteを使ってネットワーク経路上で応答が止まっているポイントを確認することも有効です。
traceroute 192.168.1.50
このように、ping → ARP → tracerouteの流れで調査を行うことで、問題の位置を段階的に絞り込むことができます。
セキュリティ上の懸念と制御の考え方
ARPとICMPは診断に便利な一方で、セキュリティ上のリスクとなることもあります。
ARPは信頼性の低いプロトコルであり、ARPスプーフィングやグラチチュアスARPといった手法を用いた攻撃が可能です。
ICMPもまた、ネットワーク探索やDDoS攻撃の一端として利用されることがあります。 以下に代表的なリスクとその対策を示します。
| リスク | 発生要因 | 対策 |
|---|---|---|
| ARPスプーフィング | 偽のMACアドレスを送信 | スイッチのポートセキュリティ機能を有効化 |
| ICMPフラッド | 大量のpingを送信 | ICMPレート制限設定 |
| ICMPリダイレクト | 経路変更の誤誘導 | OS側でリダイレクト受信を拒否 |
ARPの制御には、スイッチ側での「動的ARP検出(DAI)」や「IP-MACバインディング」といったセキュリティ機能の導入が効果的です。
ICMPに関しては、完全に遮断してしまうとネットワーク診断ができなくなるため、社内のみ許可・外部遮断といった柔軟な設定が推奨されます。
現場で役立つ簡易診断スクリプトの活用
ネットワーク担当者は、繰り返し行う診断作業を効率化するために、簡易的なシェルスクリプトを用意しておくと便利です。
以下は、指定したIPアドレスに対してpingとarp情報をまとめて確認するスクリプトの例です。
#!/bin/bash
TARGET=$1
echo "===== PING ====="
ping -c 3 $TARGET
echo "===== ARP ====="
arp -a | grep $TARGET
このスクリプトは、引数で与えたIPアドレスに対して3回pingを実行し、その後ARPテーブルを確認するというものです。 使用例:
./netcheck.sh 192.168.1.10
応用として、複数のIPに対して一括実行するようなバージョンや、出力をログとして保存する機能を追加することも可能です。
現場での作業を効率化し、トラブル対応のスピードアップにつながります。 また、tracerouteの結果をファイルに出力して、後から比較・分析する方法も効果的です。
traceroute 192.168.1.10 > route_log.txt
このようなツールを活用することで、再発防止や定期点検にも役立ち、ネットワーク全体の安定性向上に寄与します。
まとめ
ARPとICMPは、ネットワークにおける通信の基盤を支える重要なプロトコルです。通常は裏側で動作しているため意識されにくい存在ですが、通信トラブルや保守・診断の場面ではその価値が一気に高まります。
本記事では、ARPによるアドレス解決の仕組みとテーブル操作、ICMPを活用した疎通確認や経路調査の方法、そして代表的なコマンドの出力とその見方について具体的に解説しました。
また、実務で遭遇するトラブル調査への応用方法や、セキュリティ上の注意点、業務効率を高めるスクリプトの活用例についても取り上げました。
これらの知識は、ネットワークの問題を「感覚」ではなく「構造」で捉える力を養うために欠かせません。
現場での対応力を高めるためにも、pingやarp、tracerouteなどの基本操作を繰り返し使いこなし、出力結果からネットワークの状態を正しく読み解ける力を身につけていきましょう。
次に読みたい記事はこちら
👉【ネットワークの基礎知識】無線LANと有線LANの違い: 物理層における通信手段の選択





