
n8nやAIエージェントを試してみたものの、最初の数回は動いてもすぐ運用が止まってしまう、という詰まりに心当たりはないでしょうか。フローは組めたのに、毎回入力データの形が違って判断が安定しない、出力を結局手作業で整え直している、そんな状態に戻ってしまう人は少なくありません。
原因はツール選びやノードの組み方ではなく、入力をどう受け取り、どう分類し、どんな出力にそろえるか、という運用ルールが設計されていない点にあります。ツールはルールを補ってくれません。ルールが曖昧なまま組まれた自動化は、最初の例外データで止まり、結局人間が再加工する作業に戻ってしまいます。
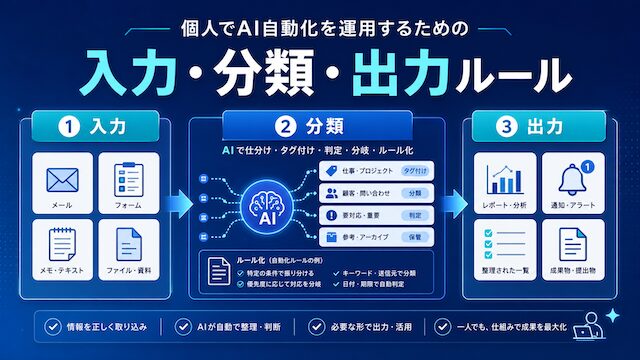
本記事では、AI自動化を個人で運用に乗せるための入力・分類・出力という3段階の運用ルール設計を整理します。完全自動化を狙わず、人間が確認する位置を残した上で、最小構成で書き出せる型を提示します。読み終えたとき、自分の業務をどこから入力・分類・出力に切り出すかという判断軸を持ち帰れる構成にしています。
AI自動化はツール導入では決まらず運用ルール設計で決まる
n8nやAIエージェントといったツールを揃えれば自動化が回る、という前提で導入が始まることが多くあります。ところが個人運用では、ツールを入れた後に運用が止まってしまう場面が頻発します。前回はAI自動化で作業者に戻らないためのn8nとAIエージェントの使い分けを扱いましたが、本記事ではその先で必要になる運用ルール設計を整理します。AI自動化の成否を決めているのはツール選びではなく、入力・分類・出力の運用ルール設計です。
n8nやAIエージェントを入れても運用できない理由
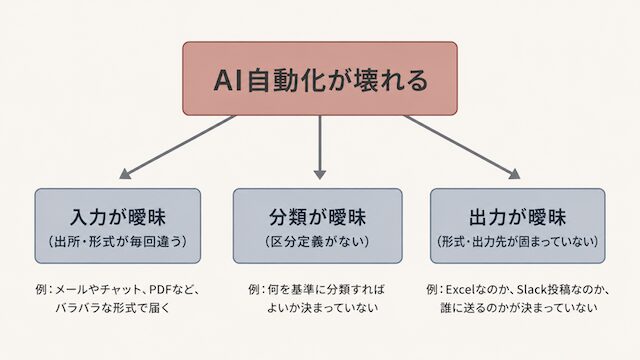
ツールを導入しても運用できないのは、入力・分類・出力のいずれか、あるいは複数が曖昧なまま組まれているからです。ツールは曖昧さを補ってくれません。
n8nのフローを組み立てる時点では、サンプルデータを通して動作確認する流れが一般的です。ところが運用に入ると、毎回違う形のデータが入力として流れてきます。出所が違う、項目数が違う、表記ゆれがある、空欄が混じる、といった揺らぎが起きるたびに、フローはどこかで詰まります。AIエージェントに判断を任せる場面でも同じで、入力の形がそろっていないと、毎回違う基準で判断が返ってきます。
運用が止まる理由をツール側に求めても解決しません。動かなくなるのはほぼ常に、入力か分類か出力のどこかでルールが言語化されていないことが原因です。
ツール選びより先に決めるべきは入力・分類・出力の型
どのツールを使うかではなく、何を入力として受け取り、どう分類し、どんな出力にそろえるかを先に決めると、ツール選びは自然と絞られます。
入力が決まっていれば、それを取得する手段としてn8nのトリガーノードで足りるのか、別の取り込み手段が必要なのかが見えます。分類が決まっていれば、明確な条件分岐で済むのか、文脈判断が必要でAIエージェントを挟むべきなのかが見えます。出力が決まっていれば、どこに何の形で書き出すかが決まり、後段の処理が安定します。
つまり3つの型が先にあれば、ツールは選択肢が絞り込まれた状態で選ぶ対象になります。逆にツールから先に選ぶと、ツールに合わせて運用を曲げる事態に陥ります。
個人運用は運用ルールが軽いほど続けやすい
個人で続ける運用ほど、ルールは軽いほど維持しやすくなります。複雑な分岐や例外を盛り込むより、最小構成で書き出した型を回し続ける方が結果として安定します。
組織であれば運用担当を分担できますが、個人運用では設計者と運用者が同一人物になります。複雑なルールを最初に組み込むと、本人の記憶からも外れていきます。半年後に自分が読んでも理解できる粒度で書き出しておく、というのが個人運用の現実的な基準です。n8nの運用コスト構造についてはn8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算でも整理しているとおり、運用負荷とコストの両面から軽さは効いてきます。
入力ルールを決めないとAIは判断できない
AIに判断を任せる場面では、入力の形が判断精度を直接左右します。入力ルールを決めないままAIに渡すと、毎回違う品質の判断が返ってきて運用に乗りません。本セクションでは入力ルールの最小構成を整理します。
入力の形を決めずにAIに渡すと結果が安定しない
同じテーマでも、与える情報の構造が毎回違えば、AIの判断はブレます。入力の構造を毎回そろえないと、判断結果を再利用できません。
たとえば問い合わせメールを分類するフローを考えると、ある日は本文だけ、別の日は件名と本文と添付ファイル名、また別の日は引用部分が大量に混じった本文、という形で入力が揺れます。AIはそのまま判断を返しますが、判断基準は入力の構造に引きずられて変わります。同じ問い合わせ内容でも、入力構造が違えば違う分類が返ってくる、という事態は十分に起こります。
判断結果を後段で再利用する前提なら、入力の構造をそろえる工程をAIに渡す前に必ず置く必要があります。
入力の出所と整形ルールをセットで決める
どこから入力を取るか (出所) と、どう整形してからAIに渡すか (整形ルール) は、必ずセットで決めます。出所だけ決めても整形が毎回違えば結果は安定しません。
出所は「Gmailの特定ラベル付きメール」「特定フォームの送信データ」「指定フォルダ内のCSV」といった具体的な取得元を指します。整形ルールは「件名と本文を結合して引用部分を除外」「日付列をISO形式に変換」「100文字を超える項目は要約を別フィールドに分ける」といった、AIに渡す前の前処理を指します。
出所と整形ルールがセットで言語化されていれば、入力データの揺れを前処理側で吸収でき、AIには毎回同じ構造の入力が届きます。ここを設計しないままAIに丸投げすると、判断のブレを後追いで補正する作業が発生します。
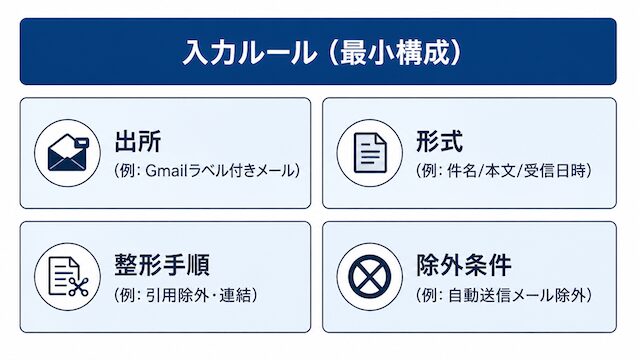
入力ルールの最小構成 (出所・形式・整形・除外条件)
入力ルールは「出所」「形式」「整形手順」「除外条件」の4点を書き出せば最小構成として機能します。最初からこれ以上を盛り込む必要はありません。
具体例として、問い合わせメール分類フローの入力ルールを書き出すと以下のようになります。
入力ルール:
出所: Gmailラベル "問い合わせ_新規" 付きの未読メール
形式: 件名 (string) / 本文 (string) / 受信日時 (ISO8601)
整形手順:
- 本文から引用部分 (>) で始まる行を除外
- 件名と本文を改行で連結し1フィールドにまとめる
- 添付ファイル名のみリスト化 (本文には含めない)
- 受信日時をISO8601文字列に正規化
除外条件:
- 件名に "[自動送信]" を含むメールは処理対象外
- 本文100文字未満のメールは人間確認キューに回す
この4点を書き出しておけば、後で運用者 (=自分) が読み返しても、何を入力として受け取っているかを再現できます。整形手順が言語化されているので、n8nやスクリプトで前処理を組み直す際の指針にもなります。除外条件を最初から置いておくのが重要で、想定外の入力が来たときに「処理しない」「人間確認に回す」という選択肢を持てるようになります。
分類ルールを決めないとn8nやAIエージェントの分岐が壊れる
入力をどう分類するかが決まっていないと、n8nのフロー分岐もAIエージェントの判断も同時に壊れます。分類はツールが決めるものではなく、運用設計者が事前に型を持っておく場所です。
分類が曖昧だと処理分岐とAI判断が両方壊れる
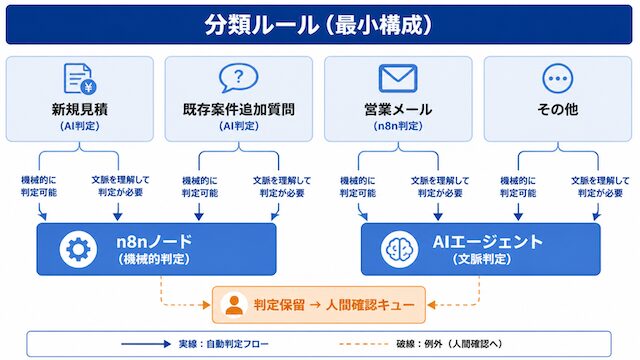
分類軸が曖昧だと、n8nのifノードはどこに振ればいいか分からず、AIも判断基準を毎回揺らします。分類は両者が共通で見る土台です。
問い合わせメールを「新規見積」「既存案件の追加質問」「営業メール」「その他」に分けたいとします。この4区分が運用設計者の頭の中だけにあって、どこにも書き出されていない場合、n8nのifノードは「件名に『見積』が含まれるか」程度の単純条件しか持てません。AIエージェントに判断を任せても、明確な区分定義がないので、ある日は「新規見積」、別の日は「既存案件の追加質問」と揺れた判断を返します。
分類軸が事前に書き出されていれば、n8nのifノードはどの条件を見ればいいかが固定でき、AIには区分定義をプロンプトに含めて判断させられます。両者が同じ分類定義を見ている状態を作れて、初めて運用が安定します。
n8nに任せる分類とAIエージェントに任せる分類を分ける
明確な条件で分けられる分類はn8nに、文脈や曖昧さを伴う分類はAIエージェントに振り分けます。境界を最初に引いておくと、後で破綻しません。
「件名に特定ワードが含まれる」「送信元ドメインが特定リストに一致する」「添付ファイルがある」といった機械的判定はn8nのifノードで処理します。一方、「文脈から見て新規見積依頼か既存案件の追加質問か」「営業メールかどうかの判断」といった文脈判断はAIエージェントに任せます。
最初にこの境界を引いておかないと、n8nの中で無理に複雑な条件式を組むか、逆にAIに機械的判定まで全部任せてAPI課金が膨らむかのどちらかに振れます。AI活用の効率差についてはAIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差でも触れていますが、向き不向きを設計時に切り分けることが運用の安定とコストの両面に効きます。
分類ルールの最小構成 (区分・優先度・例外区分)
分類ルールは「区分」「優先度」「例外区分」の3点で最小構成になります。例外区分を最初から置いておくと、想定外のデータが来ても運用が止まりません。
問い合わせメール分類フローの分類ルールを書き出すと以下のようになります。
分類ルール:
区分:
- 名称: 新規見積
判定: AIエージェント (文脈判断)
定義: 受注前段階の問い合わせ。価格・納期・体制の質問を含む
- 名称: 既存案件追加質問
判定: AIエージェント (文脈判断)
定義: 進行中案件への追加質問。既存スレッドの言及を含む
- 名称: 営業メール
判定: n8n (送信元ドメイン照合)
定義: 営業ドメインリストに一致するメール
- 名称: その他
判定: 上記いずれにも該当しない
定義: 上記区分の判定がいずれも false の場合に該当
優先度:
- 新規見積: 高 (即日確認)
- 既存案件追加質問: 中 (翌営業日確認)
- 営業メール: 低 (週次確認)
- その他: 中 (翌営業日確認)
例外区分:
- 名称: 判定保留
条件: AIの判断信頼度が閾値未満、または複数区分にまたがる場合
処理: 人間確認キューに回す
区分・優先度・例外区分の3点が書き出されていれば、n8nとAIエージェントのどちらが何を判定するかが明確になり、想定外の入力が来た場合も「判定保留」に逃がせます。例外区分がないと、AIが無理に分類を決めて誤った後段処理が走ります。
出力ルールを決めないと確認・転記・再利用ができない
出力ルールを決めないと、AIの出力を人間が再加工する作業に戻ってしまいます。出力は「次の処理が読める形」にそろえることで初めて、確認・転記・再利用が成立します。
出力先と形式が曖昧だと人間が再加工する作業に戻る
出力がバラバラの形で返ってくると、結局人間がコピペや整形をやり直すことになります。これでは自動化した意味が薄れます。
AIに分類結果を返させたとき、ある日は「区分: 新規見積、優先度: 高」という箇条書き、別の日は「これは新規見積依頼と思われます。優先度は高めです」という文章、また別の日はJSON風だけど構造が違う、という出力が返ってくることがあります。後段でこれをスプレッドシートに転記する処理を組んでも、形式が揺れている時点で転記処理がエラーで止まります。
結果として、AIの出力を人間が読み直して整形して転記する、という作業に戻ります。AIを通した分の手間が増えただけ、という状態になりかねません。
出力は「次の処理が読める形」にそろえる
出力は次に渡す相手 (人間 / 他ノード / 別ツール) が読める形にそろえます。読み手を意識した形式設計が、再利用性を生みます。
n8nの後段ノードに渡すならJSON、スプレッドシートに転記するなら列構造を持つCSVまたは表形式、人間が確認するならMarkdownや短文サマリ、というように、次の処理側に合わせて形式を決めます。AIに自由に書かせるのではなく、出力スキーマをプロンプトで指定し、外れた場合は再生成または人間確認に回すフローにしておきます。
「次の処理が読める形」を意識しておくと、出力ルールは自然と必要項目と禁止項目に分解できます。AI利用形態の前提知識はChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類あるで整理していますが、API利用ならスキーマ強制機能を活用し、サブスク利用ならプロンプトで形式を固定する、といった選択にもつながります。
出力ルールの最小構成 (出力先・形式・必須項目・人間確認位置)
出力ルールは「出力先」「形式」「必須項目」「人間確認位置」の4点で最小構成になります。人間確認位置を出力ルール側に明記しておくと、設計時に確認スキップを防げます。
問い合わせメール分類フローの出力ルールを書き出すと以下のようになります。
出力ルール:
出力先:
- 主出力: Googleスプレッドシート "問い合わせ管理" の新規行
- 副出力: Slackチャンネル "#inbox-classified" への通知
形式: JSON (n8n内部) → スプレッドシート列に展開
必須項目:
- 受信日時 (ISO8601)
- 区分 (新規見積 / 既存案件追加質問 / 営業メール / その他 / 判定保留)
- 優先度 (高 / 中 / 低)
- 件名 (原文)
- 判定信頼度 (0.0-1.0、AI判断時のみ)
- 元メールURL (Gmail内リンク)
人間確認位置:
- 判定保留: スプレッドシート上で "確認待ち" 列にチェックを付与し、Slack通知に @ メンション
- 新規見積 (優先度高): Slack通知のみ (確認は人間判断、処理は止めない)
- その他: 通知なし、週次でまとめて確認
必須項目を出力ルール側で固定しておくと、AIに渡すプロンプトもこの項目リストに沿って書けます。人間確認位置を「保留」「即時通知」「週次まとめ」と階層で分けておくと、確認負荷が現実的な範囲に収まります。確認を全部スキップする設計にすると一見楽ですが、想定外の出力が出たときに気付かずに後段に流れる事故が起きます。
個人で扱いやすい3段階構成 入力 → 分類 → 出力
入力・分類・出力のルールを別々に持つのではなく、3段階の流れとしてつないで設計すると、個人運用でも崩れにくくなります。本セクションでは3段階を1本の運用設計として整理します。
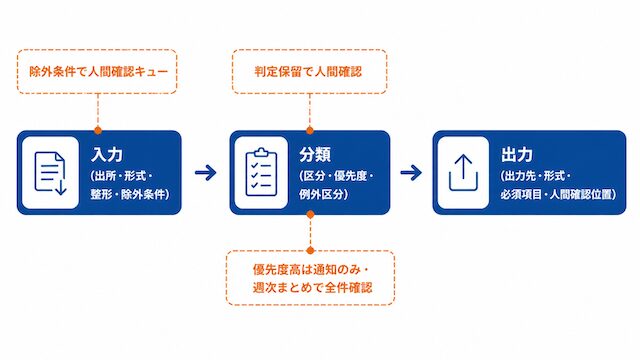
完全自動化を狙わず人間確認位置を残す
個人運用では最初から完全自動化を狙わず、人間が確認する位置を残しておく方が長く回ります。確認位置があるから、想定外の出力が出たときにも止められます。
完全自動化を初手で狙うと、例外データが出た瞬間に気付かない事故が起きます。判定保留を人間確認に回す、優先度高はSlack通知だけ送る、週次で全件をざっと見直す、といった確認位置を3段階それぞれに置いておくと、運用が壊れる前に止められます。これは作業者ポジションに戻らないための設計でもあり、AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由で触れた通り、確認・判断という上位の役割を自分側に残しておく構造そのものです。
確認位置は手戻りではなく、設計上の安全装置として置きます。
3段階のうち1段階だけでも運用ルールがあれば崩れない
入力・分類・出力の3段階すべてを最初から完璧にする必要はありません。1段階だけでも運用ルールが書き出されていれば、運用は崩れにくくなります。
たとえば入力ルールだけ先に固めて、分類と出力は最初の数週間は人間確認に回す、という運用も成立します。入力がそろっていれば、人間が判断する場合でも判断材料の品質が安定するので、後で分類ルールを書き出すときに過去ログから区分の傾向を抽出しやすくなります。
逆に3段階全部を最初から完璧に書き出そうとすると、設計だけで止まって運用が始まらない、という事態になります。1段階ずつ書き出して回しながら、不足を足していく順序が現実的です。
業務整理力こそが自立したエンジニアの価値になる
ツール操作を覚えるよりも、業務を入力・分類・出力に整理して型にする力の方が、自立したエンジニアの強みになります。受注の場でもこの整理力が直接価値になります。
n8nのノード操作やAIエージェントのプロンプト設計は、ドキュメントとサンプルがあれば習得できます。一方、依頼主の業務を聞き取って、何が入力で、どう分類すべきで、どんな出力が次の処理につながるのか、を切り出して言語化する作業は、ツールでは置き換えられません。
「何を自動化するか」ではなく「入力・分類・出力のルールをどう設計するか」を提示できる人が、AI自動化の受注で選ばれます。ツール選びは整理が終わった後の話で、整理ができていないままツールを売っても運用に乗りません。業務整理力を自分の主軸の価値として置き直すと、AI時代に作業者ポジションへ戻るループから抜ける道筋が見えます。
まとめ
AI自動化を個人で運用するための核は、ツール導入ではなく入力・分類・出力の運用ルール設計です。最小構成の型を作って3段階で回すこと、人間確認位置を残すこと、業務整理力を自分の価値として置き直すこと。この3点を押さえれば、自動化を組んだ後に作業者へ戻るループから抜けられます。
入力ルールは「出所・形式・整形手順・除外条件」の4点、分類ルールは「区分・優先度・例外区分」の3点、出力ルールは「出力先・形式・必須項目・人間確認位置」の4点。それぞれ最小構成で書き出し、3段階を1本の流れとしてつなぎ、確認位置を設計上の安全装置として残す。この型を回しながら、不足箇所を1段階ずつ足していくのが個人運用の現実的な順序です。
関連記事
入力・分類・出力ルール設計と関連の深い、Beエンジニアの公開記事を以下に紹介します。n8n運用コストの実態と、AI活用差のリアルを補強する文脈証跡として参照してください。
- n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算 — 個人運用で軽さを優先する根拠としてのコスト構造
- AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 — 業務整理力を自分の価値に置き直す文脈
- AI自動化で作業者に戻らないためのn8nとAIエージェントの使い分け — 本記事の前段にあたるシリーズ記事
関連解説
AI利用形態の前提知識として、本記事の出力ルール設計と関わる解説記事を案内します。
- ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある — 出力スキーマ強制やコスト前提の選択につながる前提知識




