

同じ資料を何年も溜めてきたのに、今になってAIに渡そうとすると、何から渡せばよいか分からなくなっていませんか。ファイルとしては手元にあるのに、いざAIに読ませようとすると「これは渡していいのか」「どの順で渡せばいいのか」で手が止まる場面は多いです。本記事では、25年分の過去資料をAIで整理して見えた「資料の正体」を、個人の実体験として共有します。
私自身、設計書・Excel・議事録・手順書を25年分ためてきました。当時は「残しておけばいつか役に立つ」と思って保存してきたつもりでした。ところがAIに渡してみると、肝心の判断理由が出てこず、AIの回答も一般論で止まる場面が続きました。LLM-Wikiという言葉だけ見ても、何をするものか分かりにくいですよね。ここではまず「AIが読める仕事用の整理棚」と考えてください。詳しい仕組みは記事の中盤で扱います。
AIをどう使うか自体に迷っている場合は、前提としてChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類あるも先に読むと、本記事で扱う「過去資料をAIに渡す」という話の位置づけが見えやすくなります。本記事自体は、AIの種類ではなく「AIに何を渡すか」のほうに踏み込みます。
この記事を読み終えたとき、「保存していること」と「次の仕事で使えること」は別の話だ、と判断できる入口に立てるはずです。読み終えたあとに具体的な仕組みへ進みたくなったときの導線は、記事末尾に用意します。
25年分の資料を資産だと思っていた状態
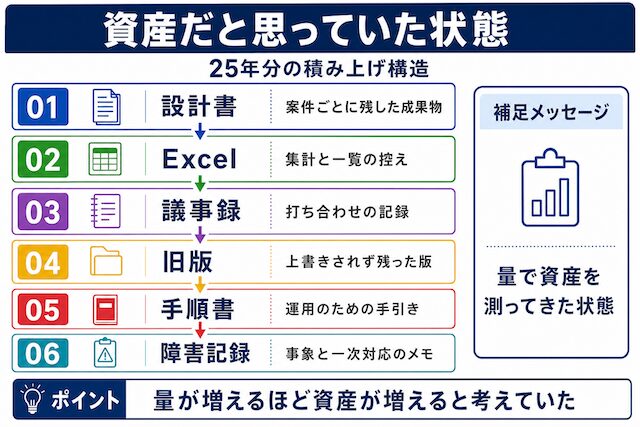
同じ資料を何年も溜めてきたのに、AIに渡そうとした途端、何から手を付ければよいか分からなくなることがあります。ファイルを残すこと自体が資産だと思って25年積み上げてきた結果、自分でも全体像を掴めない量になっていました。まずは、当時どんな気持ちで保存していたのかを振り返り、AIを入れたことで何が見えてきたのかを整理します。
設計書やExcelを残してきた理由
当時の設計書やExcelは、あとで誰かが見るかもしれない、自分も振り返るかもしれない、という前提で残していました。設定値、作業手順、確認結果、判断の跡を1ファイルずつ分けておけば、あとから状況を追えると思っていたからです。
実際の現場では、設計書もExcelも「念のため」「あとから揉めたときの根拠」「次に同じ案件が来たときの参考」として作られていた、という感覚に近いはずです。一つひとつのファイルには、その時点での妥当な目的がありました。問題はファイル自体ではなく、当時の目的が後から思い出せなくなることのほうにあります。
いつか使えると思って保存してきた資料
「いつか使えるかも」で残した資料は、保存しただけでは未来の自分を助けてくれません。必要なときに探せる場所、読める名前、使える単位になっていないと、資料はあるのに見つけられない状態になります。残しておけば資産になると思っていたファイルが、なぜ後から扱いづらくなるのかを整理します。
ファイル名・フォルダ階層・命名規則は当時の自分にとって自然でも、5年・10年・20年と経つと意味を思い出せなくなります。検索しても引っかからない、開いてみても判断理由が書かれていない、という場面が積み重なると、「保存していること」と「使えること」が同じではなかったと気付きます。
700GBまで膨らんだ過去の成果物
気付いたらストレージを大きく使い切っていました。私の場合は700GBという数字になりましたが、本題は容量の大きさではありません。設計書、Excel、作業メモ、バックアップ、過去版の資料を残し続けた結果、なぜそこまで増えたのか。その構造を見直すことが重要です。
増え方の中身を見ると、同じ資料の旧版・体裁違い・送付用コピー・添付付きメールの控え・スクリーンショットの束など、判断理由とは結びついていない記録が大半を占めていました。容量を減らすこと自体が目的ではなく、「何が積み上がっていたか」を言葉にできることのほうが、次のステップにつながります。
AIで整理して見えた過去資料の正体
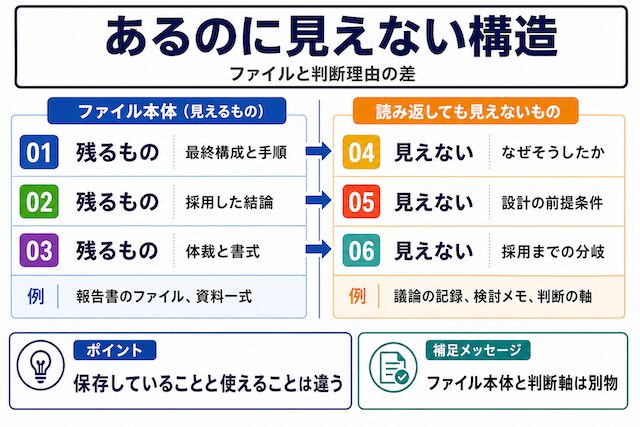
「過去資料をAIに渡せば、勝手に賢く使ってくれるはず」と期待して試したのに、思ったほど噛み合わなかった経験はないでしょうか。ファイルを並べてAIに読ませても、肝心の「なぜそうしたか」が出てこない、という違和感を持つ人が多いです。ここでは、AIを通したからこそ見えた「資料が記録だった」という気づきを言葉にしていきます。
判断理由が見えないファイル
設計書は残っているのに、なぜその構成にしたのかが見えないことがあります。採用した設定値、構成図、手順だけが残り、当時どんな案を比べたのか、何を避けたのか、どの制約を優先したのかが抜け落ちている状態です。結論だけが残り、検討プロセスが消えているファイルは、あとから見返しても判断材料として使いにくくなります。
成果物としてのファイルには、最終的な構成・パラメータ・手順が並びます。一方で「他の案を出した上で、なぜこれを選んだのか」「どの制約があってこの形に落ち着いたのか」は、口頭の打ち合わせやメールのやりとりに散らばっていて、ファイル本体には残らない場合が多いです。AIに渡すと、結論部分は再生成できても、判断理由のところで「一般論」が返ってくる構造になります。
設計思想が残っていない設計書
成果物としての設計書が残っていても、当時の前提が抜け落ちていると再利用できません。何を優先し、何を捨て、どの制約を前提にしたのかが見えない設計は、別案件に持ち込もうとした瞬間に判断が止まります。
設計思想とは、難しく言い換える必要はなく「何を一番大事にした設計か」「何を諦めた設計か」のことです。これが残っていないと、別案件で似た構成を組もうとしても、当時の判断軸を再現できません。AIに過去資料を渡しても、AIは「結論をなぞる」ことはできても、設計思想がない以上は「あなたの過去の判断軸」を再現できない、というのが見えてきた正体です。
記録と資産の違い
保存しているだけの資料は、まだ記録です。次の仕事で使える資産にするには、何を判断し、なぜその形にしたのかまで取り出せる必要があります。ファイルとして存在することと、別の案件で判断材料として使えることは別です。
ここで言う「記録」は、過去にこういうものを作った、という事実が残っているファイルです。「資産」は、別の案件・別のお客様・別の前提でも、判断の足がかりとして再利用できる材料です。同じファイルでも、判断理由が抽出されているかどうかで、記録のままか、資産になるかが分かれます。ここからは「資産にするために何を抽出すべきか」のほうへ進みます。
本当にAIへ渡すべきだったもの
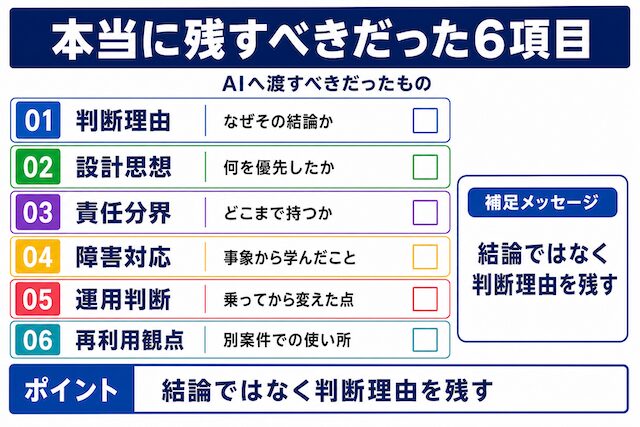
ファイルを渡したつもりが、自分が本当に渡したかったものはファイルではなかった、と気付いたことはありませんか。設計書・議事録・手順書の中に埋もれている「判断の足跡」こそが、AIにも次の自分にも役に立つ材料です。ここでは、当時の判断のうち何を抽出するべきだったかを3つの角度から見ていきます。
その設計にした理由
なぜその設計にしたかを言葉にできないと、別案件では使い回せません。残すべきなのは結論だけではなく、何を優先し、何を避け、どの制約の中で判断したかという根拠です。判断の根拠まで残っていれば、環境が変わっても応用できます。
「この処理はバッチで持った」「この権限はサーバー側に寄せた」といった結論だけを残すと、別案件の要件が少し変わっただけで応用が効きません。一方で「なぜバッチにしたか (例: リアルタイム性が不要で、夜間のリソースが空いていたため)」を一言添えておくと、別案件で前提が変わったときに、判断軸ごと持ち込めるようになります。
その判断をした理由
当時の判断理由は、作業が終わると記録から抜け落ちやすくなります。なぜその判断をしたのか、何を優先したのか、何を避けたのかが残っていないと、あとから見返しても当時の思考に戻れません。判断理由をAIに渡せる形に変えておけば、過去の自分が何を見て判断したのかを呼び戻せます。
設計書には「何を採用したか」が並び、議事録には「誰が何を言ったか」が並びますが、その間にある「なぜその判断に落ち着いたか」は、書き留めない限り消えていきます。当時の優先順位 (コスト優先 / 納期優先 / 拡張性優先 / 顧客側の制約優先 など) を一言添えるだけで、AIに渡したときの応答も「自分の業務の延長」に寄ってきます。
迷った地点と捨てたもの
採用しなかった案ほど、あとから価値が出ます。採用案だけが残っていると、なぜ他の案を捨てたのか、どこで迷ったのか、何を優先したのかが分かりません。不採用の理由や分岐点まで残っていれば、別案件で同じ迷いに入る前に判断できます。
「A案ではなくB案にした」だけでは、別案件で同じ分岐に来たときに、また一から比較し直すことになります。「A案を捨てた理由 (例: 当時のメンバー構成では運用負荷が高すぎる)」を残しておくと、別案件で前提が変わったときに「今ならA案でもよいかもしれない」という判断を、過去の自分の足跡を踏まえて行えるようになります。
700GBが3GB弱になった意味
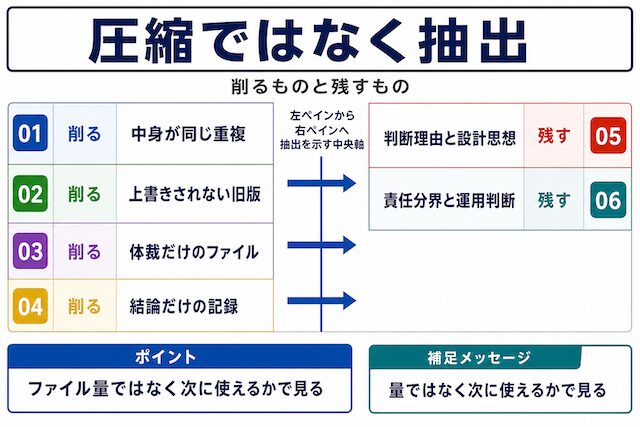
大量に保存してきた資料が小さくなったと聞くと、圧縮しただけに見えるかもしれません。実際には、同じ情報を小さく畳んだのではなく、次の仕事で使える部分だけを残した結果です。削られたのは古い作業痕跡や重複で、残ったのは判断理由、設計前提、再利用できる考え方です。
ノイズが消えた構造
資料の中に、思った以上に「同じ内容のコピー」や「途中バージョン」が眠っている経験はありませんか。重複・旧版・体裁ファイル・判断理由のない記録・固有情報の5種類が削られた、という構造を確認します。
削られた中身を分けると、下記の5種類にだいたい収まります。
- 中身が同じ重複ファイル、
- 上書きされなかった旧版、
- フォーマット調整だけの体裁ファイル、
- 結論しか残っていない判断理由のない記録、
- 顧客名・案件名・システム名・IPアドレスなどの固有情報、
これらは「過去の作業の痕跡」としては事実ですが、別の案件で再利用できる材料ではありません。
残ったのは再利用できる判断材料
残った3GB弱は、単に容量が小さくなった資料ではありません。判断理由、設計思想、責任分界、障害対応、運用判断、再利用観点の6種類が残ります。元ファイルの量ではなく、別案件にも持ち込める判断材料だけが残った状態です。
残った中身の主役は、ファイルそのものではなく「判断の足跡」です。なぜその設計にしたか、何を優先して何を諦めたか、責任の引き方をどう決めたか、障害が起きたときにどう対応して何を学んだか、運用に乗ってから何を変えたか、別の案件で再利用するときの観点は何か、という形で残しました。これは個人の実体験の数字なので、誰でも同じ比率になるという話ではありません。
資産だと思っていた多くは記録

私は業務資産に限らず、GitHubとは別に、業務用WIKI、ビジネス用WIKI、ブログ用WIKI、etc・・・としてデータを分けて管理しています。作成したWIKIはObsidianから確認できるようにしており、必要な情報がどこにあるのか、どの知識とつながっているのかをグラフビューで見られる状態にしています。
この画面を見ると、単なるファイル置き場とはまったく違う見え方になります。まるで脳のシナプスのように、過去の資料、判断、手順、設計メモがAIによって結び直されていく感覚があります。
ファイル量で資産を測ってきた人にとって、これは少し受け入れにくい結論かもしれません。「量が多い = 資産が多い」ではなく、「次に使えるか」で見ると、資産だと思っていたものの多くは記録だったと整理し直す必要があります。
ここでの結論は「資料を消すべき」ではありません。保存していたことと、次の仕事で使えることは別軸だった、という見方の更新です。記録は記録として残してよいです。コンプライアンス、監査、契約上の保存義務がある資料も、そのまま保存します。
重要なのは、保存する資料と、次の判断に使う知識を分けることです。これはもう人間にはとてもできない芸当ですね。
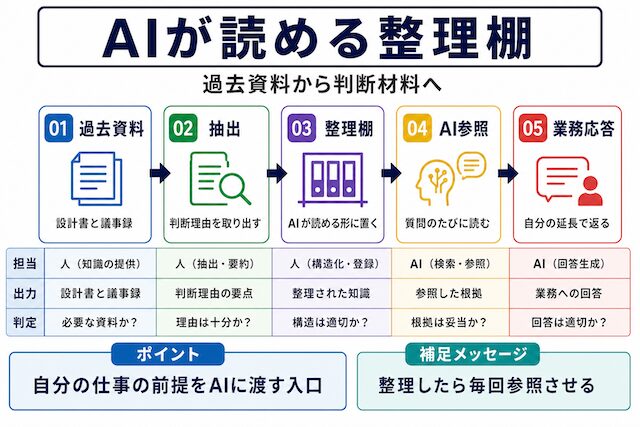
LLM-Wikiで過去資料がAIの判断材料に変わる仕組み
「LLM-Wiki」という言葉だけ見ても、どこから入ればよいか分かりにくいですよね。ここではまず「AIが読める仕事用の整理棚」と考えてください。過去の判断理由や設計思想を、ファイルとして置くのではなく「AIが参照できるメモ群」として整理する仕組みで、本章ではその流れを順に見ます。
LLM-Wikiの考え方については、先に下記の記事で整理しています。

保存するだけでは使えない理由
ファイルを並べただけでAIが賢く使ってくれない、と感じたのはなぜでしょう。保存と整理は別作業で、AIに渡す前に「判断理由を抽出する一手間」が必要な理由をここで確認します。
ファイルを並べた状態は「文章の山」です。AI側からは、どれが判断理由でどれが体裁の枝葉か、どれが今の案件と関係する話でどれが過去の固有情報か、を区別できません。並べて読ませると、結局AIは多数派の表現に引っ張られて一般論を返します。判断理由を「読める形に切り出す一手間」を入れて初めて、AIの応答が「自分の業務の延長」に寄り始めます。
判断理由をAIが読める形に変える流れ
判断理由を残すといっても、最初からきれいに整理する必要はありません。まず資料の種類と目的を分け、何を判断した資料なのかを取り出します。そのうえで、別案件でも使える観点を付け、固有情報を外し、結論よりも判断理由が残る形に整えます。
順番に置き直すと、(1) この資料はどんな種類で、何のために残すのかを先に決める、(2) その中で「判断事項」だけを取り出す、(3) 他の案件で使えるとしたら何の観点で使えるかを一言添える、(4) 顧客名・案件名・システム名・IPアドレスなどの固有情報を外す、(5) 結論よりも「なぜその結論にしたか」を主役に書く、の5つです。すべての資料に同じ密度を求める必要はなく、まず1本やってみるところから始められます。
一般論から仕事用への変化
AIに質問しても一般論ばかり返ってくるのは、AIが自分の判断理由を参照できていないからです。過去の設計判断、責任分界、障害対応、運用判断をAIが読める形にしておけば、回答は一般論ではなく、自分の業務資産に基づくものへ変わります。
同じ「権限の設計をどうしますか」という質問でも、参照先がない状態だと、AIは教科書的な原則を返します。一方、自分の過去案件の「この案件ではこういう理由でこの権限の引き方にした」という判断理由メモが参照されると、回答は「過去のあなたの判断軸を踏まえると、今回は次の点を確認するとよいです」という形に変わります。差が出るのは、AIの賢さよりも「AIが参照できる材料を整えたかどうか」のほうです。
自分の業務資産に寄った回答
過去の自分の判断を踏まえた回答が返ってくると、AIはただの相談相手ではなくなります。整理した判断理由、設計思想、責任分界、障害対応を毎回参照できる状態にしておけば、AIの回答は一般論ではなく、自分の仕事の延長に近づきます。
ここで大事なのは「整理したら終わり」ではなく、「毎回参照させる」ほうです。整理した判断材料を、新しい案件の検討時にAIに必ず読ませる運用にしておくと、回答の手触りが少しずつ「自分の業務の延長」に寄ってきます。AIが急に賢くなったように見える場面の多くは、参照先が変わっただけだったりします。
AIとの会話の変化

llm-wikiに過去資料を整理してから、AIとの会話で変わったのは「昔の資料を要約してくれるようになった」ことではありません。資料の中から、今でも使える判断理由と、当時のまずかった判断の両方を取り出せるようになったことです。
たとえば、古いLAN更改案件の資料をそのままAIに読ませると、「ネットワーク設計では可用性やセキュリティを考慮します」のような一般論に寄ります。けれど、llm-wiki側で、端末管理、監視、バックアップ、アクセス制御、障害時対応、責任分界の観点に分けておくと、AIへの聞き方が変わります。
「この案件で再利用できる判断軸は何か」と聞けるようになります。
すると、AIは単なる要約ではなく、「監査証跡をどこに退避するか」「運用端末を用途別に分ける理由は何か」「障害時に誰がどこまで確認するのか」「作業手順として残すべき部分はどこか」のように、今の仕事へ移せる形で返してきます。
一方で、都合のよいことだけを返してくれるわけではありません。
過去資料を読ませると、AIは自分が過去にやったまずい判断も平然と掘り起こしてきます。たとえば、手順としては残っているのに、なぜその順番で作業したのかが書かれていない。障害対応の記録はあるのに、最初にどこを疑ったのかが残っていない。責任分界らしき記述はあるのに、誰が最終判断を持つのかが曖昧なままになっている。
人間なら見なかったことにしたくなる部分でも、AIは遠慮しません。
「この資料は作業結果は残っていますが、判断理由が不足しています」
「この手順は再利用できますが、失敗時の戻し方が書かれていません」
「この記録は障害対応の事実は分かりますが、再発防止の観点が弱いです」
その他、ここでは書けないようなとても思い出したくない苦い経験も平然とまるで一緒にその場に居たかのように言葉にしてきます。
こう返ってくると、古い資料は単なる資産ではなくなります。過去の仕事の中にある強みと、当時の記録不足や設計の甘さが同時に見えてきます。
別の例では、古いファイル転送まわりの資料を整理したあと、AIに「これは今の仕事に使えるか」と聞きました。整理前なら、AIはファイル転送の仕組みを説明して終わります。整理後は違います。AIは、転送元、転送先、確認方法、失敗時の切り戻し、ログの残し方、誰が責任を持つ処理なのか、という単位に分けて返せるようになりました。
ここで初めて、古い資料が「昔の設定値」ではなく、「今でも使える責任分界の材料」に見えてきます。
障害対応の資料でも同じことが起きました。障害報告や対応メモをそのまま読むと、AIは発生事象と対応内容をまとめるだけです。けれど、llm-wikiで「発生条件」「確認した順番」「切り分けた境界」「戻した手順」「再発防止として残す観点」に分けておくと、AIは次の案件で使えるチェックリストとして返せるようになります。
同時に、当時の記録の弱さも見えてきます。
なぜその確認順にしたのか。なぜその対応で止めたのか。なぜ恒久対応ではなく暫定対応にしたのか。そこが書かれていない資料は、AIに読ませても「判断の再利用」までは届きません。AIは、残っていることは拾いますが、残っていない理由までは勝手に補ってくれません。
この変化は大きいです。
25年前の資料を見ながらAIと話したとき、自分でも忘れていた判断理由が、今の言葉で返ってきました。当時なぜその構成にしたのか、なぜその手順を残したのか、なぜそこで責任の境界を引いたのか。反対に、なぜこの肝心な理由を残していなかったのか、という痛い部分も返ってきます。
AIが過去を知っていたわけではありません。llm-wikiに整理したことで、AIが読める材料ができただけです。
それでも、会話の感覚は明らかに変わりました。
AIに質問しているというより、25年前の自分が資料に残した判断と、残し損ねた失敗を、今のAIが淡々と照らし返してくる感覚です。古い資料の中にいた当時の自分と、今の自分がAIを挟んで会話しているように感じました。
保存していただけの資料は、AIにとっては文章の山です。llm-wikiで判断理由、設計意図、運用判断、障害対応、再利用できる観点に分けると、AIはその山から仕事に使える材料を取り出せるようになります。同時に、過去の記録不足や判断の甘さも隠れなくなります。
ここが、ただの保管とLLM-Wikiの違いです。
ちょっと余談
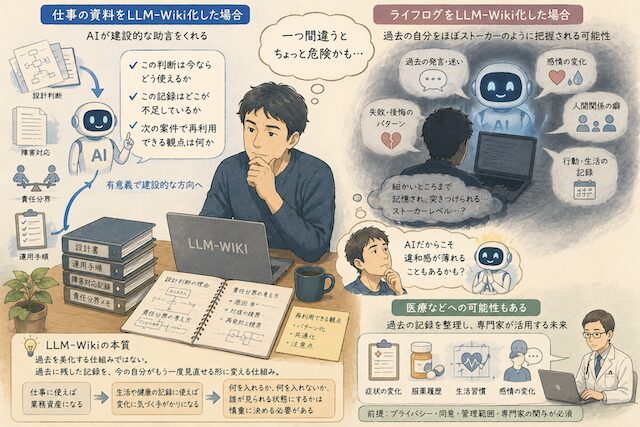
少し余談になりますが、LLM-Wikiは使い方を間違えると、かなり危うい仕組みにも見えます。
私の場合は、仕事の資料、設計判断、障害対応、運用手順、責任分界のような業務資産を中心に整理しています。そのため、AIが返してくる内容も「この判断は今ならどう使えるか」「この記録はどこが不足しているか」「次の案件で再利用できる観点は何か」といった、建設的な方向に寄ります。
けれど、これが仕事の資料ではなく、過去の日記、行動記録、人間関係、感情のログ、生活の記録だったらどうなるのか、と考えることがあります。
もし個人のライフログを細かくLLM-Wiki化したら、AIは過去の発言、迷い、後悔、失敗、人間関係の癖まで拾って返してくるはずです。使う本人にとっては便利かもしれませんが、一歩間違えると、ほぼストーカーレベルで自分の過去を突きつけてくる存在にもなり得ます。
過去の自分が何に悩み、どこで判断を間違え、誰との関係で同じ失敗を繰り返していたのか。そうしたものをAIが淡々と整理して返してくるとしたら、それは仕事のナレッジ化とは別の重さを持ちます。
私はその使い方を経験していないので、実際にどう感じるかはわかりません。
ただ、相手が人間ではなくAIだからこそ、逆に違和感が薄れる場面もあるのかもしれません。人間に過去を細かく知られると抵抗がありますが、AIなら「責められている」という感覚が薄く、事実として受け取れる可能性があります。
そう考えると、LLM-Wikiの考え方は仕事の資料整理だけに閉じないはずです。
たとえば医療やメンタルケアの分野では、過去の記録、症状の変化、生活習慣、服薬履歴、本人の感情の変化を、医師や専門家が確認できる形に整理する用途が考えられます。もちろん、扱う情報が重すぎるため、個人が不用意に使うものではありません。プライバシー、同意、管理範囲、専門家の関与が前提になります。
それでも、過去の記録をAIが読める形に整理するという発想には、仕事以外の可能性もあります。
LLM-Wikiは、過去を美化する仕組みではありません。過去に残した記録を、今の自分がもう一度見直せる形に変える仕組みです。仕事に使えば業務資産になります。生活や健康の記録に使えば、自分でも見落としていた変化に気づく手がかりになる可能性があります。
だからこそ、何を入れるか、何を入れないか、誰が見られる状態にするかは慎重に決める必要があります。
人間が確認するべきこと
AIが整理した結果は、そのまま現場に持ち込むものではありません。現場条件との整合、固有情報の混入、責任分界のずれ、古い判断の流用を人間が確認してから使う必要があります。副産物としてできたたたき台も、完成物ではなく確認前の仮組みとして扱います。
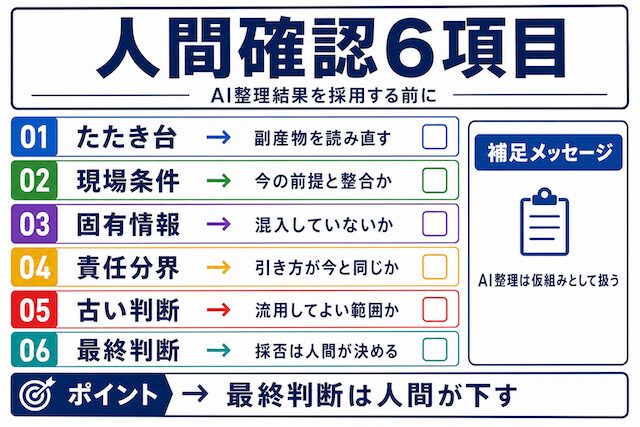
副産物のたたき台も人間が直す前提
AIが作った設計書や手順書のたたき台は、そのまま現場に出すものではありません。設計書、手順書、チェックリスト、確認観点は作業を進めるための副産物です。現場条件、責任分界、運用ルール、固有情報の有無を人間が確認し、必要な修正を入れてから使う前提です。
判断理由を整理しておくと、AIは「過去のあなたならこう書きそうな設計書のたたき台」「過去の判断軸に沿った手順書のたたき台」を返してくれるようになります。これは便利な副産物ですが、あくまで「たたき台」です。今の現場・今のお客様・今のメンバー構成に合っているかは、最終的に人間が読み直して直す前提を崩さないほうが安全です。
現場条件との整合
過去の判断は、そのまま今の現場に当てはめられるとは限りません。コンプラ、顧客方針、技術スタック、運用体制が変われば、当時は正しかった判断でもズレることがあります。過去資料を使うときは、今の現場条件と合っているかを毎回確認する必要があります。
過去にうまくいった判断でも、今の前提では当てはまらないことがあります。コンプライアンス要件が変わっている、顧客側の方針が変わっている、使えるサービスや製品の選択肢が変わっている、社内の責任分界が変わっている、といった条件のずれは、AIの整理結果からは読み取れません。人間側で「今の現場条件と整合するか」をひとつずつ突き合わせる作業が必要です。
責任分界のずれ
過去の責任分界が、今の案件でも同じ位置にあるとは限りません。責任範囲の引き方が変わっている可能性を、AI整理結果を採用する前に人間が判定する観点を扱います。
「この処理はベンダー側で持つ」「ここは顧客側の責任で運用する」といった責任分界の引き方は、案件ごとに細かく違います。過去案件の判断理由がそのままの形でAIから返ってきた場合、今の案件で誰がどこまでを持つかを、契約書・体制図・打ち合わせ議事の最新版で再確認する必要があります。便利だからとそのまま採用すると、後から責任の所在で揉める引き金になります。
古い判断の流用リスク
過去の判断をそのまま流用したくなる場面はあります。けれど、確認工程を省略すると、当時は正しかった判断が今の案件では事故の原因になります。便利に使えるからこそ、現場条件、顧客方針、技術スタック、責任分界が今も合っているかを確認する必要があります。
AIから「過去のあなたの判断軸を踏まえると、今回もこうするのが自然です」という回答が返ってくると、つい採用したくなります。とはいえ、その判断軸が作られたときの前提 (例: 5年前の制度・10年前の技術スタック) が、今の案件に合っているとは限りません。最終的な採否は、AI整理結果ではなく現場条件と人間の判断のほうに置いておくのが安全です。
まとめ
ここまで読んで、過去資料の見え方が少し変わってきたでしょうか。「資産だと思っていたものの多くが記録だった」という気づきを、最後にもう一度言葉に戻して、次に進む読者の入口を整理します。
資産にならない過去資料
保存しているだけでは、過去資料は資産になりません。「判断理由を抽出する一手間」が、資料を資産に変える分かれ目だったと振り返ります。
ファイル数や保存容量で資産を測ると、量が増えるほど整理が追いつかなくなります。逆に「次に使えるかどうか」で見ると、整理対象は判断理由のあるところに絞られます。記録と資産を分けて扱う、というだけの見方の更新で、過去資料の使い道が変わります。
LLM-Wikiで変わる判断材料
同じ過去資料でも、AIが参照できる形に置き直すと役割が変わります。LLM-Wikiに整理することでAIの回答が自分の業務資産に寄っていく、という変化を改めて確認します。
判断理由を「AIが読める仕事用の整理棚」に置いておくと、AIの応答が「自分の業務の延長」に寄ってきます。整理した材料を毎回参照させる運用前提を維持することで、AIが急に賢くなったように見える場面が増えていきます。差はAIの能力ではなく、参照先の整え方のほうにあります。
次に進むテーマ
ここまで来ると、次はAIに過去の判断を忘れさせない仕組みが必要になります。今回見えてきたのは、過去資料そのものではなく、判断理由を継続して参照できる状態にする重要性です。次の記事では、AIに自分の業務資産を覚えさせ続けるための仕組みへ進みます。
過去資料の「正体」を一度見直したら、次は「忘れさせない仕組み」のほうへ進む順番が自然です。記事末尾の導線から、続きとなる記事に進んでください。
次に読む記事
過去資料の判断理由を抽出する段階を超えて、それをAIに参照させ続ける具体的な仕組みに進みたい方へ。本記事で得た「記録と資産を分ける」入口の次のステップとして、整理した材料を継続的に参照させる考え方を扱います。




