

ニュース収集、要約、SNS投稿の下書きづくりを自動化したあと、その処理が夜中に失敗していたら気づけるでしょうか。AI自動化は、作った瞬間よりも、動き始めたあとに本当の問題が出ます。
この記事では、AI自動化を壊さず回すために必要な役割を「記録・監視・失敗の振り分け・再実行・通知・巻き戻し・常駐管理」の7つに分けて整理します。対象は、n8n や AI を使った自動化を作り始めたものの、失敗時にどこを見て、何を止め、どう戻せばよいか判断できずに止まっている方です。
AI自動化で重要なのは動かすことより壊れたときの設計
AI自動化を作ってみたあと、それが失敗したとき自分は気づけるか、考えたことはありますか。この記事は新しいツールの紹介ではなく、n8nやAI自動化のフローを動かしたあとに必要になる運用の話です。いつもは動いている前提で使うフローを、壊れる前提で見直すと、何を準備すべきかが見えてきます。
動いたフローだけでは運用にならない理由
フローが一度動くと、つい「完成した」と感じてしまいますよね。でも自動化は、動いたあとに失敗をどう扱うかまで決めて、はじめて運用に乗ります。
最初に作るとき、人は「うまくいく道筋」を組み立てます。データを取ってきて、AIで処理して、どこかへ書き込む。この一本道がつながった瞬間、達成感があります。ただ、自動化は人間が見ていない時間も動き続けます。見ていない時間に何かがずれたとき、それを拾う仕組みがなければ、フローは「動いている」のか「黙って壊れている」のか区別がつきません。
入力・分類・出力のルールを先に決めておく設計フェーズについては、前段の記事個人でAI自動化を運用するための入力・分類・出力ルールで整理しています。本記事はその次の段、つまり「ルールを決めて動かしたあと、壊れたときにどうするか」を扱います。作る段と運用する段は地続きですが、必要になる準備は別物です。
失敗に気づけない自動化が一番危ない理由
自動化のこわさは、派手に止まることより「失敗したのに誰も気づかない」ことにあります。気づけないと、壊れたデータのまま後ろの処理が進み続けます。
たとえば、ニュースを集めるフローが0件しか取れなかったとします。エラーは出ていません。でも実際は取得元の仕様が変わって、何も拾えていない。次の要約処理は「空のデータ」をそのまま処理し、投稿フローは中身の薄い下書きを作ります。どこも止まっていないので、画面上は順調に見えます。これが「握りつぶし」と呼ばれる状態です。失敗が表面に出ず、後続が壊れたまま走り続けます。
派手に止まる失敗は、むしろ親切です。止まれば気づけるからです。本当に怖いのは、止まらずに静かに間違い続ける失敗です。運用設計の出発点は、この「気づけない失敗」を見える状態にすることだと考えてよいと思います。
運用設計で最初に分ける7つの役割
「運用設計」と言われても、何から手をつけるか迷いますよね。
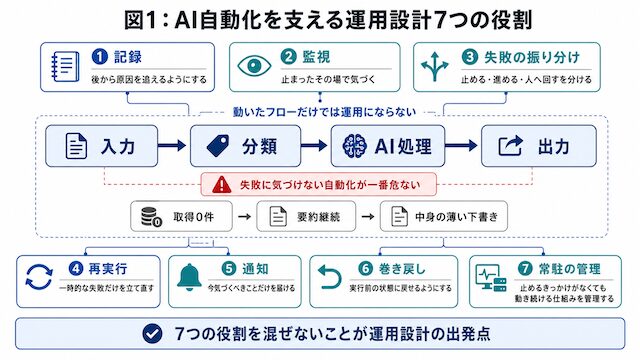
ここでは下記の7つの役割に分け、混ぜずに考える形で全体像を示します。
- 記録:「後から原因を追えるようにする」役割
- 監視:「止まったその場で気づく」役割
- 失敗の振り分け:「止めるか・進めるか・人へ回すかを決める」役割
- 再実行:「一時的な失敗だけを自動で立て直す」役割
- 通知:「人が今気づくべきことだけを届ける」役割
- 巻き戻し:「実行前の状態に戻せるようにする」役割
- 常駐の管理:「止めるきっかけがなくても動き続ける常駐型の仕組みを管理する」役割
ここで大事なのは、これらを混ぜないことです。記録と通知を混ぜると「全部通知」になり、再実行と巻き戻しを混ぜると「やり直したつもりが二重実行」になります。図1のように、7つを別々の引き出しとして持っておくと、自分のフローのどこが手薄かを点検しやすくなります。以降のH2で、この7つを順番に見ていきます。
失敗に気づけないAI自動化を見えるようにする記録と監視
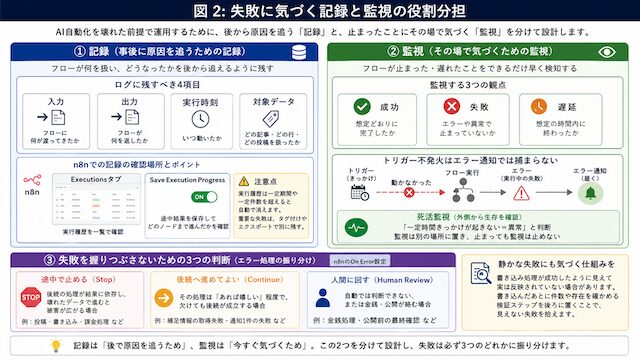
AI自動化が止まったとき、あなたは何分で気づけるでしょうか。壊れたことに気づくには、後から原因を追うための記録と、止まったことにその場で気づくための監視という2つの仕組みが要ります。ここでは、この2つを混ぜずに用意する考え方を整理します。
ログに残すべき4項目(入力・出力・実行時刻・対象データ)
ログは、失敗したあとに「何が起きたか」を追うための記録です。
最低限、次の4つを残します。
- 入力:フローに何が渡されたかを残します。何を処理しようとしたのかを確認できます。
- 出力:フローが何を返したかを残します。期待した結果になっているかを確認できます。
- 実行時刻:いつ動いたかを残します。遅延、未実行、重複実行を追いやすくなります。
- 対象データ:どの記事、どの行、どの投稿を扱ったかを残します。あとから対象を特定できます。
この4つがあると、失敗したときに「いつ・何を入れて・何が返って・どれを触ったか」が分かります。逆に、これがないと「失敗したらしい」までしか分かりません。原因を追うたびに、毎回ゼロから調査することになります。
n8n では、実行履歴を Executions タブで確認できます。ノードごとの途中結果を残したい場合は、ワークフロー設定の Save Execution Progress を確認します。
重要な失敗ログは、実行履歴が消える前に別で残す前提にします。実行履歴は、期間や件数の上限を超えると消える場合があるためです。
成功・失敗・遅延を見分ける監視の観点
監視と聞くと大げさな仕組みを想像しますよね。実際に見るのは、フローが成功したか・失敗したか・遅れていないか、という3点だけで十分です。
成功と失敗は分かりやすい観点ですが、見落としやすいのが「遅延」です。いつもは1分で終わるフローが30分かかっているとき、結果としては成功でも、何かがおかしくなりかけています。成功か失敗かだけでなく「想定の時間内に終わったか」も監視の対象に入れておくと、壊れる前の予兆を拾えます。
記録と監視は似ていますが、役割が違います。記録は事後に原因を追うため、監視は進行中や直後にその場で気づくためのものです。図2のように、この2つは別の引き出しとして持っておきます。記録だけあって監視がないと「壊れたあとに調べられるが、壊れたこと自体に気づけない」という状態になります。
エラー通知で捕まらないトリガー不発火
エラー処理を入れても、すべての失敗を拾えるわけではありません。特に見落としやすいのが、トリガー不発火です。トリガーとは、フローを動かし始めるきっかけです。
たとえば、次のようなものです。
- 決まった時刻に動くスケジュール
- 外部からの合図で動く Webhook
- 別サービスから届く通知
n8n のエラー処理は、実行されたフローの失敗を捕まえる仕組みです。つまり、フローがそもそも実行されなかった場合は、エラー通知まで届きません。
たとえば、毎朝9時に動くはずのフローが動かなかったとします。この場合、フロー内のエラー処理は動きません。フロー自体が始まっていないからです。この穴を埋めるには、フローの外側から「予定どおり動いたか」を見る必要があります。
この考え方が死活監視です。
死活監視では、次のように確認します。
- 毎朝9時に動くはずのフローがある
- 9時5分になっても実行記録がない
- フローが動いていないと判断する
- フローの外側から通知する
死活監視は、監視されるフローとは別の場所に置きます。同じ仕組みの中に置くと、その仕組みごと止まったとき、監視も一緒に止まるからです。
失敗を握りつぶさないための3つの判断
自動化では、失敗したあとに必ず判断が必要です。
判断は、次の3つに分けます。
- 止める:
後続へ進むと被害が広がる場合です。壊れたデータを投稿する、間違った内容を書き込む、公開処理へ進む、といった場面では止めます。 - 後続へ進める:
欠けても処理全体が成立する場合です。補足情報の取得失敗や、軽い通知の失敗などは、後続へ進めてもよい場合があります。 - 人間に回す:
自動で判断できない場合です。金銭、公開、削除、送信、外部への影響がある処理は、人間確認へ回します。
n8n では、ノード設定の On Error で失敗時の動きを選べます。ここで「とりあえず次へ進む」にすると、失敗が握りつぶされます。
握りつぶされた失敗は、画面上では成功に見える場合があります。壊れたデータで後続処理が進み、あとから原因を追うのが難しくなります。特に書き込み処理では、成功したように見えて、実は反映されていない失敗もあります。
そのため、書き込み後には次の確認を入れます。
- 件数が増えているか
- 対象データが存在するか
- 更新日時が変わっているか
- 想定した値が入っているか
失敗を見えるようにするには、エラーが出たかどうかだけでは足りません。記録、監視、トリガー不発火、失敗時の判断を分けておく必要があります。
再実行してよい失敗だけにretryを使う判断

失敗したら自動でもう一度試せばいい、と考えていませんか。便利そうですが、投稿や課金のように2回実行すると二重になる処理では、その自動再実行が事故になります。ここでは、再実行(retry)してよい失敗だけを見分ける判断を整理します。
一時的な失敗か恒久的な失敗かの見分け
retry を使ってよいのは、時間をおけば直る失敗だけです。
一時的な失敗は、少し待ってから再実行すると直る可能性があります。
- ネットワークの一時的な途切れ
- 相手サービスの一時的な混雑
- アクセス集中による一時的な制限
- 外部APIの一時的な応答失敗
反対に、恒久的な失敗は retry しても直りません。
- 認証が切れている
- 必須項目が空になっている
- 指定した対象が存在しない
- 入力データの形式が間違っている
- 設定値が間違っている
この違いを分けないまま retry を使うと、直らない失敗を何度も繰り返すだけになります。n8n では、ノード設定の Retry On Fail で、失敗時の再実行を設定できます。ただし、retry を使う前に見るべきことは、回数ではありません。
先に見るのは、次の2つです。
- 時間をおけば直る失敗か
- 同じ処理を2回流しても問題ないか
この2つを満たさない処理には、retry を入れない方が安全です。
同じ処理を2回流すと危険なケースと冪等性
retry で一番危ないのは、同じ処理を2回流すことです。特に危ないのは、外側へ何かを残す処理です。
- 投稿する
- メールを送る
- データを書き込む
- 料金が発生する
- 外部サービスへ登録する
これらは、1回目が実は成功していた場合、retry によって二重実行になる可能性があります。ここで出てくる考え方が冪等性です。
冪等性とは、同じ処理を2回実行しても、結果が1回分と変わらない性質です。
たとえば、次のような処理は retry しやすいです。
- 情報を取得する
- 検索する
- 要約する
- 文章を整形する
- 一時ファイルを作り直す
反対に、次の処理は retry に注意が必要です。
- SNSへ投稿する
- メールを送信する
- スプレッドシートへ追記する
- 請求や決済に関係する
- 外部公開する
特に危ないのは、「成功したか不明」の状態です。
処理は実行されたのに、応答だけが返ってこなかった場合、成功とも失敗とも判断できません。この状態で retry すると、二重投稿や二重書き込みになります。
防ぐには、実行前に処理済みかどうかを確認します。
- 同じ記事IDを処理済みにしていないか
- 同じ日付の投稿を作っていないか
- 同じスラッグで公開済みではないか
- 同じ行番号へ書き込み済みではないか
- 同じ投稿IDが存在しないか
retry してよいのは、一時的な失敗で、かつ二重実行にならない処理です。
AIの応答が崩れたら人間確認に回す判断
AIの出力が崩れた場合は、すぐ retry に回さない方が安全です。
たとえば、次のような失敗です。
- 出力が空
- JSON形式が崩れている
- 必要な項目が抜けている
- 指示と違う形式で返ってくる
- 本文ではなく説明文が混ざる
この失敗は、一時的な不調とは限りません。
入力データが悪い場合もあります。指示文が曖昧な場合もあります。後続処理が期待している形式と合っていない場合もあります。この状態で retry を繰り返すと、同じ失敗を何度も出すだけになります。
AI出力の失敗は、まず後ろの工程で検証します。
- 空でないか
- 必要な項目があるか
- 決まった形式になっているか
- 後続処理に渡してよい内容か
- 人間が確認すべき内容ではないか
検証で崩れていると分かったら、自動で繰り返すのではなく、人間確認へ回します。retry は便利ですが、使う場所を間違えると事故になります。
retry してよいのは、次の条件を満たす失敗だけです。
- 時間をおけば直る
- 同じ処理を2回流しても問題ない
- 後続に壊れたデータを渡さない
- AIの出力形式が検証済みである
この条件に当てはまらない失敗は、止めるか、人間確認へ回します。
送ったあとでは戻せない処理を実行前に止める
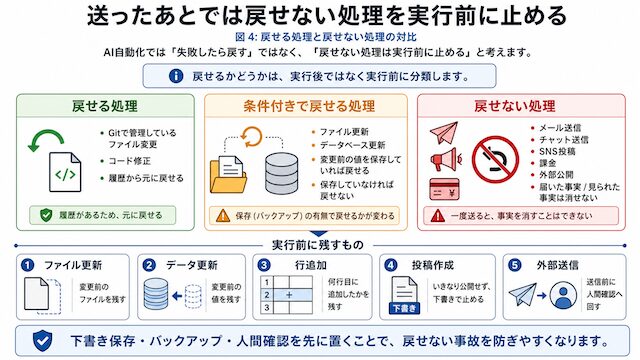
メールを送ったあと、相手に届いた事実は消せません。SNSへ投稿したあと、誰かに見られた事実も戻せません。課金や外部送信が絡む処理も、あとから完全に元へ戻せるとは限りません。
だから、AI自動化では「失敗したら戻す」ではなく、「戻せない処理は実行前に止める」と考えます。
戻せる処理・条件付きで戻せる処理・戻せない処理
自動化の処理は、最初に3つへ分けます。
・戻せる処理
Gitで管理しているファイルやコードの変更です。
履歴が残っていれば、前の状態へ戻せます。
- 条件付きで戻せる処理
ファイル更新やデータベース更新です。
変更前の値を保存していれば戻せます。
保存していなければ戻せません。 - 戻せない処理
メール送信、チャット送信、SNS投稿、課金、外部公開です。
削除できる場合でも、相手に届いた事実、見られた事実、処理された事実は消せません。
ここで大事なのは、戻せるかどうかを実行後に考えないことです。
実行前に分類しておきます。
実行前に残すもの
戻せる状態は、実行前にしか作れません。あとから「戻したい」と思っても、変更前の状態が残っていなければ戻せません。
実行前に残すものは、次のように分けます。
- ファイル更新:変更前のファイルを残します。
- データ更新:変更前の値を残します。
- 行追加:何行目に追加したかを残します。
- 投稿作成:いきなり公開せず、下書きで止めます。
- 外部送信:送信前に人間確認へ回します。
AI自動化では、下書き経由がかなり重要です。下書きなら、まだ外に出ていません。人が見て、問題があれば公開前に止められます。
戻せない処理は承認ゲートで止める
戻せない処理は、戻し方を探すより、実行前に止めます。そのために置くのが承認ゲートです。承認ゲートは、後戻りできない処理の直前で一度止める場所です。
置くべき場所は、次の処理です。
- メール送信
- チャット送信
- SNS投稿
- 記事公開
- 課金
- 削除
- 外部サービスへの登録
何にでも承認を置く必要はありません。承認が多すぎると、確認が作業になり、最後は中身を見ずに通すようになります。承認ゲートは、戻せない処理だけに絞ります。
AI自動化で危ないのは、処理が失敗することだけではありません。成功してしまったあとに、もう戻せない処理があることです。
戻せる処理は戻す準備をします。条件付きで戻せる処理は実行前に控えを残します。戻せない処理は、人間確認で止めます。
失敗を人へ届けるnotificationの絞り込み
通知を全部の処理に付けたら、かえって何も見なくなった。そんな経験はありませんか。「全部通知」は「通知なし」と同じになります。ここでは、人が本当に気づくべき通知だけを残す絞り込みを整理します。

成功通知と失敗通知を分ける理由
成功通知を毎回送ると、失敗通知が埋もれます。
通知するものは、最初から絞ります。
- 失敗した処理
- 人間確認が必要な処理
- お金が動く処理
- 外部へ公開する処理
- メールやチャットを送る処理
反対に、毎回通知しなくてよいものもあります。
- 定常処理の成功
- 件数ゼロ
- 軽微なスキップ
- あとで見ればよい実行結果
成功は、毎回ではなく1日分の要約で十分です。失敗と、外に影響する処理だけをすぐ見える場所へ送ります。
通知に必要な情報の中身
通知は、見た瞬間に次の行動が分かる形にします。
最低限、入れる情報は3つです。
- どの実行か
- どのノードで止まったか
- 何が起きたか
「フローが失敗しました」だけでは足りません。その通知では、どの実行履歴を開けばよいか分かりません。どのノードで失敗したかも分かりません。何を直せばよいかも分かりません。
通知は、調査を始めるための入口です。だから、通知本文には「開く場所」と「見る場所」と「起きたこと」を入れます。
通知疲れを避けるチャンネルの分け方
通知先は、優先度で分けます。
おすすめは、次の3つです。
- 即対応
- 翌日確認
- 日次要約
即対応へ送るものは、今見る必要がある通知だけです。
- フロー失敗
- 承認待ち
- お金が絡む処理
- 公開前確認
- 外部送信前確認
翌日確認へ送るものは、急ぎではないが見ておくものです。
- 軽微な失敗
- スキップ
- 件数ゼロ
- 再実行で復旧した処理
日次要約へ送るものは、まとめて見れば足りるものです。
- 成功件数
- 失敗件数
- 処理時間
- 最大遅延
- スキップ件数
通知を1か所に集めると、全部が同じ重みに見えます。即対応だけを別にすると、本当に見るべき通知だけが残ります。
まとめ
AI自動化でいちばん難しいのは、フローを作ることではなく、壊れたときに気づき・止め・戻し・再実行できる状態を先に用意しておくことです。最後に要点を振り返ります。
失敗を前提に役割を分ける考え方
うまくいく前提ではなく、壊れる前提で7つの役割に分けて設計します。
自動化は、人が見ていない時間も動き続けます。だからこそ「うまくいったとき」だけでなく「壊れたとき」を先に考えておく必要があります。記録・監視・失敗の振り分け・再実行・通知・巻き戻し・常駐の管理という7つの役割を、別々の引き出しとして持っておくことが出発点になります。
記録・監視・再実行・巻き戻しを混ぜない設計
それぞれ役割が違うので、「とりあえず全部通知」「とりあえず全部再実行」のように混ぜると破綻します。
記録は後から追うため、監視はその場で気づくため、再実行は一時的な失敗を立て直すため、巻き戻しは実行前の状態に戻すための役割です。役割を混ぜると、通知の山で何も見なくなったり、やり直したつもりが二重実行になったりします。混ぜないことが、壊れにくい運用設計の核だと考えてよいと思います。
常駐型AIエージェントに欠かせない人間の停止点
動き続ける常駐型ほど、人間がどこで止めるかをあらかじめ決めておくことが要になります。
常駐型のエージェントは、きっかけがなくても動き続けます。動き続ける前提だからこそ、戻せない操作には承認を挟み、コストの上限を決め、すぐ止められる手段を手元に置いておく。「どこまでAIに任せ、どこで人が止めるか」を先に言葉にしておくことが、安全に使う前提になります。
ここまで読んで、自分のフローに当てはめてみると、処理ごとの責任範囲・失敗時の停止点・通知先・戻し方が決まっていない箇所が見つかるかもしれません。その整理は、AI自動化や n8n を本格的に広げる前にやっておくほど、後の手戻りが減ります。
関連解説
常駐型のコスト累積や、コストの上限設定の話に踏み込みたい場合は、API課金の構造を詳しく整理した記事もあわせて参考にしてみてください。
関連記事
そもそも何を自動化対象に選ぶかという、運用設計より前の段階については、こちらの記事で整理しています。




