

AIに「昨日の続きをお願い」と頼んだのに、話がまったく違う方向へ進んでしまったことはありませんか。
前の日に、作業の目的、修正した内容、残っている課題まで細かく話したはずなのに、翌日になるとAIが別の前提で答え始める。
そのたびに、また最初から説明し直すことになります。
これは、AIが急に不親切になったからではありません。でもからかわれてる感じがして頭きますよね。これが原因で私はかなりうちのAIと喧嘩になります(笑
人間側では「昨日の続き」としてつながっているつもりでも、AI側では、今見えている会話、過去の履歴、途中で作ったファイル、現在の進行状態が、同じ場所にまとまっているとは限らないからです。
たとえば、次のような場面でズレが起きます。
- ChatGPTに前回の相談内容を前提にしてほしい
- Claude Codeに昨日の修正作業の続きを頼みたい
- Discord連携したAIに過去のやりとりを踏まえて返してほしい
- n8nのワークフロー内で、AIに途中結果を引き継がせたい
- 作業中の判断、未完了タスク、次にやることをAIに忘れさせたくない
このとき必要なのは、「AIに全部覚えてもらうこと」ではありません。大事なのは、AIがその場で見られる情報と、人間側がファイルとして残しておく情報を分けることです。
この記事では、AIが「忘れた」ように見える原因を、作業状態の残し方として整理します。
最初から難しい仕組みを理解する必要はありません。
まず見るべきなのは、AIが続きを失敗するときに、どの情報が渡っていなかったのかです。
そこが分かると、「昨日の続き」を頼むときに、何を会話で伝え、何をMarkdownやタスク状態として残すべきかが見えてきます。
AIが途中経過を失うように見える理由
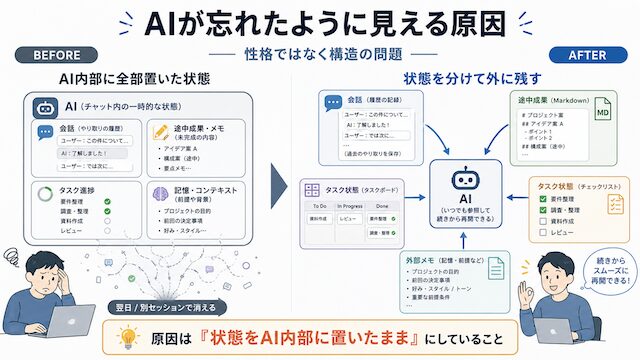
AI が昨日の続きを失うのは、性格ではなく構造の問題です。何で止まっているのかが見えないと、AI を責めてしまいたくなりますよね。ここでは「忘れる」ように見える正体を、状態の分離不足という観点で整理します。
「忘れる」ように見える正体
AI が忘れたように見える場面の多くは、別セッションで始まり context が空の状態になっていることが原因です。前回のチャット画面が残っていても、AI 側から見ると別の作業台に座り直したのと同じです。
Claude Code の公式ドキュメントには「Each Claude Code session begins with a fresh context window.」と書かれており、毎セッションが新しい作業台から始まる仕様です。ChatGPT のように画面上に過去スレッドが見えていても、AI が常に参照しているわけではなく、サービス側がどこまで読み込んでいるかは画面の見た目とは別の話になります。
これエンジニア出身者には理解できても、非エンジニアなどの一般層の方にはなかなか理解し難いのではないかと思います。私はこれまでずっとエンジニア業を生業にしてきましたが、これが原因でかなりの確率で我が家のAIと衝突を繰り返してきました。
context / history / memory / 途中成果 / タスク状態の分離不足
ccontext、history、memory、途中成果、タスク状態と並べられても、最初はどれも「AIが覚えている情報」に見えますよね。
でも、実際にはそれぞれ置き場所が違います。
たとえば、AIに作業を頼んでいるとき、今この瞬間にAIが見ている情報があります。これが context です。作業机の上に広げている資料のようなものです。
その作業机の上には、これまでの会話も積まれます。これが history です。何を話したかの履歴です。
一方で、途中で作ったMarkdown、JSON、ログ、チェックリスト、修正済みファイルは、AIの中に自動で残るものではありません。
これらは途中成果です。ファイルとして保存しておかないと、次に作業を再開するときに確認できません。
さらに、「未着手」「作業中」「完了」「保留」「失敗」「再実行待ち」のような進行状況も、会話とは別に残す必要があります。
これがタスク状態です。
HermesAgent memory のような仕組みも、すべての会話や作業を丸ごと覚えるものではありません。あらかじめ書き込まれた短い情報や、明示的に検索・注入された情報だけが使われます。
つまり、AIが見ている会話、過去の履歴、途中で作ったファイル、作業の進行状態、外部メモリは、全部同じ場所にあるわけではありません。
この5つを同じものとして考えると、「昨日話したのに、なぜ伝わっていないのか」が分からなくなります。
逆に、どの情報がどこにあるのかを分けて考えると、AIが続きを失敗したときに「会話が足りなかったのか」「ファイルが残っていなかったのか」「タスク状態が渡っていなかったのか」を切り分けられます。
context と history の違い
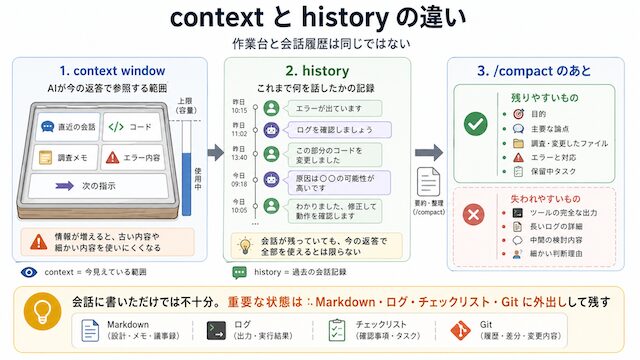
context と history は、どちらも「AI が見ている会話」に見えるかもしれません。
ですが、この 2 つは同じものではありません。
context は、AI が今の返答を作るために見ている作業領域です。history は、これまで積み上がってきた会話の記録です。
人間の感覚では、過去に話したことはそのまま残っているように見えます。でも AI から見ると、「会話として残っていること」と「今の返答で参照できること」は別です。
ここを分けて考えないと、「前に話したのに、なぜ伝わっていないのか」が分からなくなります。
context window という有限の作業領域
context window は、AI が 1 回の返答を作るときに見られる範囲です。
作業机をイメージすると分かりやすいです。机の上に広げられる資料には限りがあります。資料が増えすぎると、古い資料や細かい内容を見落としやすくなります。
AI も同じです。
長いやり取り、貼り付けたコード、調査結果、エラー内容、修正方針などが増えていくと、作業領域がいっぱいになります。その結果、まだ会話履歴には残っていても、今の返答ではうまく使われない情報が出てきます。
Claude などのモデルには、参照できる token 数の上限があります。大きな context window を持つモデルでも、情報を大量に詰め込めば常に正確に扱えるわけではありません。
大事なのは、容量の数字そのものではありません。「会話に書いたから大丈夫」と考えず、重要な判断、完了条件、次にやることは、別のファイルやチェックリストにも残しておくことです。
history と作業状態のズレ
history は、これまで何を話したかの履歴です。
一方で、作業状態は「いま何がどこまで進んでいるか」です。
この 2 つも同じではありません。
たとえば、会話の中に「修正しました」と書かれていても、実際のファイルが保存されていなければ、作業は残っていません。
「確認しました」と書かれていても、確認結果のログやチェックリストがなければ、後から検証できません。
会話履歴は、あくまで会話の記録です。
作業そのものを保証してくれるものではありません。
ここを混同すると、AI に「昨日の続き」を頼んだときに、AI は会話の流れからそれらしい続きを作ってしまいます。
でも、実際にはファイルが残っていない、タスク状態が更新されていない、検証結果がない、ということが起きます。
だから、作業を続けてもらうには、会話履歴だけでは足りません。
- 何を完了したのか。
- 何が未完了なのか。
- どのファイルを見ればよいのか。
- どこで止まったのか。
こうした作業状態を、会話とは別に残す必要があります。
/compact で残るもの・失われるもの
Claude Code の /compact は、長くなった会話を短くまとめる機能です。
要点は残ります。
一方で、細かいやり取り、ツールの完全な出力、中間の検討内容まですべて残るわけではありません。
たとえば、次のような情報は残りやすいです。
- ユーザーが何をしたかったのか
- 重要な技術的な話題
- 調査したファイルや修正したファイル
- 発生したエラーと対応内容
- 残っているタスク
- 現在取り組んでいる作業
逆に、次のような情報は落ちやすくなります。
- コマンドの完全な出力
- 途中で出た細かい候補
- 検討中に捨てた案
- 一時的な判断理由
- 長いログの詳細
- その場では重要に見えなかった補足情報
つまり、/compact 後に残るのは「要約された作業の流れ」です。
作業を再現するための完全な記録ではありません。
だから、あとで必要になりそうな情報は、会話の中だけに置かない方が安全です。
調査結果は Markdown に残す。
実行結果はログとして残す。
完了条件や未完了タスクはチェックリストに残す。
修正内容は Git の差分やコミットで残す。
このように、会話とは別の場所に作業状態を出しておくと、/compact された後でも、翌日でも、別セッションでも続きから再開しやすくなります。
途中成果を残さない作業の危険性
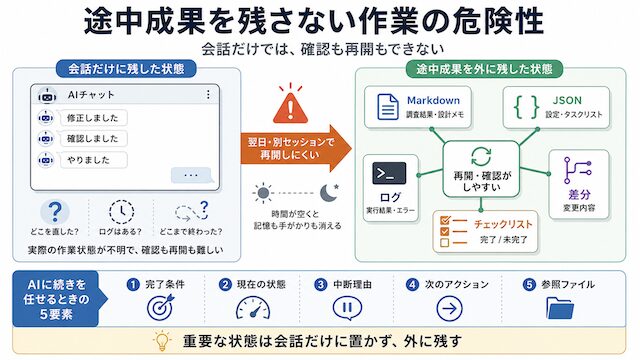
AI に作業を頼んでいると、「やりました」「修正しました」「確認しました」と返ってくることがあります。
そのとき、何を見て確認していますか。
会話の中で「やりました」と書かれていても、実際にファイルが保存されていなかったり、ログが残っていなかったり、どこまで終わったかのチェックがなかったりすると、後から確認できません。
人間が作業するときでも、メモも保存もせずに作業を進めると、次の日に「どこまでやったっけ」となりますよね。
AI でも同じです。
途中で作ったものを外に残しておかないと、会話が長くなったとき、別のセッションで再開するとき、翌日に続きを頼むときに、何を根拠に進めればよいのか分からなくなります。
途中成果をファイルに残す理由
AI に作業を任せるときは、会話だけに頼らず、途中でできたものを外に残しておく必要があります。
ここでいう「途中成果」は、完成品だけではありません。調べた内容、決めた方針、実行したコマンド、出たエラー、修正した差分、残っている作業も含みます。
たとえば、次のように分けて残します。
| 残すもの | 役割 |
|---|---|
| Markdown | 調査結果、設計メモ、判断理由を残す |
| JSON | タスクリスト、設定、記事設計などを機械的に扱える形で残す |
| ログ | 実行結果、エラー、コマンド履歴を残す |
| 差分 | どこを変更したかを残す |
| チェックリスト | 完了したこと、まだ残っていることを残す |
難しく考える必要はありません。要するに、「AI が作業中に見ていた情報」を、あとから人間や別の AI が見ても分かる形で残すということです。
- これをしておくと、途中で止まっても再開できます。
- 別の日に続きを頼んでも、前回の状態を説明しやすくなります。
- AI の返答が正しいかどうかも、会話の雰囲気ではなく、実際のファイルやログで確認できます。
逆に、途中成果を残していないと、AI は会話の流れからそれらしい続きを作るしかありません。その結果、「前回と違うことを言い始めた」「直したはずの内容をまた戻した」「どこまで終わったか分からない」という状態になります。
続きを任せるときに渡すべき 5 要素
AI に続きを任せるときは、長い説明をもう一度書くよりも、最低限の情報を整理して渡した方が安定します。
必要なのは、次の 5 つです。
| 渡す情報 | 意味 |
|---|---|
| 完了条件 | 何ができたら終わりか |
| 現在の状態 | どこまで進んでいるか |
| 中断理由 | なぜ止まっているか |
| 次のアクション | まず何をやるか |
| 参照ファイル | どのファイルを見ればよいか |
たとえば、AI に「続きからお願いします」とだけ言うと、AI は前回の状態を推測するしかありません。
でも、次のように渡せば、再開しやすくなります。
- 完了条件: 記事の冒頭と最初の H2 を読みやすくする
- 現在の状態: 冒頭は修正済み、途中成果の章を修正中
- 中断理由: 専門語が多く、一般読者に伝わりにくい
- 次のアクション: 途中成果の章をやさしい文章に直す
- 参照ファイル: 対象の記事 Markdown と画像配置メモ
ここまで書いておけば、AI は何をすればよいかをかなり正確に判断できます。大事なのは、AI に「前回の流れを思い出してもらう」ことではありません。人間側が、再開に必要な情報を見える場所に残しておくことです。
完了条件、現在の状態、中断理由、次のアクション、参照ファイル。この 5 つを残しておくだけで、「昨日の続き」がかなり安定します。
タスク状態を外部化する必要性
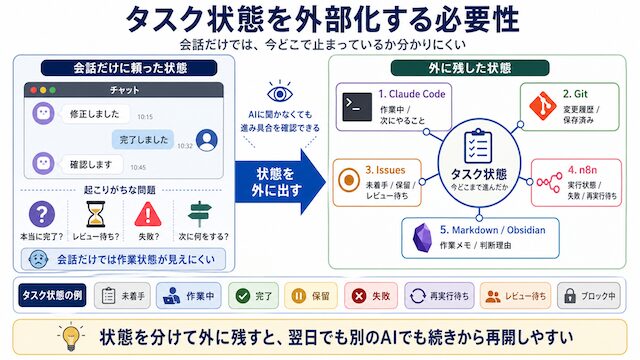
AI に作業を頼んでいるとき、今その作業がどこまで進んでいるかを、AI に聞かなくても確認できますか。
- 「さっきまでやっていたはず」
- 「たしか修正済みだったはず」
- 「前回の会話では終わったと言っていたはず」
このような状態だと、次の日に続きを頼むときに不安定になります。
会話の中に「完了しました」と書かれていても、本当に完了しているとは限りません。
実ファイルが更新されているのか、確認が済んでいるのか、エラーで止まっているのか、次に何をすればよいのかは、会話だけでは分からないことがあります。
だから、タスク状態は会話の中だけに置かず、外から見える場所に残す必要があります。
「済 / 未」だけでは足りない理由
タスクの状態を「終わった」「まだ終わっていない」だけで分けると、途中で困ることがあります。
実際の作業には、もっと細かい状態があります。
| 状態 | 意味 |
|---|---|
| 未着手 | まだ始めていない |
| 作業中 | いま進めている |
| 完了 | 作業が終わっている |
| 保留 | いったん止めている |
| 失敗 | 実行したがうまくいかなかった |
| 再実行待ち | 条件を直したあと、もう一度実行する |
| レビュー待ち | 人間の確認が必要 |
| ブロック中 | 依存する作業や判断が止まっている |
たとえば、「完了」と見えていても、まだ確認が終わっていないことがあります。
「失敗」と見えていても、原因を直せば再実行できることがあります。
「未完了」と見えていても、実際には人間の判断待ちで止まっていることもあります。
これらを全部「未」や「途中」にしてしまうと、AI も人間も次に何をすればよいか判断できません。
タスク状態を細かく分ける目的は、管理を難しくすることではありません。
- 次に動ける状態なのか。
- 人間の確認が必要なのか。
- エラー対応が必要なのか。
- もう一度実行すればよいのか。
この判断をしやすくするためです。
タスク状態を置く場所
タスク状態は、1つの会話の中にだけ置かない方が安全です。
使っている道具ごとに、向いている保存先があります。
| 置き場所 | 残す内容 |
|---|---|
| Claude Code | 作業中のタスク、次にやること、短いチェックリスト |
| Git | 変更履歴、差分、どこまで保存されたか |
| GitHub Issues | 未着手、作業中、保留、レビュー待ちなどの管理 |
| n8n DB | ワークフローの実行状態、成功、失敗、再実行待ち |
| Obsidian / Markdown | 作業メモ、判断理由、次に見る場所 |
たとえば、Claude Code の会話の中で「修正しました」と言われても、Git に差分が残っていなければ、後から変更内容を確認しにくくなります。
n8n のワークフローでエラーが出た場合も、会話で説明するだけでは足りません。
どの実行で止まったのか、どのノードで失敗したのか、再実行できるのかを、実行履歴や外部 DB に残しておく必要があります。
Obsidian や Markdown には、作業の背景や判断理由を残せます。
「なぜこの対応にしたのか」「なぜ保留にしたのか」「次に何を見るのか」を書いておくと、翌日でも別のAIでも再開しやすくなります。
大事なのは、すべてを1か所に詰め込まないことです。
- 会話は会話。
- 変更履歴は Git。
- 作業状態は Issues やチェックリスト。
- 自動化の実行状態は n8n。
- 判断理由や作業メモは Markdown。
このように分けておくと、AI に聞かなくても、いま作業がどこで止まっているかを確認できます。
AIに任せるための状態管理
AI に仕事を任せるなら、「今どうなっているか」をAIの返答だけに頼らない方が安定します。
- AI が「完了しました」と言ったら、何をもって完了とするのか。
- エラーになったら、どこに失敗状態を残すのか。
- 人間の確認が必要なら、どこにレビュー待ちとして置くのか。
- 再実行が必要なら、どこに再実行待ちとして残すのか。
ここまで決めておくと、AI は次にやることを判断しやすくなります。
人間側も、毎回会話を読み直さなくて済みます。
タスク状態を外に出す目的は、管理表を増やすことではありません。
AI に作業を任せても、途中で迷子にならないようにすることです。
そして、人間が画面に張り付かなくても、どこまで進んだかをあとから確認できるようにすることです。
AIエージェントを状態管理の万能手段にしない考え方
ここまで、AI に続きを任せるには、会話だけでなく、途中成果やタスク状態を外に残す必要があると整理してきました。
では、AIエージェントを使えば、この問題は全部解決するのでしょうか。
たとえば、常駐型のAIエージェントや、Discordと連携したAIを見ると、「これなら過去のやりとりも全部覚えてくれるのでは」と期待したくなります。
でも、ここで一度分けて考える必要があります。
AIエージェントは便利です。チャットだけで使うAIよりも、ファイルを読んだり、過去の記録を検索したり、外部ツールとつながったりできます。
ですが、それは「何もしなくても全部覚えてくれる」という意味ではありません。
- 過去の記録が保存されていること。
- AIがその記録を検索できること。
- 検索した結果が今の返答に使われること。
この3つは別の話です。
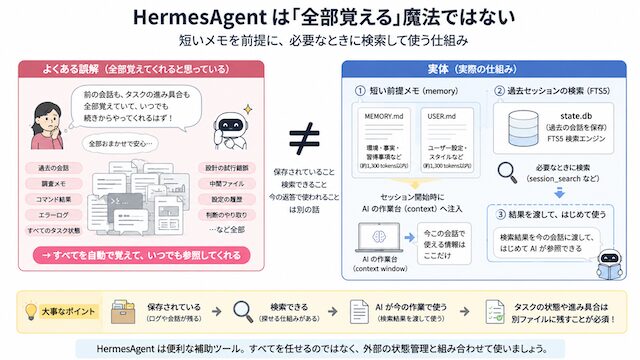
HermesAgent も同じです。便利な memory や検索の仕組みはありますが、全会話を自動で読み直して、毎回すべてを前提にしてくれる魔法の記憶装置ではありません。
ここでは、HermesAgent を例にして、「覚えているように見える仕組み」と「実際にAIが今見ている情報」の違いを整理します。
HermesAgent とは何か
ここで出てくる HermesAgent という名前を、初めて聞く方もいるかもしれません。
HermesAgent は、AIとの会話、コマンド実行、外部ツール連携、memory、過去セッション検索などを組み合わせて使う AI エージェント系の仕組みです。
最近は、LLM に毎回すべてを詰め込むのではなく、外部の記録やナレッジを必要に応じて読ませる考え方が注目されています。LLM-Wiki のように、Markdown や Wiki 型の知識構造を AI が参照しながら使う考え方も、その流れの一つです。
そのため、HermesAgent のような仕組みを見ると、「これなら過去の会話も作業状態も全部覚えてくれるのでは」と期待したくなります。
でも、ここで大事なのは、AIエージェントといっても万能の記憶装置ではない、という点です。
HermesAgent には memory や検索の仕組みがあります。それでも、全会話、全ログ、全タスク状態を自動で毎回読み込んでくれるわけではありません。
ここからは、HermesAgent を例にして、「保存されている情報」と「AIが今の返答で実際に使える情報」の違いを整理します。
memory は短い前提メモ
HermesAgent の memory は、AI に毎回思い出してほしい短い前提を書く場所です。
たとえば、次のような情報を置くイメージです。
| memory に向いている情報 | 例 |
|---|---|
| 環境の前提 | どの作業ディレクトリを使うか |
| ユーザーの好み | どういう口調や進め方を好むか |
| 作業時の注意 | やってはいけないこと |
| よく使う方針 | 出力形式や確認手順 |
これは、すべての会話を保存する場所ではありません。
長い議論、途中で出た候補、コマンドの実行結果、細かいログ、全タスクの進行状況を丸ごと入れる場所ではない、ということです。
HermesAgent の場合、memory は MEMORY.md と USER.md のようなファイルに分かれており、入れられる量にも上限があります。
そのため、ここには「毎回必要になる短い前提」だけを置くと考えた方が分かりやすいです。
検索できることと、自動で読んでくれることは違う
HermesAgent には、過去セッションを検索する仕組みがあります。
ここで注意したいのは、「保存されている」「検索できる」「今の返答に使われる」は同じではない、という点です。
たとえば、机の横に過去のノートが積んであるとします。ノートが存在していても、開かなければ中身は見えません。索引があって探せるとしても、探す操作をしなければ今の作業には使えません。
AIエージェントも同じです。
過去の会話や記録がどこかに保存されていても、AI が自動で全部読み込むわけではありません。必要なときに検索し、その結果を今の作業に使う流れが必要です。
HermesAgent では、過去セッションを検索する仕組みとして FTS5 のような全文検索が使われます。FTS5 という名前を覚える必要はありません。
ここで大事なのは、検索機能があるからといって、過去の内容が毎回自動でAIの作業台に並ぶわけではない、ということです。
Discord に履歴が見えていても、AI が読んでいるとは限らない
Discord とAIを連携すると、チャンネルには過去の会話が残ります。
人間から見ると、画面に履歴が見えているので、AIも当然それを読んでいるように感じます。でも、これは分けて考える必要があります。
Discord に履歴が表示されていることと、AI がその履歴を今の返答で参照していることは別です。AI に「前の続きで」と頼んでも、過去の会話が自動で読み込まれていなければ、AI は今見えている情報だけで答えることになります。
そのため、Discord連携AIに過去文脈を使わせたい場合は、次のような設計が必要になります。
| 必要なこと | 意味 |
|---|---|
| 過去ログを保存する | あとから探せる場所に残す |
| 必要なログを検索する | 関係ある会話を取り出す |
| 検索結果をAIに渡す | 今の返答で使える形にする |
| 重要な状態を別ファイルに残す | 会話履歴だけに頼らない |
つまり、Discordに会話が残っているだけでは足りません。AI がその履歴を見つけて、読み込んで、今の作業に使えるようにする必要があります。
HermesAgent は補助輪として使う
HermesAgent は、状態管理をすべて任せるための道具ではありません。
- 短い前提を memory に置く。
- 過去セッションを検索する。
- 必要な記録を今の作業に戻す。
こうした補助には使えます。
一方で、完了条件、現在の状態、中断理由、次のアクション、参照ファイルのような作業状態は、別途 Markdown、Issues、Git、n8n DB などに残しておいた方が安定します。
AIエージェントを入れれば状態管理が不要になるのではありません。AIエージェントが参照できるように、人間側が状態を外に出しておく必要があります。
AIに仕事を任せる前に人間が残すべき情報
AI に作業を任せるとき、いちばん困るのは「次に何をすればよいか」が分からなくなることです。
前の日にかなり話したはずなのに、翌日になると、AI が前提を取り違える。途中まで進んでいたはずなのに、どこから再開すればよいか分からない。終わったと思っていた作業が、本当に終わっているのか確認できない。
こうなると、また最初から説明し直すことになります。
これを防ぐには、AI に続きを頼む前に、人間側で最低限の情報を残しておく必要があります。
難しい管理表を作る必要はありません。
まずは、次に作業を再開するときに困らない情報を、短く残しておくことが大切です。
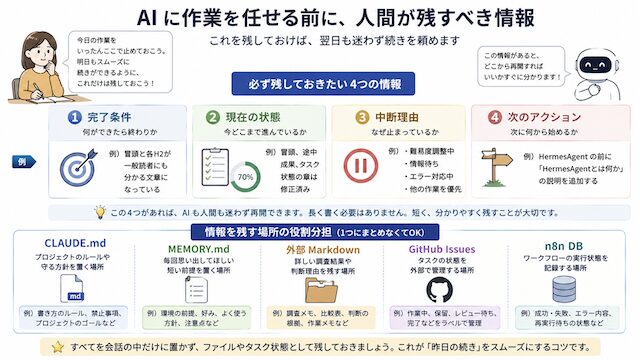
翌日も続きを頼むために残す4つの情報
AI に作業を渡す前、または作業をいったん止める前に、次の4つを残しておきます。
| 残す情報 | 意味 |
|---|---|
| 完了条件 | 何ができたら終わりか |
| 現在の状態 | 今どこまで進んでいるか |
| 中断理由 | なぜ止まっているか |
| 次のアクション | 次に何から始めるか |
たとえば、記事リライトなら次のように書けます。
| 残す情報 | 例 |
|---|---|
| 完了条件 | 冒頭と各H2が一般読者にも分かる文章になっている |
| 現在の状態 | 冒頭、途中成果、タスク状態の章は修正済み |
| 中断理由 | HermesAgent の説明が急に難しくなるため調整中 |
| 次のアクション | HermesAgent の前に「HermesAgentとは何か」の説明を追加する |
このくらいで十分です。
大事なのは、AI に「前回の流れを思い出して」と頼むことではありません。
AI が作業を再開できるように、必要な情報を見える形で渡すことです。
- 「何を目指しているのか」
- 「今どこまで終わったのか」
- 「なぜ止まっているのか」
- 「次に何をすればよいのか」
この4つがあれば、AI も人間も迷いにくくなります。
保存先は1つにまとめない
作業状態を残す場所は、1つにまとめなくて大丈夫です。
むしろ、役割ごとに分けた方が再開しやすくなります。
| 保存先 | 置くもの |
|---|---|
| CLAUDE.md | プロジェクト全体のルールや守る方針 |
| MEMORY.md | 毎回思い出してほしい短い前提 |
| 外部 Markdown | 調査結果、判断理由、作業メモ |
| GitHub Issues | タスクの状態、保留、レビュー待ち |
| n8n DB | ワークフローの実行状態、成功、失敗、再実行待ち |
- たとえば、CLAUDE.md には「このプロジェクトでは何を守るか」を置きます。
- MEMORY.md には「毎回参照したい短い前提」を置きます。
- 外部 Markdown には、詳しい調査結果や判断理由を残します。
- Issues には、作業中・保留・レビュー待ちなどのタスク状態を置きます。
- n8n DB には、自動化フローの実行結果や失敗状態を残します。
すべてを1つのファイルに詰め込むと、後から探しにくくなります。AI に読ませる量も増えすぎます。必要な情報が埋もれて、結局また説明し直すことになります。
だから、保存先は役割で分けます。
- ルールは CLAUDE.md。
- 短い前提は MEMORY.md。
- 詳しい記録は Markdown。
- タスク状態は Issues。
- 自動化の実行状態は n8n DB。
このように分けておくと、翌日に続きを頼むときも、「どこを見ればよいか」をAIに伝えやすくなります。
人間が残すのは、AIへの引き継ぎメモ
ここまでの話をまとめると、人間が残すべきものは、AIへの引き継ぎメモです。
長文でなくて構いません。
きれいな資料でなくても構いません。
次に再開するときに、AI が迷わないだけの情報があれば十分です。
- 何ができたら終わりか
- 今どこまで進んでいるか
- なぜ止まっているか
- 次に何をするか
- どのファイルを見ればよいか
この情報を会話の中だけに置かず、ファイルやタスク状態として残しておく。
それだけで、AI に「昨日の続き」を頼むときの失敗はかなり減ります
まとめ
AI に「昨日の続き」を頼んでも話がズレるのは、AI が急に忘れっぽくなったからではありません。
多くの場合、前回の作業状態が、AI に分かる形で残っていないことが原因です。
人間は、昨日の会話、作ったファイル、途中まで進めた作業、次にやることをまとめて「続き」と考えます。
でも AI から見ると、それらは同じ場所にあるとは限りません。
- 会話は会話。
- 途中成果はファイル。
- タスク状態はチェックリストや Issues。
- 変更履歴は Git。
- 自動化の実行状態は n8n。
- 短い前提は memory。
このように、情報の置き場所を分けて残しておく必要があります。
AI に続きを任せたいなら、毎回すべてを説明し直すのではなく、次の情報を残しておくことが大切です。
| 残す情報 | 意味 |
|---|---|
| 完了条件 | 何ができたら終わりか |
| 現在の状態 | 今どこまで進んでいるか |
| 中断理由 | なぜ止まっているか |
| 次のアクション | 次に何から始めるか |
| 参照ファイル | どこを見ればよいか |
この5つがあれば、AI は前回の作業を思い出すのではなく、残された情報を見て続きを判断できます。
HermesAgent のような AIエージェントを使っても、この考え方は変わりません。AIエージェントは便利ですが、すべてを自動で覚えてくれる魔法の記憶装置ではありません。
大事なのは、AI に覚えさせることではなく、AI が必要な情報を見に行ける状態を作ることです。
会話の中だけに置かず、Markdown、チェックリスト、Git、Issues、n8n DB などに作業状態を残す。それができると、翌日でも、別セッションでも、別のAIでも、続きから作業を再開しやすくなります。




