

AI を業務で使っていると、同じ前提を毎回説明していることに気づく場面があります。
会社のルール、記事の書き方、ファイルの置き場所、確認してほしい観点、やってはいけないこと。最初はその都度プロンプトに書けば済みますが、作業が増えるほど説明文が長くなり、AI に仕事を任せているのか、AI に毎回仕事の説明をしているのか分からなくなってきます。
この状態で必要なのは、プロンプトをさらに長くすることではありません。1回だけ使う依頼文と、何度も使う作業手順を分けることです。毎回貼り直している前提は、再利用できる形に切り出したほうが、作業の再現性が上がります。
この記事では、AI への仕事の渡し方を、プロンプト、タスク、ワークフロー、スキル、引き継ぎ、自律型エージェントの段階に分けて整理します。目的は、専門用語を覚えることではなく、自分が毎回説明している内容を、どこに保存し、どこから再利用すればよいかを判断できるようにすることです。
読み終えたときに、毎回打ち込んでいる補足のうち、どれを作業手順として残し、どれを自動化の流れに組み込み、どこを人間が引き継ぐべきかが見える状態を目指します。
なぜプロンプトだけでは作業手順を渡したことにならないのか
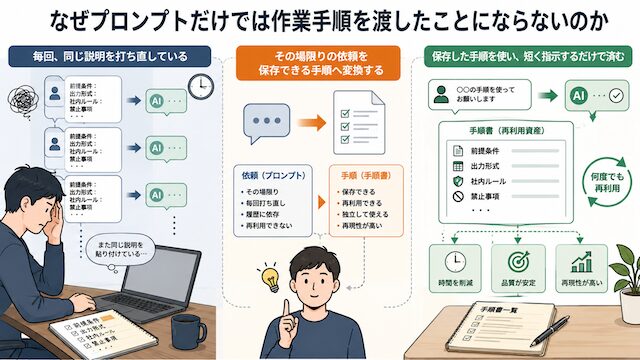
AI に仕事を渡したつもりが、毎回同じ説明を打ち込み直している。その状態は、プロンプトという 1 回限りの依頼文と、作業手順という再利用可能な指示の塊とを混ぜている合図です。本章では、プロンプトと作業手順の境界をはっきりさせ、なぜ毎回の打ち直しが構造的に発生するのかを整理します。
プロンプトはそのターンで消える指示文に過ぎない
プロンプトは LLM API の 1 回の入力で、応答が返るとそのターンで完結します。会話履歴に残るのは「やり取りの記録」であって、「次回からも同じ手順で動かす保証」ではありません。
会話履歴は LLM ベンダー側のセッションに依存し、別のスレッドや別のツールに切り替えた瞬間に消えます。同じ AI に翌週同じ仕事を頼む場合でも、前提条件・出力形式・社内固有ルールはまた打ち込み直す前提で動かす必要があります。プロンプトは依頼文であり、保存物ではないという区別が、6 段階階層の出発点です。
この前提を踏まえると、AI を使う側が「再利用したい」と感じた瞬間に、プロンプトの外側 (ファイル・設定・ツール定義) に出す設計判断が要求されていると読み替えられます。プロンプトの工夫だけで再利用性を出そうとすると、毎回貼り付ける長文テンプレートが肥大化し、管理コストが上回ります。
「同じ補足を毎回打ち込んでいる」は手順化の合図
Anthropic は Claude Code のドキュメントで、同じ指示を何度も貼り付けているなら skill を作るよう案内しています。同じ補足の繰り返しは、プロンプトの工夫不足ではなく、その補足を外に置く設計が抜けているサインとして読み替えるのが妥当です。
実務では「文体ルールを毎回貼っている」「特定ディレクトリ構造の前提を毎回説明している」「禁止事項リストを毎回コピーしている」など、繰り返し補足の対象は人によって異なります。共通しているのは、内容が毎回同じであるという 1 点です。これは個別の依頼内容ではなく前提条件であり、依頼文の外に置けば次回からは「skill を使って」とだけ指定できます。
同じ補足を打ち込んでいる時間は、生産性差として表面化します。AI で速くなるエンジニアと遅くなるエンジニアの差は、ツールの使い方の上手さよりも、補足の繰り返しに気付けているかどうかに先に出ます。詳細はAIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差で扱っています。
単発依頼と手順設計の決定的な差
単発のプロンプトは「今この場でだけ動かすための指示」、手順設計は「次回以降も同じように動かすための保存物」です。保存形式 (ファイルか、揮発か) と呼び出し可否で、両者は別物として扱う必要があります。
両者を分けると、AI に渡す行為が「依頼」と「設計」の 2 種類に分かれていることが見えてきます。依頼は今回 1 回の出力を取り出す行為、設計は次回以降の依頼を短くするための投資です。同じ依頼が 3 回繰り返されたら、3 回目に依頼として打ち込むのではなく、手順として外に出す判断に切り替えるのが構造的に正しい動きです。
この判断軸を持つと、「AI を使いこなしている」状態は長文プロンプトを書けることではなく、依頼と設計のスイッチを意識的に切り替えられることだと言い直せます。
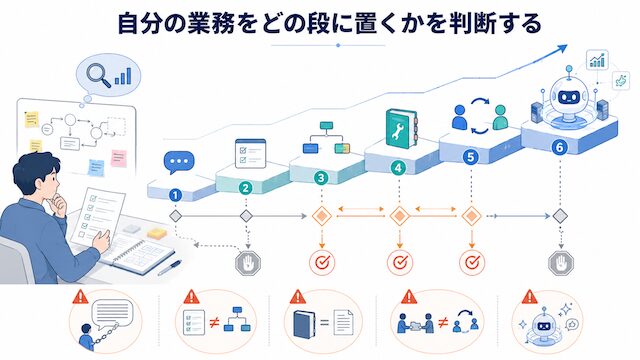
AIに作業を渡す行為は 6 段階に分けられる
prompt から HermesAgent まで、AI に作業を渡す行為には粒度の異なる 6 つの段が存在します。各段で「保存形式」「再利用性」「制御の所在」が違うため、自分の業務がどの段に置くべきかを意識すると、設計の解像度が一気に上がります。本章では公式定義をもとに 6 段階を並列に並べ直します。
prompt → task → workflow → skill → handoff → HermesAgent の概念階層
6 段階を矢印で並べると、左から右へ「より大きな単位」「より再利用可能」「より自律的」に動きます。右側が常に正解というわけではなく、業務に応じてどこで止めるかを選ぶための階層として扱います。
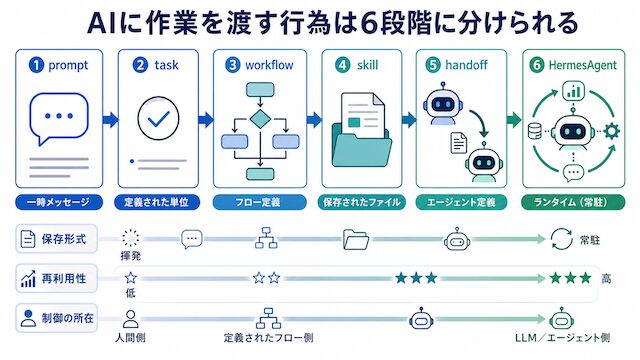
各段の役割をひと言で並べると、prompt は揮発する依頼文、task は 1 目的の実行単位、workflow は事前定義された複数 task の流れ、skill は再利用可能な作業手順の保存物、handoff はエージェント間の制御移譲、HermesAgent はランタイム本体です。同じ単語が出典によって違う層を指していることがあるため、本記事では各段の出典を都度明示します。
保存形式・再利用性・制御の所在で並列に見る
prompt は揮発し、task は明示形式を持たず、workflow はフロー定義、skill は SKILL.md とサポートファイル、handoff は LLM 上のツール表現、HermesAgent はランタイム本体に保存先が分かれます。再利用性と制御の所在もこの順に変化します。
3 軸で表として並べると次の通りです。
| 段 | 保存形式 | 再利用性 | 制御の所在 |
|---|---|---|---|
| prompt | 揮発 (会話履歴のみ) | なし | 依頼者 (人間) |
| task | 明示形式なし (依頼内の 1 単位) | プロンプト依存 | 依頼者 (人間) |
| workflow | フロー定義 (n8n / コードパス) | あり (定義ファイルとして) | 事前定義済みコード |
| skill | SKILL.md + scripts/ + references/ + assets/ | あり (ファイル保存物) | LLM が読み込んで実行 |
| handoff | LLM 上のツール定義 (Agents SDK 等) | あり (エージェント定義として) | エージェント間で移譲 |
| HermesAgent | ランタイム本体 (常駐プロセス) | あり (常駐自律) | エージェント自身 |
この表を見ると、prompt と HermesAgent の間には依頼と運用の差が横たわっていることが分かります。途中の各段は、その差を埋めるための保存・再利用・制御移譲の階段として並んでいます。
どの段で止めても設計として正しい
小規模業務であれば skill 止まりで十分、複数の専門領域が絡む業務なら handoff まで分解する必要が出てきます。HermesAgent まで進めるかどうかは、業務量と運用コストの兼ね合いで判断する話で、上の段ほど偉いという話ではありません。
skill 止まりが「初心者の段」というわけではなく、業務が単一専門領域に閉じていれば skill が最適点になります。反対に、複数領域を 1 つのエージェントで処理しようとすると指示が肥大化し、handoff まで分解した方が結果的に運用コストが下がる場合があります。最上段の HermesAgent は常駐自律が必要な業務以外では過剰で、運用負荷が利益を上回りやすい点に注意が必要です。
skills と workflow と task と handoff の違いを整理する
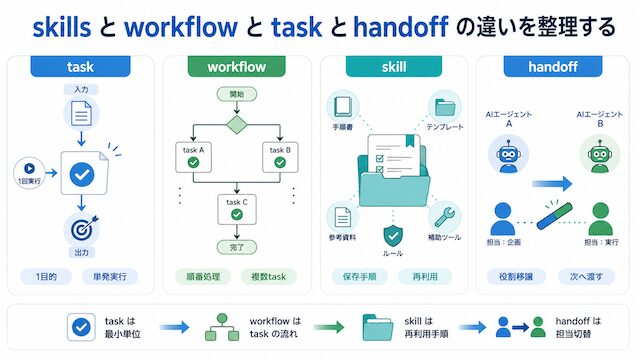
6 段階のうち、混同が起きやすい中盤の 4 段 (skills / workflow / task / handoff) を一つずつ見ていきます。同じ語が出典によって違う意味で使われているため、Anthropic と OpenAI と n8n の公式定義を並べ、それぞれが何を指しているかをはっきりさせます。
skills は再利用可能な作業手順・判断基準・制約のまとまり
skills は agentskills.io が策定するオープン標準で、SKILL.md と scripts/ / references/ / assets/ で構成されます。Claude Code・Gemini CLI・GitHub Copilot など 30 を超えるツールが採用しており、AI に再利用可能な作業手順を渡すための保存先として位置づけられます。
agentskills.io が定めているディレクトリ構造は次の 4 行に集約されます。
SKILL.md scripts/ references/ assets/
SKILL.md が作業手順本体、scripts/ が補助スクリプト、references/ が参照すべきナレッジ、assets/ が画像・テンプレート等を置く場所です。AI に「文体ルール」「禁止事項」「出力フォーマット」を毎回貼り付ける代わりに、SKILL.md として保存しておけば次回以降は読み込むだけで前提が揃います。
skill が単なるテンプレートではなく、references/ や scripts/ を持つ運用実例である点は、AIに過去の記憶を忘れさせない方法|LLMナレッジベースという考え方で扱っているナレッジベース運用と地続きです。skill が読み込む references/ をどう構造化するかが、運用後の精度を大きく左右します。
workflow は複数処理を順番に流す業務導線
workflow は Anthropic Building Effective Agents の定義では「LLM とツールが事前定義のコードパスで調整されるシステム」です。n8n などの自動化基盤では automation flow 全体を指して使われることもあり、出典で意味が分かれる点に注意が必要です。
Anthropic 公式は agent と workflow を対比させた上で、agent を「LLM が自身のプロセスとツール使用を動的に指示するシステム」と定義しています。workflow は事前定義された決まったルートを通る点で、agent と区別されます。
n8n は AI agentic workflow を「AI エージェントが自律的に判断しながら処理を進めるフロー」として案内しており、Anthropic の workflow よりも agent 寄りの動きを含めて指す傾向があります。同じ workflow という語でも、文脈が「決まったコードパス」(Anthropic) なのか「AI が判断しながら流すフロー」(n8n) なのかで意味が変わるため、出典を確認する習慣が要ります。
workflow を n8n で実装した場合のコスト構造については、n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算で扱っています。workflow を組む前に、AI 呼び出しがどこで何回発生するかを設計しておかないと、運用後に課金が膨らみます。
task は 1 目的の実行単位
task は Anthropic では workflow 内の作業単位、agentskills.io では skill の Task content として登場します。OpenAI Agents SDK には公式 API としての task はなく、「ターン」という別概念で扱われており、同じ task という語でも層が異なります。
実務で「これは 1 つの task」と言うとき、ほとんどの場合「1 回で出力を取り出したい単位」を指しています。workflow がその task を複数つなげたものであり、skill はその task を実行するための前提条件をまとめたものだと整理すると、関係が見えてきます。
task を意識的に切り分ける効用は、「依頼を分割した方が AI の精度が上がる」点にあります。1 つのプロンプトに複数 task を詰め込むより、task ごとにスレッドや呼び出しを分けた方が、各 task の精度が高く出る傾向があります。
handoff は人間・AI・別ツール間で作業を引き渡す境界
handoff は OpenAI Agents SDK の公式定義で「あるエージェントから別エージェントへの作業委譲」です。LLM 上ではツールとして表現され、会話履歴ごと次のエージェントへ制御が移ります。人間が引き継ぐ意味の handoff ではない点に注意してください。
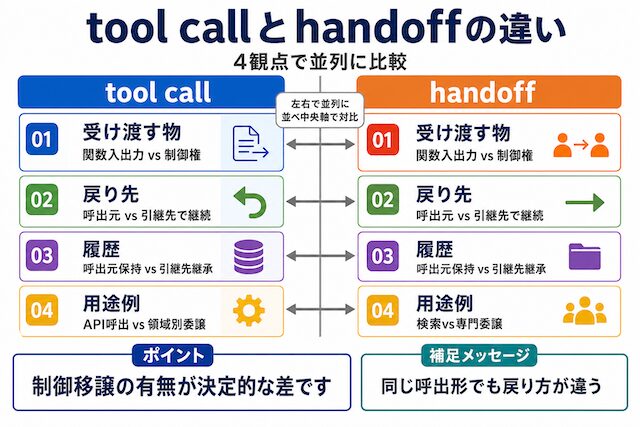
handoff を tool call と比較すると、両者は LLM 上で同じ「ツール」として表現される一方、振る舞いが異なります。
| 観点 | tool call | handoff |
|---|---|---|
| 制御 | 呼び出し元エージェントに制御が戻る | 制御自体が次のエージェントへ移る |
| 会話履歴 | 呼び出し元が継続 | 次のエージェントへ引き継がれる |
| 用途 | 機能の呼び出し (検索・計算・API 実行) | 専門領域の切り替え (営業 → 経理 等) |
handoff まで分解する設計が必要になるのは、1 つのエージェントで複数専門領域を処理するとプロンプトが肥大化し、各領域の精度が落ちる場合です。専門化と引き換えに、エージェント数が増えた分だけトークン消費は積み上がります。
HermesAgent はどう位置づければよいのか
6 段階の最上段に置いた HermesAgent は、Nous Research が提供する常駐型の自律エージェントランタイムです。万能 AI として扱う前に、何ができて何ができないかを公式ドキュメントと実機検証の範囲で押さえます。
ChatAI の頭脳に手足を付ける常駐型自律エージェントの一例
HermesAgent は LLM の頭脳に「外部ツール接続」「セッション間記憶」「常駐実行」の手足を付けた構成で、メッセージング 15 経路超のゲートウェイから到達できます。AI エージェントを継続作業や常駐処理へ広げる代表例として参照する位置づけです。
ChatGPT や Claude のような対話型 AI は、依頼が来てから応答する受動的なモデルです。HermesAgent は常駐プロセスとして動き続け、自律的にツールを呼び出す点が異なります。常駐させる以上、API 課金は使っていない時間にも一定発生し、運用コストの設計が前提条件になります。
HermesAgent と類似する常駐自律エージェントの位置づけや、AI の使い方そのものの 3 種類 (サブスク・API・ローカル LLM) との関係は、ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類あるで並列に整理しています。
skill を自動生成するランタイムだが万能 AI ではない
公式は skill の自動生成トリガーとして「5 回以上のツール呼び出し」「エラー回復」「ユーザー修正」「非自明なワークフロー発見」の 4 条件を挙げています。これはモデル再学習ではなく、スキルファイルを自律生成する仕組みで、AI が勝手に賢くなるわけではありません。
4 条件はいずれも「人間が同じ操作を繰り返している」「人間が AI の出力を毎回修正している」状態を検知するトリガーです。HermesAgent はその検知結果をもとに SKILL.md を生成し、次回以降の依頼で読み込めるようにします。生成された skill 自体は人間がレビューして取捨選択する前提で、AI が業務全体を判断するわけではありません。
skill 自動生成は agentskills.io の標準に乗っているため、生成された skill ファイルは Claude Code や Gemini CLI など他ツールでも読み込めます。ランタイムをまたいで skill を共有できる点が、agentskills.io オープン標準のメリットです。
ローカル LLM 接続では実用にならないという実機検証の含意
Mac mini 24GB に Ollama でローカル LLM を接続した実機検証では、cc-wiki 読み取りなどの思考タスクは実用に届きませんでした。「常駐自律」とバックエンド LLM の性能は別軸の話だと押さえておくと、HermesAgent を冷静に評価できます。
HermesAgent そのものは LLM ではなくランタイムです。バックエンドに接続する LLM の性能と、HermesAgent の常駐自律機能は独立した軸として評価する必要があります。ローカル LLM でコストを抑えようとすると、思考精度が業務に届かず、結果として API モデル接続が前提になりやすい構図です。
この含意は、HermesAgent を本格運用したい場合に「常駐ランタイム代」と「LLM API 代」の二重コストを背負う準備が要ることを意味します。本記事では HermesAgent を 6 段階の最上段として参照位置に置き、本格運用は別途の判断としています。
自分の業務をどの段に置くかを判断する
6 段階を理解した後、実務で必要になるのは「自分の業務はどの段に置くか」の判断です。すべてを最上段に押し上げる必要はなく、業務ごとに止めるべき段が異なります。skill / workflow / handoff の使い分けと、5 つの誤解の自己診断で判断軸を整えます。
skill 化するべき業務 / workflow 化するべき業務の見分け方
同じ補足を 2 回以上打ち込んでいるなら skill 化、複数 task を毎回同じ順序で実行しているなら workflow 化が分岐点です。skill と workflow は対立せず、workflow の中で skill を呼び出す構成も成立します。
skill 化は「依頼文に貼っている前提条件 (文体・禁止事項・出力形式・参照ファイル) を外に出す」動きです。workflow 化は「複数の依頼を毎回同じ順序で投げている流れを定義として保存する」動きで、向きが違います。両者は混ぜて使え、workflow のステップごとに skill を読み込む構成にすると、フロー全体の前提を skill 側で管理できます。
判断順としては、まず skill 化 (前提の保存) を済ませた上で、workflow 化 (流れの保存) に進むのが運用しやすい順序です。先に workflow を組むと、各ステップに毎回同じ補足を埋め込むことになり、skill 化のメリットが薄れます。
handoff まで分解するべき業務の特徴
1 つのエージェントで処理すると指示が肥大化する複数専門領域の業務では、handoff まで分解する価値が出てきます。一方で handoff はマルチエージェント設計に伴うトークン消費の増大 (3〜10 倍規模) を背負うため、専門化で得られる精度向上と引き換えに評価する必要があります。
handoff まで分解する典型は、「営業 → 見積もり → 契約 → 経理」のような専門領域の切り替えが明確な業務です。各領域に異なる SKILL.md と参照資料が必要で、1 つのエージェントに全部を持たせるとプロンプトが破綻します。
トークン消費の増大は、エージェント数が増えるほどシステムプロンプトとツール定義が複製される構造から発生します。3〜10 倍規模という数字はマルチエージェント設計の一般的な目安で、精度向上が課金増を上回るかを業務単位で判断する必要があります。
5 つの誤解の自己診断
長文プロンプト依存 / workflow と task の混同 / skill をテンプレート扱い / handoff を人間引き継ぎと混同 / HermesAgent を万能 AI と捉える、の 5 つの停止点を自己診断のチェックリストとして並べます。自分の業務がどこで止まっているかを言語化する出発点として使ってください。
各停止点の自己診断のポイントは次の通りです。
- 長文プロンプト依存: 同じ補足を 2 回以上貼っているなら skill 化を検討
- workflow と task の混同: 「1 回で出力したいか」「複数 task を順に流したいか」で分ける
- skill をテンプレート扱い: SKILL.md だけでなく references/ と scripts/ を運用しているかを確認
- handoff を人間引き継ぎと混同: handoff はエージェント間移譲で、人間の業務引き継ぎとは別概念
- HermesAgent を万能視: 常駐ランタイム機能と LLM 性能を分けて評価する
AI を構造理解なしに使うことで起きる誤解の全体像は、「AIでノーコード開発」は幻想|構造を知らずにアプリを作ろうとする人へ告ぐでも扱っています。本記事の 5 停止点はその構造理解の中でも、特に「作業手順をどう渡すか」に絞った診断軸です。
まとめ
AI に作業を渡す行為は、prompt から HermesAgent までの 6 段階に分解できます。長文プロンプトを書くことではなく、どの段でどう保存するかを設計することが、AI 時代の仕事の作り方そのものです。自分の業務を 6 段階のどこに置くかを言語化したい方は、業務整理・仕様整理・自動化設計の相談窓口を併せてご利用ください。
prompt は揮発し、task は 1 目的の実行単位、workflow は複数 task の流れ、skill は SKILL.md とサポートファイルの保存物、handoff はエージェント間の制御移譲、HermesAgent は常駐自律ランタイムという順で、保存形式と再利用性と制御の所在が変化します。どの段で止めるかは業務量と運用コストの兼ね合いで決まり、上の段ほど偉いという話ではありません。
5 つの誤解の自己診断を通して、自分が長文プロンプトに依存していないか、workflow と task を混同していないか、skill をテンプレート扱いしていないか、handoff を人間引き継ぎと取り違えていないか、HermesAgent を万能視していないかをチェックしてください。停止点が言語化できれば、次に進むべき段が見えてきます。
関連記事
本記事の 6 段階階層と並列に読むと、AI 活用の前提条件が補完されます。
- ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある — AI の使い方 (料金・実行形態) の 3 種類を並列に整理した記事。本記事の「渡し方の粒度」と「使い方の前提」を補完する関係。
- 「AIでノーコード開発」は幻想|構造を知らずにアプリを作ろうとする人へ告ぐ — AI を構造理解なしに使うことの誤解を扱った記事。本記事の 5 つの誤解の自己診断と接続します。
- AIは誰でも使えるが成果を出せるのはエンジニアだけという現実 — AI を「使う」と「成果を出す」の差を扱った記事。本記事の「作業手順を渡す」設計と接続します。
次に読む記事
本記事で「作業手順の設計側に回る」結論を出した直後に読むと、ポジション選びの判断材料が揃います。
- AIで今後自分の仕事はどうなる?|AI時代に作業者のままでは危ない理由 — シリーズ最終記事として、作業者のまま AI を使う側に留まった場合のリスクと、判断責任ポジションへの移行を扱っています。




