ネットワークの調子が悪いとき、あなたはまず何を疑いますか。サーバーの設定でしょうか、それとも回線の不具合でしょうか。
そんなときに真っ先に使われるのが「ping」と「traceroute」です。普段は意識しないコマンドですが、実はネットワークの状態を診断するうえで欠かせない役割を担っています。
例えば、相手のサーバーにきちんと到達できているのか、どの経路でパケットが流れているのか、途中で遅延や途切れが発生していないかを確認することができます。
もし応答が返ってこなかった場合、それは相手のサーバーが落ちているのか、それとも途中のネットワークに問題があるのか。状況を切り分ける最初の手がかりを与えてくれるのがこれらのコマンドです。
本記事では、pingとtracerouteを使ったネットワーク診断の基本をわかりやすく解説していきます。
Linuxの基礎知識
└─【Linuxの基礎知識】ネットワーク系でよくあるトラブルと解決の入口
├─ 【Linuxの基礎知識】ネットワーク設定とトラブルシューティングを徹底解説!
├─ 【Linuxの基礎知識】tcpdumpの使い方と通信トラブルの本質的な見方
├─ 【Linuxの基礎知識】ping / tracerouteでわかるネットワーク診断の基本
├─ 【Linuxの基礎知識】dig / host / nslookupの違いとDNSトラブル調査法
├─ 【Linuxの基礎知識】nmapの使い方とセキュリティ確認の実践
└─ 【Linuxの基礎知識】ss / netstatでポート状態を確認する方法
pingコマンドとは
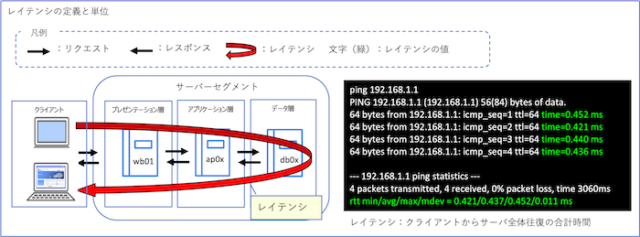
pingコマンドは、ネットワークの疎通確認を行うための最も基本的なコマンドです。
サーバーやルーターなどの機器が応答するかどうかを確認することで、通信経路が正しくつながっているかを簡単に判断することができます。
ネットワーク障害が発生したときに、まず最初に利用されることが多いコマンドです。
基本概要
pingコマンドはICMP(Internet Control Message Protocol)を利用して対象にエコー要求を送信し、その応答が返ってくるかを確認します。
応答があれば通信経路が確立されていることを意味し、応答がなければ対象に到達できない、またはファイアウォールなどで遮断されている可能性があります。
ping www.example.com
このように簡単なコマンドで対象への応答時間(RTT: Round Trip Time)を確認することができ、ネットワーク遅延や接続可否の切り分けに役立ちます。

取得できる情報の種類
pingコマンドを実行することで、以下のような情報を取得できます。
| 取得できる情報 | 説明 |
|---|---|
| 応答可否 | 対象ホストが応答するかどうかを確認できます。 |
| 遅延時間 | パケットの往復にかかる時間(ミリ秒単位)を表示します。 |
| パケットロス | 送信したパケットのうち応答が返らなかった割合を確認できます。 |
| 統計情報 | 平均応答時間や最大値・最小値などの統計を取得できます。 |
これらの情報は、回線品質の目安や通信経路の健全性を判断する材料となります。
メリットと他ツールとの違い
pingコマンドの最大のメリットは、その手軽さと汎用性にあります。ほとんどのLinux環境に標準で搭載されており、特別な設定を必要とせずに利用できます。
一方で、pingは単純に応答の有無と遅延を確認する機能しか持たないため、経路情報までは把握できません。経路を確認したい場合には、tracerouteコマンドのような他の診断ツールを併用する必要があります。
このように、pingは「接続確認の第一歩」として位置づけられるシンプルかつ重要なコマンドです。
tracerouteコマンドとは
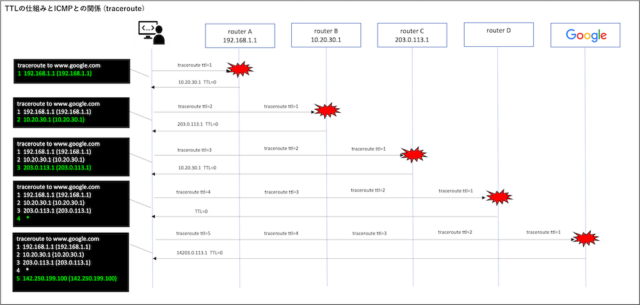
tracerouteコマンドは、通信が相手先に届くまでにどのような経路をたどっているのかを確認するためのコマンドです。
ネットワーク障害の切り分けを行う際に、どこで通信が滞っているのかを可視化できる便利なツールです。
インターネットの通信は複数のルーターを経由して相手先に届きますが、その経路上のどこに問題があるのかを知ることで、原因調査を効率的に進めることができます。
基本概要
tracerouteコマンドは、対象ホストに向けてTTL(Time To Live)値を変化させながらパケットを送信し、経路上の各ルーターからの応答を収集します。これにより、どのルーターを経由して目的地に到達しているかが順番に表示されます。
traceroute www.example.com
このように入力することで、指定したホストまでの通信経路が表示され、途中で遅延や不達が発生している箇所を特定できます。

取得できる情報の種類
tracerouteコマンドを利用すると、以下のような情報を確認することができます。
| 取得できる情報 | 説明 |
|---|---|
| 経路情報 | 対象ホストに到達するまでのルーターの順序を確認できます。 |
| 応答時間 | 各経路ごとの応答速度をミリ秒単位で確認できます。 |
| 障害箇所の特定 | 途中で応答が途絶える地点を把握することで、障害の発生場所を推測できます。 |
これらの情報は、回線の品質や特定のネットワーク区間の状態を調査する際に有用です。
メリットと他ツールとの違い
tracerouteコマンドのメリットは、ネットワーク経路を可視化できる点にあります。単純に通信の可否や遅延だけを確認するpingとは異なり、どの区間で問題が発生しているかを具体的に確認できるのが強みです。
ただし、経路上のルーターがICMPやUDPの応答を返さないように設定されている場合、結果が正確に表示されないことがあります。そのため、pingコマンドと併用して確認することで、より精度の高い切り分けが可能になります。
このように、tracerouteはネットワーク障害の調査に欠かせない診断ツールのひとつです。
コマンドの導入手順
Linux環境でpingやtracerouteを利用するためには、必要なパッケージが正しくインストールされていることを確認する必要があります。
多くのディストリビューションでは標準で導入されていますが、環境によっては追加インストールが必要な場合があります。
ここではRHEL系Linuxを前提に導入方法と基本的な使い方を解説します。
パッケージのインストール方法
pingコマンドは通常「iputils」パッケージに含まれており、tracerouteは「traceroute」パッケージとして提供されています。
以下のコマンドで導入できます。
sudo dnf install -y iputils traceroute
インストールが完了したら、バージョン確認を行い、正しく導入されているかを確認します。
pingコマンドのバージョン確認:
ping -V
出力例:
ping from iputils s20221126
tracerouteコマンドのバージョン確認:
traceroute --version
出力例:
Modern traceroute for Linux, version 2.1.2
pingの基本的な使い方
pingコマンドはネットワーク診断の中でも最も多く利用されるツールです。対象ホストの疎通確認、応答速度の測定、パケットロスの有無などを簡単に調べることができます。ここでは代表的なオプションと具体的な使い方を解説します。
pingコマンドには複数のオプションがありますが、日常的な診断で利用されるものは限られています。以下は代表的なオプションと内容です。
| オプション | 内容 |
|---|---|
| -c 回数 | 指定した回数だけ送信して終了します。 |
| -i 秒 | 送信間隔を秒単位で指定します。 |
| -s サイズ | 送信するパケットサイズを指定します。 |
| -W 秒 | 応答の待ち時間を秒単位で指定します。 |
基本表示
最も単純な使い方は、対象のホスト名またはIPアドレスを指定するだけです。以下はwww.google.comに対してpingを実行した例です。
ping -c 4 www.google.com
出力例:
PING www.google.com (142.250.199.100) 56(84) bytes of data.
64 bytes from 142.250.199.100: icmp_seq=1 ttl=115 time=12.3 ms
64 bytes from 142.250.199.100: icmp_seq=2 ttl=115 time=12.1 ms
64 bytes from 142.250.199.100: icmp_seq=3 ttl=115 time=12.2 ms
64 bytes from 142.250.199.100: icmp_seq=4 ttl=115 time=12.4 ms
--- www.google.com ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 12.100/12.250/12.400/0.120 ms
この結果から、応答が正常に返っており、平均応答時間が約12msであることがわかります。
条件付き表示(対象指定)
pingでは対象をホスト名のほか、IPアドレスで直接指定することも可能です。また、送信回数を制御することで一時的な確認に利用できます。
ping -c 2 8.8.8.8
※ 8.8.8.8 は非常に信頼性の高いサーバーなので、疎通確認の対象としてよく使われます。
出力例:
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=15.4 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=15.3 ms
--- 8.8.8.8 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 15.300/15.350/15.400/0.050 ms
この結果から、Google Public DNSへの通信が正常であり、平均応答時間が15ms程度であることが確認できます。
詳細表示(拡張オプション)
より詳細に確認する場合は、送信間隔やパケットサイズを指定することで回線品質の評価に利用できます。
ping -c 5 -i 0.5 -s 1024 www.google.com
出力例:
PING www.google.com (142.250.199.100) 1024(1052) bytes of data.
64 bytes from 142.250.199.100: icmp_seq=1 ttl=115 time=13.1 ms
64 bytes from 142.250.199.100: icmp_seq=2 ttl=115 time=13.0 ms
64 bytes from 142.250.199.100: icmp_seq=3 ttl=115 time=13.2 ms
64 bytes from 142.250.199.100: icmp_seq=4 ttl=115 time=13.0 ms
64 bytes from 142.250.199.100: icmp_seq=5 ttl=115 time=13.1 ms
--- www.google.com ping statistics ---
5 packets transmitted, 5 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 13.000/13.080/13.200/0.080 ms
このように、パケットサイズを変更することで回線の処理能力や安定性を確認でき、送信間隔を調整することで短時間に負荷をかけたテストが可能となります。
tracerouteの基本的な使い方
tracerouteコマンドは、通信経路の確認や遅延の発生箇所を特定する際に非常に役立ちます。単純な疎通確認だけではわからない経路上の状態を把握できるため、ネットワークトラブルの切り分けに欠かせないツールです。
tracerouteにはさまざまなオプションがありますが、実際に利用する機会が多いのは以下のようなものです。
| オプション | 内容 |
|---|---|
| -m ホップ数 | 最大ホップ数(TTLの上限)を指定します。 |
| -w 秒数 | 応答を待つ秒数を指定します。 |
| -q 回数 | 各ホップごとに送信するパケット数を指定します。 |
| -I | ICMP Echoを使用して経路確認を行います。 |

基本表示
対象ホストを指定するだけで、目的地までの経路を順番に表示できます。以下はwww.google.comに対して実行した例です。
traceroute www.google.com
出力例:
traceroute to www.google.com (142.250.199.100), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 0.512 ms 0.498 ms 0.490 ms
2 10.20.30.1 (10.20.30.1) 2.341 ms 2.317 ms 2.305 ms
3 203.0.113.1 (203.0.113.1) 5.672 ms 5.641 ms 5.623 ms
4 142.250.199.100 (142.250.199.100) 12.301 ms 12.276 ms 12.259 ms
この結果から、通信がどのルーターを経由して目的地に届いているかを確認でき、遅延時間も把握できます。
条件付き表示(対象指定)
オプションを利用することで、経路表示の条件を変更できます。例えば、最大ホップ数を10に制限する場合は以下のように指定します。
traceroute -m 10 www.google.com
出力例:
traceroute to www.google.com (142.250.199.100), 10 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 0.610 ms 0.595 ms 0.580 ms
2 10.20.30.1 (10.20.30.1) 2.402 ms 2.376 ms 2.350 ms
3 203.0.113.1 (203.0.113.1) 5.721 ms 5.690 ms 5.663 ms
このようにホップ数を制御することで、経路の途中までを確認することが可能です。
詳細表示(拡張オプション)
より詳細に経路状況を調べたい場合は、ICMPを利用したモードや応答待ち時間の指定が有効です。
traceroute -I -w 3 -q 4 www.google.com
出力例:
traceroute to www.google.com (142.250.199.100), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 0.511 ms 0.497 ms 0.482 ms 0.470 ms
2 10.20.30.1 (10.20.30.1) 2.356 ms 2.340 ms 2.328 ms 2.315 ms
3 203.0.113.1 (203.0.113.1) 5.702 ms 5.672 ms 5.645 ms 5.619 ms
4 142.250.199.100 (142.250.199.100) 12.310 ms 12.284 ms 12.265 ms 12.250 ms
この結果から、各ホップごとに4回の応答が記録され、待ち時間を指定したことで安定したレスポンスが得られていることがわかります。これにより、経路の安定性や遅延の発生箇所をより詳細に把握できます。
応用・拡張利用
pingやtracerouteは単純な疎通確認にとどまらず、長期的な監視やログの蓄積といった応用的な使い方が可能です。ここでは日常的なネットワーク運用に役立つ拡張利用の方法を紹介します。
長期監視とcron利用
pingやtracerouteを定期的に実行し、結果を記録することでネットワークの安定性を継続的に監視できます。Linuxではcronを使って自動化するのが一般的です。
以下は毎分ごとに8.8.8.8への疎通を確認し、結果をログに記録する例です。
* * * * * /usr/bin/ping -c 1 8.8.8.8 >> /var/log/ping_test.log 2>&1
この設定により、応答の有無や遅延の増加を自動で記録でき、障害発生時の原因調査に役立ちます。

ログ管理と保存期間
監視結果を保存する場合、ログが無制限に増えるとディスクを圧迫する可能性があります。そのため、保存期間を決めて古いログを削除する仕組みを設けることが重要です。Linuxではlogrotateを利用して自動的に世代管理を行う方法がよく使われます。
以下はping監視ログを1週間ごとにローテーションし、4世代分を保持する設定例です。
/var/log/ping_test.log {
weekly
rotate 4
compress
missingok
notifempty
}
この設定により、ログファイルは自動で圧縮・整理され、無駄なディスク消費を防げます。

保存場所とディレクトリ構成
ログや監視結果を保存する際には、ディレクトリ構成を整理することで管理性が向上します。以下はシェルスクリプト運用を前提とした構成例です。
| ディレクトリ | 用途 |
|---|---|
| /scripts/bin | 実行用のスクリプトを配置します。 |
| /scripts/log | pingやtracerouteのログを保存します。 |
| /scripts/etc | 監視設定ファイルやcron設定を管理します。 |
| /scripts/tmp | 一時ファイルを保存します。 |
このように役割ごとに分けることで、スクリプトやログが散らばることなく一元管理でき、障害発生時の調査やメンテナンスが効率的になります。
実践的な活用例
ネットワーク障害やサーバートラブルが発生した際、pingやtracerouteの結果を正しく読み取ることで危険な兆候を素早く把握できます。ここでは現場で役立つ実践的な使い方と、結果から判断できるリスクの目安を解説します。
ネットワーク障害時の切り分け
障害時に最初に行うのは疎通確認です。以下のようにGoogle Public DNSへpingを打つことで、インターネット側が正常かどうかをすぐに確認できます。
ping -c 4 8.8.8.8
出力例:
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=15.4 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=15.3 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=118 time=15.5 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=118 time=15.4 ms
--- 8.8.8.8 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3005ms
rtt min/avg/max/mdev = 15.300/15.400/15.500/0.080 ms
疎通が安定していれば、インターネット側は問題ないと判断できます。
サーバー再起動時の復旧確認
サーバーを再起動した直後にpingを実行すると、応答が途絶えてから再び戻る瞬間を確認できます。これにより「サーバーがOSレベルで立ち上がったこと」を判断できます。
ping xxx.xxx.xxx.xxx
出力例(再起動直後):
PING xxx.xxx.xxx.xxx (xxx.xxx.xxx.xxx) 56(84) bytes of data.
Request timeout for icmp_seq 1
Request timeout for icmp_seq 2
Request timeout for icmp_seq 3
出力例(復旧後):
64 bytes from xxx.xxx.xxx.xxx: icmp_seq=4 ttl=64 time=0.432 ms
64 bytes from xxx.xxx.xxx.xxx: icmp_seq=5 ttl=64 time=0.410 ms
この応答が安定して返ってきた時点で「サーバーが無事に立ち上がった」と確認できます。管理者はここで次の確認(サービスやアプリケーションの稼働確認)に進みます。
pingの途中終了操作
pingコマンドは停止させない限り実行が続きます。途中で切り上げたい場合は、キーボードからCtrl + Cを押すことで終了できます。
ping xxx.xxx.xxx.xxx
出力例(Ctrl + Cで途中終了):
PING xxx.xxx.xxx.xxx (xxx.xxx.xxx.xxx) 56(84) bytes of data.
64 bytes from xxx.xxx.xxx.xxx: icmp_seq=1 ttl=64 time=0.412 ms
64 bytes from xxx.xxx.xxx.xxx: icmp_seq=2 ttl=64 time=0.418 ms
^C
--- xxx.xxx.xxx.xxx ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.412/0.415/0.418/0.003 ms
このように、Ctrl + Cで終了した時点までの送受信回数、パケットロス率、平均応答時間などが統計として表示されます。
サーバー接続のトラブルシュート
特定のサーバーに接続できない場合、tracerouteで経路を調べると「ネットワークの問題なのか」「サーバー自体の問題なのか」を切り分けられます。これは障害対応において大きな意味があります。
traceroute www.example.com
出力例:
traceroute to www.example.com (203.0.113.10), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 0.512 ms 0.498 ms 0.490 ms
2 10.20.30.1 (10.20.30.1) 2.341 ms 2.317 ms 2.305 ms
3 203.0.113.1 (203.0.113.1) 5.672 ms 5.641 ms 5.623 ms
4 203.0.113.10 (203.0.113.10) 12.301 ms 12.276 ms 12.259 ms
このように目的のサーバーまで経路が正しく通っているにもかかわらず接続できない場合、ネットワークや経路には問題がなく、サーバーのアプリケーションやサービスが停止している可能性が高いと判断できます。

他ツールとの組み合わせ
pingやtracerouteだけでは障害の全容を掴めない場合もあります。他のツールと組み合わせることで、危険な兆候をより確実に見抜けます。
| ツール | 確認できる危険な兆候 |
|---|---|
| netstat / ss | サーバー側でポートがリッスンしていない場合、アプリケーション障害が疑われます。 |
| tcpdump | パケットが届いていない場合、途中経路でのフィルタリングやファイアウォール設定が原因の可能性があります。 |
| sar / vmstat | サーバーが高負荷で応答できない状態かを確認できます。 |
このように、単に「疎通できるかどうか」ではなく「遅延やパケットロスの兆候」「経路遮断の有無」を確認することで、障害の前兆を見逃さずに対応できます。
利用時の注意点
pingやtracerouteは便利な診断ツールですが、利用方法を誤るとシステムに負荷をかけたり、運用に支障をきたすことがあります。
ここでは利用時に注意すべきポイントを解説します。
ping利用時の注意点
pingは疎通確認に役立ちますが、出力の解釈を誤ると誤診につながります。
ping -c 4 8.8.8.8
出力例:
PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.
64 bytes from 8.8.8.8: icmp_seq=1 ttl=118 time=15.4 ms
64 bytes from 8.8.8.8: icmp_seq=2 ttl=118 time=150.3 ms
64 bytes from 8.8.8.8: icmp_seq=3 ttl=118 time=14.9 ms
64 bytes from 8.8.8.8: icmp_seq=4 ttl=118 time=15.2 ms
ポイント
- 2回目だけ150msと大きな遅延が出ていますが、これは一時的な経路負荷であり障害とは限りません。数回の跳ね上がりで慌てて「回線障害だ」と判断するのは危険です。
- 応答がある=アプリケーションが動いている、ではありません。OSがICMPに応答しているだけで、WebやDBサービスは落ちている可能性もあります。
- 一方で、応答が途絶えたまま戻らない場合は「サーバー停止やネットワーク断」が濃厚な兆候となります。
traceroute利用時の注意点
tracerouteは経路調査に役立ちますが、こちらも出力の読み取りには落とし穴があります。
traceroute to www.example.com (203.0.113.10), 30 hops max, 60 byte packets
1 192.168.1.1 (192.168.1.1) 0.602 ms 0.590 ms 0.578 ms
2 10.20.30.1 (10.20.30.1) 2.451 ms 2.433 ms 2.421 ms
3 * * *
4 203.0.113.10 (203.0.113.10) 12.401 ms 12.387 ms 12.370 ms
tracerouteの注意点
- 「*」が出ても必ずしも経路断ではありません。ルーターがICMP応答を返さないだけのケースが多くあります。
- 各ホップの応答時間が跳ねても実アプリ通信には影響がない場合があります。ICMP応答の優先度が低いためです。
- 途中経路が全て「*」で表示されても、最終ホストに到達できれば通信は成立しています。
運用上の落とし穴
pingやtracerouteの結果だけで障害原因を断定してしまうのは危険です。例えば以下のようなケースがあります。
| 状況 | 誤った解釈 | 正しい見方 |
|---|---|---|
| 途中のホップで応答がない | 経路が遮断されている | ルーターがICMP応答を抑止しているだけで、実際には通信は通っている場合があります。 |
| 応答時間が一時的に上昇 | 常に遅延が発生している | ICMPより優先度の高い処理をしているだけで、実アプリケーション通信には影響がないこともあります。 |
| パケットロスが少量発生 | ネットワーク障害と判断 | 一時的な負荷や無視可能なロスであり、即座に障害とは限りません。 |
このように、pingやtracerouteは「参考指標」として利用し、必ず他の監視ツールやログと組み合わせて総合的に判断することが重要です。
まとめ
pingやtracerouteは、ネットワーク診断における基本でありながら、運用現場で最も利用頻度の高いコマンドです。単なる疎通確認にとどまらず、障害切り分け、サーバーリスタート時の復旧確認、経路上の遅延調査など、多くの場面で活躍します。
pingはサーバーが「無事に立ち上がったかどうか」を確認できる最初の手段であり、tracerouteは「どこで通信が滞っているのか」を突き止めるための有効なツールです。両者を適切に使い分ければ、障害対応のスピードと精度は大きく向上します。
一方で、ログの肥大化や過剰な実行による負荷、結果の誤解釈といった運用上の落とし穴も存在します。これらを回避するには、保存期間や実行間隔の調整、他の監視ツールとの併用が欠かせません。
日常的な監視からトラブルシュートまで、pingとtracerouteを正しく理解し活用することが、安定したシステム運用につながります。
次のおすすめ記事

実践環境を整える
ここまで学んだ知識を実際に試すには、Linuxを動かす環境が必要です。手軽に始めるならVPSを利用するのがおすすめです。
→ VPS徹底比較!ConoHa・さくら・Xserverの選び方

VPSを利用してLinux環境を準備したら、実際の設定は下記の記事が参考になります。
→ VPSに開発環境を自動構築する方法|Apache+Tomcat+PostgreSQL