

エンジニアなら誰もが経験するの下記の調査に時間を奪われるデバッグ地獄です。
- 「どこで処理が止まったのか分からない」
- 「ログが不揃いで追跡ができない」
第4回では、この問題を避けるために設計した 共通ログ出力クラス とそれを支える Logger / LogWriter / system.xml(log設定) の構成を整理します。
この共通DBアクセスクラス群では、SELECT・INSERT・UPDATE・DELETE の全処理で ログ出力が自動挿入される設計 を採用しています。開発者が毎回ログを書く必要はありません。
どの処理が実行され、どの段階で何が起きたのかを、統一形式で必ず記録できる 仕組みです。
今回の記事では、下記の “ログ運用の土台” を中心に解説します。
ログ運用の土台
- なぜこのログ構成にしたのか
- Logger と LogWriter の役割分担
- system.xml の設定値をどう読み込むか
- ログレベルに応じた出力制御の仕組み
ログが整っていれば、原因調査のスピードは一気に上がります。開発効率を底上げする共通ログ設計の基礎 を、この回でしっかり整理しましょう。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを利用しています。テストデータには、日本郵便が提供している全国一括の郵便番号CSV(15列構成)を使用し、住所情報を登録・検索・更新する処理を通じて、各クラスの動作を確認しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
共通DBアクセスクラス
🟣共通DBアクセスクラス
📌 SQL記述を最小化、業務ロジックに集中できる共通基盤
├─ORMにはうんざり!第1回:シンプルなJava DBアクセスクラスを考えてみた
├─ORMにはうんざり!第2回:共通DBアクセスクラスでSQLを直感的に操作するJava設計
├─ORMにはうんざり!第3回:JavaでDB接続の最適化と共通プールの構築
├─ORMにはうんざり!第4回:Java共通ログ出力とsystem.xml設定の構成を解説
├─ORMにはうんざり!第5回:例外の闇を断つ、堅牢なJavaエラーハンドリングとログ設計
└─ORMにはうんざり!第6回:Java共通DBアクセスクラスの実用例で脱フレームワーク
共通ログ出力クラスの構成と役割
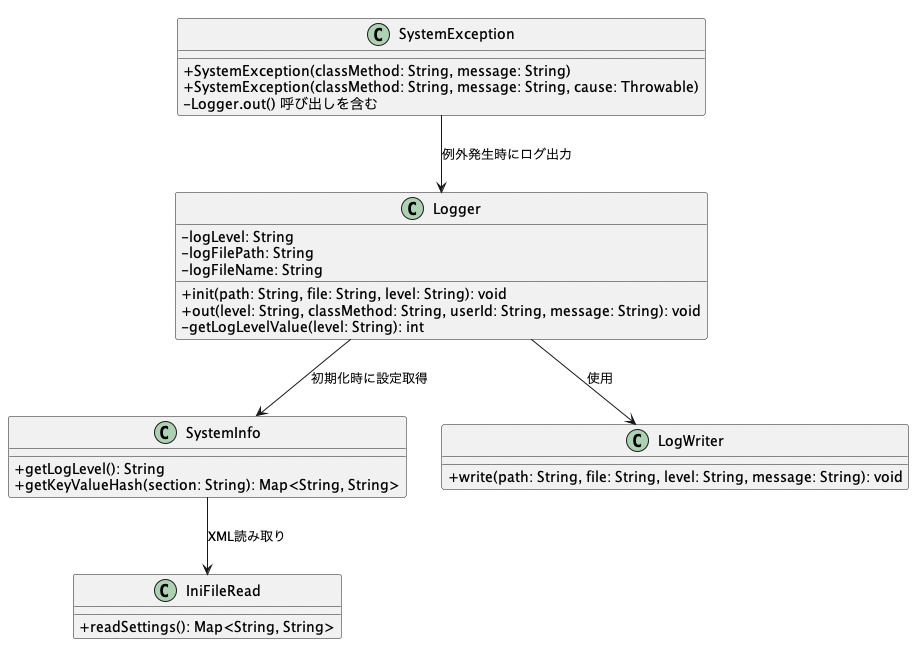
現場の調査で最も時間を奪うのが、ログの粒度不足や出力漏れによって処理の流れが見えなくなる状況です。どこで止まり、何が起きたのか分からないまま原因探しに追われるのは、開発者にとって大きなストレスになります。
こうした問題を避けるため、この共通DBアクセスクラス群では、すべての処理に対して統一されたログが必ず出力される仕組みを採用しています。LoggerとLogWriterが役割を分担することで、出力形式の統一とレベル制御を徹底し、調査効率を大幅に高められる構成になっています。
ログ出力は明示的に書かなくても自動的に挿入され、system.xmlでレベルや出力先を切り替えるだけで運用環境に応じた最適な記録が行われます。これにより、不要なログの氾濫を防ぎつつ、必要な情報は確実に残すことができます。調査速度と保守性を両立させたログ基盤が、今回のテーマです。
LoggerとLogWriterの機能分担
LoggerとLogWriterは、それぞれ異なる責務を持ちつつ密接に連携しています。Loggerクラスはアプリケーションが直接呼び出すログインターフェースを提供し、LogWriterクラスは実際のログファイル書き込み処理を担当します。
このように責務を分離することで、Loggerでは出力形式や制御ロジックに集中でき、LogWriterでは書き込み先やファイル出力処理に特化することができます。
下記にLoggerとLogWriterの役割の違いをまとめた表を示します。
| クラス名 | 役割 | 責任範囲 |
|---|---|---|
| Logger | ログ出力の呼び出し窓口 | ログレベルによる制御、呼び出し形式の統一 |
| LogWriter | ログファイルへの書き込み | ファイルI/O、フォーマット変換、ファイル出力 |
この構成により、Loggerはどの処理からも統一的に呼び出される中心的なインターフェースとして機能し、LogWriterはその下層でシステムの出力処理を担う安定的な基盤となります。
共通DBアクセスクラスのログ出力処理は、プロジェクト全体の保守性や運用効率に直結します。まだLoggerクラスの実装に不安がある方は、まずこちらの記事でシンプルな共通ログ出力クラスの考え方を確認しておくと理解が深まります。
▶︎ 【Javaの基礎知識】設定地獄はもう嫌!シンプルな共通ログ出力クラスを作ってみた

ログ出力の呼び出し方法と構造
ログ出力は、全ての共通データアクセスクラスにおいて自動で組み込まれるよう設計されています。基本的にはLoggerクラスのoutメソッドを呼び出すだけで、必要なログが出力されます。
呼び出し形式は以下のようになります。
Logger.out(Logger.INFO, "DbAccessSelect#execute()", "user0001", "SQL実行開始");
このように、ログ出力には以下の4つの情報を明示的に渡します。
| パラメータ | 内容 |
|---|---|
| ログレベル | INFO / DEBUG1 / DEBUG2 / DEBUG3 / WARN / ERROR などの出力種別 |
| 発生場所 | クラス名#メソッド名(呼び出し元の明示) |
| ユーザー名 | 処理を実行したユーザーID(空白も可) |
| 出力メッセージ | 任意の文字列。処理状況の説明やデバッグ用 |
この4項目により、ログは「何時」、「何処で」、「誰が」、「何を」、「行った」のかを一貫して記録することができます。また、ログ出力の場所を意識しなくても、doSelectやdoExecなどの共通関数の中でログが自動的に挿入されるよう設計されており、出力忘れを防ぐ仕組みになっています。
ログレベルと出力制御の仕組み
ログ出力の制御は、system.xmlに設定されたログレベル情報をもとに、Loggerクラスがフィルタリングを行う設計になっています。ログレベルは以下のような段階で分類されています。
| ログレベル | 用途 |
|---|---|
| ERROR | 致命的な例外や予期しない終了 |
| WARN | 軽微な異常やリカバリ可能な状況 |
| INFO | 通常の業務処理の進捗 |
| DEBUG1 | 処理開始・完了など、ステップ単位の進行記録 |
| DEBUG2 | 詳細なSQL構文やパラメータの出力(任意) |
| DEBUG3 | 個別レコード内容や繰り返し処理の内容(任意) |
例えば、system.xmlにてログレベルが「INFO」に設定されている場合、DEBUG2やDEBUG3のログは出力されません。これにより、本番環境ではINFO以上、開発・検証環境ではDEBUG3まで出力するという切り分けが可能となっています。
この仕組みはLogger.init()メソッドの初期化時に自動的に読み込まれます。実装上は以下のように初期化されます。
Logger.init(logFilePath, logFileName, logLevel);
また、LogWriterはログレベルごとに別ファイル出力を行うように設計することも可能で、将来的なログ分割運用にも柔軟に対応できます。
ログ出力設定とsystem.xmlの連携構成
共通DBアクセスクラス群では、ログ出力に関する設定を外部ファイルであるsystem.xmlに集約することで、実行環境ごとのログレベル切り替えや出力先の変更を容易にしています。
この仕組みにより、ソースコードを一切修正せずにログ運用方針を変更できる柔軟性が生まれ、保守性の高い設計となっています。
本章では、system.xmlの構造からLoggerクラスとの連携、実際のログ出力レベルに応じた制御方法までを具体的に解説します。
system.xmlのlogセクション構造
system.xmlファイルは、アプリケーション全体の動作パラメータを一元管理する設定ファイルです。この中でもlogセクションはログ出力に関する重要な設定を保持しており、主に以下のような構成で記述されています。
<database>
<password>postgres</password>
<url>P@ssW0rd</url>
<connect>20</connect>
<driver>jdbc:postgresql://localhost:5432/postgres</driver>
<object_id>CTID</object_id>
</database>
<log>
<filepath>/Users/bepro/Work/Java/logs</filepath>
<logfile>application.log</logfile>
<level>INFO</level>
</log>
各タグが持つ意味は以下の通りです。
| カテゴリ | タグ名 | 設定項目 | 説明 |
|---|---|---|---|
| ログ | filepath | ログ出力先ディレクトリ | ログファイルが保存されるディレクトリパス |
| logfile | ログファイル名 | 実際に出力されるログファイルの名前 | |
| level | ログレベル | 出力対象とするログレベルのしきい値(DEBUG3〜ERROR) |
このように、ログ出力に関わる項目は全てsystem.xmlに記述され、コード側では読み取り処理のみを行う設計となっています。これにより、本番環境と開発環境で出力内容を簡単に切り替えることが可能になります。
Loggerの初期化とSystemInfoの関係
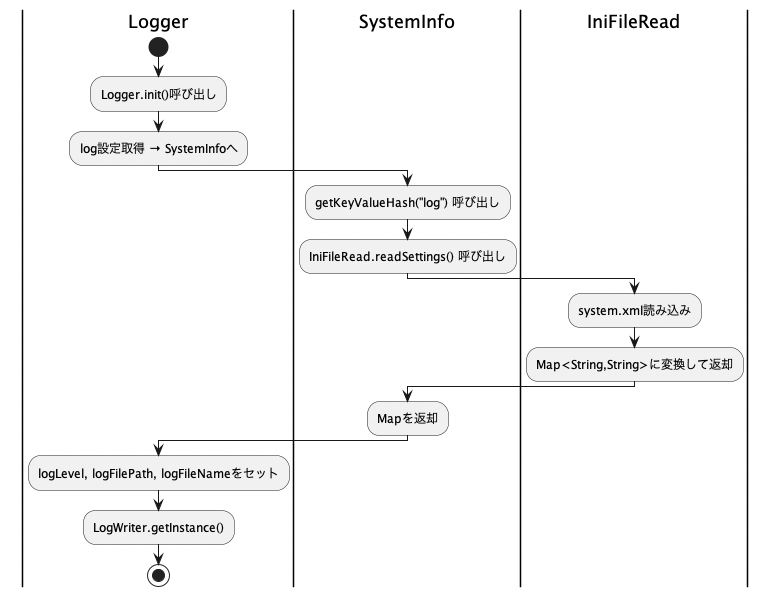
Loggerクラスは、アプリケーション開始時にsystem.xmlの設定値をもとに初期化処理を行います。その役割を担うのが、SystemInfoクラスを通じた設定取得処理です。
SystemInfoクラスは、system.xmlを読み込んでHashMap(旧構成ではHashtable)に変換し、設定値の取得インターフェースを提供する構成になっています。
以下のようなコードでログ設定値を取得します。
[ SystemInfo.java: getKeyValueHash(String section)]
// 指定セクションに該当する設定を抽出
Map<String, String> result = new HashMap<>();
for (String key : cachedSettings.keySet()) {
if (key.startsWith(section + "_")) {
String shortKey = key.substring(section.length() + 1);
result.put(shortKey, cachedSettings.get(key));
}
}
これにより、Loggerは下記のように初期化されます。
[ sample.java ]
public class Sample implements Constants, SqlConstants, FieldsConstants {
// 固定値の定義(false と 0 を明示的に扱うため)
private static final boolean W_FALSE = false;
public static void main(String[] args) {
(省略)
// ログの初期化
Logger.init(); 👈 ログの初期化
この初期化を行うことで、Loggerは以降の全てのログ出力に対して、適切なファイルとレベル設定を維持しながら書き込みを行うことが可能となります。これらの処理はアプリケーションの起動直後に一度だけ行われるため、ログ出力の安定性が確保されます。
【出力ログファイル例:】
例)/Users/bepro/Work/Java/logs/application_20250715.log
ログファイルは、指定されたディレクトリ内に「application_yyyymmdd.log」 の形式で出力されます。
日付部分(yyyymmdd)は、ログを生成した年月日が自動的に付与され、運用時のファイル管理や日別のログ確認を容易にします。
ログレベルに応じた出力分岐と運用パターン
ログレベルは、system.xmlの設定によって制御されるフィルターのような役割を果たします。Loggerクラスは、ログ出力時に設定されたログレベルと出力リクエストのログレベルを比較し、出力対象とするかどうかを判断します。
たとえば、system.xmlでログレベルが「INFO」に設定されている場合、DEBUG2やDEBUG3のログは出力されません。これにより、本番環境では重要なログだけを記録し、開発環境では詳細なトレースが取得できるといった使い分けが実現できます。
ログ出力の制御処理は以下のように記述されています。
private static boolean shouldLog(String level) {
int current = getLogRank(level);
int threshold = getLogRank(logLevel);
return current <= threshold;
}
ここで、shouldLogはログレベルの優先度を判定する関数であり、ログ出力の対象かどうかを論理的に判定します。
この仕組みにより、アプリケーション全体で一貫したログ制御が可能となり、コード上での細かな出力分岐を意識する必要がなくなります。 また、system.xmlを再読み込みすれば、アプリケーションを停止せずにログレベルを変更する仕組みも実装可能です。
これにより、障害発生時のみ一時的にログレベルを下げて詳細出力を取得するなど、柔軟な運用が可能になります。 運用例を以下に示します。
| 環境 | 推奨ログレベル | 主な出力対象 |
|---|---|---|
| 本番環境 | INFO | 業務処理の進捗や異常のみ |
| ステージング環境 | DEBUG1 | 処理ステップの進行ログ(開始・完了など) |
| 検証環境 | DEBUG2 | SQLログやパラメータ確認 |
| 開発環境 | DEBUG3 | レコード単位のデバッグ出力 |
このような運用パターンを事前に整理しておくことで、ログ出力の目的を明確にし、不要なファイル肥大化や情報漏洩のリスクを回避できます。
【 出力例: 】
[2025-11-15 12:01:44] [DEBUG3] DbAccessController#doExec().sys: executeInsert :INSERT INTO user_mst (password,update_user,company_id,user_id,user_name,e_mail,update_dt,create_dt,del_flg,remark,create_user) VALUES( ?,?,?,?,?,?,?,?,?,?,? )
[2025-11-15 12:01:44] [DEBUG3] DbAccessInsert#execute().sys: 変更フラグ配列の件数: 1
[2025-11-15 12:01:44] [DEBUG3] DbAccessInsert#execute().sys: 登録フラグの値 : 0 : true
(省略)
[2025-11-15 12:01:44] [DEBUG3] DbAccessInsert#execute().sys: 1件 Inserted !
[2025-11-15 12:01:44] [DEBUG3] DbAccessController#doExec().sys: ENDED
まとめ
今回の共通ログ出力設計では、LoggerとLogWriterの役割を明確に分離することで、システム全体のトレース性と保守性を大幅に高められる構成になっています。
ログ出力が統一されることで、デバッグ時に情報が点在せず、処理の流れを一連のストーリーとして読み取れるようになります。これは業務システムのように複数の処理が連鎖する環境では特に効果的で、原因追跡にかかる時間を確実に短縮できます。
system.xmlに設定値を集約したことで、ログレベルや出力先を環境ごとに柔軟に調整できるようになり、運用の自由度も広がります。
開発環境では詳細ログを出し、ステージングでは絞り、本番では必要最小限にするという切り替えが、コードの修正なしで行える点は大きなメリットです。アプリケーションが成長してもログ運用の負担が増えないため、長期的な運用にも向いた構造といえます。
今回の仕組みを導入することで、ログの出力忘れやレベル設定のばらつきといった人為的なミスを防ぎ、出力されたログから確実に状況を判断できる基盤が整います。
これにより、開発者が本来注力すべき業務ロジックに集中できるようになり、チーム全体の生産性向上にもつながります。共通ログ基盤をしっかり整えることが、結果としてシステム品質の底上げにつながることを実感していただけるはずです。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / log ディレクトリ
次の第5回では、例外処理とログ設計に焦点を当て、障害対応に強いシステムを支えるエラーハンドリングの仕組みを解説します。SystemExceptionとLoggerを連携させることで、トラブルの早期発見・迅速な原因特定を可能にし、開発現場の実用性を高める設計思想を掘り下げます。ログや例外処理に不安を抱える方はぜひご覧ください。
▶︎ORMにはうんざり!第5回:例外の闇を断つ、堅牢なJavaエラーハンドリングとログ設計





