

エンジニアとしてJavaでのデータベース連携を行う中で、「設定が多すぎる」「構造が複雑すぎる」といったORM(Object-Relational Mapping)への不満を感じたことはありませんか?
実際、HibernateやJPAのようなライブラリは便利である一方、ちょっとしたDB操作にも大量のアノテーションや設定ファイルが必要になるケースが多く、プロジェクトが肥大化する原因にもなりかねません。
そこで私たちは、あえてORMを使わず、SQLを直接制御できる共通DBアクセスクラス群を独自に設計しました。目的はただ一つ、シンプルに、確実に、そして再利用性の高い仕組みを作ることです。
本記事では、その中でも中核となる「DbAccessController」クラスに焦点を当てます。このクラスは、SQLの実行処理(SELECT、UPDATEなど)を統一的な形で扱えるように設計されており、煩雑な設定やフレームワークに縛られることなく、Javaらしい明快なコードでデータベース操作を可能にします。
これから紹介する実装と設計の工夫が、あなたの開発を軽くし、プロジェクトの保守性を大きく向上させる助けになれば幸いです。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを想定しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
なお、本記事で紹介している共通DBアクセスクラス群は、エラー処理や操作ログの記録において、共通ログ出力クラス(Logger)との連携を前提としています。SQLの実行結果や例外情報はすべてLogger経由で出力され、運用時のトラブルシュートや監視にも対応できる構成です。
まだLoggerクラスを導入していない場合は、以下の記事を先に参照してください。ログ出力に特化したシンプルな共通クラスを構築する方法を紹介しています。
▶︎【Javaの基礎知識】設定地獄はもう嫌!シンプルな共通ログ出力クラスを作ってみた

共通DBアクセスクラス
🟣共通DBアクセスクラス
📌 SQL記述を最小化、業務ロジックに集中できる共通基盤
├─ORMにはうんざり!第1回:シンプルなJava DBアクセスクラスを考えてみた
├─ORMにはうんざり!第2回:共通DBアクセスクラスでSQLを直感的に操作するJava設計
├─ORMにはうんざり!第3回:JavaでDB接続の最適化と共通プールの構築
├─ORMにはうんざり!第4回:Java共通ログ出力とsystem.xml設定の構成を解説
├─ORMにはうんざり!第5回:例外の闇を断つ、堅牢なJavaエラーハンドリングとログ設計
└─ORMにはうんざり!第6回:Java共通DBアクセスクラスの実用例で脱フレームワーク
DbAccessControllerクラスの概要と構成
共通DBアクセスクラス群の中核を担うのがDbAccessControllerクラスです。このクラスはSQL操作の統一的なインターフェースを提供し、SQLの実行種別ごとに適切な処理クラスを自動的に呼び出す役割を果たします。
実装上は、SQL定義やデータエンティティと密接に連携し、アプリケーションコードをシンプルに保ちつつ、実行パフォーマンスを維持できるよう設計されています。
クラス全体の役割と配置パッケージ
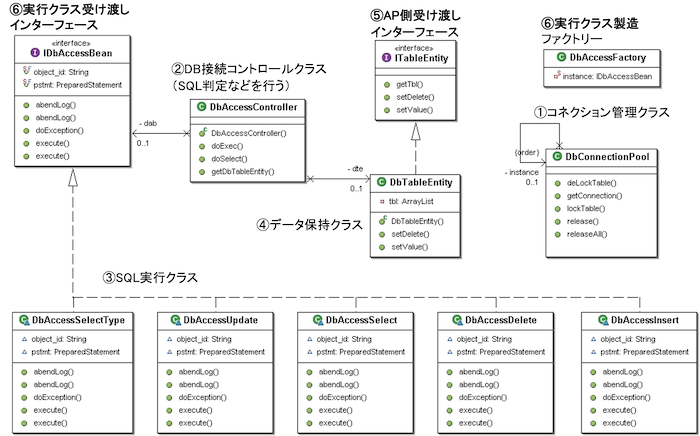
DbAccessControllerクラスは、開発プロジェクト内でデータアクセス機能を統括する役割を持ちます。クライアントコードはSQLの種類(SELECT、INSERT、UPDATE、DELETE)にかかわらず、同一のインターフェースを通じてSQL操作を実行することができます。パッケージ構成は以下の通りです。
| 要素 | パス |
|---|---|
| クラス名 | DbAccessController |
| パッケージ | com.beengineer.common.db |
| 関連ファイル | DbAccessFactory, DbAccessSelect, DbAccessInsert など |
ソース全体はこちら
👉 GitHub – db-access-core / data ディレクトリ
主なフィールドと初期化処理
DbAccessControllerクラスでは、SQL定義のキー(sqlId)とエンティティ情報を受け取り、ファクトリクラスを通じて内部的に適切なDbAccessインスタンスを取得します。
内部には、実行種別に応じたマッピングロジックが実装されており、doSelectやdoExecの呼び出し時に適切な処理クラスへ制御を移す構造です。
public static List<?> doSelect(String sqlId, ITableEntity entity) throws SystemException {
return DbAccessFactory.getDbAccess(DbAccessSelectType.SELECT).doSelect(sqlId, entity);
}
このように、呼び出しは一行で済みますが、裏側ではSQL種別の判定からSQL定義の取得、PreparedStatementの組み立てまでが行われています。
使用される補助クラスと依存関係
DbAccessControllerが機能するためには、複数の補助クラスが連携しています。
代表的なものにはDbAccessFactory(実行種別による処理クラスの分岐)、DbTableEntity(SQLにバインドする値情報の保持)、SystemInfo(共通設定取得)があります。
これらのクラスは、単一責任の原則に従ってそれぞれ独立した役割を担いながら、DbAccessController内で統合され、シームレスな処理を実現しています。
| クラス名 | 主な役割 |
|---|---|
| DbAccessFactory | SQL種別に応じたアクセスクラスの生成 |
| DbTableEntity | SQLバインド対象データの保持と提供 |
| SystemInfo | ログ設定やDB接続設定の取得 |
このように、DbAccessControllerは単体で完結する構造ではなく、各コンポーネントと役割分担を行いながら機能する共通クラス群のハブとして機能しています。
DbAccessFactoryによる実行クラスの動的切り替え
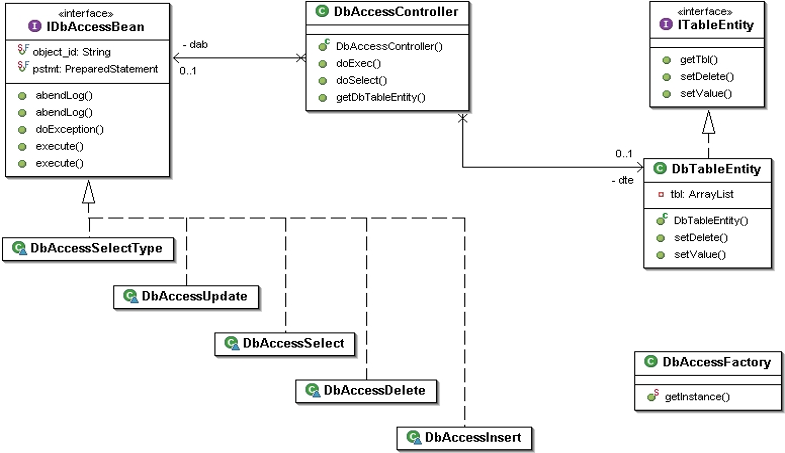
このセクションでは、DbAccessController#doExec() から各実行クラス(Select/Insert/Update/Delete)へ処理を振り分ける「DbAccessFactory」の動作を解説します。このFactoryクラスの役割は、SQLの実行種別(DbAccessSelectType)に応じて適切なクラスインスタンスを生成し、共通的なインターフェースで処理を委譲できるようにすることです。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
doExec内で実行対象が切り替わる仕組み
DbAccessControllerのdoExecメソッドでは、受け取った DbAccessSelectType に応じて、DbAccessFactoryを利用して実行クラスを切り替えています。実行対象がSELECT/INSERT/UPDATE/DELETEのいずれかであるかにより、処理経路が決まります。
IDbAccessBean access = DbAccessFactory.getInstance(type);
return access.doExec(sqlId, entity);
この1行のコードで、型に応じたクラスがインスタンス化され、インターフェースを通して共通処理が実行されます。
SELECT/INSERT/UPDATE/DELETEの種別に応じた分岐処理
DbAccessFactory#getInstanceメソッドでは、渡されたEnum値(DbAccessSelectType)に基づいて、対応するクラスを生成するswitch文が実装されています。以下はその一部の例です。
public static IDbAccessBean getInstance(DbAccessSelectType type) throws SystemException {
switch (type) {
case SELECT:
return new DbAccessSelect();
case INSERT:
return new DbAccessInsert();
case UPDATE:
return new DbAccessUpdate();
case DELETE:
return new DbAccessDelete();
default:
throw new SystemException("未定義のタイプが指定されました");
}
}
この構造により、どの処理種別であっても、呼び出し元は常に IDbAccessBean 型で処理でき、コードの再利用性が高まります。
DbAccessFactoryの内部構造とメリット
DbAccessFactoryの本質的な目的は「処理種別ごとのif文を呼び出し元に書かせない」ことです。処理クラスの選定はFactoryに任せ、呼び出し側は getInstance() だけを呼び出せばよいため、以下のメリットがあります。
- 処理分岐が一元化されて保守性が向上する
- 新しい処理クラスを追加する際もFactoryに追加するだけで済む
- 呼び出し元が処理クラスの内部を意識しなくてよい
この設計は、共通DBアクセスクラス全体において非常に重要な役割を担っており、「どのようにdoExecがInsertやUpdateにルーティングされるか」を理解する上で欠かせないポイントです。
使用するユーザー関連テーブルの定義
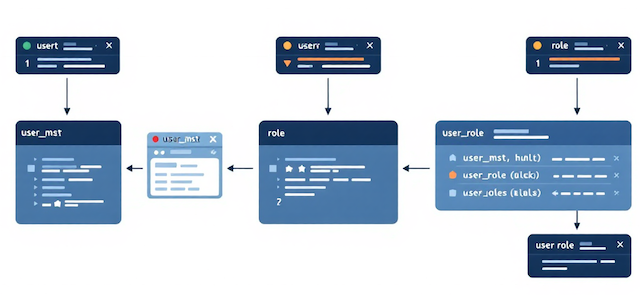
実際にプログラムを実行する上でDbAccessControllerクラスの説明に進む前に、操作対象となるユーザー関連テーブルの構造をはっきりさせておきます。
先に「どんなテーブルをどんな目的で触るのか」が見えていると、後から出てくる doSelect や doExec の処理フローを読み解きやすくなりますし、自分の環境に合わせて置き換えるイメージもつかみやすくなります。
ここでは、ユーザー情報を管理する user_mst、企業情報を表す company_mst を前提に、権限を表す role とユーザーとロールを結びつける user_role の関係までを整理しておきます。
| テーブル名 | 論理名 | 用途 |
|---|---|---|
| user_mst | 社員マスタ | システムにログインするユーザー(社員)を管理するマスタ。所属企業、メールアドレス、パスワードなどの基本情報を保持する。 |
| role | 権限マスタ | システム内の権限種別を管理するマスタ。役割名と権限レベルを保持し、画面や機能のアクセス制御に利用する。 |
| user_role | ユーザー権限(中間) | ユーザーと権限を結びつける多対多の中間テーブル。1ユーザーに複数権限、1権限を複数ユーザーに割り当てるための対応表。 |
| company_mst | 企業マスタ | 取引先・所属企業などの企業情報を管理するマスタ。会社名、所在地、連絡先、業種、ランクなど企業属性を保持する。 |
user_mstテーブルの構造と役割
user_mstテーブルは、アプリケーションで扱う「ユーザーの基本情報」を一元管理するテーブルです。
ログイン時に参照するIDやパスワード、メールアドレスに加えて、どの企業に所属しているかを表すcompany_idもここで持たせます。
DbAccessControllerクラスからは、もっとも頻繁に参照するテーブルのひとつになるため、カラム構造を頭に入れておくとSQLの流れを追いやすくなります。
ユーザーにひも付く情報は増やそうと思えばいくらでも増やせますが、共通DBアクセスクラスの解説では「どのカラムが検索条件になりそうか」「どのカラムが更新対象になりそうか」が重要です。
user_id、user_name、company_id、e_mail、passwordといった基本項目を軸に、論理削除用のdel_flgや備考欄のremarkを加えることで、実運用に耐えられる最低限の構造にしています。
実際のテーブル定義は次のようになります。
[ create_user_mst.sql ]
-- Table: public.user_mst
-- DROP TABLE IF EXISTS public.user_mst;
CREATE TABLE IF NOT EXISTS public.user_mst
(
user_id character varying(32) COLLATE pg_catalog."default" NOT NULL,
user_name character varying(64) COLLATE pg_catalog."default" NOT NULL,
company_id character varying(32) COLLATE pg_catalog."default" NOT NULL,
e_mail character varying(256) COLLATE pg_catalog."default" NOT NULL,
password character varying(256) COLLATE pg_catalog."default" NOT NULL,
create_dt timestamp without time zone DEFAULT now(),
create_user character varying(32) COLLATE pg_catalog."default",
update_dt timestamp without time zone DEFAULT now(),
update_user character varying(32) COLLATE pg_catalog."default",
del_flg character(1) COLLATE pg_catalog."default" DEFAULT '0'::bpchar,
remark text COLLATE pg_catalog."default",
CONSTRAINT user_mst_pkey PRIMARY KEY (user_id)
)
TABLESPACE pg_default;
ALTER TABLE IF EXISTS public.user_mst
OWNER to postgres;
COMMENT ON TABLE public.user_mst
IS 'User master table';
COMMENT ON COLUMN public.user_mst.user_id
IS 'User ID';
COMMENT ON COLUMN public.user_mst.user_name
IS 'User Name';
COMMENT ON COLUMN public.user_mst.company_id
IS 'Company ID';
COMMENT ON COLUMN public.user_mst.e_mail
IS 'Email';
COMMENT ON COLUMN public.user_mst.password
IS 'password';
COMMENT ON COLUMN public.user_mst.create_dt
IS 'Create datetime';
COMMENT ON COLUMN public.user_mst.create_user
IS 'Create user';
COMMENT ON COLUMN public.user_mst.update_dt
IS 'Update datetime';
COMMENT ON COLUMN public.user_mst.update_user
IS 'Update user';
COMMENT ON COLUMN public.user_mst.del_flg
IS 'Delete flag';
COMMENT ON COLUMN public.user_mst.remark
IS 'Remark';
このテーブル定義を適用する際、psqlからSQLファイルを流し込む運用を想定すると、実行コマンドと出力は次のようになります。
psql -U postgres -d <<データベース名>> -f create_user_mst.sql
【出力例:】
DROP TABLE
CREATE TABLE
ALTER TABLE
COMMENT
COMMENT
COMMENT
COMMENT
COMMENT
COMMENT
COMMENT
この段階で、ユーザーの基本情報を格納する入り口が準備できました。次のセクションで扱う権限テーブルと組み合わせることで、「どのユーザーが、どの企業に所属し、どの権限を持っているか」を一貫した構造で表現できるようになります。
company_mst/role/user_roleの関係図(簡易ER)
ユーザー情報だけでは、現実のアプリケーションで必要になる「企業」や「権限」の概念を表現しきれません。
特に業務システムでは、同じアプリケーションを複数の企業が共用するケースや、ユーザーごとに操作権限が細かく分かれているケースが当たり前のように存在します。
そこで、ユーザーの所属先を表すcompany_mst、権限の種類を表すrole、ユーザーとロールの多対多関係を表すuser_roleという構造を組み合わせて使います。
企業はあくまで「どこの組織に属しているか」を表す情報であり、「何ができるか」を決めるのはロールです。
企業情報を管理する company_mst テーブルも存在しますが、リレーションが複雑になるため本記事では扱わず、第二回では user_mst を中心に説明します。
まずは権限マスタとなるroleテーブルです。
CREATE TABLE role (
role_id VARCHAR(32) PRIMARY KEY,
role_name VARCHAR(100) NOT NULL UNIQUE,
role_level INTEGER NOT NULL,
description TEXT
);
続いて、ユーザーとロールを結びつける中間テーブルuser_roleを定義します。ここでは、同じユーザーが同じロールを二重に持つことがないよう、user_idとrole_idの組み合わせを主キーにしています。
CREATE TABLE user_role (
user_id VARCHAR(32) NOT NULL,
role_id VARCHAR(32) NOT NULL,
PRIMARY KEY (user_id, role_id),
FOREIGN KEY (user_id) REFERENCES user_mst(user_id),
FOREIGN KEY (role_id) REFERENCES role(role_id)
);
roleとuser_roleの定義も、user_mstと同じようにpsqlから実行することができます。次の例では、2つのSQLファイルを順番に適用したときの様子を示しています。
psql -U postgres -d <<データベース名>> -f create_role.sql
psql -U postgres -d <<データベース名>> -f create_user_role.sql
【出力例:】
CREATE TABLE
CREATE TABLE
この三つ組を頭の中で簡易ER図としてイメージすると、構造は次のようになります。
ポイント
- company_mst … 企業を表すマスタ(company_idが主キー)
- user_mst … ユーザーを表すマスタ(company_idでどの企業に属するかを表現)
- role … 権限の種類を表すマスタ
- user_role … user_mstとroleの多対多を管理する中間テーブル
この関係が見えているだけで、後ほど登場する doSelect で「特定企業に所属し、かつ管理者ロールを持つユーザー一覧を取得する」といったクエリを組み立てるときに、頭の中で迷子にならずに済みます。
実行サンプルで使用するフィールド一覧
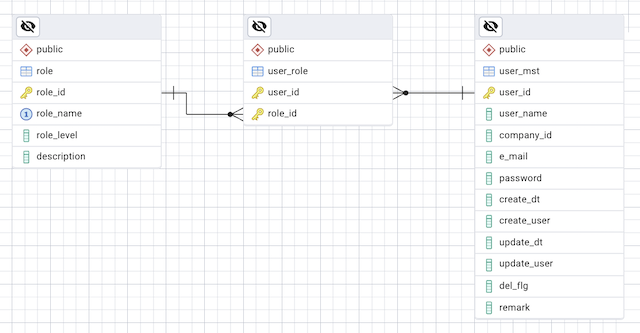
ここまでで、user_mst、role、user_roleの定義を用意しましたが、第2回以降のコード例では、この中のすべてを一度に使うわけではありません。
読者がSQLやDbAccessControllerのコードを読むときに混乱しないよう、実際のサンプルでよく登場するフィールドだけを一度整理しておきます。
ここでは、後続のセクションで登場する代表的なフィールドを表にまとめます。
| テーブル名 | フィールド名 | 役割 |
|---|---|---|
| user_mst | user_id | ユーザーを一意に識別するIDです。検索やJOINの軸になります。 |
| user_name | 画面に表示するユーザー名です。検索やソートで利用します。 | |
| company_id | 所属企業を表します。company_mstと結合して企業単位の絞り込みを行います。 | |
| e_mail | ログイン通知やパスワードリセットで利用するメールアドレスです。 | |
| role | role_name | 管理者・一般などの権限名称を表します。 |
| role_level | 権限の強さを数値で示します。大きいほど強い権限といった運用が可能です。 | |
| user_role | user_id / role_id | どのユーザーにどのロールが割り当てられているかを定義する中間テーブルです。 |
この一覧を頭に置いた状態で、次のH2で解説する「SQL操作の基本:doSelect/doExecの流れ」を読むと、DbAccessControllerが「どのテーブルのどのフィールドを、どのような条件で操作しているのか」が立体的にイメージできるようになります。
単なるサンプルコードではなく、自分の案件のユーザーテーブルや権限テーブルに置き換えたときの姿も想像しやすくなるため、学習時間の短縮と実装への直結を両方狙える構成になります。
実行例と出力結果の確認
以下に、第一回記事で使用したサンプルコードを上記の使用に合わせて修正します。 ユーザー情報を持つテーブルにデータを登録し、その後SELECTで当該データを取得してコンソールに出力する流れです。
[ sample1.java ]
package com.sample;
import java.sql.Connection;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.beengineer.common.Constants;
import com.beengineer.common.FieldsConstants;
import com.beengineer.common.SqlConstants;
import com.beengineer.common.data.DbAccessController;
import com.beengineer.common.data.DbConnectionPool;
import com.beengineer.common.data.DbTableEntity;
import com.beengineer.common.log.Logger;
public class Sample1 implements Constants, SqlConstants, FieldsConstants {
// 固定値の定義(false と 0 を明示的に扱うため)
private static final boolean W_FALSE = false;
private static final int N_Zero = 0;
// 操作対象となるテーブル名(DbAccessControllerへ渡すキー)
private static final String USER_TBL = "user_mst";
public static void main(String[] args) {
// SELECT結果が1件以上かどうかのフラグ
boolean bResult = W_FALSE;
// user_mst を操作する DbAccessController を生成
DbAccessController dac = new DbAccessController(USER_TBL);
// コネクションプールの取得
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = null;
// ログの初期化
Logger.init();
try {
// DBコネクション取得
con = pool.getConnection();
// 自動コミット OFF(INSERT/UPDATE を明示的に commit/rollback したい)
con.setAutoCommit(W_FALSE);
// ① INSERT に使用するパラメータを準備
Map<String, String> params = new HashMap<>();
params.put("user_id", "test001");
params.put("user_name", "山田太郎");
params.put("company_id", "0000000001");
params.put("e_mail", "test@example.co.jp");
params.put("password", "P@ssW0rd");
// INSERT 対象の値を保持する Entity(DbTableEntity)
DbTableEntity ite = dac.getDbTableEntity();
// ite.resetAllFlg(); // 必要に応じて更新フラグを初期化
// ② INSERT する値を Entity へ設定
ite.setValue("user_id", params.get("user_id"), N_Zero);
ite.setValue("user_name", params.get("user_name"), N_Zero);
ite.setValue("company_id", params.get("company_id"), N_Zero);
ite.setValue("e_mail", params.get("e_mail"), N_Zero);
ite.setValue("password", params.get("password"), N_Zero);
// ③ SQL 実行(INSERT)
int iResult = dac.doExec(con, USER_TBL);
// ④ INSERT結果に応じて commit / rollback
if (iResult > N_Zero) {
con.commit();
System.out.println("INSERT結果: " + iResult);
} else {
con.rollback();
System.out.println("INSERT失敗");
}
// ----------------------------------------------------------
// ⑤ SELECT 文の構築(SQL_USER_SELECT_BY_ID を使用)
// ----------------------------------------------------------
String strSQL_USER_SELECT_BY_ID = EMPTY;
strSQL_USER_SELECT_BY_ID = SQL_USER_SELECT_BY_ID;
strSQL_USER_SELECT_BY_ID += "'test001'"; // WHERE user_id='test001'
// ----------------------------------------------------------
// ⑥ SELECT 実行
// ----------------------------------------------------------
iResult = dac.doSelect(con, strSQL_USER_SELECT_BY_ID);
if (iResult >= 1) {
bResult = true;
}
// ----------------------------------------------------------
// ⑦ 結果の取得と表示
// ----------------------------------------------------------
if (bResult) {
// SELECT の結果は DbTableEntity の rows に格納されている
List<Map<String, Object>> rows = ite.getTbl();
for (Map<String, Object> row : rows) {
System.out.println(row); // キーと値の組み合わせを標準出力へ表示
}
} else {
System.out.println("データ取得に失敗しました。");
}
} catch (Exception e) {
// 例外発生時はログ出力+ロールバック
e.printStackTrace();
try {
if (con != null)
con.rollback();
} catch (Exception ignore) {
}
} finally {
// コネクションのクローズ
try {
if (con != null)
con.close();
} catch (Exception ignore) {
}
}
}
}
【出力例:】
{ctid=(0,11), update_user=, company_id=0000000001, user_id=test001, user_name=山田太郎, update_dt=2025-11-15 12:12:34.276, create_dt=2025-11-15 12:12:34.276, del_flg=, remark=, create_user=}
返されるMapはテーブル構造そのままの形式で格納されているため、画面への表示や後続処理へ自然につなげることができます。構造を理解しやすいSQLと、読みやすいEntity形式がそろうことで、アプリケーション全体の見通しがよくなります。
実用例:定数キーとSQL文のマッピング
アプリケーションが複雑になるほど、SQL文をどこに置くかで保守性が大きく変わります。ここでは、SQLをSqlConstantsへ集約して管理する方法を取り上げながら、実際のテーブル操作と結びつけて解説します。コードと実行結果がひとまとまりで理解できるため、開発後の手戻りを最小限に抑えられます。
SqlConstantsの設計方針
SQL文を散在させると、修正のたびに複数ファイルを追いかける必要が出てきます。SqlConstantsへまとめることで、ロジック部分とSQL部分が明確に切り離され、管理がしやすくなります。読者が迷わないように定数名は処理内容が推測できる命名に統一しています。
具体例として、IDでユーザーを検索するSQLを次のように定義しています。
static final String SQL_USER_SELECT_BY_ID = "SELECT " +
" ctid, " +
" user_id," +
" user_name," +
" company_id," +
" create_dt, " +
" create_user, " +
" update_dt, " +
" update_user, " +
" del_flg, " +
" remark " +
" FROM user_mst WHERE user_id= ";
この時点でSQLがどのカラムを返すのかが明確に分かるため、DbTableEntityで値を取り出す処理にも迷いが生まれません。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
SQL_USER_SELECT_BY_IDの構造と読み解き
この定数は、ユーザーIDに紐づくレコードを1件取得するための最小構成のSELECT文です。WHERE句の直後で値を足し込むことを前提に設計されているため、アプリ側で動的な条件を付与しやすい構造になっています。
実際に実行する時は、次のようにIDを連結してSQLを完成させます。
String sql = SQL_USER_SELECT_BY_ID + "'test001'";
その後、DbAccessControllerのdoSelectを呼び出して結果を取得します。
int result = dac.doSelect(con, SQL_USER_SELECT_BY_ID);
DbAccessController の内部処理フロー(doSelect / doExec)
DbAccessControllerクラスはSQLの種類に応じて複数の操作メソッドを持っており、主に検索を行うdoSelectメソッドと、INSERT・UPDATE・DELETEを実行するdoExecメソッドが中心になります。
これらを使うと、アプリ側はSQL文を直接書かずに、処理内容に応じてキーと値を渡すだけで操作が完結します。特にユーザー情報の取得や更新といった頻度の高い処理では、この構造が大きな効果を発揮します。
以降では、実際にどのような引数を渡し、どのような形で結果を受け取るのかを、具体的なコード例とともに順番に確認していきます。
DbAccessControllerクラスは、SQLの種類に応じて複数の操作メソッドを提供しています。その中でも、検索処理を担当するdoSelectと、更新系処理を担当するdoExec(およびdoInsert、doUpdate)は、内部でDbAccessFactoryと連携し、適切な処理クラスを自動選択する仕組みになっています。
このセクションでは、まず検索処理であるdoSelectを中心に、その流れと内部構造を詳しく解説します。
doSelectによる検索処理の基本構造
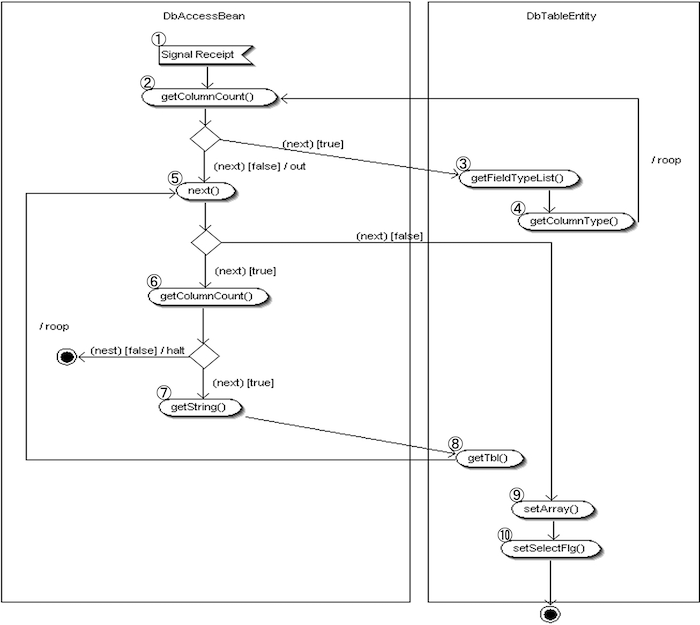
検索処理の流れ
- ① SQL要求の受信
DbAccessController が SQL 実行要求を受け取る。 - ② データ型取得ループ開始
ResultSetMetaData から項目データ型を取得。次件数あり→②継続、なし→⑤へ。 - ③ データ型格納配列の取得
次件数がある場合、DbTableEntity から型格納配列を取得。 - ④ データ型の格納
取得した型をラベル対応の配列へ格納。次件数あり→②へ戻る、なし→⑤へ。 - ⑤ 結果セット取得
結果行を取得。次件数あり→⑥へ、なし→⑨へ。 - ⑥ データ値取得ループ開始
ResultSetMetaData からデータ値を取得。次件数あり→⑦へ、なし→例外。 - ⑦ データ値の取得
1項目分のデータ値を取得する。 - ⑧ データ値の格納
取得データを DbTableEntity の値配列に格納。次件数あり→⑤へ戻る、なし→⑨へ。 - ⑨ テーブル結果配列へのセット
⑧で溜めた値配列を DbTableEntity の結果配列へ格納。 - ⑩ 検索済みフラグのセット
Insert 時のデータ型取得で使用するため、検索済みフラグをセット。
doSelectメソッドは、SQL定義キーとエンティティ情報を受け取り、内部でSELECT文を組み立てて実行する役割を持ちます。戻り値はList型で、実行結果の行データが格納されたオブジェクト群となります。
public static List<?> doSelect(String sqlId, ITableEntity entity) throws SystemException {
return DbAccessFactory.getDbAccess(DbAccessSelectType.SELECT).doSelect(sqlId, entity);
}
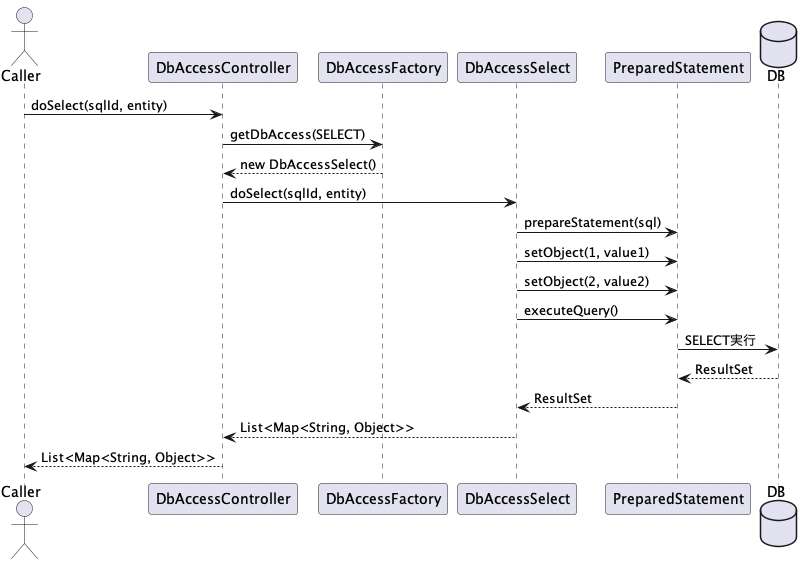
このように、実行対象のクラスはDbAccessFactoryを通じて取得され、実行種別であるDbAccessSelectType.SELECTが引数として渡されます。
DbAccessSelectType.SELECTの役割
DbAccessSelectTypeは、SQL実行種別を明示するための列挙型です。doSelectを実行する場合は、DbAccessSelectType.SELECTが使用され、これによりDbAccessFactoryがDbAccessSelectクラスのインスタンスを返すよう制御されます。
public enum DbAccessSelectType {
SELECT,
INSERT,
UPDATE,
DELETE
}
この仕組みにより、SQLの目的に応じた処理クラスが動的に選ばれ、同一のインターフェースで異なる処理を実行可能となります。
DbAccessFactoryを介したクラス分岐の流れ
DbAccessFactoryは、DbAccessSelectTypeの値に基づき、対応する実行クラス(DbAccessSelect、DbAccessInsert、DbAccessUpdate、DbAccessDelete)を返すファクトリクラスです。これにより、呼び出し元はSQL種別だけを意識すればよく、処理クラスの実装に依存しない構成が実現されています。
public static IDbAccessBean getDbAccess(DbAccessSelectType type) throws SystemException {
switch (type) {
case SELECT:
return new DbAccessSelect();
case INSERT:
return new DbAccessInsert();
case UPDATE:
return new DbAccessUpdate();
case DELETE:
return new DbAccessDelete();
}
throw new SystemException("Invalid type");
}
DbAccessSelect#doSelectの内部処理
DbAccessSelectクラスは、doSelectメソッドをオーバーライドし、SQL文の組み立てからPreparedStatementの生成、そしてResultSetの読み取りまでを担当します。SQLは定数から取得され、プレースホルダにはDbTableEntityで指定された値がバインドされます。
String sql = SqlConstants.SQL_USER_SELECT_BY_ID;
PreparedStatement pstmt = conn.prepareStatement(sql);
List<Object> bindValues = entity.getValues();
for (int i = 0; i < bindValues.size(); i++) {
pstmt.setObject(i + 1, bindValues.get(i));
}
ResultSet rs = pstmt.executeQuery();
このように、SQLの構文自体は事前に定義され、実行時には値のバインド処理と実行結果のオブジェクト化が行われます。
PreparedStatementによる検索の実行と戻り値
検索処理の実行結果は、ResultSetを順に読み取り、List形式で格納されます。エンティティクラスで定義されたカラム構成に従い、フィールドごとに値がマッピングされていきます。
while (rs.next()) {
Map<String, Object> row = new HashMap<>();
for (String col : entity.getFields()) {
row.put(col, rs.getObject(col));
}
resultList.add(row);
}
こうして取得されたリストは、呼び出し元に返却され、必要に応じて画面表示やロジック処理に利用されます。
doExecによるINSERT/UPDATE/DELETEの実行
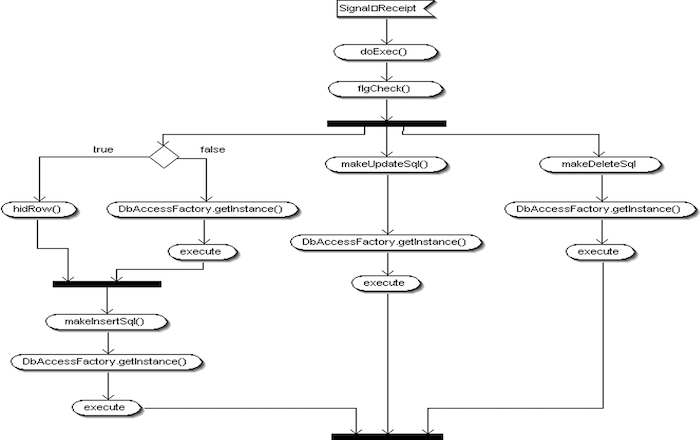
DbAccessControllerクラスでは、検索以外のSQL実行処理として、INSERT、UPDATE、DELETEに対応したdoExec系メソッドが用意されています。これらのメソッドはそれぞれ異なる目的を持ちつつも、内部構造としては共通化された実行処理により、効率的かつ保守性の高い構成となっています。
DbAccessController#doInsertの仕組み
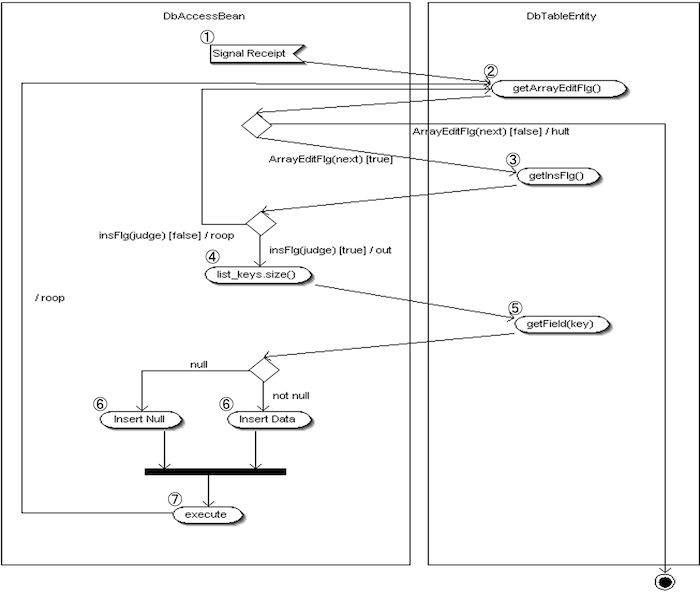
登録処理の流れ
- ① SQL要求の受信
DbAccessController が SQL 実行要求信号を受け取る。 - ② 変更フラグ配列のループ
変更フラグ配列を取得し、件数分ループ。次件数あり→③へ、なし→処理終了。
※この処理は DbAccessBean 内で実行される。 - ③ 登録判定
登録フラグ配列を取得し、現在インデックスの値を判定。"true" なら登録処理へ、"false" なら次ループへ。 - ④ 項目キー配列のループ
項目キー配列を取得し、件数分のループを開始する。 - ⑤ 登録対象データの取得
項目キーを使い登録対象データを取得。取得時に NullPointerException が発生した場合は、データを空文字に置き換える。 - ⑥ 値セット処理
⑤で空文字に置き換えられたデータには NULL をセット。それ以外は取得した値をセットする。 - ⑦ 登録実行
値を登録する。次件数あり→②へ戻る、なし→処理終了。
doInsertメソッドは、新規レコードの追加処理を担当します。実行対象のSQLは定数で指定され、エンティティに設定された値がプレースホルダにバインドされてSQLが発行されます。
public static int doInsert(String sqlId, ITableEntity entity) throws SystemException {
return DbAccessFactory.getDbAccess(DbAccessSelectType.INSERT).doExec(sqlId, entity);
}
このように、doInsertは内部でDbAccessFactoryを通じてDbAccessInsertクラスを取得し、そのdoExecメソッドを呼び出します。呼び出し元から見ると、SQLの実行種別を意識することなく、シンプルな呼び出し形式でINSERT処理を実現できます。
DbAccessController#doUpdateの仕組み
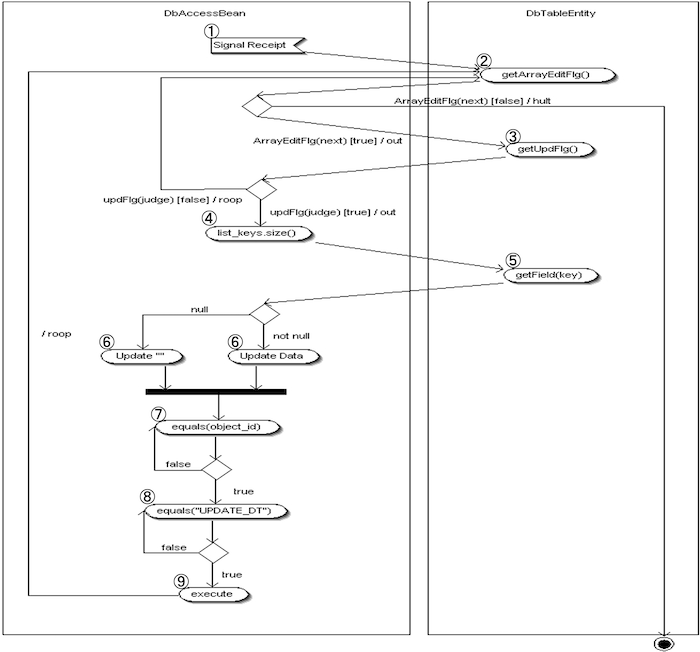
変更処理の流れ
- ① SQL要求の受信
DbTableController が SQL 実行要求信号を受け取る。 - ② 変更フラグ配列のループ
変更フラグ配列を取得し、件数分ループ。次件数あり→③へ、なし→処理終了。
※この処理は DbAccessBean 内で行われる。 - ③ 更新判定
更新フラグ配列から該当インデックスの値を取得。"true" なら更新処理へ、"false" なら次ループへ。 - ④ 項目キー配列のループ
項目キー配列を取得し、件数分ループ処理を開始する。 - ⑤ 更新対象データの取得
項目キーで変更対象データを取得。取得時点で NullPointerException が発生した場合は空文字に置き換える。 - ⑥ 値セット処理
⑤で空文字になったデータは NULL をセット。それ以外は取得した値をセットする。 - ⑦ 更新キー(Object_id)の取得
更新処理のキーとなる Object_id を取得する。Object_id 以外ならループを続行。 - ⑧ 排他チェック
更新対象データの値が、データ取得時の値と一致しているか確認。
一致 → ⑨へ進む。
不一致 → SystemException。 - ⑨ 更新処理
値を更新する。次件数あり→②へ戻る、なし→処理終了。
doUpdateメソッドは、既存レコードの更新処理を実行するためのインターフェースです。doInsertと同様に、SQLキーとエンティティ情報を受け取り、内部でDbAccessUpdateのdoExecを呼び出します。
public static int doUpdate(String sqlId, ITableEntity entity) throws SystemException {
return DbAccessFactory.getDbAccess(DbAccessSelectType.UPDATE).doExec(sqlId, entity);
}
この実装により、更新処理もINSERTと同様の構文で呼び出すことができ、呼び出し側のコードはSQLの種別に依存しない形となっています。
DbAccessController#doDeleteの仕組み
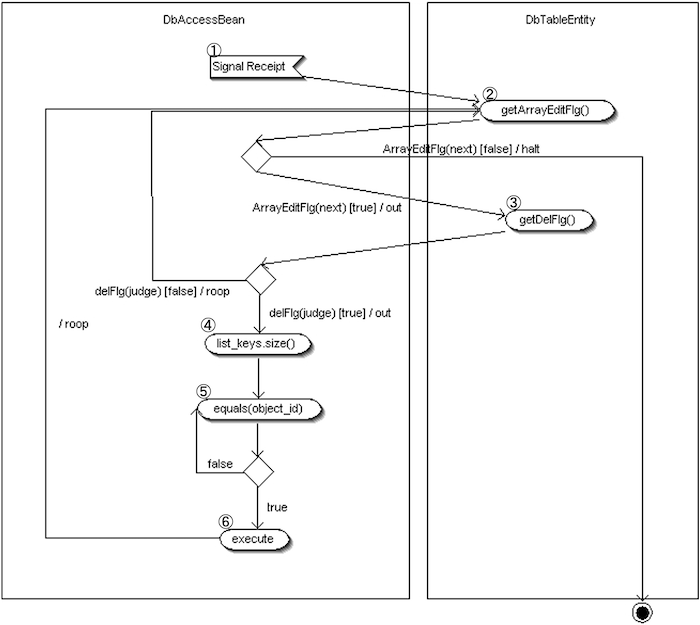
削除処理の流れ
- ① SQL要求の受信
DbAccessController が SQL 実行要求信号を受け取る。 - ② 変更フラグ配列のループ
変更フラグ配列を取得し、件数分ループ。次件数あり→③へ、なし→処理終了。
※この処理は DbAccessBean 内で行われる。 - ③ 削除判定
削除フラグ配列から該当インデックスを判定。"true" なら削除処理へ、"false" なら次ループへ。 - ④ 項目キー配列のループ
項目キー配列を取得し、件数分のループ処理を行う。 - ⑤ Object_id 判定
④の処理の中で Object_id を探索。
Object_id 以外であればループを継続。 - ⑥ 削除実行
⑤で選択された Object_id をパラメータにセットし、対象レコードの削除を行う。
次件数あり→②へ戻る、なし→処理終了。
DbAccessControllerクラスでは、DELETE処理もINSERTやUPDATEと同様に doExec() を内部的に呼び出す構成となっており、DbAccessDelete クラスに処理を委譲します。
呼び出し元からは doDelete(String sqlId, ITableEntity entity) を使用するだけで、共通インターフェースに従った削除処理が実行されるため、呼び出しコード側はSQL種別を意識せずに済みます。 doDeleteメソッドの主な処理は以下のとおりです。
public List<Map<String, Object>> doDelete(String sqlId, ITableEntity entity) throws SystemException {
return doExec(DbAccessSelectType.DELETE, sqlId, entity);
}
このように、doDeleteはDbAccessSelectType.DELETEを指定して doExec() を呼び出すだけのラッパーです。実際の削除処理は、DbAccessFactoryが DbAccessDelete クラスを選択し、そこに処理が委譲されます。
SQL文の取得、プレースホルダへのバインド、DELETE文の実行といった具体的な処理はDbAccessDelete#doExec内に記述されています。 この仕組みにより、SQLの種別が異なっても統一された流れで操作できるという、共通DBアクセスクラス群の設計思想が貫かれています。
読者が独自にINSERTやUPDATEと同じようなコードをDELETEにも適用できる点も、学習コストの削減に貢献します。
DbAccessSelectTypeによる実行種別の切り替え
DbAccessFactoryが返すアクセスクラスの切り替えには、DbAccessSelectTypeという列挙型が使用されています。この列挙型はSELECT、INSERT、UPDATE、DELETEという4つの種別を定義しており、それぞれの処理に応じて適切なクラスが選択される仕組みとなっています。
public enum DbAccessSelectType {
SELECT,
INSERT,
UPDATE,
DELETE
}
呼び出し時にこの列挙型の値を指定することで、DbAccessFactoryは該当するアクセスクラスをインスタンス化し、戻り値として提供します。
DbAccessInsert/Update/Delete#doExecの共通構造
INSERT、UPDATE、DELETEの各クラスは、共通インターフェースであるIDbAccessBeanを実装しており、それぞれにdoExecメソッドが定義されています。doExecは、SQLの取得、PreparedStatementの構築、バインド処理、実行処理の4ステップで構成されており、構造はほぼ共通です。
PreparedStatement pstmt = conn.prepareStatement(sql);
List<Object> values = entity.getValues();
for (int i = 0; i < values.size(); i++) {
pstmt.setObject(i + 1, values.get(i));
}
int result = pstmt.executeUpdate();
これにより、各SQL処理の実行ロジックが統一され、再利用性が高まると同時に、保守性も飛躍的に向上しています。
更新結果の戻り値とその意味
doExecメソッドの戻り値は、SQL文の実行結果としての影響行数を表す整数値です。これは、INSERTなら挿入された行数、UPDATEなら更新された行数、DELETEなら削除された行数を意味します。
int updatedRows = DbAccessController.doUpdate("SQL_USER_UPDATE", userEntity);
if (updatedRows == 0) {
// 更新対象が存在しなかった場合の処理
}
このように、実行結果を受け取ることで、アプリケーション側は更新の成否や影響範囲を柔軟に判定できるようになっています。
まとめ
今回の記事では、共通DBアクセスクラスの中核である DbAccessController の役割と内部処理の流れを整理しました。
SQL種別に応じた Factoryによる動的切り替え、そして doSelect / doExec の実装構造 を理解することで、DB操作を統一的に扱える仕組みの全体像がつかめたはずです。
ポイントは以下の3つです。
ポイント
- Controller が SQL 実行を一元化し、処理種別だけで適切な実行クラスが呼ばれること
- Entity(DbTableEntity)を通じて値と構造が整理され、SQLバインドが明確になること
- SELECT/INSERT/UPDATE/DELETE の流れが統一され、アプリ側の記述量を大幅に減らせること
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
次の第3回では、共通DBアクセスクラスを支える重要な土台である「DB接続の最適化」に焦点を当てます。複数の処理で接続を共通化しつつ、安定性とパフォーマンスを両立させるための接続プールの構築方法を解説しています。システム全体の信頼性を支えるインフラ層の設計に興味がある方は、ぜひご確認ください。
▶︎ORMにはうんざり!第3回:JavaでDB接続の最適化と共通プールの構築





