

多くのエンジニアが一度は通る道、それがORM(Object-Relational Mapping)によるデータアクセスの自動化です。しかし、実際の開発現場では「ブラックボックス化してわかりにくい」「SQLが思うようにチューニングできない」「結局、素のJDBCに戻した」などの声が後を絶ちません。
本記事では、そうしたORMに限界を感じたエンジニアに向けて、フレームワークに依存しない共通DBアクセスクラス群の“実用的な使い方”をご紹介します。
第6回となる今回は、MVCモデルをベースに、現場でよくあるユースケースを交えて、どのようにこの仕組みが使われているかを具体的に解説します。フレームワークに頼らない自由度と保守性の高さを、ぜひ体感してみてください。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを想定しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
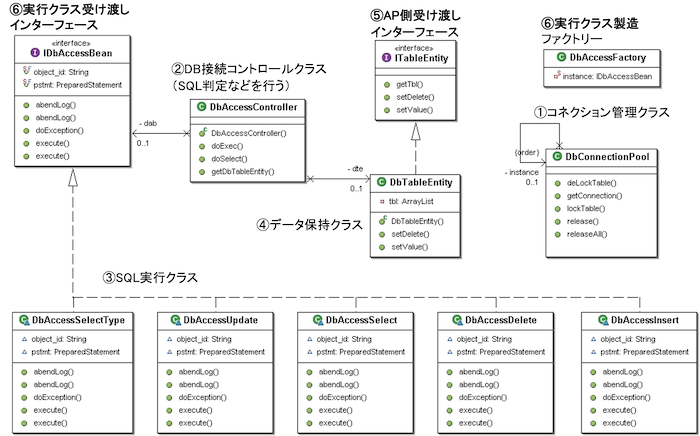
共通DBアクセスクラス
🟣共通DBアクセスクラス
📌 SQL記述を最小化、業務ロジックに集中できる共通基盤
├─ORMにはうんざり!第1回:シンプルなJava DBアクセスクラスを考えてみた
├─ORMにはうんざり!第2回:共通DBアクセスクラスでSQLを直感的に操作するJava設計
├─ORMにはうんざり!第3回:JavaでDB接続の最適化と共通プールの構築
├─ORMにはうんざり!第4回:Java共通ログ出力とsystem.xml設定の構成を解説
├─ORMにはうんざり!第5回:例外の闇を断つ、堅牢なJavaエラーハンドリングとログ設計
└─ORMにはうんざり!第6回:Java共通DBアクセスクラスの実用例で脱フレームワーク
MVC構成と共通DBアクセスクラスの関係
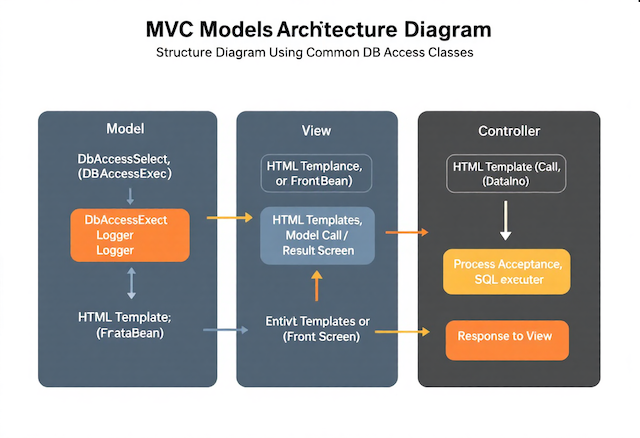
MVC構成の中で共通DBアクセスクラスを導入する最大の価値は、アプリケーションの各役割が整理され、保守性と拡張性が大幅に向上する点にあります。
特に業務システムでは、データアクセスが複雑になりやすく、変更が発生しやすい部分でもあります。DB処理を共通化することで、ControllerやViewに余計なロジックが混ざることを防ぎ、開発者がアプリケーションの本質に集中しやすい環境を作ることができます。
MVC と DB アクセスの役割分担
MVC構成では、Model、View、Controllerの三つが独立して役割を持ちます。ここに共通DBアクセスクラスを組み込むことで、各層が行うべき作業が明確になり、ソースコードの見通しが良くなります。
役割分担が整理されると、新しい機能追加の際にも必要な修正箇所をすぐに把握でき、開発スピードと品質の両立が実現できます。
以下は、MVCそれぞれと共通DBアクセスクラスの関係を整理した表です。
| 層 | 本来の役割 | 共通DBアクセス導入後のメリット |
|---|---|---|
| Model | 業務ロジックとデータ処理 | SQL作成や共通処理の大半が自動化され、実装量が減る |
| View | 画面表示 | Modelから受け取る値が安定するため余計な加工が不要になる |
| Controller | 入力受付と処理の振り分け | DB処理を直接持たなくなるため、処理が単純化され保守性が高まる |
共通DBアクセスクラスをModel層に置くことで、ControllerやViewがデータアクセスの詳細を一切意識しなくなります。この構造は大規模開発で特に効果を発揮し、層ごとの責務が明確に保たれるため、複数人開発や長期保守においても破綻しにくい強いシステム設計が実現できます。
Model層での役割
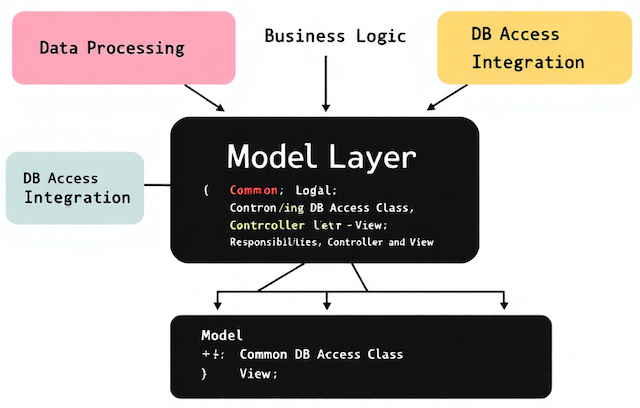
Model層は、アプリケーションの中心としてデータ処理と業務ロジックを担います。特に共通DBアクセスクラスを導入した場合、Model層が扱う処理は明確に整理され、Controller層やView層が余計なデータ処理を抱え込むことを防げます。
システム全体の見通しが良くなるだけでなく、修正箇所を特定しやすくなるため、後から発生する仕様変更への耐性も高くなります。データアクセスをModelに一本化することで、開発効率と保守性を両立できる構造が実現します。
Model 層が行う DB アクセスの責務
Model層がDBアクセスを担う意義は、SQLの発行やレコード更新といった処理を確実にModel側へ閉じ込め、他の層に影響を与えないようにする点にあります。
共通DBアクセスクラスを用いることで、Modelのコード量が増えるどころか、むしろ統一されたインターフェースのおかげで簡潔にまとまり、業務ロジックに集中しやすくなります。
以下は、Model層が担う具体的な責務を整理した表です。
| 責務 | 内容 | メリット |
|---|---|---|
| データ取得 | 単一行または複数行のレコード取得を行う | ControllerがSQLを意識する必要がなくなる |
| データ登録 | 新規レコードの追加を行う | 登録項目の変更に強くなる |
| データ更新 | 既存レコードの変更を行う | 更新処理が共通化されロジックの重複を排除できる |
| データ削除 | 特定レコードの削除を行う | 削除条件の統一により操作ミスを防ぎやすくなる |
ここからは、Model層が実際にデータアクセスを行う流れをイメージしやすいように、具体的なコード例とその出力例を示します。
DbAccessController user_dac = new DbAccessController(USER_MST);
ITableEntity ent = user_dac.getDbTableEntity();
ent.setValue("user_id", "u0001", 0);
Connection con = DbConnectionPool.getInstance().getConnection();
int result = user_dac.doSelect(con, SQL_BASE);
System.out.println(result);
【 出力例:】
1
この例では、Model層が必要な項目をセットし、共通DBアクセスクラスを通じて処理を実行しています。返り値が1の場合は該当データが存在することを示し、後続の業務ロジックへ自然につなげることができます。
Model層が責務を正しく担うことで、Controller層はリクエスト処理に集中でき、View層は整形済みデータを安心して表示するだけで済むようになります。
Controller層との連携ポイント
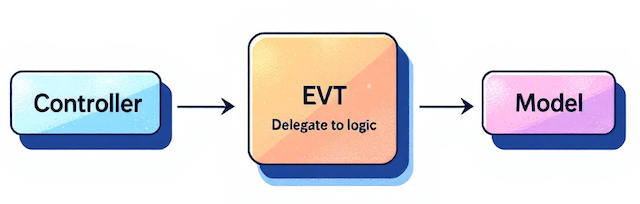
Controller層はアプリケーション全体の入り口として、ユーザー操作を正確に受け取り、必要な処理を誤りなくEVT層へ渡す役割を担います。多くの現場では、このControllerが肥大化しやすく、ビジネスロジックまで混在してしまうケースが後を絶ちません。
しかし、Controllerが「入力整理とEVT呼び出し」に徹することで、コードは驚くほど読みやすくなり、修正にも強くなります。ここでは、ControllerがどのようにEVTと連携するのか、その流れを分かりやすく解説します。
Controller → Model 呼び出しの流れ
ControllerからEVTへの処理依頼は、明確なパターンに統一することでミスを減らし、誰が開発しても同じ品質を維持できるようになります。ここでは例として、アバターとして登場する「開発担当の佐藤さん」がユーザー検索機能を実装する場面を想定します。
佐藤さんは画面のフォームから送信されたユーザーIDを処理したいと考えています。しかし、ControllerではSQLを触ったり、トランザクションを操作したりするべきではありません。そこで、受け取った値をDataBeanに格納し、EVTへ処理を委譲します。
Adm_login_DataBean bean = new Adm_login_DataBean();
bean.setValue("user_id", request.getParameter("user_id"), 0);
Adm_login_Evt evt = (Adm_App_Evt)EvtFactory.getEvt(Adm_login_Evt.class.getName());
boolean result = evt.execute(bean);
このようにControllerは、ユーザー入力をDataBeanへ移し替えるだけで必要な準備が整います。ここでのポイントは、Controllerが一切の業務判断やDB操作を行わず、EVTへ正しく責務を渡している点です。
処理が成功すれば次の画面へ進むためのフラグを返し、失敗時はEVT側でSystemExceptionが発生し、ログにも必ず記録されます。 この流れを採用することで得られる主なメリットは次のとおりです。
| メリット | 説明 |
|---|---|
| Controllerがシンプルになる | 入力整理に徹することで、画面遷移の流れを直感的に把握できます |
| EVTへ責務が集約される | DB処理やビジネスロジックがひとつの層にまとまり、テストが容易になります |
| 修正時の影響範囲が小さくなる | Controller側の記述が変わらないため、EVT内部だけに集中して修正できます |
EVTを呼び出した際の返却結果を例として示します。佐藤さんが「u001」を検索した場合、EVTの中でDbAccessControllerを通じてデータ取得処理が実行され、その結果フラグがControllerへ戻ります。
true
このように、Controllerが「入力整理」と「EVT呼び出し」に集中することで、アプリケーション全体の構造が明確になり、障害発生時の切り分けも圧倒的に速くなります。現場で運用するシステムほど、このシンプルな流れが大きな効果を発揮します。
View層との依存排除
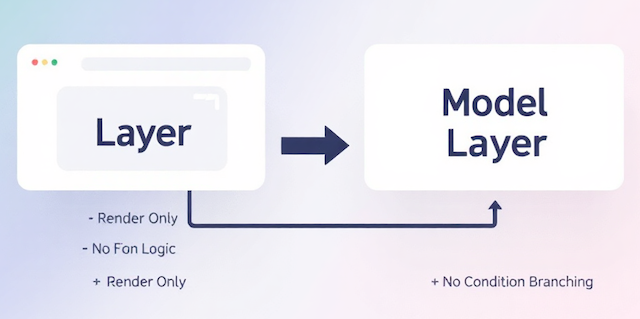
View層はユーザーに情報を届ける最終地点ですが、ここに余計なロジックが入り込むと、保守性が一気に崩れてしまいます。特に業務システムでは、画面側に条件分岐やDBアクセス由来のロジックが混在してしまい、後からの修正で不具合を引き起こすケースが非常に多いです。
この問題を解消するためには、Viewが扱う情報をModel(EVT)が整形し、View側は受け取った値を表示するだけの状態にしておくことが重要です。ここでは、あなたのアーキテクチャが実現している「View層の完全な依存排除」とはどういうものかを説明します。
View が Model から受け取るデータの扱い
ViewはModelから受け取ったデータを、そのまま表示することに専念します。依存排除という言葉が難しく感じられるかもしれませんが、実際には「画面が判断しない」という一点に集約されます。
たとえば、画面表示用の処理を実装している開発メンバーの鈴木さんが、ユーザー情報一覧画面にデータを表示したいとします。このとき、鈴木さんが悩む必要はありません。
EVTがすべてのデータを整形し、Entityに格納した状態で返してくれるからです。 以下は、ControllerからViewに渡されるデータの具体例です。
ArrayList userList = entity.getTbl();
この一行で、View側は行データの一覧を安全に受け取れます。ビューに渡されるデータは、すでにEVT内部でDbAccessControllerによって取得され、DbTableEntityのtblへ格納済みです。
そのため、View側で行うのは「受け取ったリストをループで表示する」だけになります。 実際の出力例は次のようになります。
[ {user_id=u001, user_name=田中太郎, email=taro@example.com}, {user_id=u002, user_name=鈴木花子, email=hanako@example.com} ]
このように、View層は値の加工や判定を行わず、Modelで形成されたデータをそのまま表示できます。これにより、View側の記述は極めてシンプルになり、画面開発担当者はデザインと表示に集中できるようになります。
次の表は、Model側がデータ整形を持つ場合と、View側が整形を持ってしまった場合の比較です。
| 方式 | 利点 | 懸念点 |
|---|---|---|
| Modelが整形 | Viewが軽量になり保守性が高まります | EVT側の責務が少し増えます |
| Viewが整形 | 柔軟な表示に対応できます | ロジックが混在し障害調査が困難になります |
この構成は、アプリケーションの安定性と開発効率を両立するための重要な仕組みです。Modelに責務を集約することで、Viewは非常に扱いやすくなり、画面修正の影響範囲も最小限に抑えられます。大型プロジェクトでも破綻しない、堅牢なアーキテクチャを実現できる点が大きなメリットです。
現場での典型的なユースケース
共通DBアクセスクラスは、構造がシンプルでありながら業務要件に柔軟に対応できるため、実際の現場で高い効果を発揮します。
特にユーザー管理やログイン認証といった基本機能では、処理の流れが複雑になりがちですが、この仕組みを採用することで実装の負荷が大きく下がります。ここでは、実際に稼働しているプロジェクトをイメージしながら、どのように共通クラスが役立つのかを紹介します。
ユーザー管理での使用例
ユーザー管理は、多くのシステムに共通する代表的な処理です。ここでは、開発担当の山本さんが「ユーザー情報の検索」を実装する場面を例にします。山本さんは、画面から渡されたユーザーIDを基にデータを取得したいと考えています。
しかし、ControllerでSQLを発行したり、トランザクションを操作したりする必要はありません。共通クラスを用いることで、担当エンジニアは最小限の記述だけで安全に検索処理を実装できます。
まず、Controllerでは入力をDataBeanへ移し替えます。
Adm_App_DataBean bean = new Adm_App_DataBean();
bean.setValue("user_id", request.getParameter("user_id"), 0);
次に、山本さんはEVTを生成して処理を委譲します。EVTはファクトリ経由で生成され、DbAccessControllerを用いてDB検索を実行します。
Adm_App_Evt evt = (Adm_App_Evt)EvtFactory.getEvt(Adm_App_Evt.class.getName());
boolean result = evt.execute(bean);
検索処理が成功すると、Entityへ行データが格納され、Controllerへ検索結果として返されます。
ArrayList list = entity.getTbl();
取得された内容の出力例を示します。
[ {user_id=u001, user_name=山本太一, email=yamamoto@example.com}, {user_id=u002, user_name=佐々木優, email=sasaki@example.com} ]
この流れを採用することで、ユーザー管理の実装は大幅に効率化されます。以下の表に、この仕組みが提供するメリットをまとめます。
| ポイント | 説明 |
|---|---|
| Controllerが軽量なまま保てます | 入力整理とEVT呼び出しだけに徹するため、修正時の影響範囲が最小限になります |
| EVTにロジックが集約されます | データ取得や整形が一箇所にまとまることで、再利用性が向上します |
| Entityが画面表示用データを保持します | Viewはリストをそのまま表示するだけになり、画面開発が非常にシンプルになります |
このように、ユーザー管理のような基本機能でも、共通DBアクセスクラスを使うことで複雑な作業を最小化し、チーム全体の生産性を高めることができます。

ログイン処理のデータ取得と検証
ログイン時には、ユーザーIDとパスワードに対応する情報をSQLで組み立てて doSelect() を実行し、対象データが存在するかどうかで認証処理を判断します。取得結果件数は int 型で返されるため、0件であれば未登録、1件であれば認証成功といった処理分岐が可能です。
// コントローラとエンティティ生成
DbAccessController user_dac = new DbAccessController(USER_MST);
ITableEntity user_ite = user_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
String sql = SQL_USER_LOGIN_BASE;
if (params.containsKey("user_id") && params.containsKey("password")) {
sql += " WHERE user_id='" + params.get("user_id") + "' AND password='" + params.get("password") + "'";
}
try {
int result = user_dac.doSelect(con, sql);
if (result == 0) {
logOut("INFO", "ユーザーが見つかりません");
}
} catch (Exception e) {
logOut("ERROR", "ログイン検索失敗:" + e.getMessage());
} finally {
pool.release(con);
}
ユーザー情報の更新処理
ユーザーの名前やメールアドレスなどを変更する場合は、対象テーブル名を指定して DbAccessController を生成し、ITableEntity 経由でフィールドに値をセットしたあと doExec() を実行します。更新処理の結果は int 型で返され、1以上であれば成功、0以下であればロールバックなどの対応を取る必要があります。
// コントローラとエンティティ生成
DbAccessController user_dac = new DbAccessController(USER_MST);
ITableEntity user_ite = user_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
try {
con.setAutoCommit(false);
user_ite.setValue("user_name", params.get("user_name"), 0);
user_ite.setValue("email", params.get("email"), 0);
user_ite.setValue("update_user", session.getAttribute("login_id").toString(), 0);
int result = user_dac.doExec(con, USER_MST);
if (result > 0) {
con.commit();
} else {
con.rollback();
}
} catch (Exception e) {
try { con.rollback(); } catch (Exception ex) {}
logOut("ERROR", "更新処理失敗:" + e.getMessage());
} finally {
pool.release(con);
}
ユーザー新規登録処理(INSERT)
新規登録時は、DbAccessController のインスタンス生成時に対象テーブル名を指定し、ITableEntity を使って各カラムに値を設定した上で doExec() を実行します。返却される int 型の値で登録件数を取得でき、想定件数でなければロールバック処理を行うことが推奨されます。
// コントローラとエンティティ生成
DbAccessController user_dac = new DbAccessController(USER_MST);
ITableEntity user_ite = user_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
try {
con.setAutoCommit(false);
user_ite.setValue("user_id", params.get("user_id"), 0);
user_ite.setValue("user_name", params.get("user_name"), 0);
user_ite.setValue("email", params.get("email"), 0);
user_ite.setValue("insert_user", session.getAttribute("login_id").toString(), 0);
int result = user_dac.doExec(con, USER_MST);
if (result > 0) {
con.commit();
} else {
con.rollback();
}
} catch (Exception e) {
try { con.rollback(); } catch (Exception ex) {}
logOut("ERROR", "登録処理失敗:" + e.getMessage());
} finally {
pool.release(con);
}
ユーザー削除処理(DELETE)
削除処理も doExec() を使って行います。対象レコードの主キーや条件を ITableEntity にセットし、削除対象のテーブル名を doExec() に指定するだけで、DELETE文が自動生成されます。返り値の int 型で削除件数を判定し、処理の成否を判断します。
// コントローラとエンティティ生成
DbAccessController user_dac = new DbAccessController(USER_MST);
ITableEntity user_ite = user_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
try {
con.setAutoCommit(false);
user_ite.setValue("user_id", params.get("user_id"), 0);
int result = user_dac.doExec(con, USER_MST);
if (result > 0) {
con.commit();
} else {
con.rollback();
}
} catch (Exception e) {
try { con.rollback(); } catch (Exception ex) {}
logOut("ERROR", "削除処理失敗:" + e.getMessage());
} finally {
pool.release(con);
}
トランザクション管理システムでの使用例
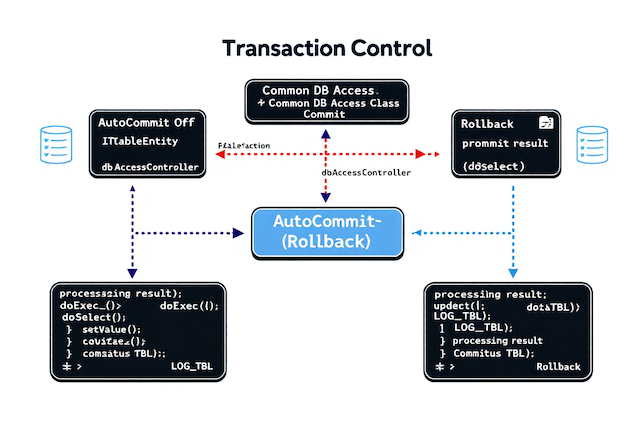
共通クラスの設計により、トランザクション開始から例外制御までを一定のパターンで統一できます。
処理単位でのトランザクション制御
更新や削除処理など、複数のステップを伴う操作は setAutoCommit(false) を明示し、コミット・ロールバックを制御します。
try {
con.setAutoCommit(false);
// 各種 setValue(), doExec() 処理
con.commit();
} catch (Exception e) {
try { con.rollback(); } catch (SQLException se) {}
}
ロールバックと例外管理の実装パターン
の例外でも確実に rollback() を通すため、ネストされた try-catch で保護します。
try {
con.setAutoCommit(false);
int result = user_dac.doExec(con, USER_MST);
if (result >= 1) {
con.commit();
} else {
con.rollback();
}
} catch (Exception e) {
try { con.rollback(); } catch (SQLException se) {}
}
複数テーブルにまたがる更新処理の一元化
処理対象が複数テーブルに渡る場合でも、それぞれ DbAccessController を分けて doExec() を呼ぶだけでよく、可読性が大きく向上します。
DbAccessController log_dac = new DbAccessController(LOG_TBL);
DbAccessController stat_dac = new DbAccessController(STATUS_TBL);
ITableEntity log_ent = log_dac.getDbTableEntity();
ITableEntity stat_ent = stat_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
try {
con.setAutoCommit(false);
log_ent.setValue("msg", "処理完了", 0);
stat_ent.setValue("status", "SUCCESS", 0);
int log_result = log_dac.doExec(con, LOG_TBL);
int stat_result = stat_dac.doExec(con, STATUS_TBL);
if (log_result > 0 && stat_result > 0) {
con.commit();
} else {
con.rollback();
}
} catch (Exception e) {
try { con.rollback(); } catch (Exception ex) {}
logOut("ERROR", "複数テーブル更新失敗:" + e.getMessage());
} finally {
pool.release(con);
}
エラーログの集中管理とトレース性
共通ログテーブルへの出力も、一般的なINSERT文と同様に doExec() を通じて自前で実装可能です。専用のロギング機能が備わっているわけではありませんが、任意のエラーメッセージや例外情報をエンティティに詰めることで、ログ出力処理を共通化できます。
DbAccessController log_dac = new DbAccessController(ERROR_LOG);
ITableEntity log_ent = log_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
try {
con.setAutoCommit(false);
// ここに通常の処理(例:在庫処理など)
throw new Exception("DB接続失敗"); // 仮に例外発生
} catch (Exception e) {
try { con.rollback(); } catch (Exception ex) {}
log_ent.setValue("error_code", "E500", 0);
log_ent.setValue("message", e.getMessage(), 0);
log_dac.doExec(con, ERROR_LOG);
logOut("ERROR", "例外発生:" + e.getMessage());
} finally {
pool.release(con);
}
フレームワーク依存を避けるメリット
現場ではSpringやHibernateなどのフレームワークを導入することが一般的ですが、一方で、あえてフレームワークを使わないシンプルな構成を採用するケースも存在します。
ここでは、共通DBアクセスクラスを活用し、フレームワークに依存しない設計を選択することで得られる具体的なメリットについて解説します。
軽量・高速な実行環境
フレームワーク非依存の最大の利点は、不要なライブラリやコンポーネントを排除できる点にあります。これにより、アプリケーション全体の実行環境が軽くなり、起動時間やレスポンス速度も改善されます。
たとえば、Spring BootのようにTomcatや多数の依存ライブラリを組み込む必要がある構成では、アプリケーションの初期化だけで数百MBのメモリを消費します。
対して、今回紹介しているような共通DBアクセスクラスを使った構成では、純粋なJavaクラスとJDBCのみで完結するため、最小限の実行環境で済みます。
実行時のボトルネックが明確になりやすく、パフォーマンスチューニングもしやすいため、リソース制限のある環境下でも柔軟に対応できます。
保守コストの削減と属人化の回避
フレームワークを導入すると、その仕様変更やバージョンアップに伴う修正対応が必ず発生します。しかもそれは、当該フレームワークに詳しい技術者に依存せざるを得ない場面を多く生み出します。結果的に、保守作業が属人化しやすくなります。
フレームワークを使わない構成にすることで、DBアクセス処理なども自作クラスで完結するため、ブラックボックスな挙動がなくなり、コード全体の見通しがよくなります。以下のように、SQLを含めて処理が明示されているため、誰が見てもロジックの流れを理解しやすくなります。
DbAccessController user_dac = new DbAccessController(USER_MST);
ITableEntity user_ite = user_dac.getDbTableEntity();
DbConnectionPool pool = DbConnectionPool.getInstance();
Connection con = pool.getConnection();
try {
con.setAutoCommit(false);
user_ite.setValue("user_id", "test001", 0);
user_ite.setValue("user_name", "テストユーザー", 0);
user_ite.setValue("email", "test@example.com", 0);
int result = user_dac.doExec(con, USER_MST);
if (result > 0) {
con.commit();
} else {
con.rollback();
}
} catch (Exception e) {
try { con.rollback(); } catch (Exception ex) {}
logOut("ERROR", "登録処理失敗:" + e.getMessage());
} finally {
pool.release(con);
}
このように構造が明快であることで、新人技術者や引継ぎ担当者でも理解しやすく、保守コストが大きく下がります。
マルチプロジェクト間での再利用性の高さ
特定のフレームワークに依存した構成では、そのフレームワークが導入されていない他のプロジェクトへの移植が困難です。対して、共通DBアクセスクラスのような汎用的な設計であれば、以下のような利点があります。
| 比較項目 | フレームワーク依存構成 | 共通DBアクセスクラス構成 |
|---|---|---|
| 再利用の容易さ | 導入環境に制限あり | どのJava環境でも利用可能 |
| 設定ファイルの量 | 多くのXMLやYAML | 最小限の設定で運用可 |
| 他プロジェクトへの流用 | 一部コード書き直しが必要 | クラス単位でそのまま流用可能 |
実際、複数案件でこの共通クラスを使い回したことで、開発速度や保守効率が向上したという実感があります。単一プロジェクトだけに閉じた設計ではなく、汎用的なライブラリとして運用する意識が重要です。
共通DBアクセスクラスを一度整備してしまえば、同様のロジックを他プロジェクトでもそのまま活用できるため、再開発の手間が不要になります。結果として、開発者のリソースを新機能実装や障害対応に集中できるようになります。
今後の拡張と応用の可能性
共通DBアクセスクラスは、現場での業務効率化だけでなく、将来的なシステム拡張や新技術との連携にも大きな柔軟性を持っています。現時点での枠にとらわれず、今後の進化や応用可能性を意識することで、さらに価値の高い基盤として成長させることができます。
マイクロサービス間での共通アクセス基盤化
システムがマイクロサービス構成へ移行する中で、DBアクセス方法を統一することは非常に重要です。各サービスがバラバラのORMや自作クエリを持つと保守性が急激に低下します。共通クラスをベースにすることで、以下のような恩恵が得られます。
| メリット | 説明 |
|---|---|
| インターフェースの統一 | 各マイクロサービスでも同一のメソッドでDB処理が可能 |
| 保守性の向上 | 仕様変更時の修正ポイントが明確化され、影響範囲も限定できる |
| 学習コストの最小化 | 新規参加者でも短時間で理解可能 |
また、DBスキーマが複数サービス間で共有される場合でも、共通クラスの導入によりアクセスパターンのバラつきを最小限に抑えることができます。
クラウド移行後のポータビリティ確保
オンプレ環境からAWSやGCPなどのクラウド基盤へ移行するケースでは、インフラだけでなくミドルウェアやデータベースエンジンの仕様も変わることがあります。たとえば以下のようなケースです。
| 変更内容 | 影響範囲 |
|---|---|
| RHEL → Ubuntu | OSレベルのシェル操作や設定ファイルの配置 |
| PostgreSQL → CloudSQL | 接続方式や文字コードの扱い |
| Tomcat → AppEngine | デプロイ方法やログ出力の方式 |
共通DBアクセスクラスを利用することで、データアクセスのロジックをサービス本体から分離できるため、クラウド移行時にも「差し替えるべき箇所」が明確になり、移行作業を大幅に簡略化できます。
AI補助によるコード自動生成との統合
今後注目されるのが、AIによるコード自動生成との連携です。あらかじめ共通クラスのインターフェースが確立していれば、AIに対して次のような指示が可能になります。
「USER_MST テーブルに対する SELECT 処理のコードを生成してください」
→ DbAccessController の doSelect() を使ったコードが自動生成される
また、更新系の処理でも同様です。
「USER_MST に user_name, email を登録するコード」
→ setValue() の羅列と doExec() を使った commit 処理が提案される
これは、AIによる自動生成の質がインターフェースの一貫性に強く依存していることを示しています。共通DBアクセスクラスが明確な構造を持っていれば、AIが正しく機能しやすくなり、開発効率を格段に向上させることができます。
さらに、テストコードの生成や異常系のパターン出力まで含めて、開発の一部をAIに委ねる環境構築も視野に入れることができます。これは今後の開発スタイルに大きな変革をもたらす可能性があります。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを想定しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core




