

業務システムの開発において、例外処理とログ出力は「後回しにされがち」な存在です。しかし、実際の運用現場ではエラーが起きたときにその原因を特定できるかどうかが、システムの信頼性と復旧速度を大きく左右します。特にJavaで開発された中〜大規模な業務システムでは、ログの粒度や例外の扱い方ひとつで、障害対応の工数やトラブルの再発率が激変します。
今回の第5回では、共通データアクセスクラス群のなかでも「例外処理」と「ログ出力」にフォーカスし、どのように堅牢なエラー制御と可視化を設計すべきかを具体的に解説していきます。
第2回の記事で紹介したDbAccessControllerを中核とした処理では、SQL実行の成否や例外発生時の振る舞いを呼び出し元へ正しく伝達する仕組みが求められます。加えて、例外の内容をログへ確実に記録し、原因追跡可能な状態を常に維持するための設計が欠かせません。
本記事では、GitHubで公開している実装(Logger.java, SystemException.java, SystemInfo.javaなど)をベースに、共通的な例外ハンドリング構造とログ出力の戦略的な実装例を詳しく解説します。
ORMでは見えづらくなった「例外の本質」をあらためて明らかにし、現場で本当に役立つログ設計とは何かを追求していきます。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを想定しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
共通DBアクセスクラス
🟣共通DBアクセスクラス
📌 SQL記述を最小化、業務ロジックに集中できる共通基盤
├─ORMにはうんざり!第1回:シンプルなJava DBアクセスクラスを考えてみた
├─ORMにはうんざり!第2回:共通DBアクセスクラスでSQLを直感的に操作するJava設計
├─ORMにはうんざり!第3回:JavaでDB接続の最適化と共通プールの構築
├─ORMにはうんざり!第4回:Java共通ログ出力とsystem.xml設定の構成を解説
├─ORMにはうんざり!第5回:例外の闇を断つ、堅牢なJavaエラーハンドリングとログ設計
└─ORMにはうんざり!第6回:Java共通DBアクセスクラスの実用例で脱フレームワーク
エラー処理とログ出力の必要性
業務システムにおいて、例外処理とログ出力は単なる開発補助の仕組みではなく、運用中のシステムを安定して維持し続けるために不可欠な設計要素です。
一見すると後回しにされがちな領域ですが、実際のトラブル対応では、これらの仕組みが機能しているかどうかで、復旧時間と再発防止の難易度が大きく変わります。
このセクションでは、なぜ例外処理やログ出力がシステム全体の品質に直結するのかを掘り下げ、共通クラスとして設計するべき背景や意義を明確にしていきます。
なぜ例外処理が疎かにされるのか
例外処理は「正常に動作する前提で開発が進められる」段階では、後回しにされることが多い領域です。特に社内向け業務システムでは、リリースまでのスケジュールが優先され、try-catchの簡易実装や、例外の握り潰し(空catch)で処理を済ませるケースが散見されます。 その背景には、以下のような要因があります。
| 原因 | 開発現場でよくある状況 |
|---|---|
| 工数不足 | 納期重視で異常系への配慮が後回し |
| 開発者の軽視 | 例外処理は「誰でもできる」雑務と誤解されがち |
| 再利用性の軽視 | 一時しのぎのロジックが積み重なり属人化 |
しかし、こうした短期的な妥協は、本番環境でのトラブル対応や原因究明の際に、必ず開発者自身の手間となって跳ね返ってきます。 例外処理は、単にcatchしてログ出力するだけでは意味がありません。例外の分類、再スローの基準、ユーザー通知の有無、そしてログ出力方針まで含めて戦略的に設計する必要があります。
ログ出力とトラブルシューティングの関係
障害発生時に最も求められるのは、「何が起きたのかを再現できるだけの情報」です。ログ出力が不完全であれば、現場の運用担当者は現象だけを見て憶測で対応を始めることになり、対応は迷走し、再発を防げないまま次の障害を招くリスクが高まります。 例えば、ログ出力の不足で発生する問題は次の通りです。
| ログの欠如 | トラブル対応時の影響 |
|---|---|
| 例外内容が不明 | 原因特定が不可能となる |
| 発生時刻が不明 | 関連処理との因果関係を追えない |
| ユーザー識別情報がない | 対象データが特定できない |
これを回避するには、ログ出力の設計段階で次の3点を明確にすることが重要です。
どのレベルのエラーをどの粒度で出力するか 例外の種類ごとに出力対象とすべき内容は何か どこにログを出力するのが適切か(ファイル/DB/外部ログ集約) など。
本シリーズで使用しているLoggerクラスでは、ログレベル(INFO/WARN/ERRORなど)と出力先(system.xmlで定義)を外部から制御可能にしており、これによってシステム稼働後も設定変更による柔軟な対応が可能となります。
例外処理の基本設計やJava標準の例外クラスの扱い方について、さらに詳しく学びたい方は、以下の記事もあわせてご覧ください。

ORMが隠す「例外の本質」
近年では、ORM(Object-Relational Mapping)の普及により、SQL文を直接扱う機会が減っています。
一見すると開発効率が上がるように思われがちですが、実際には例外発生時の挙動やSQLレベルでの問題特定が困難になるケースが多く存在します。ORMが抽象化することで見えにくくなるのは以下のような情報です。
| ORMが隠す内容 | 影響 |
|---|---|
| 実際に発行されたSQL | エラー原因のSQLが不明となる |
| DB制約違反の詳細 | 例外がまとめられ、エラー内容が不鮮明 |
| トランザクション境界 | ロールバックやコミットのタイミングが把握困難 |
このような背景から、本シリーズではあえてORMを排除し、SQLを明示的に扱う共通DBアクセスクラスとして設計を行っています。
これにより、SQL実行時のエラー内容を例外として捕捉しやすくなり、呼び出し元に対しても意味のある情報を通知できる構造が実現できます。
また、Loggerクラスとの連携によって、例外が発生した瞬間のSQL文やパラメータ、ユーザー情報をそのまま出力する設計が可能となり、トラブルの原因分析が格段に効率化されます。
共通エラーハンドリングの設計指針
エラー処理を行き当たりばったりで実装してしまうと、保守性の低いコードが蓄積し、全体の品質が劣化していきます。
特にJavaでは、標準の例外クラスだけで業務ごとのエラー状態を正確に表現しようとすると、catchブロックが乱立し、例外の意味も曖昧になります。
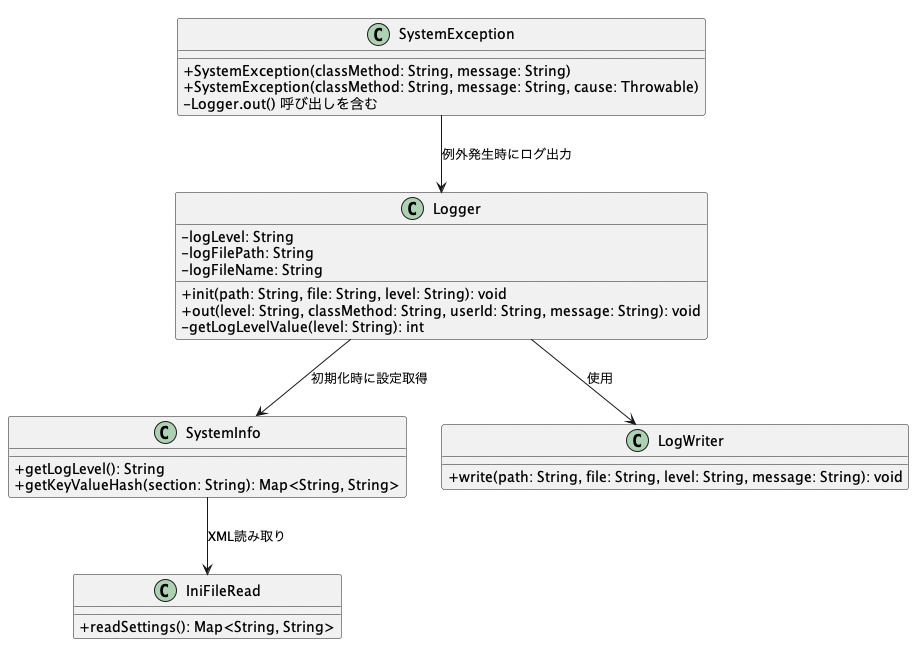
そこで、共通DBアクセスクラスでは、業務ロジック層に適したエラー伝達手段として、独自の例外クラスSystemExceptionを導入し、例外の分類・管理・伝搬方法を統一しています。
このセクションでは、再利用可能で意味のあるエラーハンドリングを実現するための基本設計方針を解説します。
SystemExceptionクラスの設計方針
SystemExceptionクラスは、JavaのRuntimeExceptionを継承した独自例外クラスで、共通DBアクセスクラス群におけるあらゆるエラー通知の中核として位置付けられています。
主な目的は以下の通りです。
| 目的 | 意図 |
|---|---|
| 共通例外の一本化 | 処理レイヤを超えて例外構造を統一 |
| ログ出力との連携 | Loggerクラスと連携し、例外発生地点を即記録 |
| メッセージ識別子の活用 | ユーザー通知用のメッセージとログ内容を分離 |
SystemExceptionには、システムエラー、業務エラー、バリデーションエラーなどの種別を意識的に含められる設計とすることで、運用面での意味のある分類と、それに応じたログレベルの使い分けが可能となります。
以下は典型的なスロー例です。
throw new SystemException("E1001", "データベース接続エラー", e);
このように、エラーコードと表示用メッセージを明示することで、ログ側には詳細な情報を、画面側には汎用的な通知を、それぞれ柔軟に制御できます。
例外関連クラスはこちら
👉 GitHub – db-access-core / exception ディレクトリ
例外の分類と切り分け
例外は「全て例外として扱う」のではなく、分類し、レベルに応じた処理方針を定義することが必要です。たとえば、以下のようにレイヤ別・内容別に例外を分類することで、呼び出し元のロジックが適切にハンドリングしやすくなります。
| 例外の種類 | 意味 | 典型的な対応方法 |
|---|---|---|
| 業務エラー | 想定範囲内の例外 | ユーザー通知+警告ログ |
| システムエラー | 想定外の異常終了 | 即時ロールバック+エラーログ |
| バリデーションエラー | 入力チェックで検知 | 入力フィードバック+ログ出力なし |
これにより、SystemExceptionを使った場合でも、業務的な再試行可能性やユーザー向け通知要否に応じて、呼び出し側のアクションを分けることができます。
さらにLoggerと連携して例外の重大度に応じたログレベル(ERROR/WARN/INFOなど)を適用することで、無駄なログを減らしながら、必要な情報は確実に残すことが可能になります。
呼び出し元への伝播方法
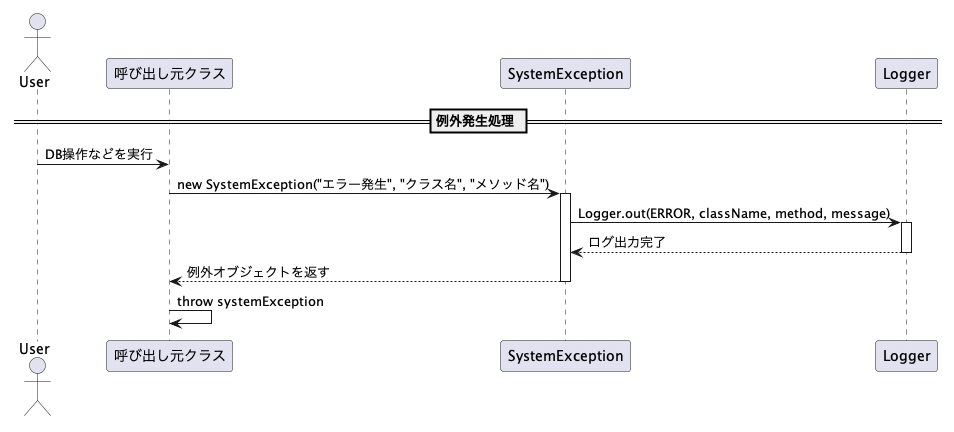
例外をスローしただけでは、上位レイヤでの正しい制御は実現できません。例外は必ず呼び出し元で捕捉する構造とし、再スローの可否やログ出力の責任範囲を明確に定義することが重要です。
共通DBアクセスクラスでは、基本的に各DB操作メソッド内部で例外が発生した場合、それをcatchした上でSystemExceptionとしてラップし、再スローしています。これにより、呼び出し側では例外の種類が常にSystemExceptionで統一され、分岐処理が簡潔に記述できます。
try {
controller.doExec(sql);
} catch (SystemException e) {
Logger.out(Logger.ERROR, "UserService#registUser", userId, e.getMessage());
throw e;
}
このように例外を上位へ伝播させる際には、ログ出力を必ず行った上で再スローするという統一ルールを設けることで、運用時のトラブル特定が容易になります。
また、ログ出力の内容には「何時」、「何処で」、「誰が」、「何を」、「行った」などを明記する必要があり、これをLoggerクラスと連携して実現しています。
共通ログ出力クラスの役割と設計
システム開発におけるログ出力は、単なるデバッグ用ではなく、本番環境での障害分析、業務追跡、セキュリティ管理まで担う重要な機能です。
そのため、プロジェクト単位で個別にログ処理を設計するのではなく、再利用可能な共通ログ出力クラスを用意することで、ログ設計の統一と保守性の向上が実現できます。
本シリーズで使用しているLoggerクラスは、ログ出力における責務を明確化し、ログレベル・出力先・ファイル名などを外部設定で柔軟に制御できる構造となっています。このセクションでは、その設計思想と使い方を具体的に解説していきます。

ログレベルの正しい使い分け
ログ出力は内容を記録することだけが目的ではありません。出力するレベルを適切に制御することで、必要な情報のみを抽出し、障害分析を効率化することができます。 共通ログ出力クラスでは、以下のログレベルを定義し、用途に応じた分類を徹底しています。
| ログレベル | 用途 | 出力対象の例 |
|---|---|---|
| ERROR | 致命的な異常 | SQL例外、NullPointerException |
| WARN | 処理継続は可能だが注意が必要 | 入力不正、業務チェック異常 |
| INFO | 通常の業務処理開始・終了 | バッチ処理の開始・終了 |
| DEBUG2 | 業務データの変化 | 更新前後のデータ内容 |
| DEBUG3 | 詳細な内部処理の追跡 | 各SQLのパラメータ、制御フロー |
特にDEBUG2、DEBUG3レベルは本番環境では出力しないことが多いため、system.xmlの設定でログ出力レベルを変更できる仕組みにより、環境ごとの柔軟な切り替えが可能です。これにより、開発中は詳細なトレースを記録し、本番では最低限の情報に絞るといった運用が実現できます。
system.xmlによるログ制御
Loggerクラスは、system.xmlという設定ファイルを通じて動作制御が可能な設計になっています。この構造により、ソースコードを変更することなく、ログ出力の構成を外部から調整することができます。 system.xmlの記述例は以下の通りです。
<log>
<filepath>/Users/nara/Work/Java/logs</filepath>
<logfile>application.log</logfile>
<level>INFO</level>
</log>
この設定は、Loggerクラスの初期化時にSystemInfo経由で読み込まれます。
Logger.init();
初期化が一度行われると、設定されたファイルパス・ファイル名・ログレベルが内部に保持され、以後のログ出力はすべてこの情報に基づいて処理されます。
ログレベルを変更したい場合はsystem.xmlの値を変更するだけで済むため、デプロイ後でも設定変更が容易です。
また、ログファイルの出力先も絶対パスで明示することで、ログがどこに出力されるかを完全にコントロールできます。プロジェクト単位でログ出力場所を変えたい場合にも対応できる構造です。
Loggerクラスの呼び出し例と注意点
Loggerクラスは、4つの引数を受け取る`Logger.out()`メソッドを中心に動作します。引数は以下の通りです。
| 引数 | 内容 |
|---|---|
| level | ログレベル(ERROR/INFOなど) |
| location | 呼び出し元クラス名とメソッド名(例:UserService#registUser) |
| userId | 処理中のユーザー識別子 |
| message | 出力メッセージ |
出力例は以下のようになります。
Logger.out(Logger.INFO, "UserService#registUser()", "user0001", "ユーザー登録を開始します");
このログが出力されると、ログファイルには以下のような行が記録されます(INFOレベルの場合):
[2025-11-16 12:34:56] [INFO] UserService#registUser().user0001: ユーザー登録を開始します
ユーザー登録を開始します 注意点として、Loggerクラスを使用する際には、必ず事前に初期化処理「Logger.init()」を呼び出す必要があります。
初期化が行われていないと、ログ出力処理が内部でスキップされるか、NullPointerExceptionが発生する可能性があります。 また、ログレベルは静的変数で管理されているため、アプリケーション全体で統一されます。
ログレベルを動的に変化させる用途には向いていないため、system.xmlの変更と再起動が必要になる点も留意してください。
本記事で紹介したLoggerクラスの具体的な実装や初期化手順、ログレベルの制御方法について詳しく知りたい方は、以下の記事をご覧ください。
▶︎【Javaの基礎知識】設定地獄はもう嫌!シンプルな共通ログ出力クラスを作ってみた

エラー発生時のログ出力戦略
エラー処理と同じく、ログ出力においても「とりあえず出す」では不十分です。特に業務システムにおいては、障害調査や監査対応などに耐えうるログ設計が求められます。
出力内容、出力形式、出力先の統一が取れていないと、ログの役割そのものが形骸化し、運用保守コストを増大させます。
本セクションでは、例外発生時におけるログ出力戦略として、エラー種別ごとの出力方針や、ログ設計を一元化する方法、さらにファイル分割やローテーション設計についても解説します。
業務エラーとシステムエラーのログ出力例
ログ出力において最も重要なことは、「何時」、「何処で」、「誰が」、「何を」、「行った」のかを判断できる情報が残っていることです。ただし、全ての例外に対して同じ粒度でログを出力する必要はありません。業務エラーとシステムエラーで明確にログ内容を変えることで、必要な情報だけを効率よく抽出できます。
| エラー種別 | ログレベル | 出力内容の粒度 |
|---|---|---|
| 業務エラー | WARN | メッセージID、エラー内容、ユーザーID |
| システムエラー | ERROR | スタックトレース、処理中SQL、例外発生場所 |
以下は業務エラーのログ出力例です。
Logger.out(Logger.WARN, "LoginService#authUser", "user1234", "ログイン失敗:パスワード不一致");
一方、システムエラーの場合は詳細な情報が求められます。
Logger.out(Logger.ERROR, "UserService#registUser", "user0001", "SQLException:重複キー違反が発生しました");
このように、ログ出力の粒度を使い分けることで、本当に必要なログだけを的確に取得し、不要な冗長ログの蓄積を防止することができます。
出力場所・ログ形式の統一設計
ログの出力場所やファイル名がバラバラになっていると、調査時に複数のディレクトリやファイルを検索する必要が生じ、非常に効率が悪くなります。
そのため、ログ出力は共通の設計ルールに従い、常に一定のディレクトリ構成・ファイル名で運用することが重要です。 共通ログ出力クラスでは、system.xmlに以下のように記述してログ出力先とログファイル名を固定化しています。
<log>
<filepath>/Users/bepro/Work/Java/logs</filepath>
<logfile>application.log</logfile>
<level>INFO</level>
</log>
また、出力形式も常に同じパターンになるように、ログ1行あたりの構造を統一しています。以下はその例です。
[2025-07-15 12:34:56] [ERROR] UserService#registUser.user0001: SQLException:重複キー違反が発生しました
このように「日時」「レベル」「呼び出し元」「ユーザーID」「メッセージ」が整ったログであれば、grep等のツールで検索しやすく、ログの抽出・フィルタ・集計といった処理も自動化しやすくなります。
実装例:SystemExceptionとLoggerの連携
共通DBアクセスクラスでは、エラーの発生からログへの記録、そしてその情報を運用に活用するまでの流れを一貫して設計しています。
LoggerクラスとSystemExceptionクラスは密に連携しており、例外が発生した際にどの情報を、どの粒度でログへ残すかを明確に制御できます。
このセクションでは、例外がスローされたときの具体的な処理シーケンスと、ログ出力時に重要となるユーザー識別情報、トレースキーの設計方針、さらに実際の現場で運用に役立つログの例について解説していきます。
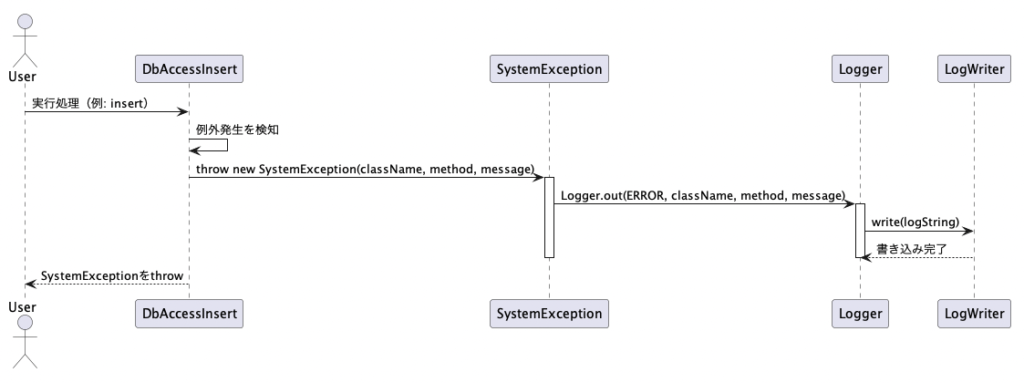
例外発生からログ記録までのシーケンス
SystemExceptionとLoggerを連携させたエラー処理では、以下のようなシーケンスで処理が流れます。
| ステップ | 処理内容 |
|---|---|
| 1 | SQL処理や業務処理中に例外が発生 |
| 2 | catchブロックでSystemExceptionとしてラップ |
| 3 | Loggerで即時にログ出力(ERROR/WARN) |
| 4 | 必要に応じて例外を再スローし、上位に伝播 |
以下はその実装例です。
try {
dbAccessController.doExec(sql);
} catch (SQLException e) {
Logger.out(Logger.ERROR, "UserService#registUser", userId, "SQL例外:" + e.getMessage());
throw new SystemException("E2001", "ユーザー登録中にDBエラーが発生しました", e);
}
このように、ログ出力は例外のスローと同時に実行し、再スローで呼び出し元へ処理を戻す設計とすることで、トラブルの瞬間を漏れなくログに記録しつつ、アプリケーションとしての整合性も保ちます。
運用現場で役立つログ出力の具体例
運用中の障害調査では、ログの内容が直接対応のスピードと精度に影響します。以下のような形式でログを設計することで、実運用でのトラブル分析が格段に効率化されます。
| ログ内容 | 記録例 | 意図 |
|---|---|---|
| 処理開始ログ | [INFO] UserService#registUser.user0001: 登録処理開始 | 処理の開始点 |
| データ出力 | [DEBUG2] DBAccessController#doExec.user0001: INSERT文実行 param=xxx | 更新内容の把握 |
| 例外通知 | [ERROR] UserService#registUser.user0001: SQLException:主キー重複 | 障害発生点 |
| 処理終了 | [INFO] UserService#registUser.user0001: 登録処理終了 | 正常終了の確認 |
特に「処理開始」「例外発生」「処理終了」の3点を必ずログに出力するように設計することで、どこでエラーが発生し、どこまで処理が進行していたかを時系列で明確に把握することができます。 また、処理にかかった時間を明示的に記録することで、性能劣化の兆候やボトルネックの検知にも繋がります。
Logger.out(Logger.INFO, "UserService#registUser", "user0001", "登録処理完了(実行時間:245ms)");
このような具体的なログ出力は、単なるメッセージの記録に留まらず、システムの可観測性(Observability)を高める効果があります。運用現場では「エラーが出た」という事実よりも、「なぜ起きたのか、再現性はあるのか」を見極めるための手がかりが重視されるため、事前にログ設計を整備しておくことが極めて重要です。
まとめと
本記事では、共通DBアクセスクラスにおけるエラーハンドリングとログ出力について、設計思想から実装例までを通して解説しました。
LoggerクラスとSystemExceptionクラスを連携させることで、エラーの検知・記録・伝達を一貫して設計でき、システムの保守性と運用性が大きく向上します。
単なるログ出力や例外通知に留まらず、「どのような場面で何を記録すべきか」「記録された情報がどのように活用されるか」を明確にしたうえで設計することが、現代の業務システムには求められています。
このセクションでは、本記事の要点を整理するとともに、次回の第6回に向けてどのようにこの仕組みを活かしていくか、その展望を共有します。
例外関連クラスはこちら
👉 GitHub – db-access-core / exception ディレクトリ
フレームワークに縛られない自由な設計を目指すなら、次の記事もぜひご覧ください。
実際に共通DBアクセスクラスを活用する具体例を通じて、脱ORM・脱フレームワークの可能性をさらに深掘りしていきます。




