

Claude Codeを複数セッションで同時に動かせば、生産性もその分だけ上がる。最初は本気でそう考えていました。1つの画面では記事構成を整理し、別の画面では自動化ワークフローを修正し、さらに別の画面では設定やログを確認する。AIは止まらずに動いてくれるので、自分ひとりでも小さな開発チームを持ったように見えました。
でも実際に10セッションを並列で動かしてみると、先に限界を迎えたのはAIではなく自分の方でした。どのセッションで何を頼んだのか、どこまで確認したのか、どの変更が安全で、どの変更がまだ怪しいのか。作業そのものはAIが進めてくれますが、最後に判断する人間は1人のままです。
この記事では、Claude Codeを10セッション動かして分かった、人間側の判断・確認・状態管理の限界を整理します。AIを増やせば作業量は増えます。でも、管理できる状態の数を超えると、成果ではなく混乱が増えます。AIを並列で使う前に、何を外に書き出し、どこを人間が見るべきかを考えるための記事です。
Claude Codeを10セッション動かせば生産性も10倍になると思っていた

Claude Codeを10セッション開いて、同時に別々の作業を走らせる。最初に思いついたときは、かなり本気で「これはいける」と思っていました。人間の自分は1人しかいません。でも、AIは10個同時に動かせます。だったら単純計算で、生産性は10倍になるんじゃないか。1日は24時間しかないけど、10セッション並列で動かせば、時間換算では1日240時間分の作業が進むんじゃないか。そんな雑な計算を、わりと真面目に信じていました。
実際、最初の数分は気持ちよかったです。こっちの画面ではブログ記事の整理。別の画面では自動化ワークフローの修正。さらに別の画面では調査、検証、設定ファイルの確認。まるで自分の下に、小さな開発チームができたような感覚でした。しかも相手はAIなので、休憩もしません。文句も言いません。指示を出せば、どんどん作業を進めてくれます。
「これ、人間がボトルネックだった作業が一気に解消されるんじゃないか」。そう思いました。でも、ここで見落としていたことがあります。AIは10個同時に働けます。でも、それを見て判断する自分の脳は1個しかありません。
1日240時間分の作業が進むという錯覚
Claude Codeを10セッション動かせば、1日24時間の中で10本の作業が同時に走ります。単純に考えれば、24時間 × 10セッションです。つまり、1日240時間分の作業が進むように見えます。この計算はかなり雑です。それでも、実際に複数セッションを動かしている最初の数分は、その計算が正しいように見えました。
自分が1つの画面で確認している間に、別のセッションでは別の作業が進んでいます。戻ってくると、そこには何かしらの結果があります。「ここまで確認しました」「修正しました」「原因候補を整理しました」。こういう報告が複数の画面から返ってくると、作業量が一気に増えたように見えます。
実際、AIは止まっていません。自分が別のことを考えている間にも、指示された範囲で処理を続けています。だから最初は、かなり気持ちよく進みます。自分が1人で作業していたときには、どうしても順番待ちが発生していました。調査している間は修正できない。修正している間は記事を書けない。記事を書いている間は別の設定確認が止まる。でも、AIに分けて投げると、この順番待ちが消えたように見えます。
ここで錯覚が起きました。作業が同時に進んでいることと、成果が同時に積み上がっていることを同じものとして見てしまったのです。
小さな開発チームを持ったように見えた瞬間
10セッションを並べて動かしていると、最初は本当に小さな開発チームを持ったように見えました。こっちのClaude Codeには記事構成を任せる。別のClaude Codeには自動化ワークフローの修正を任せる。また別のClaude Codeには設定ファイルの確認を任せる。さらに別のClaude Codeには、原因調査を任せる。役割を分けて指示を出すと、それぞれの画面でAIが作業を進めます。
人間の部下に依頼しているわけではありません。でも、画面の上では複数人が同時に作業しているように見えます。この感覚はかなり強烈でした。今まで自分が抱えていた作業を、外へ出せたように感じます。自分が細かい作業を全部やらなくても、AIが進めてくれる。自分は指示と判断に集中すればいい。
特に、ファイル確認や調査のような作業では、この効果が大きく見えます。自分が1つの作業に集中している間に、別の画面では別の結果が返ってくる。その結果を見て次の指示を出す。さらに別の画面へ移ると、そこでもまた進捗が出ている。この流れだけを見ると、かなり効率が上がったように感じます。
最初に見えていたのは成果ではなく進んでいる感じ

Claude Codeのセッションをいくつも開いて、それぞれに別の作業を投げる。ひとつはブログ記事の構成。ひとつはコード修正。ひとつは調査。ひとつは設定ファイルの確認。画面のあちこちで、AIが勝手に作業を進めている。これがかなり気持ちよかったんです。
今までなら、自分がひとつずつ考えて、調べて、直して、確認していた作業が、同時に何本も進んでいきます。しかも、自分はその間に別の指示を出せます。「あれ、これ本当に一人会社の限界を超えたんじゃないか?」そんな感じがありました。
特に、単純な調査やファイル確認みたいな作業は、並列にするとかなり速く見えます。自分が一つの画面を見ている間に、別の画面では次の結果が出ている。戻るたびに何かが進んでいる。これは楽しいです。かなり中毒性があります。
あの異様にうざいyes/noの確認さえなければもう最高です。
複数画面で作業が進む気持ちよさ
複数画面でClaude Codeが動いている状態は、かなり気持ちよさがあります。こっちの画面では記事の流れを整理している。別の画面ではエラー原因を探している。さらに別の画面ではファイル差分を確認している。自分が画面を切り替えるたびに、どこかで何かが進んでいます。
人間がひとりで作業していると、同時に進められる作業には限界があります。調べている間は、別の作業は止まります。修正している間は、記事の確認は止まります。でも、Claude Codeを複数セッションで動かすと、その停止感がなくなります。自分が別の作業を見ている間にも、AIは指示された範囲で作業を進めています。だから、画面上だけを見ると、作業全体が一気に流れ始めたように見えます。
この感覚は便利です。そして、少し危ないです。進んでいる画面が多いほど、自分の判断も進んでいるように錯覚します。でも実際には、AIが出した結果を人間がまだ確認していない段階では、成果として確定していません。画面の中では進んでいても、自分の中ではまだ処理待ちです。この違いを見落とすと、未確認の作業がどんどん積み上がっていきます。
確認できる量かどうかを見ていなかった問題
Claude Codeに作業を投げると、AIはかなり速く返してきます。調査結果、修正案、差分、原因候補、次にやること。それぞれのセッションから、次々に情報が戻ってきます。最初はそれがありがたく見えます。
10セッション動かすということは、10本分の結果が返ってくるということです。10本分の結果が返ってくるということは、10本分の確認が必要になるということです。
しかも、それぞれの作業は内容が違います。記事構成を見る頭。コード修正を見る頭。n8nの設定を見る頭。Gitの差分を見る頭。ブログ導線を見る頭。全部、見る場所が違います。それなのに、最初は「AIが進めてくれるから楽になる」としか考えていませんでした。
実際には、AIが進めた分だけ、確認する対象も増えます。確認対象が増えると、自分の頭の切り替えも増えます。切り替えが増えると、どこまで見たか分からなくなってきます。
1つの不具合で複数セッションの状態が混ざった瞬間
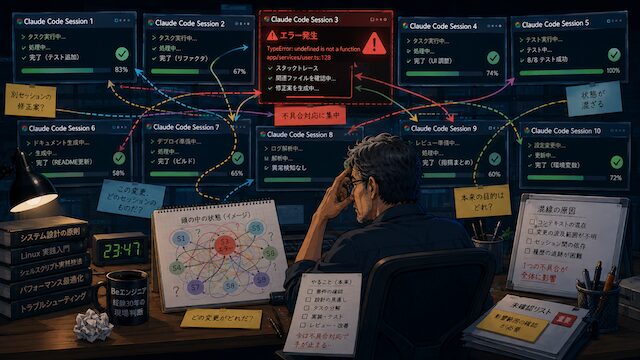
崩れ始めたのは、1つのセッションで不具合が出たときでした。最初は、よくある小さな問題のつもりでした。「あ、ここだけ直せば大丈夫だな」くらいの感覚です。でも、その不具合を追いかけ始めた瞬間に、頭の中の優先順位が全部そこへ寄っていきました。
エラー内容を読む。原因を考える。関連ファイルを確認する。Claude Codeに追加で調べさせる。戻ってきた回答を見て、また指示を出す。気づくと、その1つの問題だけで頭がいっぱいになっていました。その間にも、他のセッションは動いています。別のプロジェクトでは、記事構成が進んでいる。別の画面では、設定変更の提案が出ている。また別のセッションでは、「修正しました」と報告が来ている。でも、自分の頭はもう不具合対応モードになっています。
ここで一番きつかったのは、作業が止まったことではありません。どの作業がどの状態だったか、分からなくなってきたことです。さっき見たエラーは、どのリポジトリの話だったか。この修正案は、不具合が出ている方のものだったか。それとも、順調に進んでいる別プロジェクトの提案だったか。画面上では分かれているはずなのに、頭の中では混ざっていきます。
一度混ざり始めると、確認のたびに時間がかかります。「これは何の作業だっけ?」「この変更は入れていいんだっけ?」「さっきのエラーと関係あるんだっけ?」本来ならAIに任せて楽になるはずだったのに、自分が各セッションの状態を思い出すだけで疲れていく。このあたりから、だんだん嫌な予感がしてきました。10個並列で動かすということは、10個分の作業を進めることではなく、10個分の混乱を同時に抱えることなんじゃないか。そう思い始めたのが、このタイミングでした。
不具合対応で注意が1点に吸い寄せられる流れ
不具合が出ると、人間の注意はかなり強くそこへ引っ張られます。特にClaude Codeで作業していると、エラーの原因を追いかける流れに入りやすいです。ログを見る。差分を見る。設定を見る。関連ファイルを確認する。前回の指示が悪かったのか、処理の前提が違ったのかを考える。この状態になると、他の作業を見る余裕が減っていきます。
自分では、少しだけ確認しているつもりでした。でも実際には、その不具合が頭の中の中心になります。そして、その考え方を持ったまま別のセッションを開いてしまいます。さっきまで見ていたエラーの原因。さっき考えていた修正方針。さっき疑っていた設定ファイル。その感覚が残ったまま、別の画面を見ることになります。
本来なら、そのセッションは別の目的で動いています。扱っているリポジトリも違います。作業の段階も違います。「こっちも同じ問題かもしれない」「この設定も直した方がいいかもしれない」「この修正も入れておいた方が安全かもしれない」。その瞬間は、正しい確認をしているように見えます。でも、後から見ると、別作業に不具合対応の判断を持ち込んでいるだけでした。
不具合対応そのものが悪いわけではありません。問題は、1つの不具合に吸い寄せられた注意のまま、他のセッションまで見てしまうことです。AIはセッションごとに別々の作業をしています。でも、判断する自分の頭は同じです。そこが切り替わらないまま別の画面を見ると、正常に進んでいた作業まで、不具合対応の目で見てしまいます。
戻った画面で何を頼んでいたか分からなくなる怖さ
不具合対応に集中したあと、別のClaude Codeの画面へ戻ると、そこで別の怖さが出てきます。画面にはログが残っています。会話も残っています。だから、読めば分かります。でも、すぐには思い出せません。このセッションでは何を頼んでいたのか。どこまで進んでいたのか。どの変更は確認済みなのか。どの報告はまだ見ていないのか。画面を開いた瞬間に、それがすぐ出てこないのです。
数分前まで自分が指示していたはずなのに、別の不具合対応を挟んだだけで文脈が抜けています。仕方なく、少し前のログを読み返します。どんな指示を出したのか。Claude Codeが何を返したのか。どこで止めるつもりだったのか。次に何を確認する予定だったのか。この読み直しが増えると、作業を進めている時間より、状態を思い出している時間の方が長くなります。
しかも、戻った画面が複数あると、同じことを何度も繰り返します。Aの画面を思い出す。Bの画面を思い出す。Cの画面を思い出す。またAに戻って、さっき何を見ていたかを思い出す。この状態になると、並列で動かしている意味が薄れていきます。AIは作業を進めています。でも、自分がその作業状態を保持できていません。
このときに必要だったのは、記憶力ではありませんでした。各セッションに、目的、現在位置、未確認事項、人間が判断する点を残しておくことでした。それがないまま画面を行き来したので、戻るたびに自分の頭で文脈を復元することになりました。そして、その復元作業が積み重なった結果、複数セッションの状態が頭の中で混ざっていきました。
うまく進んでいた作業まで壊した理由
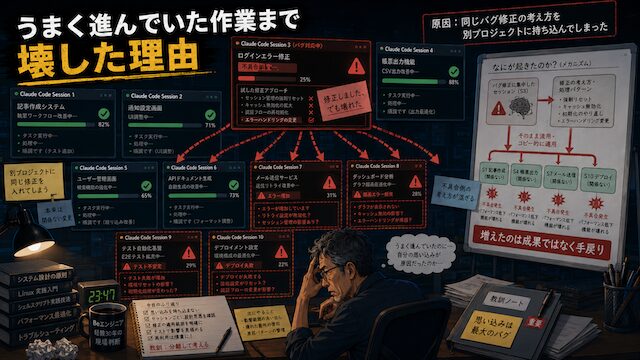
一番まずかったのは、不具合が出ていない作業にまで、間違った修正を入れてしまったことです。不具合対応をしていると、頭の中では原因らしきものをずっと追いかけています。「設定の持ち方が悪いのかもしれない」「このファイルの参照先がおかしいのかもしれない」「こっちの処理も同じ問題を持っているかもしれない」。そんなふうに考えながら、別のセッションを開いてしまいました。
すると、本当は順調に進んでいた作業まで、さっきの不具合と同じ目で見てしまいます。「あれ、これも直した方がいいんじゃないか」「こっちにも同じ修正を入れておいた方が安全じゃないか」。その瞬間は、かなりもっともらしく見えます。でも後から見直すと、全然関係ありません。むしろ、正常に動いていたものを自分で壊していました。
これが本当にきつかったです。AIが勝手に暴走したというより、自分の判断が混ざってしまいました。不具合が出ているプロジェクトの考え方を、別のプロジェクトに持ち込んでしまったのです。しかも、Claude Codeの画面はどれも似ています。黒い画面に、似たようなログ。似たようなファイル名。似たような「修正しました」という報告。10セッション開いていると、どれも別の作業のはずなのに、だんだん同じ作業に見えてきます。
そして、間違った修正を入れたあとに気づきます。「あ、これはそっちじゃなかった」。この瞬間の脱力感がすごいです。AIに作業を任せていたはずなのに、結局、自分で地雷を埋めていました。しかも厄介なのは、間違いがすぐには見えないことです。その場ではそれっぽく進みます。Claude Codeも「修正しました」と言います。ログも一見きれいに見えます。でも、後で確認すると、別の場所が壊れている。ここでようやく、並列で動かす怖さは、AIがミスすることだけではないと分かりました。自分の頭の中で、別々の作業が混ざることの方が危ないのです。
不具合側の考え方を別プロジェクトへ持ち込んだ失敗
不具合対応をしていると、その原因を見つけるために頭がかなり狭くなります。設定の参照先、ファイルの読み込み順、環境変数、実行パス、権限、差分の入り方。ひとつの問題を追いかけるために、怪しい場所を順番に疑っていきます。この見方自体は、不具合対応では必要です。
問題は、その見方を持ったまま別のプロジェクトを見てしまったことです。本来なら、別プロジェクトには別プロジェクトの目的があります。作業の前提も違います。触ってよい範囲も違います。確認すべき観点も違います。それなのに、不具合対応中の頭のまま開くと、「こっちにも同じ問題があるかもしれない」と見えてしまいます。
その結果、順調に進んでいた作業にまで、不具合対応側の修正方針を入れてしまいました。あとから見れば、その修正は不要でした。不要どころか、正常だった流れを崩す原因になっていました。これはClaude Codeが勝手にやったというより、自分が混ざった判断をAIに渡してしまった失敗です。
ここで分かったのは、並列運用では「今どの問題を見ている頭なのか」を分けないと危ないということです。不具合対応の頭、記事整理の頭、設定確認の頭、レビューの頭。それぞれを切り替えたつもりでも、実際には前の作業の見方が残っています。その状態で別のセッションに指示を出すと、関係ない修正まで正しく見えてしまいます。
Claude Codeの似た画面が判断ミスを増やす構造
Claude Codeを複数セッションで開いていると、画面の見た目はかなり似ています。黒いターミナル画面。似たようなログ。似たような「確認しました」「修正しました」という報告。作業しているリポジトリや目的は違うのに、画面としては同じ種類の情報に見えます。
この似た画面が、判断ミスを増やしました。もちろん、よく読めば違いは分かります。パスも違います。ファイル名も違います。会話の流れも違います。でも、複数セッションを行き来していると、毎回それを読み直さないと文脈が戻りません。急いでいると、前のセッションの感覚を持ったまま次の画面を見てしまいます。
特に危ないのは、Claude Codeがどの画面でも似たように「修正しました」と返してくることです。不具合対応中の「修正しました」と、順調な作業中の「修正しました」は意味が違います。前者は原因追跡の途中かもしれません。後者は予定どおりの変更かもしれません。でも、画面上では同じような完了報告に見えます。
この状態で判断すると、「どの修正を採用していいのか」「どの変更はまだ検証前なのか」「どのセッションは止めるべきなのか」が曖昧になります。AIの出力そのものだけではなく、画面をまたいで判断する自分の状態が危なくなっていました。Claude Codeを複数動かすなら、画面が似ていることを前提に、セッションごとの目的、触ってよい範囲、未確認事項を外に出しておかないと、見た目の似た報告に引っ張られて判断を間違えます。
AIは並列で走れるが人間の判断は並列にならない
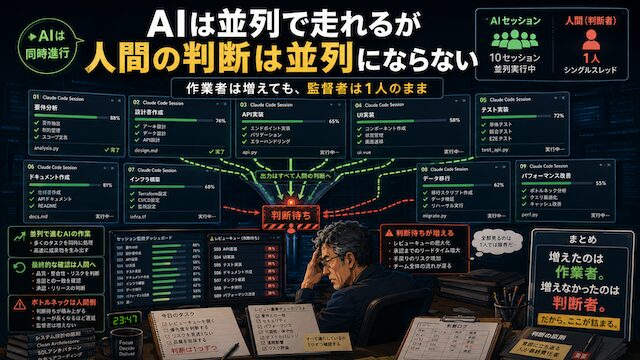
ここでようやく気づきました。AIは並列で走れます。Claude Codeのセッションを10個開けば、10個の作業は本当に同時に進みます。でも、それを確認する自分は1人です。どの提案を採用するか。どの修正を止めるか。どのエラーを先に見るか。どこまでを「完了」と判断するか。そこは全部、自分が決めないといけません。
AIに作業を投げると、作業そのものは軽くなります。でも、判断まで消えるわけではありません。むしろ、並列にすればするほど、判断の数は増えます。1セッションなら、見るべき流れは1本です。でも10セッションあると、10本分の流れを追わないといけません。しかも、それぞれの流れは途中で変わります。エラーが出る。追加確認が必要になる。思ったより大きな修正になる。別のファイルに影響が出る。そのたびに、自分の頭を切り替えないといけません。
この切り替えが、想像以上に重かったです。画面を切り替えるだけなら簡単です。でも、頭の中まで一瞬で切り替わるわけではありません。「これは何の作業だったか」「どこまで確認したか」「次に何を見ればいいのか」。毎回そこから思い出す必要があります。AIは待ってくれます。でも、セッションの数が増えるほど、自分の頭の中には未処理の判断が積み上がっていきます。
そして、その判断待ちが詰まり始めると、全体が遅くなります。AIが遅いのではありません。自分が追いついていない。ここが一番大きな誤算でした。AIを増やせば、作業者は増えます。でも、監督者である自分は増えません。10人分の作業員を連れてきたつもりが、現場監督は自分1人のまま。しかも、その現場が10か所に分かれている。そりゃ無理があります。この時点で、「AIを何個動かせるか」よりも、「自分が何個まで判断できるか」の方が大事だと分かりました。
作業者は増えても監督者は増えない
Claude Codeを複数セッションで動かすと、作業者が増えたように見えます。ひとつのセッションでは記事構成を作る。別のセッションではコードを直す。別のセッションでは設定を調べる。さらに別のセッションではログを追う。画面上では、複数の作業者が同時に動いているように見えます。
でも、実際には監督者は増えていません。指示を出す人も、結果を確認する人も、修正を採用する人も、止める判断をする人も自分です。AIは作業を進めてくれますが、「この変更は入れていい」「これは危ないから止める」「ここはまだ未確認」といった判断は、最後に人間へ戻ってきます。
ここを見落とすと、AIを増やした分だけ楽になるように見えて、実際には自分の確認待ちが増えていきます。人間のチームでも、作業者だけ増やして監督者が増えなければ、報告を受ける人が詰まります。AIでも同じでした。むしろAIは返答が速いので、確認待ちが溜まる速度も速くなります。
作業者が増えたことと、管理できる状態が増えたことは別です。Claude Codeを10個開けば、作業者は10人分に見えます。でも、その10人分の状態を見て判断する人間は1人です。ここを分けて考えないと、並列化したつもりが、未確認の山を増やしているだけになります。
判断待ちが増えるほど全体が遅くなる
AIを並列で動かすと、最初は全体が速くなったように見えます。別々のセッションから、次々に報告が返ってきます。調査結果、修正案、差分、確認事項、次の提案。画面を切り替えるたびに何かが進んでいるので、作業全体が加速しているように感じます。
でも、その報告はまだ成果ではありません。人間が読んで、判断して、必要なら止めて、必要なら次の指示を出して、初めて次へ進めます。つまり、AIが速く返してくるほど、人間側には判断待ちが積み上がります。ここを処理できないと、AIが速いこと自体が負担になります。
判断待ちが増えると、全体の流れは逆に遅くなります。なぜなら、どのセッションも最後は人間の確認を待つからです。修正しても、採用判断が止まっている。調査しても、次に進む判断が止まっている。記事構成が出ても、使うかどうかの判断が止まっている。表面上は複数作業が進んでいても、要所で人間の判断に詰まると、全体はそこで止まります。
この状態になると、AIを増やしても意味が薄くなります。むしろ、確認していないもの、採用していないもの、止めるべきか分からないものが増えるだけです。AIが並列で走れることと、人間が並列で判断できることは違います。AI時代の生産性を考えるなら、何個起動できるかではなく、何個まで自分が判断できる状態で管理できるかを先に決める必要があります。
生産性を下げた正体は作業量ではなく切り替え回数
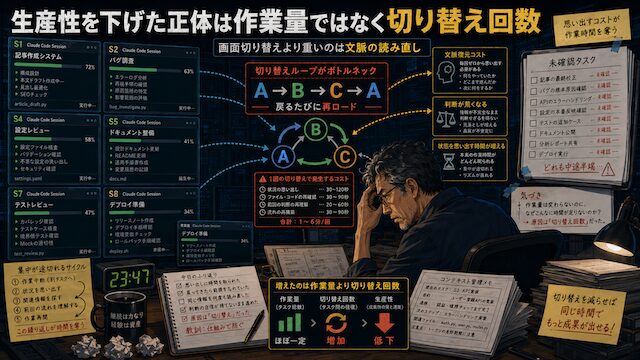
最初は、作業量が増えたから疲れたのだと思っていました。10セッションも動かしているから、単純に見るものが多い。だから大変なんだろう、と。でも、少し違いました。本当にきつかったのは、作業量そのものではなく、頭の切り替え回数でした。
Aのプロジェクトで不具合を見る。Bのプロジェクトで記事構成を見る。Cのプロジェクトで設定変更を見る。またAに戻ってエラーを見る。そのあとDに移って、さっき何を頼んだか思い出す。この「戻るたびに思い出す」が、かなり重いです。
画面を開けば、ログや会話は残っています。だから、一応たどれば分かります。でも、たどるだけで時間を使います。「このセッションは何をしていたんだっけ」「この修正は採用していいんだっけ」「この作業は止めていたのか、進めていたのか」。毎回、頭の中で再ロードが発生します。
これが積み重なると、作業を進めている時間より、状態を思い出している時間の方が長くなっていきます。しかも、切り替えた直後は判断が荒くなります。さっきまで不具合対応をしていた頭のまま、別の作業を見る。すると、必要以上に疑ってしまったり、逆に確認を飛ばしてしまったりします。落ち着いて1つずつ見れば気づけることを、並列の流れの中では見落とします。ここで、生産性が下がっている理由がはっきりしました。AIが遅いわけではありません。作業が難しすぎるわけでもありません。自分の頭が、切り替えのたびに削られていたのです。
画面切り替えより重い文脈の読み直し
画面を切り替えるだけなら簡単です。タブを選ぶ。別のターミナルを見る。別のClaude Codeのセッションを開く。操作としては数秒でできます。でも、本当に重いのは画面の切り替えではありません。その画面で何をしていたのかを思い出すことです。
同じClaude Codeでも、セッションごとに文脈は違います。ある画面では記事構成を作っています。別の画面ではn8nの設定を見ています。別の画面ではGitの差分を確認しています。さらに別の画面では不具合対応をしています。見た目は似ていても、頭の中で読むべき前提は全部違います。
だから、画面を開いた瞬間にすぐ判断できるわけではありません。まず、このセッションで何を頼んでいたのかを読み直します。次に、Claude Codeがどこまで進めたのかを確認します。そのうえで、どの変更が確認済みで、どこが未確認なのかを思い出します。この読み直しが、想像以上に重い作業でした。
しかも、文脈の読み直しは成果として見えません。画面上では何も進んでいないように見えます。でも、自分の頭の中ではかなりの処理をしています。前提を読み戻し、状態を復元し、次に見るべき場所を決める。この作業をセッションを切り替えるたびに繰り返していました。結果として、AIを並列に走らせているのに、自分は文脈の読み直しに時間を使っていました。
思い出すコストが作業時間を奪う流れ
思い出すコストは、最初は小さく見えます。ひとつのセッションなら、少し前のログを見ればすぐ戻れます。何を頼んだか、どこまで進んだか、次に何を見るかもすぐ分かります。でも、セッションが増えると、この小さなコストが一気に積み上がります。
10セッションを開いていると、それぞれに別の作業状態があります。記事の途中。設定確認の途中。エラー調査の途中。修正提案の途中。レビュー待ちの途中。どれも少しずつ進んでいるので、戻るたびに「今ここはどの状態だったか」を思い出す必要があります。
この思い出す作業が増えると、実際に手を動かす時間や判断する時間が削られていきます。作業を進めるために画面を開いたはずなのに、最初の数分を状態確認に使います。次の画面に移っても、また状態確認から始まります。これを繰り返すと、並列で作業しているのではなく、並列に散らかった状態を回収しているだけになります。
ここで必要だったのは、記憶力を上げることではありませんでした。各セッションの状態を外に出しておくことでした。何を頼んだのか。どこまで終わったのか。何が未確認なのか。人間が次に見る点はどこなのか。これを残しておけば、戻るたびに頭で復元する必要は減ります。逆に、それを残さないままセッションだけ増やすと、AIが進めた作業よりも、自分が思い出すための時間が増えていきます。生産性を下げていた正体は、作業量ではなく、切り替えのたびに発生する文脈復元のコストでした。
次にやるなら10個起動する前に状態を外へ出す

失敗して分かったのは、いきなり10個動かしてはいけないということです。AIを並列で使うこと自体が悪いわけではありません。むしろ、うまく使えばかなり強いと思います。でも、その前に必要な準備がありました。最初にやるべきことは、Claude Codeを何個起動するかではなく、作業状態を自分の頭の外へ出すことでした。
人間の頭だけで、10個の作業状態を覚えるのは無理でした。どのセッションが何を担当しているのか。どのリポジトリを触っているのか。どこまでやってよくて、どこから先は止めるのか。何が完了していて、何が未確認なのか。これを頭の中だけで持とうとすると、画面を切り替えるたびに文脈を読み直すことになります。
本当は、AIに任せたいはずでした。でも、状態管理を作らないまま並列化すると、AIを管理するために自分の脳を使い切ってしまいます。これはかなり本末転倒でした。10倍速くしたいなら、最初に必要なのは10個起動することではありません。1つずつの作業を、混ざらない形に分けることです。
セッションごとに目的を書く。変更していい範囲を書く。どこで止めるかを書く。最後に必ず、何をしたか、何を確認していないか、人間が何を見るべきかを残させる。そこまでやって、ようやく並列化の土台ができます。AIを10個動かすなら、10個分の記憶を自分で抱えない仕組みが必要でした。それを作らずに走らせたから、今回は崩れたのだと思います。
セッションごとに目的・範囲・停止条件を分ける
次に同じことをやるなら、まずセッションごとに役割を分けます。たとえば、1つは実装、1つは調査、1つはレビュー、1つは記事整理というように、何のためのセッションなのかを最初に固定します。ここが曖昧なまま走らせると、あとで自分が追えなくなります。
目的だけでは足りません。触っていい範囲も必要です。どのリポジトリを見るのか。どのファイルを変更していいのか。どのファイルは確認だけにするのか。勝手に修正していいのか、提案だけで止めるのか。ここを決めておかないと、別の作業で考えていた修正方針が混ざったときに、関係ない場所まで触らせてしまいます。
さらに必要なのが停止条件です。エラーが出たら止める。想定外のファイル変更が必要になったら止める。複数リポジトリへ影響しそうなら止める。仕様が曖昧なら止める。人間の判断が必要になったら止める。この線を先に決めておかないと、AIは作業を進め続けます。そして、進んだあとで自分が確認できない量になって返ってきます。
並列運用で怖いのは、AIが動くことではありません。どのAIがどこまで動いていいのか、人間側が把握していないことです。目的、範囲、停止条件を分けておけば、少なくとも「このセッションは何をしているのか」を思い出す負担は減ります。逆に、ここを決めないまま数だけ増やすと、10個の作業が進んでいるのではなく、10個の曖昧な状態が増えていくだけになります。
やったこと・未確認・人間が見る点を必ず残す
もうひとつ必要だったのは、各セッションの最後に状態を残させることです。Claude Codeが何かを進めたら、そのまま次へ行くのではなく、必ず「やったこと」「未確認のこと」「人間が見る点」を残してもらう。これをしないと、戻ってきたときに自分がログを読み直して、最初から状態を復元することになります。
特に重要なのは、未確認のことです。AIは「修正しました」「確認しました」と返してきます。でも、その言葉だけでは、人間がどこまで信じていいのか分かりません。テストまで済んでいるのか。差分を見ただけなのか。想定外の変更がないかは未確認なのか。別ファイルへの影響は見ていないのか。ここが曖昧なままだと、完了しているように見えても、実際には判断待ちのまま残ります。
人間が見る点も、必ず分けて残す必要があります。どの差分を見るのか。どのログを見るのか。どの設定値を確認するのか。どの判断を人間が決めるのか。ここまで書かれていれば、画面に戻ったときにすぐ判断へ入れます。逆に、これがないと、まず「何を見るんだっけ」というところから始まります。
AIを並列で使うなら、作業ログは単なる記録ではありません。人間の脳を守るための外部メモです。やったこと、未確認、人間が見る点が残っていれば、状態を自分の頭だけで抱えなくて済みます。自分の脳を作業状態の置き場にしない。今回の失敗で、ここが一番大事だと分かりました。
まとめ
Claude Codeを10セッション同時に動かせば、生産性も10倍になる。最初は本気でそう考えていました。実際、画面のあちこちでAIが動き、調査、修正、記事整理、設定確認が同時に進んでいるように見えました。1日24時間しかない自分でも、10セッション並列で動かせば、1日240時間分の作業が進むように感じたのです。
でも、実際に増えたのは作業量だけではありませんでした。確認する量、判断する量、思い出す量、止めるべきか決める量も増えていました。AIは並列で走れます。でも、それを見て判断する自分の脳は並列になりません。ここを見落としたまま数だけ増やすと、作業が進むどころか、状態が混ざり、判断が荒くなり、うまく進んでいた作業まで壊してしまいます。
今回の失敗で分かったのは、AI時代の生産性は「AIを何個起動できるか」では決まらないということです。大事なのは、自分が管理できる状態の数です。セッションごとに目的、範囲、停止条件を分ける。やったこと、未確認、人間が見る点を残す。状態を自分の頭の中だけに置かない。そこまでやって、初めてAIの並列運用は力になります。
AI並列運用で増えるのは作業量だけではない
AIを並列で動かすと、作業量は確かに増えます。複数のClaude Codeが同時に動き、調査結果や修正案や記事構成が次々に返ってきます。画面を切り替えるたびに何かが進んでいるので、最初はかなり効率が上がったように見えます。
でも、AIが返してきたものは、そのまま成果になるわけではありません。人間が読んで、確認して、採用するか、止めるか、修正するかを判断する必要があります。つまり、AIを増やすほど、確認待ちも増えます。判断待ちも増えます。未確認の作業も増えます。
ここを見落とすと、AIを増やしたつもりが、未処理の山を増やしているだけになります。作業が進んでいるように見えても、自分が確認できていなければ成果としては確定していません。AI並列運用で増えるのは、作業量だけではなく、状態管理の量でもあります。
管理できる状態の数から並列数を決める
次に同じことをやるなら、いきなり10セッションは開きません。まず、自分が管理できる数から決めます。今このセッションは何をしているのか。どこまで進んだのか。何が未確認なのか。次に人間が判断する点はどこなのか。これをすぐ言えないなら、そのセッションはもう管理できていない状態です。
AIを何個動かせるかではなく、自分が何個まで状態を把握したまま見られるか。ここを基準にします。最初は2つか3つで十分です。1つは実装、1つは調査、1つはレビューというように役割を分け、目的、範囲、停止条件を明確にする。終わったら、やったこと、未確認、人間が見る点を必ず残す。
それを見て、まだ自分が余裕を持って判断できるなら、1つ増やす。逆に、少しでも混ざり始めたら減らす。この順番の方が安全です。AIは10倍働けます。でも、自分の脳は10倍になりません。だからこそ、AIを増やす前に、自分の脳に抱えさせる状態を減らす必要があります。




