

PDFやExcelをAIに渡しても、答えが浅かったり、ズレた内容で返ってきて困っていませんか。先に結論を書きます。AIに資料を読ませて使えるようにしたいなら、RAGやVectorDBという言葉に進む前に、手元の資料をAIが読める形に整える工程を済ませる方が、最初の一歩としては安全です。整理を飛ばして検索基盤だけ入れた状態では、AIの答えは改善しません。
RAGやVectorDBと言われても、正直わからないですよね。検索すると専門用語ばかりが並んでいて、自分の手元のPDFやExcelとどう関係するのかが見えにくいです。ちょっと自分でも整理してみると、これらは「整った資料を効率よくAIに渡すための仕組み」であって、整っていない資料を整える仕組みではないことが分かります。最初に手を付けるのは、検索基盤の検討ではなく、資料そのものの形を整える作業です。
この記事では、Markdown化・1テーマ1ファイル化・結論と理由の分離・顧客固有情報の除去という4つの条件を入口にして、AIに読ませやすい資料の作り方を整理します。続いて、読ませにくい資料の典型と、よくある失敗6種、そして「自分は今どの段階にいるのか」を判定するための段階別判断表 (Markdown整理 / RAG / VectorDB) まで通して扱います。手元の資料が散らばっていて止まっている方が、まず何から触ればよいかが見えるところまで持っていきます。
「保管」と「再利用可能な状態」は別物
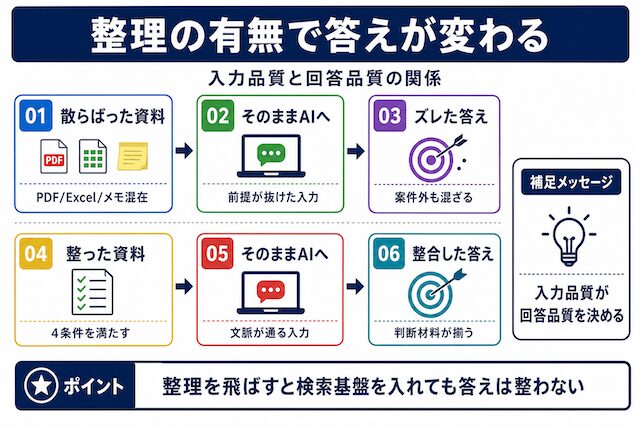
答えは、ファイルがあるかどうかではなく、後から読んで使える形になっているかで決まります。資料を保管しただけの状態と、AIが再利用できる状態は同じものではありません。
保管しただけの資料が止まる場面
設計書や議事録は、保存した直後は便利でも、半年後の別案件で開くと「なぜこうしたか」が思い出せません。判断理由が抜けた記録は、AIに渡しても同じ理由でズレた答えしか返ってきません。
クラウドストレージや社内共有フォルダにファイルを置くこと自体は、保管の作業として完結します。ただし、保管された状態のままでは、半年後の自分でも、別案件のメンバーでも、AIでも、判断の根拠を取り出せません。資料に書かれているのは結果だけで、その結果に至った前提・比較した選択肢・採用しなかった理由が抜け落ちているためです。
この上位の概念として、AIにおける記憶・継続性の設計を扱った AIの限界を超える設計とは何か──記憶と継続性の再定義 も関連解説として参照できます。資料整理はその設計の中で「最も具体的な施策レイヤ」にあたります。
AIが再利用できる状態の最低条件
AIが使える資料は、結論と理由の両方が読める形で残っているものです。1テーマ1ファイル化・結論と理由の分離・更新日・出典の4点が最低条件になります。
更新日と出典がない資料は、AIから見ると「いつ時点の話か」「どこから来た情報か」が判断できません。最低条件の4点を満たした状態は、人間が後から読み返すときにも有効で、結果としてAIの回答精度も底上げされます。
AIに読ませやすい資料の4条件
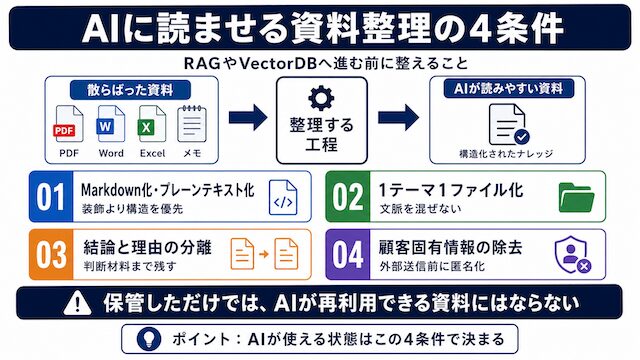
結論は、Markdown化・1テーマ1ファイル化・結論と理由の分離・顧客固有情報の除去の4点です。先にこの4点を満たしていれば、ChatGPTでもClaudeでも回答の精度は上がります。
Markdown化・プレーンテキスト化
読ませやすさの基本はプレーンテキストです。装飾Wordやスキャン画像PDFは、読み取り精度が落ちる前提で扱います。
Markdownは、見出し・箇条書き・コードブロックといった構造を、テキストだけで表現できる軽量な記法です。AI側から見ると、装飾コードや画像化された文字を解釈する負荷がなく、本文の構造をそのまま読み取れます。手元のWordやPowerPointは、可能であればコピーしてMarkdownへ書き出しておくと、後から複数のAIに渡し回すときの取り回しが楽になります。
1テーマ1ファイル化
1ファイルに複数テーマを混ぜると、AIがどの文脈で答えればよいか判断できません。テーマ単位で分け、ファイル名に内容を反映させます。
「議事録2026-05.md」のような月単位ファイルに、案件Aの仕様議論と案件Bの契約議論が混在していると、AIに「案件Aの仕様」を聞いた時点で、案件Bの記述まで参照されて答えが濁ります。1テーマにつき1ファイル、ファイル名はテーマがそのまま読み取れる粒度に揃えると、後から探すときも渡すときも誤参照が減ります。
結論と理由の分離
結論だけの記録は資産になりません。「なぜそうしたか」を必ず残してこそ、AIが別案件でも判断材料として使えます。
「APIをRESTで実装した」とだけ書かれた資料は、別案件で「GraphQLとRESTのどちらが妥当か」を相談されたAIにとって何の助けにもなりません。「APIをRESTで実装した。理由は、社内のクライアント側ライブラリが既にRESTを前提にしており、移行コストが見合わなかったため」のように、結論の隣に理由が残っている状態を作ります。書き手の頭の中にしかない判断材料を、明示的に文字にしておく工程です。
顧客固有情報の除去
クラウドAPIに送る前に、顧客名・案件名・個人名・社内固有名詞は伏字または削除します。一度送ったあとでは取り戻せない可能性があるためです。
ここで「顧客固有情報」と言われても、どこまでが対象か迷うところです。判断軸はシンプルで、その情報が外部に出た場合に契約・信頼・法令面で問題になり得るかを見ます。具体名を「顧客A」「製品X」のような代名詞に置き換えるだけでも、AIに渡す資料としての要件は満たせます。資料整理の段階で機械的に置換ルールを決めておくと、後の運用負荷が下がります。
AIに読ませにくい資料の典型
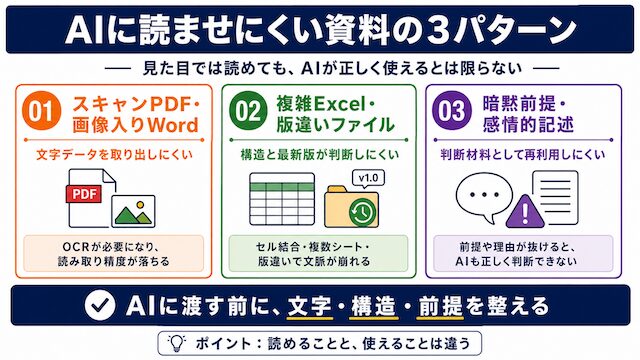
自分が普段渡しているPDFやExcelが対象か、迷うところではないでしょうか。読ませにくい資料には共通の型があり、先にこの型を知っておくと、AIに渡す前に分類できます。
スキャンPDFと装飾Wordの読み取り精度
スキャンPDFと画像入りWordは、文字データが入っていない、または取り出しにくい形で保存されています。Anthropic公式も「画像を含むWordはPDFに変換してから渡す」と案内しています。
紙の書類をスキャナで取り込んだPDFは、見た目は文字ですが、中身はページ全体が1枚の画像になっていることが多いです。AIから見ると、画像の中身を読み取る別工程 (OCR) が必要になり、読み取りの精度が落ちます。装飾の多いWordも、図形・テキストボックス・画像が入り組んでいると、本文の順序が崩れて読み取られる場合があります。
複雑Excelと版違いファイルの混乱
セル結合・複数シートのExcelや、「最終版v3改訂2.docx」のような版違いファイルは、AIにとって何が正かが判断できません。OpenAI File SearchはXLSXを先頭1000行のみで処理する仕様です。
セル結合が多用されたExcelは、人間の目では見出しと本文の対応が見えても、AI側から行列構造を読み取ろうとすると対応が崩れます。複数シートを跨いで参照しているExcelも、シート単位で渡された場合には文脈が抜けます。版違いファイルは、ファイル名の末尾を見ても「最終版v3改訂2_最終」のどれが本当の最新か分からないことが多く、AIにとっても人間にとっても判断不能です。
暗黙前提と感情的記述の混入
「Aシステムの仕様」とだけ書かれた資料や、「あいつが悪い」のような感情的記述は、判断材料になりません。前提が省略された資料は、AIにも読者にも届きません。
書き手にとっては当たり前の前提でも、明示されていない情報はAIには伝わりません。「Aシステム」が何を指すか、どのバージョンの話か、どの工程の話かが書かれていない資料は、AIにとっては固有名詞の羅列です。感情的な記述は、判断材料ではなく書き手の主観が混じった意見になっているため、AIが判断軸として使うと答えが偏ります。資料に残すのは、誰が読んでも同じ判断ができる範囲の事実と理由に絞ります。
よくある失敗とそれぞれの正しい入口
失敗の型は6つに集約できます。共通点は、整理工程を飛ばして道具に頼ろうとしたことです。
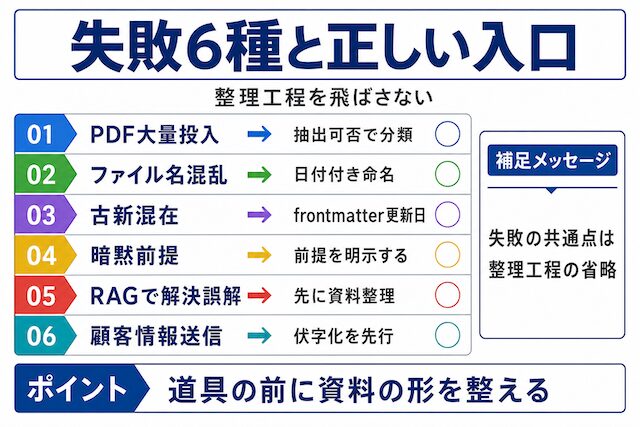
PDFの大量投入で起きること
とりあえずPDFを全部渡す運用は、スキャンPDFや版違いの混入で答えがズレる典型です。正しい入口は、テキスト抽出可否を確認してプレーンテキスト化できるものから整理することです。
PDFを大量に渡すと、AI側ではすべての文書を等しく参照しようとします。その中にスキャンPDFが1枚混ざっていれば、その箇所の読み取りに失敗します。版違いが3つ並んでいれば、最新版以外の記述も同じ重みで参照されます。先に「テキストとして抽出できるPDF」と「画像になっているPDF」を分けて、抽出できるものから順に整える方が、結果として総工数は短くなります。
ファイル名と古新混在の問題
「最終版v3改訂2.docx」という名前と古新混在は、AIが現在の正を判断できない最大の原因です。「YYYY-MM-DD_テーマ名.md」形式の命名規則と、frontmatterの更新日で防げます。
ここでfrontmatterと言われても、聞き慣れない方が多い言葉です。簡単に言うと、Markdownファイルの先頭に書く「このファイルの基本情報」のメモ欄で、更新日・タイトル・タグなどを数行で残しておく場所です。ファイル名に日付を入れ、frontmatterに更新日と出典を書いておくと、ファイル名だけでは見えなかった「いつの情報か」「どこから来た情報か」が、AIにも人間にも一目で読み取れるようになります。
「RAGを入れれば解決する」という誤解
RAGはハルシネーションを消しません。失敗モードが生成時から検索解釈時へ移動するだけで、資料品質が低ければ検索結果も低品質のままです。
RAGという言葉を初めて見ると、AIの答えが正確になる魔法の仕組みに見えます。ちょっと自分でも調べてみると、RAGは「関連する資料の断片だけを取り出してAIに渡す仕組み」で、渡される断片の品質には介入しません。整っていない資料を渡せば、整っていない断片が選ばれてAIの手元に届き、結果として答えは整いません。RAGを検討する前に、まず手元の資料の品質を整える工程が先になります。
Markdown整理 / RAG / VectorDB の段階別判断表
答えは、資料の規模と更新頻度で決まります。自分が今どの段階にいるかを判断表で確認してから道具を選ぶ順序が安全です。
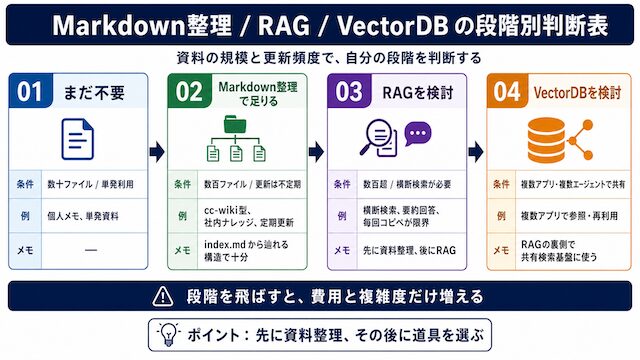
Markdown整理で足りる状態
結論は、数百ファイル規模で更新頻度が不定期なら、Markdownナレッジベースで足ります。BeProのcc-wikiもこの形で運用しており、index.mdから関連ページを辿る構造があれば、ベクトル検索なしでも自分のための知識ベースになります。
BePro社内ではcc-wikiという名前の小さな知識ベースを運用しています。構成は3層で、未整理の調査素材を置く raw/ ・整理済みのナレッジを置く wiki/ ・入口となる index.md の3つに分かれており、新しい情報は raw/ に入った後、整理工程を経て wiki/ に移され、最後に index.md から辿れる状態になります。個人や小規模事業で運用するbusiness-wiki型のナレッジベースは、この粒度から始めれば十分です。

この段階の続編として、整理した資料をAIのナレッジベースとして実際に使う方法は AIに過去の記憶を忘れさせない方法|LLMナレッジベースという考え方 で扱っています。
RAGを検討する状態
ファイル数が数百を超えてindex.md管理が破綻し、毎回のコピペが現実的でなくなった段階で初めてRAGの出番です。RAGは「関連する資料の断片だけを取り出してAIに渡す仕組み」のことで、整理が終わっていない資料に入れても効果は出ません。
RAGを入れる前に確認したいのは、入れようとしている資料が前章までの4条件 (Markdown化・1テーマ1ファイル化・結論と理由の分離・顧客固有情報の除去) を満たしているかどうかです。満たしていない資料に対してRAGを入れると、検索結果として返ってくる断片の品質が低いままになります。先に整理、後にRAG、の順序が崩れると失敗モードが検索側にずれるだけで、AIの回答品質は変わりません。
VectorDBを検討する状態
複数のアプリ・複数のエージェントが同じ検索を共有する段階で、VectorDBが現実的になります。VectorDBは「AIが意味で検索するための保管庫」にあたり、RAGの裏側で動くデータベースです。
VectorDBを入れた後に何が解決し、何が解決しないかを別の角度から見るには AIが記憶を持てない理由と「ベクトルDB」が抱える構造的限界を暴く を併読すると、自分の状況に当てはまるか判断しやすくなります。VectorDBは万能の記憶装置ではなく、検索の手段の1つです。整理が終わった資料に対して、複数のアプリやエージェントから同じ検索基盤を共有したい段階で初めて、現実的な選択肢になります。
関連記事
整理の続編・周辺領域として、以下の記事を併せて読むと、整理 → 運用 → 限界理解の動線が辿れます。
- AIに過去の記憶を忘れさせない方法|LLMナレッジベースという考え方 — Markdown整理で足りる段階を、ナレッジベースとして実装する続編
- AIが記憶を持てない理由と「ベクトルDB」が抱える構造的限界を暴く — VectorDBを入れた後に解決すること・残ることの整理
- ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある — 整理した資料を「どの形態のAIに渡すか」を整理する補助記事
- AIの限界を超える設計とは何か──記憶と継続性の再定義 — 資料整理の上位概念にあたる記憶・継続性設計の解説
まとめ
資料整理は保管ではなく、AIが再利用できる形へ変える作業です。RAGやVectorDBは、その整理が終わった後に検討する道具として位置づけるのが安全で、最初に手を付けるのはMarkdown化・1テーマ1ファイル化・結論と理由の分離・顧客情報除去の4点です。




