「プロセスの自動起動や監視って、複雑なスクリプトを書かないと無理だと思っていませんか?」
systemdを使えば、シェルスクリプトを組まずともプロセスの自動起動・再起動・ログ管理が簡単にできるようになります。これまで cron や watch、あるいは自作スクリプトで面倒な運用をしていた方には、目からウロコの運用方法です。
私がシステム監視を覚えた時代は init.d でした。シェルスクリプトでプロセス監視を組み、ログは /var/log/messages を tail で見張っていたものです。今や systemd によってそれらは抽象化され、ログすら journalctl という新しい手法に置き換わりました。
でも、「障害に気づけるかどうか」「それを通知できるかどうか」という本質は、何も変わっていません。
本記事ではsystemdの基本から設定ファイルの書き方、実行例まで体系的に整理して紹介していきます。
Linuxの基礎知識 🔵 プロセス・サービス系
📌 サービスを安定稼働させるためのプロセス管理と制御の基本
└─【Linuxの基礎知識】プロセス・サービス系でよくあるトラブルと解決の入口
├─ 【Linuxの基礎知識】プロセス管理はもうスクリプト不要?systemdの基本と自動監視設定
├─ 【Linuxの基礎知識】psコマンドの実践活用|プロセス管理の第一歩
├─ 【Linuxの基礎知識】kill / killall / timeoutの違いと正しい使い分け
├─ 【Linuxの基礎知識】カーネルの役割と起動プロセスをわかりやすく解説!
└─ 【Linuxの基礎知識】ファイルディスクリプタとulimitを理解する
systemdとは
systemdとは、Linuxにおける起動・プロセス・サービスの管理を一手に引き受ける初期化システムです。従来のSysVinitに代わって多くのLinuxディストリビューションで採用されており、プロセスの自動起動、異常時の自動再起動、ログ管理などの機能を統一的に提供します。複雑なシェルスクリプトを使わずに、サービスを安定的に管理できるのが最大の特徴です。
systemdの目的と背景
systemdが登場した背景には、従来のinitスクリプトによる起動処理の遅さや、依存関係の煩雑さ、非同期処理への非対応といった課題がありました。systemdはこれらの課題を解決し、次のような目的で開発されました。
| 目的 | 説明 |
|---|---|
| 高速な起動処理 | 依存関係の並列処理により、起動時間を短縮 |
| ユニット管理の統一 | サービス・ソケット・タイマーなどを統一的に管理 |
| ログの一元化 | journalctlコマンドによりログを集中管理 |
| 再起動制御 | プロセス異常時の自動再起動・再実行設定が可能 |
Linuxのシステム起動だけでなく、日常のサービス運用においても非常に有用な仕組みです。
既存スクリプトとの比較と利点
従来、プロセスの自動起動や監視、再起動などを実現するためには、cronや監視スクリプトを自作する必要がありました。しかし、systemdを活用することで、それらの運用スクリプトを簡素化できます。
以下に従来の方式との比較表を示します。
| 機能 | 従来スクリプト | systemd |
|---|---|---|
| 起動順制御 | 依存関係を明示的にスクリプトで記述 | After, Requires で明確に記述 |
| 自動起動 | rc.localやcronに記述 | Enable設定で簡単に制御 |
| 異常時の再起動 | trapやループを用いたスクリプト | Restart=always の指定のみ |
| ログ管理 | 標準出力やログローテート設定が必要 | journalctlで一元管理 |
たとえば、これまで再起動監視用のスクリプトを自作していた場合でも、systemdであればユニットファイル1つで代替できます。
Restart=always
RestartSec=10
このように、systemdを活用することで、保守性と可読性の高いプロセス運用が可能になります。
systemdの基本設計と仕様
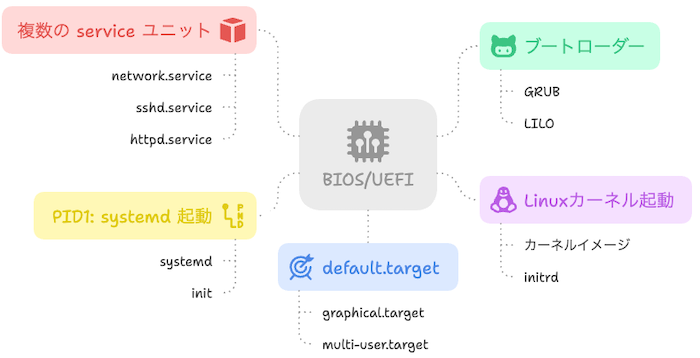
Linuxのサービス管理や起動シーケンスに関わる仕組みとして、systemdは今やほとんどのディストリビューションで標準採用されています。しかし、その仕組みや設計思想を理解せずに使っている方も多いのではないでしょうか。
ここでは、systemdがどういう設計になっており、どのような仕組みで動作しているのかを、具体的な構造やディレクトリ配置を通じて丁寧に解説します。
ユニットファイルの構造
ユニットファイルはsystemdでプロセスやサービスを管理するための設定ファイルであり、明確なセクション構造を持っています。
以下のような構造で定義されます。
[Unit] # ユニットの定義セクション
Description=説明文 # サービスの説明(自由記述)
After=network.target # ネットワーク起動後にこのサービスを起動
[Service] # 実行内容の定義セクション
Type=simple # 単純なプロセス(親がフォアグラウンドで動作)
ExecStart=/usr/bin/sample_command.sh # 実行するコマンド(絶対パス)
Restart=always # プロセスが終了したら常に再起動
[Install] # systemctl enable 時の挙動
WantedBy=multi-user.target # 通常のマルチユーザモードで起動対象に含める
各セクションの意味は以下のとおりです。
| セクション | 概要 |
|---|---|
| [Unit] | ユニットの基本情報や依存関係を定義します |
| [Service] | 起動コマンドや再起動ポリシーなど、実行に関する情報を設定します |
| [Install] | サービスの有効化(enable)時に、どのターゲットに含めるかを指定します |
配置ディレクトリと読み込みタイミング
ユニットファイルは複数のディレクトリに配置され、読み込みの優先順位や上書きの仕組みが明確に設計されています。
代表的な配置場所は以下のとおりです。
【systemd ユニットファイルの設置先と使い分け】
| パス | 用途・説明 | 誰向け |
|---|---|---|
| /etc/systemd/system/ | ユーザが独自にユニットファイルを配置・上書きする場所(最も重要) | 管理者(root) |
| /etc/systemd/system/ xxxxx.target.wants/ | targetに紐づくサービスの自動起動リンクを入れる場所 | 管理者 |
| ~/.config/systemd/user/ | 一般ユーザーが使うユーザーユニット用の保存先 | 一般ユーザー |
| /lib/systemd/system/ | OSやパッケージ側が提供するデフォルトのユニットファイル置き場 | 読むだけ。上書きNG |
| /run/systemd/system/ | 一時的なユニットの置き場。再起動で消える | 一時作業者用 |
dnf を使ってインストールしたアプリの systemd ユニットファイルは、通常 /usr/lib/systemd/system に配置されます。
自作サービスを作る場合
- 以下のパスに .service を作成
→ /etc/systemd/system/myapp.service - 起動テスト
systemctl start myapp - 自動起動設定
systemctl enable myapp
→/etc/systemd/system/multi-user.target.wants/myapp.serviceにシンボリックリンクが作られる
systemdのユニットファイルは、通常 systemctl daemon-reload によって再読み込みされます。これはユニットファイルの編集内容を反映させるために必要です。
systemctl daemon-reload
一方、systemd自体のバイナリを再読み込みして構成全体を再初期化するには systemctl daemon-reexec を使用します。これはごく一部の特殊ケース(例:systemdのバージョンアップ時など)に限られます。
systemctl daemon-reexe
systemctlの主なコマンド一覧
systemdの操作は systemctl コマンドで統一されており、サービスの起動・停止だけでなく、有効化、状態確認、ログ表示など多くの操作が可能です。
代表的なコマンドを以下にまとめます。
| コマンド | 用途 |
|---|---|
| systemctl start サービス名 | サービスを起動します |
| systemctl stop サービス名 | サービスを停止します |
| systemctl restart サービス名 | サービスを再起動します |
| systemctl enable サービス名 | 起動時に自動起動するよう設定します |
| systemctl disable サービス名 | 起動時の自動起動設定を無効にします |
| systemctl status サービス名 | サービスの状態を確認します |
| journalctl -u サービス名 | サービスごとのログを確認します |
例)httpd起動
systemctl start httpd.service
実装例と設定ファイルの書き方
systemdサービスは単なる起動・停止の仕組みではありません。運用現場では「どう実行するか」「どのように使い回すか」が重要です。
たとえば「プロセスが落ちたら即復旧」「夜間バッチの自動実行」「複数サービスの依存関係制御」など、systemdの柔軟な仕組みを理解しておくことで、あなたのLinux運用スキルは確実に一段レベルアップします。
以下では、用途に応じて選択できる代表的な4つのパターンを紹介します。
サービスユニットの作成例
ユニットファイルとは、systemdが管理するサービスの設定ファイルです。以下に、シェルスクリプトを監視対象とするサービスユニットの基本的な書き方を示します。
[Unit]
Description=Tomcat Web Application Server # systemctl status などで表示される説明文
After=network.target # ネットワークが使えるようになってから起動
[Service]
Type=simple # 実行中と判断する方法
ExecStart=/opt/tomcat/bin/startup.sh # 実行するコマンド
ExecStop=/opt/tomcat/bin/shutdown.sh # 終了するコマンド
Restart=always # 異常時に自動で再起動する
RestartSec=5 # 再起動までの待ち時間(秒)
StandardOutput=journal # stdoutをjournaldに記録
StandardError=journal # stderrもjournaldに記録
SyslogIdentifier=tomcat # journalctlで識別・抽出しやすくする
[Install]
WantedBy=multi-user.target # 通常の起動モードで有効化
この例では、tomcatをサービスとして登録し、異常終了時には自動的に再起動されるよう設定しています。
再起動までの待機時間(RestartSec)の意味と必要性
プロセスが異常終了した際、すぐに再起動すれば良いと思われがちですが、RestartSec によって数秒の待機時間を設けるのには明確な理由があります。
- 無限クラッシュループを防止する
アプリが即死する状態で `RestartSec=0` にすると、起動 → 異常終了 → 再起動を1秒間に何十回も繰り返す「暴走状態」に陥る危険があります。これによりCPU使用率の急上昇、ログの異常肥大、システム全体の不安定化を招く可能性があります。 - 外部リソースの復旧を待つ
アプリがネットワーク障害やDBダウンなど外部要因で落ちた場合、すぐに再起動しても同じ原因で再びクラッシュする可能性があります。`RestartSec=5` など数秒の待機を設けることで、外部の回復を待つ猶予が得られます。
このような理由から、たとえ安定したアプリでも RestartSec=1 など最低限の待機を設けるのが推奨されています。
自動起動とリスタートの設定例
サービスの安定運用には、自動起動とリスタート設定が欠かせません。systemdではRestartやRestartSecを指定することで簡単に実現できます。
| パラメータ | 意味 | 推奨設定 |
|---|---|---|
| Restart | 終了後の再起動動作 | always |
| RestartSec | 再起動までの待機時間(秒) | 5 |
| StartLimitIntervalSec | 再起動回数の制限時間 | 60 |
| StartLimitBurst | 指定時間内の再起動上限 | 5 |
これらの設定を組み合わせることで、短時間での連続クラッシュによる暴走を防ぐことができます。
ログ出力とjournalctlの連携
systemdでは標準でjournalctlと連携してログを確認することができます。ユニットファイル内に以下の記述を加えることで、標準出力・標準エラー出力をjournalに転送できます。
StandardOutput=journal
StandardError=journal
実行後のログ確認は次のコマンドで行います。
journalctl -u tomcat.service -n 50 --no-pager
このコマンドは、systemdの管理下にあるサービス tomcat.service のログを簡潔に表示するためのものです。
- -u tomcat.service:指定したサービス単体のログに絞って表示できる
- -n 50:最新の50件だけを表示し、無駄なスクロールが不要になる
- --no-pager:lessなどのページャーを使わず、そのまま画面に全出力してくれるのでパイプ処理やログ検索に使いやすい
このように、スクリプトの標準出力・標準エラーをそのままjournalctl経由で取得できるため、ログ監視も一元化できます。また、日付やPID、レベルなどでのフィルタも柔軟に行えるため、従来のsyslog連携よりも扱いやすくなっています。

systemdによるプロセス監視とログ通知の仕組み
systemdでプロセスの再起動を自動化しても、障害が発生したことを人間が知る手段がなければ意味がありません。特に、旧来からメール通知などで障害を検知していた環境では、ログの出力先と通知方法が一貫していることが非常に重要です。
そこで必要になるのが、以下の3つのポイントです。
| 目的 | 設定内容 | 備考 |
|---|---|---|
| systemdログをsyslogへ転送する | /etc/systemd/journald.conf ForwardToSyslog=yes | 再起動後に systemd-journald を再起動 |
| ログを識別しやすくする | SyslogIdentifier=tomcat | grepや通知スクリプトで絞り込み可能 |
| rsyslog側でログを受け取る | rsyslogサービスを起動し /var/log/messagesに記録する設定 | rsyslogがsystemdログを処理する役割 |
systemdログにおける「障害の兆候」の実際の出力例
実際に systemctl status や journalctl -u tomcat.service を確認すると、異常終了や再起動が発生したときは、次のようなログが記録されます。
tomcat[1234]: プロセスが異常終了しました
systemd[1]: tomcat.service: Main process exited, code=exited, status=1/FAILURE
systemd[1]: tomcat.service: Failed with result 'exit-code'.
systemd[1]: tomcat.service: Scheduled restart job, restart counter is 1.
これらを通知に使うには、以下をgrep対象にします。
ポイント
- "Failed with result"
- "Main process exited"
- "Scheduled restart job"
- "status=1/FAILURE"
- "result='exit-code'"
- "tomcat.service: failed"(←もっとも汎用的)
journalctl -u tomcat.service -n 100 | grep -Ei "failed|exit|restart|status="
あるいは:
journalctl SYSLOG_IDENTIFIER=tomcat | grep -Ei "failed|exit|status="
かつては /var/log/messages を grep して障害通知するのが定番でした。しかし、systemdの登場により、ログの流れそのものが変化しました。現在は journald を中核とする「journalctl」でログを扱うのが基本です。/var/log/messages も併用は可能ですが、あくまで補助的な位置づけとなります。
・企業システムや金融インフラなどでは、今でも rsyslog 前提の監査設計は多いです
・監視ツールも /var/log/messages を前提にしているものはまだ多数あります
・しかし Red Hat や Debian、Ubuntu などの公式ガイドでは journalctl が前提になっています
実行パターンと活用方法
systemdサービスは単なる起動・停止の仕組みではありません。運用現場では「どう実行するか」「どのように使い回すか」が重要です。
たとえば「プロセスが落ちたら即復旧」「夜間バッチの自動実行」「複数サービスの依存関係制御」など、systemdの柔軟な仕組みを理解しておくことで、あなたのLinux運用スキルは確実に一段レベルアップします。
以下では、代表的な3つの活用パターンについて、実際の運用シーンを交えて解説していきます。
デーモンプロセスの監視に使う
常駐型のシェルスクリプトやデーモンプロセスを systemd で起動管理することで、落ちた場合の自動再起動やログ連携が可能になります。
この用途では、Restart=always などのオプションが非常に効果的です。
[Service]
Type=simple
ExecStart=/home/user/scripts/monitor_script.sh
Restart=always
RestartSec=5s
この設定により、監視スクリプトが異常終了しても systemd が即座に再起動してくれます。特にログ監視やポート監視系の処理に向いています。
アプリケーションプロセスの常時監視に使う
Tomcatのようなアプリケーションは、systemdのサービスユニットに登録することで、異常終了時に自動で再起動できます。
[Service]
Type=forking
ExecStart=/opt/tomcat/bin/startup.sh
ExecStop=/opt/tomcat/bin/shutdown.sh
Restart=always
RestartSec=5
StandardOutput=journal
StandardError=journal
SyslogIdentifier=tomcat
この設定により、Tomcatが異常終了してもsystemdが即座に再起動処理を行います。スクリプトは不要です。
タイマーと連携して定期実行に使う
systemd は cron に似た Timer 機能も提供しています。これにより、任意のスクリプトを柔軟な間隔で実行することが可能です。たとえば、ログの定期バックアップ処理を毎日深夜に実行する場合、以下のように設定します。
| ファイル | 目的 |
|---|---|
| /etc/systemd/system/log_backup.service | バックアップスクリプトの実行設定 |
| /etc/systemd/system/log_backup.timer | タイミング設定(例:毎日 02:00) |
[Timer]
OnCalendar=*-*-* 02:00:00
Persistent=true
このようにタイマーを使えば、cron に依存しない柔軟なジョブ実行が可能になります。
複数プロセスの一元管理に活用する
アプリケーションやシステムによっては、1つのサービスだけで完結せず、複数のプロセスが連携して動作する構成になることがあります。
こうしたケースでは、それぞれのサービスを個別に操作するのではなく、グループ化して一括管理することで運用効率が大きく向上します。systemdでは .target ファイルを用いることで、複数の .service をまとめて管理できます。
たとえば、以下のような構成を考えてみます。
| ユニット名 | 役割 |
|---|---|
| db.service | PostgreSQLプロセス起動 |
| web.service | Tomcatアプリケーション起動 |
| myapp.target | 上記2つをまとめて起動 |
.target ファイルは、いわば「サービスグループ」のようなもので、以下のように記述します。
[Unit]
Description=MyApp Group Start
Description=MyApp Group Start. # 説明
Requires=db.service # サービスファイル
Requires=web.service # サービスファイル
After=db.service # 実行順
After=web.service. # 実行順
[Install]
WantedBy=multi-user.target
この例では myapp.target というグループを定義しており、db.service と web.service をこのターゲットファイルにまとめています。
.targetファイルの作成と配置
- /etc/systemd/system/myapp.target を作る(中身は [Unit] だけでOK)
- /etc/systemd/system/myapp.target.wants/ に、
自動起動させたい .service へのシンボリックリンクを置く
この .target ファイルを myapp.target として保存しておけば、下記の1行だけで、2つのサービスファイルが定義した順序に従って一括起動されます。
systemctl start myapp.target
同様に、停止や再起動も .target 単位で操作可能です。
この仕組みは、以下のようなケースで特に有効です。
- システム再起動時に、一括して必要なサービス群を立ち上げる
- アプリケーション単位でサービスをまとめてメンテナンス対象にする
- Dev/Prodなど環境単位で構成を切り替える
つまり、.target は「サービスの起動順と依存関係を整理し、実行を簡潔にまとめる」ための中核機能です。
次のおすすめ記事

実践環境を整える
ここまで学んだ知識を実際に試すには、Linuxを動かす環境が必要です。手軽に始めるならVPSを利用するのがおすすめです。
→ VPS徹底比較!ConoHa・さくら・Xserverの選び方

VPSを利用してLinux環境を準備したら、実際の設定は下記の記事が参考になります。
→ VPSに開発環境を自動構築する方法|Apache+Tomcat+PostgreSQL