

あなたは「突然システムが応答しなくなった」とき、原因をどうやって突き止めますか?
サーバーが高負荷状態になると、アプリケーションがファイルやネットワーク接続を大量に扱い、限界を超えた瞬間に動作が止まってしまうことがあります。
そんなとき、単に再起動して終わりにするのではなく「何が制限に引っかかっているのか」を見抜けるのがエンジニアの腕の見せ所です。
Linuxの世界では、すべてのリソースは「ファイルディスクリプタ」という番号で管理され、開ける数には上限があります。
その上限を確認・制御できるのが「ulimit」です。では、どのコマンドを打てば現在の状態を知り、どうすれば必要な調整ができるのか――この記事ではその具体的な方法を解説します。
Linuxの基礎知識 🔵 プロセス・サービス系
📌 サービスを安定稼働させるためのプロセス管理と制御の基本
└─【Linuxの基礎知識】プロセス・サービス系でよくあるトラブルと解決の入口
├─ 【Linuxの基礎知識】プロセス管理はもうスクリプト不要?systemdの基本と自動監視設定
├─ 【Linuxの基礎知識】psコマンドの実践活用|プロセス管理の第一歩
├─ 【Linuxの基礎知識】kill / killall / timeoutの違いと正しい使い分け
├─ 【Linuxの基礎知識】カーネルの役割と起動プロセスをわかりやすく解説!
└─ 【Linuxの基礎知識】ファイルディスクリプタとulimitを理解する
ファイルディスクリプタの基本
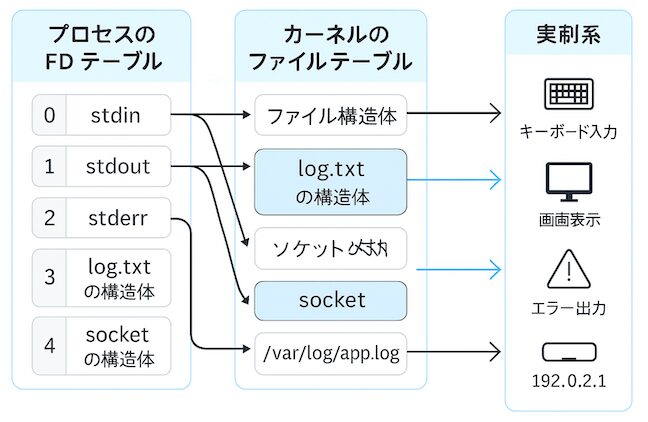
Linuxではプロセスが利用するリソースは「ファイル」として扱われます。
標準入力や標準出力、ソケットなども含めて、すべては「ファイルディスクリプタ」という番号で管理されます。これを理解すると、プロセスがどのリソースを利用しているかを確認でき、トラブルシュートの役に立ちます。

ファイルディスクリプタとは?
ファイルディスクリプタとは、プロセスが開いたファイルやソケットを識別するために割り当てられる番号です。
アプリケーションは直接ファイルを扱うのではなく、OSが管理する「ファイルテーブル」と呼ばれる仕組みを介して入出力を行います。このときアプリケーションは、対象を識別するための番号=ファイルディスクリプタを指定します。
例えば標準入力は0、標準出力は1、標準エラーは2という番号が予約されており、それ以降の番号(3以降)が通常のファイルやソケット、パイプに割り当てられます。
つまりファイルディスクリプタは「アプリケーションと実際のリソースを紐づけるための番号」であり、アプリケーションは番号を通じてOSに処理を依頼するだけで、対象がファイルでもソケットでも同じように扱えるのです。
Linuxでは「すべてはファイル」という思想のもと、標準入出力も同じ仕組みで管理されます。 現在のシェルが利用しているファイルディスクリプタを確認するには次のコマンドを実行します。
ls -l /proc/$$/fd 【出力例】
lrwx------ 1 user user 64 9月 5 12:00 0 -> /dev/pts/0
lrwx------ 1 user user 64 9月 5 12:00 1 -> /dev/pts/0
lrwx------ 1 user user 64 9月 5 12:00 2 -> /dev/pts/0
管理対象と種類(標準入力・標準出力・標準エラー)
ファイルディスクリプタの代表的なものは次の3つです。
| 番号 | 名称 | 説明 |
|---|---|---|
| 0 | 標準入力 (stdin) | キーボードなどからの入力を受け付ける |
| 1 | 標準出力 (stdout) | 通常の出力結果を表示する |
| 2 | 標準エラー (stderr) | エラーメッセージを表示する |
これらをリダイレクトすることで、通常のログとエラーログを分けることができます。
ls /notfound > out.log 2> err.log
この場合、通常の出力はout.logに、エラーはerr.logに記録されます。
アプリケーションとファイルが紐づく仕組み
ファイルディスクリプタ(FD)は「単なる番号」という説明をよく見かけますが、実際にはそれだけでは不十分です。
実体は、アプリケーションとファイルやソケット、パイプといった入出力リソースをつなぐための「橋渡しの仕組み」です。この仕組みを理解しないと、「なぜ番号だけで動作するのか」「なぜ無限にFDを増やせないのか」が曖昧なままになります。
ここでは、open() の呼び出しから inode にアクセスするまでの流れを、できるだけ丁寧に追って解説します。
プロセスごとのファイルディスクリプタテーブル
まず前提として、UNIX系OSでは プロセスごとに独立した「ファイルディスクリプタテーブル」 を持っています。
[プロセスのFDテーブル] [カーネルのファイルテーブル] [実リソース]
0 ──→ stdin ───────────────→ キーボード入力
1 ──→ stdout ───────────────→ 画面表示
2 ──→ stderr ───────────────→ エラー出力
※ここで記載している「APP1」「APP2」といった表現は、ExcelやWord、Webサーバといったアプリケーション(プロセス)を例示的に指しています。実際のLinux上では、それぞれのアプリケーションごとに独立したプロセスが動作し、そのプロセス単位でファイルディスクリプタテーブルが用意されます。
このテーブルは単なる配列のような構造で、スロット番号が 0,1,2,… と振られています。
アプリケーションから見えるのは、あくまで「ファイルディスクリプタテーブル」に並んだ番号だけです。APP1の例では、スロット3に「オープンファイルテーブル #17」という参照が登録されているため、アプリケーションは単純に「FD=3に書き込む」と指定するだけで済みます。しかし、FD=3が実際にどのファイルを指しているのかは、アプリケーション自身は知りません。
| テーブル | 番号 / スロット | 格納内容 |
|---|---|---|
| APP1のファイルディスクリプタテーブル | 0 | → オープンファイルテーブル #5 |
| 1 | → オープンファイルテーブル #6 | |
| 2 | → オープンファイルテーブル #7 | |
| 🈳 | 🈳 | |
| カーネルのオープンファイルテーブル | #5 | inode 11 : キーボード(標準入力) |
| #6 | inode 12 : 画面(標準出力) | |
| #7 | inode 13 : エラーデバイス(標準エラー) | |
| 🈳 | 🈳 |
実際の中身を決めているのは、カーネルが管理する「オープンファイルテーブル」です。この表はシステム全体で共有されており、各エントリには「inode番号」「アクセスモード」「現在の読み書き位置」「参照カウント」といった詳細情報が格納されています。APP1の例では、オープンファイルテーブル #17 が inode 255 を参照しており、そのinodeは /var/log/app.log という実ファイルを表しています。
さらに奥には inode が存在します。inode にはファイルの所有者、パーミッション、サイズ、ディスク上のブロック位置など、ファイル本体に関する情報が記録されています。最終的に「FD=3 → オープンファイルテーブル #17 → inode 255 → /var/log/app.log」という流れで、アプリケーションと実ファイルが結び付けられているのです。
言い換えれば、ファイルディスクリプタテーブルはアプリケーション側の「しおり番号」、オープンファイルテーブルはカーネル側の「索引カード」、inode は「本の実物」という関係になっています。アプリケーションはしおり番号だけを操作しますが、カーネルが裏で索引カードを引き、最終的に本そのものへアクセスすることで、正しくファイル操作が行われる仕組みになっているのです。
最初の3つは必ず予約されており、FD=0が標準入力、FD=1が標準出力、FD=2が標準エラー出力です。したがってユーザーがファイルを開いたときに最初に割り当てられる番号はFD=3から始まるのが一般的です。
open() 呼び出しとファイルテーブル
実際に、アプリケーションが「log.txt」というファイルを書き込みモードで開くケースを考えましょう。
アプリケーションは open("log.txt", O_WRONLY) というシステムコールを呼び出します。この時点でアプリケーション自身はファイルの中身やinodeを直接扱っているわけではありません。システムコールを経由して、OSカーネルに「log.txtを開いて欲しい」と依頼しているのです。
ファイルテーブルのエントリ
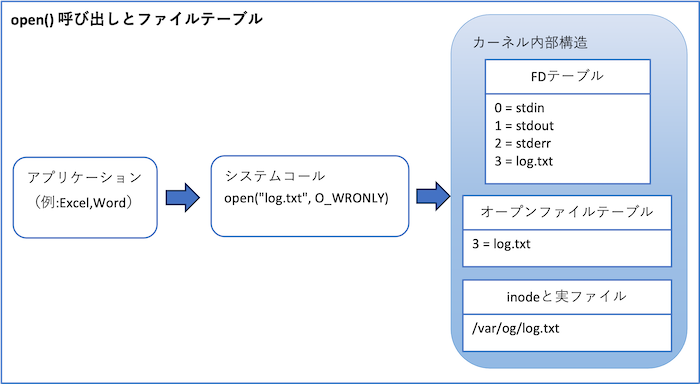
カーネルはまず ファイルテーブル に新しいエントリを作成します。ファイルテーブルはカーネル内部で共有される構造体群で、ここにファイルの詳細情報が格納されます。
例えば、対象となるinode番号(どのファイルかを示す識別子)、アクセスモード(読み込み専用、書き込み専用、追記など)、現在の読み書き位置を示すファイルオフセット、そしてこのファイルを指しているFDの数を示す参照カウントなどです。
つまりファイルテーブルは「このファイルをどう扱うか」の状態管理を担っています。
ファイルディスクリプタテーブルへの割り当て
ファイルテーブルのエントリが準備できると、次にカーネルは呼び出したプロセス固有の ファイルディスクリプタテーブル を参照します。
そして「次に空いているスロット」を探し出し、そこに「このファイルテーブルを指す参照」を格納します。結果として、このプロセスのFD=3に「log.txtを開いたファイルテーブルへのポインタ」が登録されます。
| テーブル | 番号 / スロット | 格納内容 |
|---|---|---|
| APP1のファイルディスクリプタテーブル | 0 | → オープンファイルテーブル #5 |
| 1 | → オープンファイルテーブル #6 | |
| 2 | → オープンファイルテーブル #7 | |
| 3 | → オープンファイルテーブル #17 | |
| カーネルのオープンファイルテーブル | #5 | inode 11 : キーボード(標準入力) |
| #6 | inode 12 : 画面(標準出力) | |
| #7 | inode 13 : エラーデバイス(標準エラー) | |
| #17 | inode 255 : /var/log/app.log |
アプリケーションからの利用
この仕組みによって、アプリケーションは以降 write(fd, "message", 7) のように「fd=3」を指定するだけでログに書き込めるようになります。
カーネルは「このプロセスのFD=3がどのファイルテーブルを指しているか」を参照し、そこからinodeを辿って最終的にディスク上の log.txt にアクセスするのです。
アプリケーションから見ると、あたかも「番号に書き込んだらファイルに届いた」ように見えますが、裏側では「プロセスごとのFDテーブル → カーネルのファイルテーブル → inode」という多段階の橋渡しが行われています。
複数プロセスによる同一ファイルの利用
さらに重要なのは、プロセスごとにFDテーブルが独立しているという点です。たとえばAPP1とAPP2が同時に open("log.txt") を呼び出した場合を考えてみます。
[APP1のFDテーブル]
0 → stdin ----------------→ キーボード入力
1 → stdout ----------------→ 画面表示
2 → stderr ----------------→ エラーメッセージ
3 → log.txt参照 ------------→ /var/log/app.log
[APP2のFDテーブル]
0 → stdin ----------------→ キーボード入力
1 → stdout ----------------→ 画面表示
2 → stderr ----------------→ エラーメッセージ
3 → log.txt参照 ------------→ /var/log/app.log
APP1のFD=3には log.txt を指すファイルテーブルが登録され、APP2のFD=3にも log.txt を指す別の参照が登録されます。しかし両者のFD=3は同じ「3番」という数字でも、全く別のテーブル内スロットなので混ざることはありません。
つまり「FD=3」という表現は「APP1の3番スロット」や「APP2の3番スロット」という文脈依存の番号に過ぎないのです。
inodeとの関係

ここでinodeとの関係について触れておきましょう。ファイルテーブルのエントリはinodeを直接参照しています。inodeとはファイルシステム内で「ファイルの本体を示す構造体」で、所有者、パーミッション、サイズ、ディスク上のブロック配置などの情報が記録されています。

最終的な紐付けの流れ
したがって最終的な流れは「FD番号 → プロセスのFDテーブル → カーネルのファイルテーブル → inode」という四段階の紐付けです。この構造があるからこそ、OSは複数のプロセスから同時にアクセスされてもリソースを正しく管理できます。
参照カウントの役割
また、参照カウントも重要な役割を果たします。同じファイルが複数のFDから開かれている場合、ファイルテーブルの参照カウントが増え、全てのFDが閉じられた時点で初めてファイルがクローズされます。
これにより「一方のプロセスがclose()したから他方のプロセスが使えなくなった」といった矛盾が発生しません。
まとめると、ファイルディスクリプタは「単なる番号」ではなく、プロセスごとのFDテーブルからカーネル内部のファイルテーブルを経由してinodeに辿り着くための参照キーです。
番号を通じてアクセスすることで、アプリケーションは複雑なカーネル内部の管理を意識することなく「3番に書き込む」といった単純な操作でファイルやソケットを利用できます。
そしてこの仕組みによって、複数のプロセスが同時に異なるファイルを扱ったり、同じファイルを同時に開いたりしても、OSが正しくリソースを分離・共有できるのです。
利用するメリットと制約
ファイルディスクリプタを理解すると、アプリケーションがどのリソースを使っているのかを把握でき、障害時の切り分けに役立ちます。
ただし、同時に利用できる数には制限があり、この制限を超えると「Too many open files」といったエラーが発生します。この上限を制御するのがulimitです。
ulimitの基本
Linuxではプロセスが利用できるリソースには制限が設けられています。
その制限を確認したり一時的に変更したりするために利用されるのが「ulimit」です。システムの安定性やセキュリティを守るために重要な仕組みであり、アプリケーションの動作に直接影響を与えるため理解が欠かせません。
ここではulimitの基本的な概念と役割を解説します。
ulimitとは?
Linuxでは、プロセスが無制限にリソースを消費するとシステム全体が停止してしまう危険があります。そこでシェルには「このユーザーは同時に何個までファイルを開ける」「このプロセスはどれだけのメモリを使える」といった制限をかける仕組みが組み込まれています。その制御を行うのがulimitです。
例えば次のコマンドで、現在のユーザーが同時に開けるファイル数の上限を確認できます。
ulimit -n
【出力例】
1024
これにより「なぜサーバーが接続数を捌けなくなったのか」「アプリケーションが急に落ちる原因は何か」といったトラブルの切り分けに役立てることができます。
確認できる制限項目
ulimitでは確認できる制限項目が複数用意されており、オプションを指定して確認することができます。代表的なものを以下にまとめます。
| オプション | 対象リソース | 説明 |
|---|---|---|
| -n | ファイルディスクリプタ数 | 同時に開けるファイル数の上限 |
| -u | プロセス数 | 同一ユーザーが生成できるプロセス数 |
| -c | コアファイルサイズ | コアダンプファイルの最大サイズ |
| -v | 仮想メモリサイズ | 利用できる仮想メモリの最大値 |
例えばプロセス数の上限を確認するには次のように入力します。
ulimit -u
【出力例】
768
この結果から、同一ユーザーが同時に768個までのプロセスを生成できることがわかります。
ファイルディスクリプタ数の制限が意味すること
ulimitで表示される「open files」の値は、プロセスが同時に開けるファイルやソケットの数を表します。
例えば値が1024の場合、そのプロセスは最大1024個のファイルやネットワーク接続しか扱えません。この制限は実際の運用に大きく影響します。
ファイルディスクリプタ数の制限例
- Webサーバーであれば同時接続数が1024を超えると新しい接続を受け付けられなくなります。
- データベースサーバーではクライアントの接続数が1024以上になると接続エラーが発生します。
- アプリケーションがログを大量に出力する場合も、同時に開くファイル数が上限に達すると新しいログファイルを開けなくなります。
つまり「1024」という数値を確認することは、システムがどの程度の負荷に耐えられるのかを把握する上で重要です。
もしアプリケーションがより多くの接続やファイルを必要とするなら、この制限値を調整することで安定稼働につなげることができます。
ファイルディスクリプタとulimitの関係性
Linuxのプロセスは、ファイルやソケットを開くたびにファイルディスクリプタを1つ消費します。
例えば、Webサーバーが100人のユーザーから同時にアクセスを受ければ、少なくとも100個のファイルディスクリプタが必要になります。
ここで効いてくるのがulimitです。
ulimitで設定されている「open files」の値が1024であれば、最大1024個までファイルディスクリプタを利用できます。
したがって100人程度のアクセスであれば問題なく処理できます。仮に、もし1000人規模のアクセスが集中すると見込まれる場合は、1024では上限に近づき、新規接続を受け付けられなくなる可能性があります。
例えば ulimit -n の結果が1024なら、そのプロセスは最大で1024個までしかファイルディスクリプタを使えません。
つまり、1025人目の接続が来たときには新しいファイルディスクリプタを確保できず、「Too many open files」というエラーが発生します。
このように、ファイルディスクリプタは「実際にリソースを使う番号」であり、ulimitは「その番号をいくつまで割り当ててよいかを決める上限値」を担っています。
両者は独立した概念ですが、現場でシステムが動作できる範囲を決めるうえで密接に結びついています。
ulimitの導入と利用方法
ulimitはLinuxの標準機能として提供されており、追加のパッケージを導入しなくても利用できます。
ただし、シェルの種類やディストリビューションによって挙動や設定方法が異なるため、環境ごとの差を理解しておくことが大切です。
ここではパッケージの有無や環境依存性の確認方法、基本的な使い方、制限値の変更方法について解説します。
パッケージの確認と環境依存性
ulimitは外部コマンドではなく、bashやzshといったシェルに組み込まれている機能です。そのため追加パッケージのインストールは不要です。ただし、利用しているシェルによってサポートしているオプションが異なる場合があります。
現在利用中のシェルを確認するには次のコマンドを実行します。
echo $SHELL
【出力例】
/bin/bash
この結果がbashであれば、bash組み込みのulimitコマンドを利用していることがわかります。zshなどを利用している場合も同様にシェル組み込みコマンドとして提供されます。
基本的な使い方(現在の制限確認)
ulimitは現在のシェル環境におけるリソース制限を確認するのに使えます。全体の制限状況を確認するには次のコマンドを実行します。
ulimit -a
【出力例】
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
max locked memory (kbytes, -l) 65536
open files (-n) 1024
max user processes (-u) 768
このように、ファイルサイズや利用できるプロセス数など複数の制限項目を一覧で確認できます。
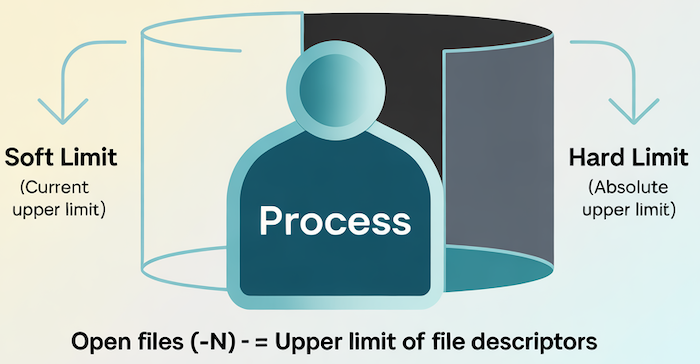
制限値の変更方法(soft limitとhard limit)
ulimitには「soft limit」と「hard limit」という2種類の制限があります。
soft limitは実際にプロセスが使える上限で、ユーザー自身が変更可能です。hard limitはその枠を決める絶対値で、管理者が設定し、ユーザーはこれを超える値に変更することはできません。
2種類の制限値
- soft limit:現在のセッションで有効な制限で、ユーザーが一時的に変更可能。
- hard limit:管理者権限が必要で、soft limitの上限として動作。
つまり、soft limitはhard limitを上限とした範囲内でしか調整できず、常に soft limit ≤ hard limit という関係にあります。
例えば ulimit -a を実行すると、現在のsoft limitが表示されます。
ulimit -a
【出力例】
…
open files (-n) 1024
…
ここで表示されている「open files (-n) 1024」は、プロセスが同時に開けるファイルディスクリプタの数が1024までに制限されていることを意味します。ファイルディスクリプタはファイルやソケット、パイプを扱う際に必ず必要となるため、この数値がシステム全体の処理能力に直結します。
もし1024では不足すると判断した場合、soft limitを2048に引き上げることができます。
ulimit -n 2048
設定後に確認すると、値が変更されていることがわかります。
ulimit -n
【出力例】
2048
この変更はあくまでsoft limitの範囲でのみ有効です。もしhard limitが1024に設定されている環境であれば、2048に変更しようとしても「Operation not permitted」とエラーになります。
hard limitを確認するには ulimit -Ha を使います。
【出力例】
core file size (blocks, -c) unlimited
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
max locked memory (kbytes, -l) 65536
open files (-n) 4096
max user processes (-u) 12032
この例では、soft limit(通常の ulimit -a で表示される値)が 1024 だったとしても、hard limitでは「open files (-n)」が 4096 となっています。
したがってユーザーは、ulimit -n 2048 のように 4096 以下であれば引き上げが可能ですが、それを超える値は設定できずエラーになります。
こうやって出力例を並べると、soft limit = 現在有効な値、hard limit = それを超えて上げられない天井 という関係が、読者にも直感的に伝わります。 なお、必要に応じてhard limitを変更する場合はroot権限が必須で、後述の/etc/security/limits.conf や systemdの設定ファイルを編集して永続化する必要があります。
ファイルディスクリプタとulimitの活用
ファイルディスクリプタとulimitを理解すると、実際の運用でプロセスごとの制御やシステム全体の安定化に役立てることができます。ここではよく使うオプションの確認方法や、ユーザー単位・システム単位での制御方法、そして永続化設定の手順について解説します。
ulimitには多数のオプションがありますが、日常的に利用するものは限られています。
代表的なオプションを以下にまとめます。
| オプション | 対象リソース | 説明 |
|---|---|---|
| -n | ファイルディスクリプタ数 | 同時に開けるファイル数の上限 |
| -u | プロセス数 | ユーザーが生成できる最大プロセス数 |
| -c | コアファイルサイズ | 生成されるコアダンプの最大サイズ |
| -v | 仮想メモリサイズ | 利用可能な仮想メモリの上限 |
例えば、現在のファイルディスクリプタ数の上限を確認する場合は次のように実行します。
ulimit -n
【出力例】
1024
実行ユーザーごとの制御
ulimitは実行ユーザー単位で制御できます。例えば特定ユーザーでプロセス数の上限を確認するには次のように実行します。
ulimit -u
【出力例】
768
この値は現在ログインしているユーザーに適用されるため、ユーザーごとに異なる制限を設けることでシステム全体の安定性を確保できます。
システム全体での制御
システム全体での制御は、管理者権限で設定を行う必要があります。カーネルパラメータとしてファイルディスクリプタ数の上限を設定する場合は、/proc ファイルシステムを利用して確認・変更が可能です。
cat /proc/sys/fs/file-max
【出力例】
9223372036854775807
この値はシステム全体で開けるファイルディスクリプタの上限を示しています。必要に応じてsysctlコマンドや設定ファイルを用いて調整します。
永続化設定(limits.confやsystemdとの関係)
ulimitコマンドで設定した値はシェルを終了すると元に戻ってしまいます。恒久的に設定を反映させたい場合は設定ファイルを利用します。
ユーザーごとの永続化には/etc/security/limits.confを編集します。例えばwebuserに対してファイルディスクリプタ数を4096に設定する場合は以下のように追記します。
webuser soft nofile 4096
webuser hard nofile 8192
systemdで管理されるサービスについては、ユニットファイルにLimitNOFILEを設定することで反映させることができます。
LimitNOFILE=4096
これにより、再起動後も設定が維持され、サービス単位で安定したリソース管理が可能になります。
実践的な活用例
ここではファイルディスクリプタとulimitの設定が実際の運用にどのように役立つのかを解説します。
高負荷環境での調整やWebサーバー・DBサーバーでの利用、さらにトラブル発生時の確認方法を理解しておくことで、安定したシステム運用につなげることができます。
高負荷アプリケーションの調整
大量の同時処理を行うアプリケーションは、多数のファイルディスクリプタを必要とします。
例えばログを多数出力する処理や同時接続が集中するサービスでは、デフォルトのopen files制限では不足することがあります。 このような場合には、ulimitを利用して制限値を引き上げることで、処理落ちやエラーを回避できます。
ulimit -n 4096
【出力例】
4096
このように引き上げることで、多数のファイルやソケットを扱う高負荷アプリケーションも安定して稼働できるようになります。
WebサーバーやDBサーバーでの適用例
Webサーバーやデータベースサーバーは、同時接続数がファイルディスクリプタ数に直結します。
制限値が小さいままでは接続数の増加に対応できず、サービス拒否状態に陥る危険があります。 例えばApacheやNginx、MySQLなどのプロセスが利用するファイルディスクリプタの上限を引き上げる場合、まず現在の値を確認します。
ulimit -n
【出力例】
1024
次に必要な規模に応じて値を変更します。
ulimit -n 8192
【出力例】
8192
これにより、多数の同時接続やファイル操作が必要なサーバー環境でも余裕を持って処理できます。
トラブルシュートでの確認手順
「Too many open files」というエラーは、ファイルディスクリプタの制限に達した典型的な症状です。
このような場合にはまず現在の制限値を確認します。
ulimit -n
【出力例】
1024
次に、どのプロセスが多くのファイルディスクリプタを使用しているかを調べます。
ls -l /proc/【PID】/fd | wc -l
【出力例】
980
このように実際の利用状況と制限値を突き合わせることで、問題がulimitの制限に起因しているのか、それともアプリケーションの不具合なのかを切り分けることができます。
適切な制限値の調整と、問題発生時の迅速な確認手順を理解しておくことが、安定したシステム運用の鍵となります。
注意点
ulimitやファイルディスクリプタの制限は便利な一方で、安易に変更するとシステムに予期しない影響を及ぼす可能性があります。
ここでは、実際に運用する際に押さえておくべき注意点を整理します。副作用、ログや監視の落とし穴、セキュリティ上の観点を理解しておくことが安定稼働のために欠かせません。
制限値の変更による副作用
制限値を必要以上に引き上げると、システムに悪影響を及ぼすことがあります。
例えばファイルディスクリプタ数を極端に増やすと、それに伴いカーネルが管理するテーブルが大きくなり、メモリを圧迫する要因となります。
その結果、他のプロセスに必要なリソースが不足し、逆にシステムが不安定になることもあります。
したがって、アプリケーションの要求に応じて適切な値を設定することが重要です。
ログや監視での落とし穴
制限値の変更は一時的に有効であっても、再起動すると元に戻るケースが多いです。
設定を恒久化するには /etc/security/limits.conf や systemd のサービスユニットで指定する必要がありますが、これを忘れると監視環境で「テスト時は問題なかったのに、本番稼働後に制限で停止する」といった事態が発生します。
また監視システムのログでは「Too many open files」としか表示されず、原因がファイルディスクリプタ上限だと気付けないケースもあります。
事前に ulimit -a で現在の値を確認し、監視のアラート設計にも組み込むことが重要です。
セキュリティ観点での考慮点
セキュリティの観点からも制限値は軽視できません。
もし無制限に設定すれば、1つのユーザーやプロセスが際限なくリソースを消費し、DoS攻撃に利用される危険があります。
特に共有環境や複数ユーザーが利用するサーバーでは、ユーザーごとに適切な制限を設けることがシステム全体の安全性につながります。
そのため、ulimitを調整する際は単に性能面だけでなく、システム全体の安定性とセキュリティバランスを考慮しながら設定することが求められます。
まとめ
ファイルディスクリプタとulimitは、Linuxシステムを安定して運用するために欠かせない基本要素です。ファイルディスクリプタはプロセスがファイルやソケット、パイプを扱う際に必ず必要となる番号であり、その上限を決めるのがulimitです。
ulimitにはsoft limitとhard limitの2種類があり、soft limitはユーザーが一時的に変更できる制限値、hard limitは管理者が定める絶対的な上限値です。両者の関係を理解しておくことで、実際に制限値を引き上げる際に「なぜ変更できる場合とできない場合があるのか」を正しく把握できます。
また、Webサーバーやデータベースサーバーのように多数の同時接続が発生するシステムでは、ファイルディスクリプタの上限を調整することが安定稼働の鍵となります。トラブルシュート時にも ulimit -a や ulimit -n で現在の制限値を確認することが、原因切り分けの近道です。
一方で、制限値を無闇に増やすことはメモリ消費やセキュリティリスクにつながる可能性があるため、システムの特性や運用環境に応じて慎重に調整する必要があります。
つまり、ファイルディスクリプタとulimitを正しく理解し、必要に応じて適切に設定することが、システムの性能と安定性を両立させる最も重要なポイントです。




