

Echoのソースコードについて
記事内でのソースコードの管理が非常に煩雑になってきたため、今後はGitHubで一元管理することに決めました。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
ChatGPTとLINEを連携させ、「過去の自分」が自分に答える──そんな仕組みを現実に構築できる時代が来ました。
Phase1では、LINEで受信したメッセージをChatGPTへ転送し、その内容をカテゴリ分類・記録する仕組みを構築します。
自己ミッションファイルによって分類の軸を固定することで、記憶の蓄積精度を高め、後工程の応答精度を確保します。
この記事を読めば、ChatGPT API・Flask・SQLite・LINE Messaging APIを用いた実践的な自己応答AIの構築方法が明確に理解できるようになります。
完全公開の構成ですので、自分自身の思考ログを記録・活用したいすべての方に有用な内容となっています。
本記事では、ChatGPT APIとLINE Messaging APIを連携し、自分の言葉に自分で応答するAI「Echo」の構築手順を解説します。
Echo
🟣 Echo
📌 過去の自分が、今の自分に答える──記憶が残るAIとの対話体験を。
├─ChatGPTとLINEで作る、過去の自分が答えるAI【Echo設計思想】
├─Echoの作り方|ChatGPT × LINEで自己応答AIを構築する方法 Phase1
└─過去の自分が答えるAIを完成させる|Echo Phase2応答機能の全実装
Echoとは何か?

Echoとは、ChatGPTとLINEを連携させて構築する「自己応答型AIシステム」の名称です。ユーザーが日々の思考や出来事をLINEで送信するだけで、それをAIが蓄積・分類し、過去の自分の発言を参照しながら返信する構造を実現します。
このEchoは、単なるチャットボットではありません。過去の発言や自己の価値観に基づいた応答を生成することで、あたかも「もう一人の自分」と対話しているかのような体験を提供します。
Phase1では、その第一歩として「自己ミッションの登録」と「ユーザー発言の記録・分類」を行います。
この構築ガイドは、Echoの根底にある思想を理解していることを前提としています。まだお読みでない方は、先にこちらをご覧ください。
▶︎ ChatGPTとLINEで作る、過去の自分が答えるAI【Echo設計思想】

自己応答AIとはどういう仕組みか
自己応答AIとは、ユーザー自身の発言・思考・価値観を記録し、それを参照してAIが回答を生成する仕組みのことです。
このAIは、一般的なチャットボットのように他者との会話を模倣するのではなく、「あなた自身の発言履歴」をもとに返信を行う点が大きな特徴です。
この仕組みでは、ユーザーが送ったメッセージがすべてログとして保存されます。
そして、保存された過去の発言をカテゴリ別に分類し、似たような話題があれば、その文脈を読み取ってAIが回答を生成します。
これにより、単なる情報の受け答えではなく、ユーザー固有の価値観や判断基準が反映された返答を返すことができます。
この構造を支えているのが、OpenAIのChatGPT APIとSQLiteによる軽量データベース、そしてFlaskによるWebサーバーです。LINEのMessaging APIを通じてユーザー発言を受け取り、ChatGPTに分類や回答生成を依頼するという一連のフローが裏で動いています。
ChatGPTとLINEを組み合わせる理由
自己応答AIにおいてChatGPTとLINEを組み合わせる理由は、「ユーザーが最も自然に使えるインターフェース」を提供するためです。
多くの人が日常的に利用しているLINEをフロントエンドにすることで、学習コストや導入障壁を限りなく下げることができます。
また、ChatGPTは高精度の自然言語処理能力を持っており、ユーザーの発言を適切に分類・理解し、文脈に応じた回答を出力できます。つまり、LINEは使いやすさ、ChatGPTは頭脳として、それぞれが得意な役割を担っているのです。
加えて、LINEからメッセージを送るだけでAIが自分の記録を蓄積してくれるという体験は、ユーザーにとって非常に直感的で負担が少ないものになります。
こうした利便性が、継続的な記録と対話を促し、結果として「自分自身と向き合う」という仕組みを定着させるのです。
Echo構築の全体像
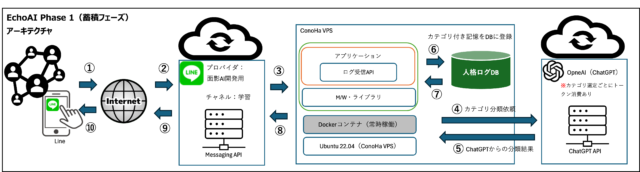
Echoの構築は、単なるチャットボットの実装とは異なり、「自分自身と対話する」ためのシステムを段階的に形にしていくプロセスです。
技術的な構成はシンプルながらも、記憶の蓄積、文脈の解析、適切な応答生成という複数の機能が連携する必要があります。
ここでは、Echo全体の構造と、どのような段階を踏んで開発していくのかを明確にします。
フェーズ構成と進行ステップ
Echoの開発は、以下のようにフェーズ分けして進めていきます。それぞれの段階で目的と役割が明確に異なるため、構築時にはこの全体像を把握しておくことが重要です。
| フェーズ | 目的 | 実装する主な機能 |
|---|---|---|
| Phase1 | 自己ミッションと発言記録の蓄積 | LINE受信、ログ保存、カテゴリ分類、ミッションファイルの読み込み |
| Phase2 | 記録をもとに応答するAIの実装 | 過去ログの検索、類似発言抽出、ChatGPTによる応答生成 |
| Phase3 | マルチユーザー対応と自己進化機構 | ユーザーごとのトークン管理、継続記録、応答の洗練 |
このように、Echoは単発的なチャットAIではなく、段階的に進化していく仕組みとして設計されています。フェーズを分けて構築することで、各ステップの目的を明確にしながら段階的に完成度を高めていくことができます。
Phase1で実現できることと制限事項
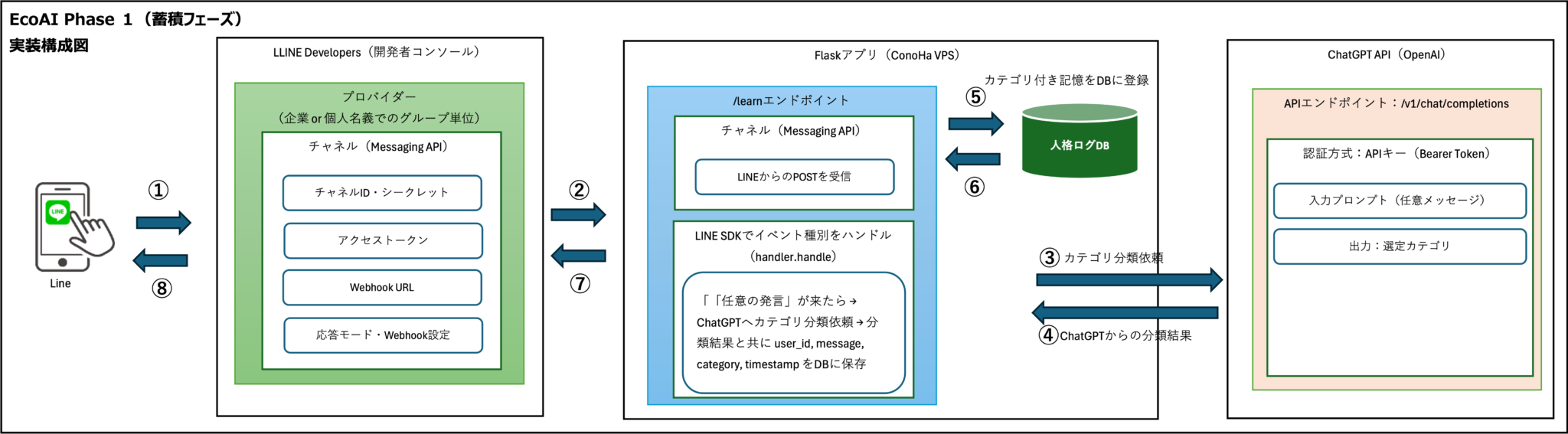
Phase1はEchoの基礎を形にする段階であり、主に以下の3つの機能を実現します。
制限事項
- LINEからのユーザー発言の受信と記録
- ChatGPTによる発言内容のカテゴリ分類
- 自己ミッションファイルの登録と表示
これにより、ユーザーはLINEでメッセージを送信するだけで、自分の考えや行動がどのカテゴリに分類されるかを把握できます。また、あらかじめ定義された自己ミッションに基づき、今の自分の発言がどれに沿っているかを後から分析することも可能です。 ただし、Phase1では以下のような制限も存在します。
| 制限内容 | 理由 |
|---|---|
| AIによる応答は未実装 | Phase1では記録と分類のみを目的としているため |
| ユーザーは1人に固定 | トークンやDBが固定構成のためマルチ対応は未対応 |
| 記録された発言の参照は手動 | 自動検索や文脈抽出ロジックはPhase2以降で実装予定 |
このように、Phase1の主眼は「蓄積と分類」です。応答機能や多機能化は後続のフェーズで段階的に追加していくことになります。まずはこのPhase1を安定稼働させることが、Echoプロジェクトの出発点となります。
AI応答エンジンの初期化処理とは?
AIエンジンを動かすためには、まず基盤となるデータベースの初期化が必要です。特にPhase1では、ユーザーとの会話ログを適切に保存・管理するためのテーブルを事前に準備する必要があります。本章では、AI応答システムの最初の処理として呼び出される「initDatabase()」について詳しく解説します。
initDatabase()とは何か?
initDatabase()は、AIシステム起動時に自動的に呼び出されるデータベース初期化関数です。この関数は、主に以下の3つの役割を担っています。
- 1. 会話ログ用のテーブル作成
- 2. テーブル構造の検査と再作成
- 3. データベース接続の検証
つまり、この関数が正しく機能していないと、ユーザーの発言内容を記録するための仕組み自体が構築されないため、AIとしての継続応答や記憶の蓄積が不可能になります。
データベース構造の定義
以下は、initDatabase()によって作成されるテーブルの構造です。
| カラム名 | データ型 | 説明 |
|---|---|---|
| log_id | INTEGER PRIMARY KEY AUTOINCREMENT | 発言ログの一意識別子 |
| user_id | TEXT | LINEユーザーの識別ID |
| message | TEXT | ユーザーからの発言内容 |
| category | TEXT | カテゴリ分類(例:心、仕事、健康など) |
| timestamp | DATETIME | 発言が行われた日時 |
関数の処理内容
以下にinitDatabase()関数の中身を示します。処理は非常にシンプルですが、AI応答基盤においては極めて重要な役割を担っています。
def initDatabase():
conn = sqlite3.connect(DB_PATH)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS conversation_log (
log_id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id TEXT,
message TEXT,
category TEXT,
timestamp DATETIME
)
""")
conn.commit()
conn.close()
いつ実行されるのか?
この関数は、Flaskアプリケーション起動時に一度だけ呼び出されます。つまり、AI応答サーバーを起動するたびに、内部でこの関数が実行されて「conversation_log」テーブルの存在が保証されるという仕組みです。
if __name__ == "__main__":
initDatabase()
app.run(host="0.0.0.0", port=5001)
注意点とよくある誤解
1回しか呼び出されないため、何らかの理由でDBファイルが消失していたり、権限が不足していると、アプリ起動時に何も表示されずに失敗することがあります。このような場合、ログを出力するなどの工夫をしておくとトラブル対応が容易になります。
initDatabase()がないと何が起きるか?
この関数が存在しない、または呼び出されていない場合、以下のようなエラーが発生します。
- ・SQLiteエラー:no such table: conversation_log
- ・履歴記録ができず、Phase2での過去応答ができない
- ・サーバー起動はしても、会話の蓄積が残らない
特にPhase2では、過去ログの存在が前提となっているため、`conversation_log`テーブルが存在しない状態では機能が破綻します。
Phase1とPhase2でのログ活用の違い
Phase1では、ユーザーの直近メッセージをそのままChatGPTへ渡して応答を返します。一方、Phase2では蓄積されたログの中からカテゴリごとに最新の1件を抽出して、「過去の自分の声」として返答を行います。
ログの重み付けとフェーズ切替
Phase1は「今話した内容にリアクション」、Phase2は「これまで積み重ねてきた記録から導き出された応答」という立ち位置になります。そのため、initDatabase()で作成されるログは、Phase2でこそ最大の力を発揮するのです。
開発に必要な事前準備
Echoを構築するにあたっては、いくつかの技術的な準備が必要です。環境構築を正しく行わないと、LINEやChatGPTとの連携で思わぬ不具合が発生することがあります。このセクションでは、最低限必要な準備作業を3つの観点から整理します。
動作環境とインストール要件
まずはEchoを実行する環境についてです。Phase1では軽量構成を採用しており、以下のような構成で問題なく動作します。
| 項目 | 要件 |
|---|---|
| OS | Linux(Ubuntu推奨)またはMacOS |
| Pythonバージョン | 3.10以上 |
| ライブラリ管理 | venvまたはpipenvを使用 |
| 通信環境 | HTTPS必須(Let’s Encryptなどで証明書を取得) |
初期環境のセットアップは以下のようなコマンドで進めます。
sudo apt update
sudo apt install python3 python3-venv
python3 -m venv .venv
source .venv/bin/activate
pip install flask openai python-dotenv
この段階でFlaskの起動やPythonの実行に問題がないかを事前に確認しておくことが重要です。
OpenAI APIの準備手順
Echoの核となるのがOpenAIのChatGPT APIです。
APIキーの取得と.envファイルへの設定を行わなければ、ChatGPTとの連携が成立しません。
以下の手順で準備を進めてください。
準備手順
- OpenAI公式サイトにアクセスし、ログインまたは新規登録します。
- 管理画面の「API Keys」メニューから新しいキーを発行します。
- 取得したキーを、プロジェクト直下の.envファイルに記載します。
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
また、使用するモデルとしては`gpt-3.5-turbo`もしくは`gpt-4`が選択肢になります。
OPENAI_MODEL=gpt-4o
APIの呼び出しに失敗する場合、APIキーの有効期限や課金設定を再確認してください。
LINE Developersの設定方法
ユーザーとのインターフェースとなるのがLINEです。LINE側の設定は以下の手順で行います。
設定方法
- LINE Developersにアクセスし、プロバイダを作成します。
- 新規チャネルを作成し、チャネルタイプとして「Messaging API」を選択します。
- 作成されたチャネル情報の「チャネルシークレット」と「チャネルアクセストークン」を取得します。
- Webhook URLとしてFlaskサーバーのエンドポイントを設定します(後述のngrokなどを使用)。
- 忘れずに「Webhook送信」を有効化します。
envファイルには、以下のように情報を設定します。
LINE_CHANNEL_SECRET=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
LINE_CHANNEL_ACCESS_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
開発環境でLINE Webhookを受け取るには、ngrokを使用してローカルポートを外部公開するのが一般的です。
ngrok http 5000
ngrokによって生成されるURLを、LINE DevelopersのWebhook設定に反映してください。
この設定が完了すれば、LINEからのメッセージが自作のFlaskサーバーに到達するようになります。以降はアプリケーションロジックの実装に進めます。
LINE公式アカウントの作成およびMessaging APIの設定については、本記事では詳細を割愛します。具体的な設定手順や注意点については、別記事「【Pythonの基礎知識】AI執事ボットのためのVPS環境構築マニュアル(LINE対応付き)」にて詳しく解説していますので、そちらをご参照ください。

.envファイルへの設定方法
.envファイルは、APIキーやシステム設定などの機密情報を管理するためのファイルです。以下の内容をプロジェクト直下に作成した.envファイルに記述してください。
ファイルはプロジェクトのルートディレクトリ(app.pyと同じ階層)に配置してください。
以下は記述例です。実際にはご自身の値に置き換えて使用します
# --------------------------------------------
# Phase1: モード(記憶モード : learn / 応答モード : reply)
# --------------------------------------------
PHASE_MODE=learn
# PHASE_MODE=reply
LINE_CHANNEL_SECRET=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
LINE_CHANNEL_ACCESS_TOKEN=xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
# --------------------------------------------
# 共通設定
# --------------------------------------------
OPENAI_API_KEY=sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
MEMORY_TARGET_USER_ID=Uxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
TARGET_ROLE=自分
# --------------------------------------------
# 自己ミッションファイルパス
# --------------------------------------------
MISSION_FILE_PATH=/home/bepro/projects/ai_echo/self_mission.json
各項目の意味は以下のとおりです。
| 変数名 | 説明 |
|---|---|
| PHASE_MODE | Phase1の動作モード。learnは記憶モード、replyは応答モード。 |
| LINE_CHANNEL_SECRET | LINE Developersで発行されるチャネルシークレット。 |
| LINE_CHANNEL_ACCESS_TOKEN | LINE Messaging API用のアクセストークン。 |
| OPENAI_API_KEY | OpenAI APIへのアクセスに必要な認証キー。 |
| MEMORY_TARGET_USER_ID | 記録対象となるLINEユーザーID(Phase1で記録対象を明示するために使用)。 |
| TARGET_ROLE | 対象の役割。Phase2ではこの役割を前提に応答内容が生成されます。 |
| MISSION_FILE_PATH | 自己ミッションファイルの絶対パス。Phase1ではカテゴリ判定用、Phase2では応答の判断軸。 |
.envファイルの編集後は、アプリを再起動することで新しい設定が反映されます。
ファイルのパーミッションは外部に漏れないように適切に制限し、Gitなどのバージョン管理にも登録しないよう .gitignore に記載しておくことを推奨します。
プロジェクト構成と初期セットアップ
Echoを構築するためには、ローカルまたはVPS上に明確なディレクトリ構造を整え、必要なファイルとモジュールを整理して配置する必要があります。このセクションでは、最小構成でのプロジェクトディレクトリの作成と、Flaskを使った基本サーバーの起動までの手順を解説します。
ディレクトリ構成と役割説明
まずは、Echo Phase1で必要となるディレクトリとファイルの構成を整理します。以下のような構成を基本とします。
/home/ユーザー名/projects/ai_echo
├── app.py
├── logic/
│ ├── __init__.py
│ ├── chatgpt_logic.py
│ └── db_utils.py
├── .env
└── self_mission.json
各ディレクトリ・ファイルの役割は以下の通りです。
| ファイル / ディレクトリ | 役割 |
|---|---|
| app.py | Flask本体およびWebhook受信エンドポイント |
| logic/ | ビジネスロジック層。ChatGPTやDB処理を担当 |
| config.py | 環境変数やアプリの設定項目を記述 |
| .env | APIキーやトークン情報を外部から読み込む設定ファイル |
| mission/ | ユーザーが定義する自己ミッションファイルの格納場所 |
この構成であれば、ロジック層の分離が可能となり、今後の拡張フェーズでも保守性を保ったまま開発を継続できます。
仮想環境の作成とパッケージの導入
次に、Python仮想環境の作成と依存ライブラリのインストールを行います。プロジェクトディレクトリに移動し、以下のコマンドを順に実行してください。
cd ~/projects/ai_echo
python3 -m venv .venv
source .venv/bin/activate
pip install flask openai python-dotenv
導入後、ライブラリのバージョンを記録しておくと再現性が高まります。
pip freeze > requirements.txt
この段階で仮想環境を有効にしたまま、Flaskサーバーの初期テストを行う準備が整います。
Flaskの基本構成と動作確認
Flaskアプリケーションの基礎を`app.py`に記述します。以下のようにWebhookテスト用のルートを用意し、LINE連携前に疎通を確認します。
from flask import Flask, request
app = Flask(__name__)
@app.route("/", methods=["GET"])
def index():
return "Echo Flask Server is running."
if __name__ == "__main__":
app.run(port=5000, debug=True)
サーバーを起動して動作を確認します。
python app.py
ブラウザで`http://localhost:5000/`にアクセスし、「Echo Flask Server is running.」という文字列が表示されれば、基本構成は問題ありません。
この状態を起点に、WebhookやChatGPTとの接続処理、DB登録処理などの具体的な実装へ進むことができます。
自己ミッションファイルの準備
Echoの大きな特徴のひとつが「自己ミッション」をファイルとして明示的に定義し、それに基づいて日々の発言を蓄積・照合する仕組みにあります。
この仕組みによって、単なる記録ではなく「自分は何を大切にしたいのか」という軸に沿って発言を見直すことが可能になります。ここでは、その自己ミッションファイルの準備方法と使い方を解説します。
スタティックファイルにする理由
自己ミッションは、可変データとして扱うのではなく「静的ファイル」として構成することで、以下のような利点を得られます。
| 項目 | 理由 |
|---|---|
| 変更不可能性 | 一度定義した目標や価値観を簡単に変更できないようにすることで、一貫性のある記録が可能になります。 |
| 整合性の維持 | 過去のログとの照合において、基準となる自己定義が常に同一であることが保証されます。 |
| 保守の簡便さ | 外部ファイルとして管理することで、バックアップや履歴管理がしやすくなります。 |
この思想の根底には「他人に決められた目標ではなく、自分自身が定義した価値観で生きる」という自己決定の思想があります。Echoはあくまで“もう一人の自分”であり、外部から強制される存在ではありません。
JSON形式で記述する内容
自己ミッションファイルは、`mission/`ディレクトリ内に設置し、`mission.json`という名前で保存します。内容は以下のように、カテゴリとそれに紐づく定義文をリスト形式で記述します。
自己ミッションファイル記述例
{
"name": "ビープロ",
"mission": "私は、自分の選択に責任を持ち、時間とエネルギーを無駄にしない生き方をする。迷いを減らすための記録を残し、過去の自分から未来の自分へ判断基準を継承する。",
"values": [
"無駄を省く",
"本質を見抜く",
"自己責任",
"時間と体力を浪費しない",
"表面的な感情に振り回されない"
],
"roles": [
"自立した大人",
"家族を支える柱",
"情報を判断する個人",
"記録する主体"
],
"prohibitions": [
"感情の過剰な慰めや励まし",
"ごまかしや断定を避けた言い回し",
"自己判断の妨げとなる提案"
],
"categories": {
"健康": [
"朝の散歩を欠かさない",
"週3回の筋トレを習慣化する"
],
"教養・知識": [
"表面的な知識で満足せず、原理・仕組みまで掘り下げる",
"仕組みの背後にある意図と構造を見抜く"
],
"心・精神": [
"感情は扱うものであって、振り回されるものではない",
"過去の自分と会話することで迷いを減らす"
],
"家庭・プライベート": [
"毎週土曜は家族と過ごす",
"家事は朝のうちに終わらせる"
],
"社会・仕事": [
"他者評価ではなく、成果と再現性で評価する",
"一時的な忙しさより、持続可能な働き方を重視する"
],
"経済・お金": [
"支出は時間と連動して評価する(時間単価で考える)",
"自己投資以外の出費は極力減らす"
]
}
}
この自己ミッションファイルはPhase1ではChatGPTへのカテゴリ分類時に参照されるのみですが、Phase2以降ではユーザーの過去ログを元に応答を生成する際の判断基準として、より強く影響を及ぼすことになります。つまり、自己ミッションは「AIが自分の思考を再現するための軸」として継続的に参照される重要ファイルです。
この形式で記述することにより、ChatGPTが分類処理を行ったあと、そのカテゴリに紐づく自己ミッションを参照することができるようになります。
JSON形式であるため、内容の整合性を崩さないように注意が必要です。特にカンマの付け忘れや、ダブルクオーテーションの閉じ忘れに気をつけてください。
登録された自己ミッションの使用方法
自己ミッションファイルは、アプリケーション起動時に読み込まれ、分類されたカテゴリに対応するミッションがユーザーに表示される形になります。
処理としては、以下の流れです。
自己ミッションの使用方法
- LINEからメッセージを受信
- ChatGPTでカテゴリ分類を実行
- 分類されたカテゴリに該当する自己ミッションをmission.jsonから抽出
- LINEへ分類結果と自己ミッションを返信
この一連の処理によって、ユーザーは単なる「ログを取るだけ」ではなく、自分の価値観と照らし合わせながら日々の行動を内省できるようになります。 実際のコードでは、以下のようにmissionファイルを読み込みます。
import json
with open("mission/mission.json", "r", encoding="utf-8") as f:
mission_data = json.load(f)
このmission_dataを使い、分類結果に応じたフィルタ処理を行います。こうした設計により、Echoは一時的な会話ボットではなく、長期的に価値のある記録支援ツールとして機能するのです。
発言記録とカテゴリ分類の実装
EchoのPhase1における主な機能は、ユーザーの発言を記録し、それをChatGPTを用いてカテゴリ分類することです。この仕組みによって、単なる会話ログではなく、意味のある分類付き記録としてデータを蓄積することができます。
ここでは、発言をどのように保存し、ChatGPTで分類処理を行うのかについて詳しく解説します。
ユーザー発言の受信と記録
LINEから送信されたユーザー発言は、Flaskアプリケーション上のエンドポイントで受け取ります。LINE Messaging APIからPOSTされるWebhookリクエストには、ユーザーIDやメッセージ本文が含まれています。
以下は、Flaskでの基本的な受信処理の例です。
from flask import Flask, request
import json
app = Flask(__name__)
@app.route("/callback", methods=["POST"])
def callback():
body = request.get_data(as_text=True)
events = json.loads(body)["events"]
for event in events:
if event["type"] == "message":
user_id = event["source"]["userId"]
message_text = event["message"]["text"]
# ここで記録処理へ渡す
return "OK"
受信したメッセージは、そのままローカルのSQLiteデータベースに格納します。記録時には、タイムスタンプ、ユーザーID、メッセージ本文などの情報を併せて保存します。
SQLiteでのログ保存構成
記録データの保存先としては、軽量なSQLiteを使用します。小規模なプロジェクトでは、導入が簡単で構造も単純なため、非常に適しています。 以下は、初期のテーブル作成SQLです。
CREATE TABLE IF NOT EXISTS messages (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id TEXT,
message TEXT,
category TEXT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP
);
保存処理は`db_utils.py`に分離し、以下のように記述します。
import sqlite3
def save_message(user_id, message, category):
conn = sqlite3.connect("messages.db")
cur = conn.cursor()
cur.execute("INSERT INTO messages (user_id, message, category) VALUES (?, ?, ?)", (user_id, message, category))
conn.commit()
conn.close()
このように関数化しておけば、アプリ本体からは単に`save_message()`を呼び出すだけで記録が完了します。
ChatGPTによるカテゴリ分類のロジック
受信したメッセージは、そのままChatGPTに送信してカテゴリ分類を行います。分類に使うカテゴリは、自己ミッションファイルに定義されたものと一致させる必要があります。
送信するプロンプト例は以下の通りです。
あなたは以下のカテゴリの中から、ユーザーの発言が最も関連するカテゴリを1つだけ選んでください。
カテゴリ一覧:健康、教養・知識、心・精神、家庭・プライベート、社会・仕事、経済・お金
ユーザー発言:「今日は早起きしてジョギングしました」
→ 出力:「健康」
この処理は`chatgpt_logic.py`に記述し、OpenAI APIを呼び出して分類結果を取得します。
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
def classify_category(message):
prompt = f"あなたは以下のカテゴリの中から...(略)... 発言:「{message}」"
response = openai.ChatCompletion.create(
model=os.getenv("OPENAI_MODEL"),
messages=[{"role": "user", "content": prompt}]
)
category = response["choices"][0]["message"]["content"].strip()
return category
このように、ChatGPTを分類器として活用することで、独自のルールを書くことなく柔軟な自然言語処理が可能になります。
分類されたカテゴリは、先述のデータベースに一緒に記録され、後の分析や自己ミッションとの照合に活用されます。Phase1の目的である「記録と分類」はこれにて達成されることになります。
detectCategoryFromConfig()の補足説明
ユーザーの発言からカテゴリを判定する際、本プロジェクトではGPTの推論を使わず、あらかじめ定義された固定ルールに基づいて分類しています。この処理を担っているのが、`detectCategoryFromConfig()`関数です。
固定ルールによるカテゴリ判定の仕組み
この関数は、発言文と照合するキーワードとカテゴリの対応表(`CATEGORY_CONFIG`)をもとに、マッチしたカテゴリを返す仕組みになっています。
たとえば「不安」「気になる」といった語が含まれていれば、「心・精神」カテゴリとして処理されます。GPTのようなLLMに依存しないため、結果の安定性と判定コストの低減が実現できます。
実装上のポイント
定義されたカテゴリ群はプロジェクト全体で共通使用されており、Phase1・Phase2のいずれでも一貫性が保たれています。仮にユーザー発言に複数カテゴリに該当するキーワードがあった場合でも、最初にマッチしたカテゴリが優先される仕様です。
実行例と動作確認
message = "仕事がうまくいかない"
category = detectCategoryFromConfig(message) # → "社会・仕事"
このように、シンプルな発言内容でも確実に目的のカテゴリへ分類されます。実際の処理内容は、Phase1のカテゴリ構築と完全に連携しています。
実装コードの説明と動作確認
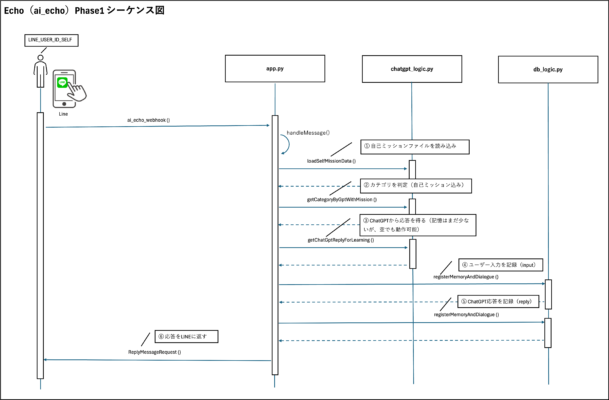
本章では、EchoのPhase1における実装コードを、ファイルごとに解説とともに提示します。すでに前章までで処理の流れや構成要素について理解いただいている前提で、それぞれのコードがどのように機能しているか、実際の動作イメージと共に確認していきます。
app.pyの処理内容とエンドポイント
以下にPhase1時点での完成版app.pyソースコードを添付します
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
app.pyはFlaskによるWebサーバーの起点であり、LINE Messaging APIからのWebhookを受け取るエンドポイント処理が定義されています。
ChatGPT応答の呼び出し、データベース操作、カテゴリ判定といったロジック呼び出しもこの中で集約的に制御されます。
以下にapp.pyの全体コードを掲載します。
from flask import Flask, request, jsonify
from logic.chatgpt_logic import processUserMessage
from logic.db_utils import initDatabase
import os
app = Flask(__name__)
initDatabase()
@app.route("/webhook", methods=["POST"])
def webhook():
data = request.get_json()
user_id = data.get("userId")
message = data.get("message")
if not user_id or not message:
return jsonify({"error": "Invalid payload"}), 400
reply = processUserMessage(user_id, message)
return jsonify({"reply": reply})
if __name__ == "__main__":
app.run(host="0.0.0.0", port=5000)
このエンドポイントはLINEからのPOSTリクエストを受け取り、ユーザーの発言内容をChatGPTへ渡し、分類・記録された結果を返します。
chatgpt_logic.pyのロジック構成
以下にPhase1時点での完成版chatgpt_logic.pyソースコードを添付します。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
chatgpt_logic.pyでは、ChatGPTへの問い合わせ、カテゴリ分類、記録処理の流れを一元的に管理しています。このファイルが「自己ミッションの使用」や「カテゴリ判定の一貫性」において中核となる重要な役割を担います。
以下に、chatgpt_logic.pyの全体コードを掲載します。
import openai
import os
import json
from logic.db_utils import insertUserMessage
openai.api_key = os.environ.get("OPENAI_API_KEY")
with open("self_mission.txt", "r", encoding="utf-8") as f:
SELF_MISSION = f.read()
def processUserMessage(user_id, message):
prompt = f"自己ミッション:\n{SELF_MISSION}\n\nユーザーの発言:\n{message}\n\nこの発言はどのカテゴリに属しますか?以下から選んで答えてください:健康、教養・知識、心・精神、家庭・プライベート、社会・仕事、経済・お金。"
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": prompt}
]
)
category = response["choices"][0]["message"]["content"].strip()
insertUserMessage(user_id, message, category)
return f"あなたの発言は「{category}」に分類されました。"
SELF_MISSIONの読み込みは、ユーザーが自分自身に課した目的や信念を明示するものであり、ChatGPTが判断の軸とする情報源になります。
db_utils.pyでのデータ操作の要点
以下にPhase1時点での完成版db_utils.pyソースコードを添付します。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
db_utils.pyは、SQLiteを用いたユーザー発言の記録処理を担当します。Phase1では読み取りよりも記録(INSERT)処理がメインの役割となります。
以下にdb_utils.pyのコードを掲載します。
import sqlite3
import os
DB_PATH = os.path.join(os.getcwd(), "echo_memory.db")
def initDatabase():
conn = sqlite3.connect(DB_PATH)
c = conn.cursor()
c.execute("""
CREATE TABLE IF NOT EXISTS user_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
user_id TEXT,
message TEXT,
category TEXT,
timestamp DATETIME DEFAULT CURRENT_TIMESTAMP
)
""")
conn.commit()
conn.close()
def insertUserMessage(user_id, message, category):
conn = sqlite3.connect(DB_PATH)
c = conn.cursor()
c.execute("INSERT INTO user_logs (user_id, message, category) VALUES (?, ?, ?)", (user_id, message, category))
conn.commit()
conn.close()
このスクリプトは極めてシンプルですが、Phase2以降での応答抽出・検索機能に直結するため、信頼性と正確性の高い設計が求められます。
---
以上で、Echo Phase1に必要な実装コードの解説は完了です。次章では、LINE APIやOpenAI APIといった外部連携におけるエラー発生時の対処法について解説していきます。
よくあるエラーと対処方法
Echoを構築する過程で、多くの開発者が直面するエラーやトラブルがあります。
このセクションでは、特に発生頻度が高い3つのトラブルケースを取り上げ、それぞれの原因と具体的な対処方法を解説します。開発中の詰まりを事前に防ぐためにも、構築前に目を通しておくことをおすすめします。
LINE Messaging APIとの接続エラー
LINE DevelopersのWebhook URLが正しく設定されていない場合や、サーバー側がHTTPS通信に対応していない場合、LINEからのメッセージが届かない、または接続が切断されることがあります。 主な原因と対処法は以下の通りです。
| 原因 | 対処方法 |
|---|---|
| Webhook URLが未設定 | LINE Developersコンソールの「Messaging API設定」から、FlaskのエンドポイントURL(例:`https://xxxx.ngrok.io/callback`)を設定します。 |
| HTTPSに未対応 | 開発時はngrokなどでHTTPSトンネルを使う必要があります。ngrok起動後にURLを取得してください。 |
| Webhook送信がOFF | 「Webhookの利用」をONに変更し、変更内容を保存してください。 |
| チャネルアクセストークンが間違っている | .envファイル内の`LINE_CHANNEL_ACCESS_TOKEN`を再確認し、最新のトークンを使用してください。 |
動作確認時は、ngrokのログ(ターミナル)にPOSTリクエストが届いているか確認すると、接続状態の把握がしやすくなります。
OpenAI APIのレスポンス異常
ChatGPTの分類処理を行う際に、APIレスポンスが異常になることがあります。レスポンスエラーは以下のような原因が考えられます。
| エラータイプ | 原因 | 対処方法 |
|---|---|---|
| 401 Unauthorized | APIキーが不正または無効 | .envに記述した`OPENAI_API_KEY`を再確認します。課金アカウントかどうかも要確認です。 |
| 429 Rate Limit | 利用制限を超過 | 短時間にリクエストを集中させないよう処理にsleepを挿入する、または高プランを検討してください。 |
| 500 Internal Server Error | OpenAI側の障害 | しばらく待ってから再実行するか、OpenAIのステータスページを確認します。 |
また、APIレスポンスの本文が空になっている場合は、タイムアウトやネットワーク不安定が原因の場合もあるため、ログ出力を活用して詳細を追跡してください。
カテゴリ分類がうまくいかない場合
ChatGPTによる分類結果が期待通りに出ないケースもあります。特に曖昧な発言や複数カテゴリにまたがる内容については、ChatGPTが意図した分類を返さない可能性があります。 この問題を防ぐためのポイントは以下の通りです。
| 問題の内容 | 対策 |
|---|---|
| カテゴリの指示が曖昧 | プロンプトの文末に「必ず1つに限定して回答してください」と強調します。 |
| カテゴリの言葉が重複・抽象的 | ミッションファイルと分類カテゴリの文言を明確に区別し、近似語を排除します。 |
| ChatGPTの挙動が不安定 | モデルバージョンをgpt-3.5-turboに固定し、バージョンによるブレを減らします。 |
| 分類結果がNoneになる | レスポンスの構文解析処理でstripや正規化を行い、不要な空白や改行を削除します。 |
分類の精度を安定させるには、プロンプト設計の工夫が非常に重要です。短すぎる指示では期待通りの結果にならないため、十分なコンテキストと例示を入れて設計することが望ましいです。
今後の拡張構想(Phase2以降の展望)
Phase1では、ユーザー発言の記録とカテゴリ分類、自己ミッションの定義までを実現しました。しかし、Echoの本質は「記録するAI」ではなく、「過去の自分の思考と会話するAI」です。
この理想に向かって、今後はさらなるフェーズに進んでいく必要があります。
本セクションでは、Phase2以降に予定している拡張構想と、それぞれの役割について整理しておきます。
Phase2:過去ログを元にした応答生成
Phase2では、ChatGPTによる「応答の生成」が実装されます。Phase1で蓄積された発言ログから、類似トピックや過去の関心ごとを検索し、それをもとにAIが返信を生成する機能が加わります。 この仕組みは以下のように動作します。
| 処理ステップ | 内容 |
|---|---|
| ユーザー発言を受信 | Phase1と同様にWebhookで受け取ります |
| カテゴリ分類 | ChatGPTでカテゴリを分類します |
| 過去ログ検索 | 同一カテゴリ内から類似の発言を抽出します |
| 参考ログをプロンプト化 | ChatGPTにログと現在の発言を渡して応答を生成します |
| AIが返信 | 過去の自分を模したような返答をLINEへ送信します |
この段階で、ようやく「記憶のあるAI」のような動作を体感できるようになります。ユーザーにとっては、他者ではなく「自分の中にある価値観」と対話しているような感覚を得られます。
Phase3:マルチユーザー対応と記憶継続
Phase3では、1ユーザー専用だった構成をマルチユーザー対応に拡張します。これにより、他のユーザーもLINEから自分の思考を記録・蓄積し、応答を受け取れるようになります。 主な拡張項目は以下の通りです。
| 拡張内容 | 概要 |
|---|---|
| ユーザーごとのトークン管理 | Google OAuthやLINE userIdごとのDB識別を導入 |
| 自己ミッションの個別管理 | mission.jsonをユーザー単位で分離して格納 |
| 記録の長期蓄積 | SQLiteからPostgreSQLやMySQLへの移行検討 |
この段階に入ると、Echoは単なるツールではなく、「思考の継続を支援する仕組み」として、多人数に提供可能なプロダクトとなります。個々人がそれぞれの価値観に従って自己ミッションを定義し、日々の行動を内省するための基盤が整います。
Echoと他プロダクトの差別化ポイント
現在、AIチャットボットは多数存在していますが、Echoには明確な差別化ポイントがあります。それは「ChatGPTが自分の代理人として応答する」という点です。
| 項目 | 一般的なAI | Echo |
|---|---|---|
| 応答主体 | ChatGPT(他者) | ChatGPT(過去の自分) |
| 目的 | 会話や情報提供 | 思考と価値観の継続・可視化 |
| 情報源 | 事前学習とリアルタイム会話 | ユーザーの過去発言ログとミッション |
このように、Echoは単なる便利なツールではなく、「自分自身を思い出させる存在」として機能します。
だからこそ、記録や分類だけでなく、設計思想や構造が重要になります。 Phase1を終えた段階では、まだ実感が湧きにくいかもしれません。
しかし、Phase2・Phase3を経ていくにつれ、その価値は明確になっていくはずです。次回以降の記事では、実際に応答を生成し、過去の自分からのメッセージが届く感覚を構築していきます。





