

ナレッジベースという言葉だけ見ると、専門家向けの仕組みに見えてしまいます。ちょっと自分でも整理してみたところ、ナレッジベースとは「あとから判断材料として使えるように、情報を取り出しやすい形でためておく場所」のことだと分かりました。難しく見えますが、最初に決めるのは「どこにためるか」と「どんな形でためるか」だけです。Obsidianはこのうち「どこにためるか」の選択肢の1つとして向いています。
この記事では、Obsidianに入れただけでは整理にならない理由から始めて、Obsidianが知識置き場として向く理由・Obsidianだけでは足りない4つの限界・AIに読ませやすいノートの4条件・フォルダとタグと内部リンクの使い分け・AIに渡してよい情報の3区分まで、一般層にもわかるように順番に整理します。フォルダ・タグ・内部リンクの公式の使い分けルールは存在しないため、本記事ではAIに渡す前提に合わせた1つのモデルとして扱います。
読み終わるころには、自分の手元のvault (Obsidianが管理しているフォルダのこと) のどこをAIに渡してよいかを、自分の判断軸で切り分けられる状態を目指します。RAGやVectorDBという言葉に進む前段の、Markdownノートの整理から見ていきます。
Obsidianに入れただけではAIの知識置き場にならない理由
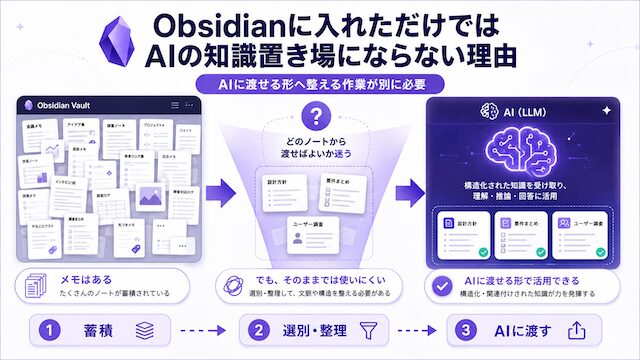
Obsidianにメモはたくさんあるのに、AIに渡そうとすると、どのノートから渡せばよいかで手が止まっていませんか。先に答えを書くと、Obsidianに入れただけではAIの知識置き場にはなりません。Obsidianはノートを残しやすくしてくれる場所であって、AIに渡せる形に整える作業そのものは別に必要だからです。
そもそもObsidianってなに?
Obsidianとは、パソコン上のフォルダにMarkdown形式のノートを保存していくメモアプリです。難しく考える必要はありません。最初は「普通のテキストファイルを、あとから探しやすく・つなげやすくしてくれるノートアプリ」と考えれば十分です。
ObsidianがAIと相性がよい理由は、ノートがアプリの中だけに閉じ込められないことです。ノートの実体は、フォルダの中にあるMarkdownファイルです。そのため、あとからAIに読ませたり、フォルダごと整理したり、別のツールで扱ったりしやすくなります。
つまり、Obsidianの価値は「きれいなノート画面」ではありません。AIに読ませる材料を、普通のファイルとして手元に残せることです。
ノートはあるのに渡せる形になっていない場面
ノートはObsidianの中にあるのに、AIに渡そうとした瞬間にどのファイルから渡すべきか判断できなくなる場面があります。フォルダ・日記・作業メモが混ざっていて、AIに使わせる形に切り出せないことが多いからです。
たとえば、議事録と日記と作業メモが同じノートに混ざっていたり、過去案件の名前が本文に残っていたりすると、AIに渡す前に「この部分は渡してよいのか」「どこからどこまで切り出すべきか」を毎回判断する必要が出てきます。判断回数が多くなると、結局AIに渡すこと自体をやめてしまう状態に近づきます。
「AIの記憶」という観点で前後関係を整理したい場合は、関連記事の AIの限界を超える設計とは何か──記憶と継続性の再定義 もあわせて読むと、本記事の位置づけが見えやすくなります。
「Obsidianに入れた = 整理した」と感じる錯覚
Obsidianに入れた段階で整理した気になる、というのが一番起きやすい錯覚です。保存場所がMarkdownに揃っていても、内容が判断材料として使える状態かは別問題です。
保管していることと、後から使えることは別軸です。保管側はObsidianが助けてくれますが、後から使える形にする側 (1テーマ1ファイル・固有情報の除去・結論と理由の両立) は人間が手を動かす必要があります。
AIに渡すための整え方の全体像
AIに渡せる形に整える作業は、大きく分けると4つの条件と3つの区分の組み合わせで決まります。4条件はノートの作り方、3区分はどのノートを渡すかの判断軸です。
4条件はMarkdown化・1テーマ1ファイル・結論と理由の両立・固有情報の除去で、本記事の「AIに読ませやすいノートの4条件」で順に見ていきます。3区分は「そのまま渡してよい」「加工して渡す」「渡さない」で、本記事の「AIに渡してよい情報と渡さない情報」で扱います。
正直に言うと、私はしばらくの間、巷で「Obsidianはすごい」と言われている理由がよく分かりませんでした。ノートをリンクでつなげたり、グラフビューで関係性を眺めたりできることは分かります。ですが、それだけなら「見た目としては面白いけれど、実務で何がそこまで変わるのか」は、なかなか実感できませんでした。
その見方が変わったのは、ObsidianにためたMarkdownノートをAIに読ませるようになってからです。
人間が画面で眺めているだけでは、Obsidianの価値は分かりにくいかもしれません。ですが、AIに読ませる前提で見ると、意味が変わります。ノートが普通のフォルダの中にMarkdownファイルとして残っているため、AIに渡しやすい。必要な範囲を切り出しやすい。あとから整理・要約・分類を任せやすい。
つまり、私が感じたObsidianの強みは、「人間が見てすごいノートアプリ」というより、「AIに読ませる材料置き場として扱いやすいこと」です。グラフビューを眺めて満足するだけなら、私にはまだそこまで大きな価値は感じられません。ですが、AIに読ませる知識をMarkdownでためておく場所として考えると、Obsidianの価値は一気に現実的になります。
人間にとってすごいというより、AIにとって扱いやすい。ここに、Obsidianを仕事の知識置き場として使う意味があると感じています。
ObsidianがAIの知識置き場として向く理由
ObsidianがAIの知識置き場として向く理由は、ノートが普通のフォルダの中にMarkdownファイルとして並んでいる点にあります。Vaultという言葉だけ見ても何のことか分かりにくいですが、ここではObsidianが管理対象にしているただのフォルダだと考えれば十分です。専用ツールを開かなくてもフォルダごとAIに読ませられて、エクスポート作業がいらないのが本質的な強みになります。

ノートが普通のフォルダにMarkdownのまま並んでいる
Obsidianのノートは、Obsidian専用の独自形式ではなく普通のMarkdownファイルです。AIから見ると、フォルダの中にある複数のテキストを順に読むだけで知識を取り込めることになります。
Markdownのプレーンテキストとは、装飾を最小限にした、コンピューターが読みやすい形式の文章のことです。エクスポート作業や変換作業がいらないので、ノートを書いた時点でAIに渡せる素材になっている、というのがObsidianの大きな強みです。
frontmatterで作成日や出典を残せる
ノートに作成日や出典を残すには、frontmatterという仕組みが使えます。frontmatterと言われると難しく聞こえますが、ファイルの一番上に作成日や出典などのメタ情報をメモしておく欄だと考えれば十分です。
frontmatterは公式仕様で --- で囲まれた数行のブロックとして書きます。作成日 (created:)・出典 (source:)・更新日 (updated:) などをここに書いておくと、AIに「いつ書いたメモか」「どこから取った情報か」を一緒に伝えられるようになります。判断材料の鮮度を保つために有効な仕組みです。
たとえば、Markdownファイルの先頭には次のような管理メモを書けます。
--- created: 2026-05-24 updated: 2026-05-25 source: https://example.com/article --- # Obsidianの整理メモ ここから本文を書く
後から別ツールに移しても資産が残るオープン形式
Obsidianの保存形式は公式に「open file formats」と書かれていて、別のエディタやファイルマネージャーでも開けます。途中でObsidianをやめても、AIに渡してきた資産はそのまま残るという意味になります。
特定のサービス専用形式に閉じ込めると、サービス終了や仕様変更で資産が動かせなくなる失敗が起きます。Markdownファイルは標準的なテキスト形式なので、Obsidianをやめてもファイルそのものは別のアプリで読み書きできます。長期で積み上げる前提なら、この性質はかなり重要になります。
Obsidianだけでは足りない4つの限界
Obsidianだけで、すべてのノートを人手で整理しようとすると途中で手が止まります。ノートが数十件なら、フォルダを分けたり、タグを付けたり、不要なメモを消したりできます。ですが、仕事のメモ、調査資料、議事録、作業ログ、過去案件の資料が増えてくると、人間が一つずつ読んで整理するには限界があります。
ここで大事なのは、無理して人手で全部整理しようとしないことです。こんなの一つ一つ人手でやってたら日が暮れます。
Obsidianは、ノートをMarkdownファイルとして保存しておける場所です。つまり、AIに読ませる材料をためる場所として使えます。人間が最初にやるべきなのは、すべてのノートを完璧に整えることではありません。まずは、AIに読ませてもよいフォルダと、まだ読ませないフォルダを分けることです。
たとえば、顧客名や個人情報が残っているメモは除外し、仕事の判断材料として使えそうなノートだけをAIに渡します。そのうえで、要約、分類、重複の整理、見出し付け、関連ノートの洗い出しはAIに任せます。
つまり、Obsidianだけで整理を終わらせる必要はありません。Obsidianは知識の置き場として使い、整理作業の多くはAIに手伝わせる。人間が担当するのは、AIに渡してよい範囲を決めることです。

規模と横断検索の限界
ノート数が増えてくると、Obsidianの全文検索だけでは「関連する判断材料を意味で引く」までは届かなくなります。Markdownナレッジベース全体の規模が、AIのコンテキスト容量を超える壁にも当たります。
コンテキスト容量とは、AIが1回のやり取りで読み込める文章量の上限のことです。何百件もあるノートをまとめて渡すと、容量を超えて打ち切られたり、関連の薄い部分まで詰め込んで回答がブレる原因になります。VectorDB側に進んだとしても何が解決し何が残るかは、関連記事の AIが記憶を持てない理由と「ベクトルDB」が抱える構造的限界を暴く で扱っているので、規模の壁に当たりそうなら参考にしてみてください。
整理そのものと機密判定は別作業
ノートを1テーマ1ファイルに整える作業や、顧客名・個人情報を抜く作業は、Obsidianが肩代わりしてくれる範囲ではありません。整理そのものと機密判定は、人間が手を動かして決める必要があります。
Obsidianは「書く」「保管する」「リンクでつなぐ」までを助けてくれますが、「このノートはAIに渡してよいか」「このメモのこの行は固有情報か」を判定するのは人間の役割です。プラグインで機械的に置換することは可能ですが、最終判断は人が見て確認することになります。
AIに読ませやすいノートの4条件
AIに読ませやすいノートには、Markdown化されている・1テーマ1ファイル・結論と理由が両方ある・固有情報が抜かれているという4つの条件があります。AIに渡したときの回答の安定度は、ツールよりこの4条件で決まります。条件は1から順に通過させると、後工程の手戻りが減ります。

1. Markdownのプレーンテキストで書かれている
1つ目の条件は、ノートがMarkdownのプレーンテキストとして書かれていることです。スキャンPDFや装飾の多いWordのままでは、AIが読み取りで精度を落とします。
スキャンPDFは画像として保存されているため、AIが文字として読み取れない場合があります。装飾の多いWordも、見出しや本文の区別が崩れて読み込まれることがあります。普段の作業からObsidian (Markdown) に書き出しておくと、後工程の変換コストがそのまま下がります。
2. 1ファイルに1テーマだけ入っている
2つ目の条件は、1つのファイルに1つのテーマだけが入っている状態です。日記と作業メモと議事録が同じファイルに混ざっていると、AIはどの文脈で答えるべきか判定できません。
混在ノートは、AIに渡したときの回答ズレの最大の原因になります。1つのファイルには1つの論点・1つの判断・1つのテーマだけを入れる前提にすると、AIが文脈を取りやすくなります。日付ベースの作業ログを1テーマに圧縮する具体例は、関連記事の AIを使って見えた過去資料の正体|25年分の蓄積は本当に資産だったのか? で扱っているので、混在ノートの分解で詰まる場合は参考にしてみてください。
3. 結論と理由が両方残っている
3つ目の条件は、結論だけでなく「なぜそうしたか」も同じファイルに残っていることです。結論だけ・経緯だけのノートは、後から別の場面で使い回す判断材料になりません。
結論だけのノートは「答え」は分かっても、似た場面で同じ判断をしてよいかが分かりません。経緯だけのノートは、何が結論だったのかが読み取れません。2つを1ファイルにまとめておくと、AIに渡したときに「同じ理由が当てはまる別の場面」にも応用できる判断材料として機能します。
4. 顧客名・個人情報などの固有情報が抜かれている
4つ目の条件は、顧客名・案件名・個人情報・認証情報などの固有情報が抜かれていることです。クラウドのAIに送信した情報は取り戻せない可能性があるため、送信前に抜く運用が前提になります。
固有情報の例は、顧客名・社名・案件名・人名・メールアドレス・電話番号・住所・パスワード・APIキーなどです。送信前に抜く運用にしておくと、後から「あの情報を送ってしまった」と気づくリスクを抑えられます。固有情報を残したまま送ると、AI側のログや学習の対象になる可能性があるため、運用としては送る前の段階で抜くのが安全です。
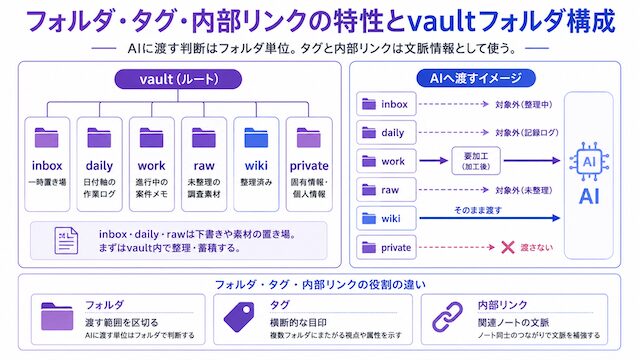
フォルダ・タグ・内部リンクの特性とvaultフォルダ構成
フォルダ・タグ・内部リンクの公式の使い分けルールは存在せず、それぞれの特性から自分なりに役割を決める前提になります。AIに渡すかどうかの判断はフォルダ単位で行い、タグと内部リンクは渡したあとの文脈情報として扱うと運用が安定します。
フォルダは渡す範囲を区切る物理的な仕切り
フォルダは、ノートの主な置き場所を決めるために使います。大事なのは、1つのノートを複数のフォルダ分類にまたがらせないことです。たとえば、同じノートを「仕事」「調査」「AIに渡す候補」のようにフォルダ側で何重にも分類しようとすると、どれをAIに渡してよいのか判断しにくくなります。
そのため、フォルダでは主所属だけを決めます。整理済みのノートは wiki、未整理の資料は raw、個人情報や顧客情報を含むものは private のように置き場所を分けます。こうしておくと、AIに読ませるときに「wiki は渡す」「private は渡さない」「raw は加工してから渡す」と判断できます。
フォルダで細かく分類しすぎる必要はありません。フォルダは、AIに渡す範囲を物理的に切るための仕切りとして使えば十分です。横断的な意味づけは、タグや内部リンクで補えばよいです。
タグと内部リンクは横断と文脈の目印

タグは複数のテーマにまたがる横断的な目印、内部リンクは関連するノート同士の文脈をつなぐ役割と考えると、用途が分かれます。AIに渡すかどうかの判断はフォルダで行い、タグや内部リンクは渡したあとの文脈情報として扱うのが扱いやすいです。
タグ (Obsidianでは #タグ名 の形式で書く) は1つのノートに複数つけられるので、「会議・営業・2026年」のような横断的な属性をつけるのに向きます。内部リンク ([[別ノートのタイトル]] の形式で書く) は、関連するノートを文脈としてつなぐのに向きます。AIには「フォルダ単位で渡す範囲を決め、タグや内部リンクは渡したあとの文脈情報として併用する」という役割分担にすると、判断軸が乱れにくくなります。
vaultフォルダ構成のひとつのモデル
Obsidianの中にノートが増えてくると、あとから「どれをAIに読ませてよいのか」で迷いやすくなります。そのため、最初から完璧に整理しようとするのではなく、AIに渡すかどうかでフォルダを分けておくと扱いやすくなります。
たとえば、下記のように分けます。
inbox:思いついたメモを一時的に入れる場所daily:日付ごとの作業ログを入れる場所work:進行中の仕事メモを入れる場所raw:まだ整理していない調査資料を入れる場所wiki:AIに渡せる形に整理したノートを入れる場所private:個人情報・顧客情報など、AIに渡さないノートを入れる場所
この分け方の目的は、フォルダ名をきれいにそろえることではありません。大事なのは、AIに渡してよい場所を決めておくことです。
たとえば、wiki はAIに渡す対象、private は渡さない対象、raw や work は必要に応じて加工してから渡す対象、というように分けておきます。
こうしておけば、AIにノートを読ませるときに、毎回すべてのファイルを確認しなくて済みます。まず wiki を渡す。必要なら work や raw から一部だけ加工して渡す。private は渡さない。この判断軸があるだけで、ObsidianはAIに読ませる知識置き場として使いやすくなります。
参考までに、BeProでもMarkdownナレッジベース運用としてcc-wikiという3層構造 (raw・wiki・index.md) を採用しています。rawは未整理の調査素材、wikiは整理済みの判断材料、index.mdは入口の索引、という分け方で、個人や小規模事業でも回しやすい構成として参考になります。Markdown LLMナレッジベース全体の組み立て方は、関連記事の AIに過去の記憶を忘れさせない方法|LLMナレッジベースという考え方 で扱っているので、本記事のあとに読むと整理 → 知識置き場構築の流れが見えやすくなります。
AIに渡してよい情報と渡さない情報・起きやすい失敗
ノートをAIに渡すときに一番危ないのは、「とりあえず全部渡せば何とかなる」と考えてしまうことです。仕事のメモや過去資料には、顧客名、個人情報、認証情報、まだ整理していない断片メモが混ざっていることがあります。そのままAIに渡すと、情報漏えいや回答ズレの原因になります。
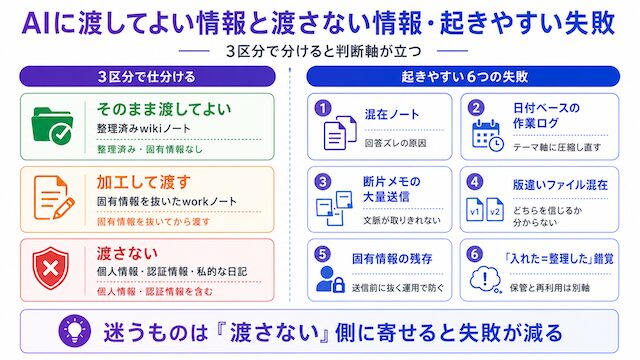
そこで、ノートは最初に3つに分けます。「そのまま渡してよい」「加工してから渡す」「渡さない」の3区分です。整理済みのwikiノートはそのまま渡す。仕事メモは固有情報を抜いてから渡す。個人情報や認証情報を含むノートは渡さない。この分け方を先に決めておくと、AIに読ませる範囲を判断しやすくなります。
3区分での仕分けかた
ノートの仕分けは、すべて人手で細かく読む前提にしなくて構いません。むしろ、ノートが増えてきたら人間だけで全部確認するのは現実的ではありません。もちろん、分類や要約、重複整理はAIにやってもらう前提で考えます。
その前に人間が決めるのは、AIに渡してよい範囲です。
ノートは大きく「そのまま渡してよい」「加工してから渡す」「渡さない」の3区分に分けます。整理済みで固有情報を含まない wiki ノートは、そのままAIに渡す対象にします。仕事の判断材料として使えそうだが、顧客名・案件名・人名などが残っている work ノートは、固有情報を抜いてから渡します。個人情報・認証情報・契約上送信できない情報・私的な日記は、AIに渡さない対象にします。
ここで大事なのは、最初から全ファイルを完璧に整理しようとしないことです。
人間がやるのは、「このフォルダはAIに渡してよい」「ここは加工してから渡す」「ここは渡さない」という境界線を作るところまでです。その境界線ができれば、あとの要約、分類、見出し付け、関連ノートの洗い出しはAIに任せやすくなります。
つまり、3区分は人手整理を増やすためのルールではありません。AIに安全に整理を任せるための入口です。
顧客名や個人情報はAIに処理させる前に分けておく
顧客名・案件名・個人情報が入っているノートは、最初から人間が全部読んで削除しようとすると大変です。現実的には、まず「外に出してはいけない情報が混ざっていそうな場所」を分けるところから始めます。
仕事のメモ、議事録、案件資料、作業ログには、顧客名や人名、メールアドレス、環境名、認証情報に近いメモが混ざっていることがあります。こうしたノートは、いきなりAIに丸ごと渡すのではなく、まず private や work のようなフォルダに分けておきます。そのうえで、AIに渡せる形へ加工する段階では、置換・要約・抽象化をAIに手伝わせます。
たとえば、実名の顧客名を「顧客A」、具体的な案件名を「社内業務システム更改」、個人名を「担当者A」のように置き換える形です。細かい表現を人間が一つずつ直すのではなく、AIに「固有情報を一般化して、仕事の判断材料だけ残す」という作業を任せます。
人間がやるべきことは、すべての固有情報を手作業で消すことではありません。AIに渡してよい範囲と、まだ渡してはいけない範囲を分けることです。最後に、人間は仕上がった内容を確認します。ここで見るのは、元の実名や個人情報が残っていないか、仕事の判断材料として意味が残っているかの2点です。
つまり、顧客名や個人情報の扱いも、全部を人手で処理する必要はありません。人間が境界線を決め、AIに抽象化を任せ、最後に確認する。この流れにすれば、過去資料をAIに読ませる準備はかなり現実的になります。
起きやすい6つの失敗
ノートをAIに渡すときに起きやすい失敗には、混在ノート・日付ベースの作業ログ・断片メモの大量送信・版違いファイル混在・固有情報の残存・「入れた=整理した」錯覚の6つがあります。「保管していること」と「後から使えること」は別軸という基本に立ち戻ると、どこで詰まったかが見えてきます。
混在ノートは1ファイルに複数テーマが入っている状態で、AIの回答ズレの原因になります。日付ベースの作業ログは、日付軸ではなくテーマ軸に圧縮し直してから渡すのが安全です。断片メモの大量送信は、結論と理由がそろっていないメモを大量に渡すことで、AIが文脈を取りきれなくなります。版違いファイル混在は、同じテーマの古い版と新しい版が両方残っていて、AIがどちらを信じるか分からなくなる失敗です。固有情報の残存は4条件で扱ったとおり、送信前に抜く運用で防ぎます。「入れた=整理した」錯覚は、Obsidianに保管した時点で安心してしまい、整理作業を後回しにする失敗です。
仕分け作業はAIに任せてよい
ここで誤解しやすいのは、ノートの仕分けをすべて人手でやる必要があると思ってしまうことです。実際には、全部を人間が一つずつ読んで分類する必要はありません。むしろ、ノートが増えている人ほど、人手で仕分けようとすると途中で止まります。
人間が最初に決めるのは、AIに渡してよい場所と、渡してはいけない場所の境界線です。そのうえで、要約、分類、重複整理、見出し付け、関連ノートの洗い出しはAIに任せた方が現実的です。
一番手っ取り早いのは、Claude CodeにObsidianのvaultフォルダを読ませて、整理候補を出してもらう方法です。Claude Codeはターミナルから使うため、フォルダ内のMarkdownファイルを読ませたり、整理案を作らせたりする作業と相性があります。
ターミナル、つまり黒い画面に抵抗がある場合は、Claude Coworkを使う方法もあります。Claude Coworkは、Claude Codeと同じようなエージェント型の考え方を、Claude Desktop側から使えるようにしたものです。ターミナルを開かずに、複数ステップの作業を任せられるため、黒い画面が苦手な人にはこちらの方が入りやすいです。
Obsidian内で完結させたい場合は、ObsidianのプラグインであるClaudianを使う選択肢もあります。Claudianは、Obsidianのvaultをエージェントの作業ディレクトリとして扱い、ノートの読み書き、検索、編集をObsidian内で行えるプラグインです。
大事なのは、「人間が全部読んで分類する」方向へ戻らないことです。人間がやるのは、AIに渡してよい範囲を決めるところまでです。その範囲の中で、どのノートが整理済みか、どれが重複しているか、どれを要約すべきかは、AIに作業させればよいです。
仕分け作業プロンプト例
Obsidianのvault内にあるMarkdownノートを確認してください。
プロンプト例
Obsidianのvault内にあるMarkdownノートを確認してください。
目的は、AIに渡してよいノートと、加工してから渡すノートと、渡さないノートを分けることです。
次の3区分で一覧を作成してください。
- そのままAIに渡してよいノート
- 整理済み
- 1テーマ1ファイルになっている
- 顧客名・個人情報・認証情報を含まない
- 仕事の判断材料として再利用できる
- 加工してからAIに渡すノート
- 仕事の判断材料として使える
- 顧客名・案件名・人名などの固有情報が残っている可能性がある
- 要約・抽象化・固有情報の一般化が必要
- AIに渡さないノート
- 個人情報を含む
- 認証情報を含む
- 契約上外部へ出せない情報を含む
- 私的な日記や、仕事の判断材料にならない内容
出力形式はMarkdownの表にしてください。
列は下記にしてください。
- ファイルパス
- 区分
- 理由
- 次に必要な作業
注意事項:
- ファイルの中身を勝手に削除しないでください。
- まず分類一覧だけを作成してください。
- 判断に迷うものは「加工してからAIに渡す」に入れてください。
- 顧客名・個人名・認証情報らしきものを見つけた場合は、本文を引用せず「固有情報らしき記述あり」とだけ書いてください。
まとめ
ObsidianはAIの知識置き場として向いている場所ですが、Obsidianに入れただけでは整理にならず、ノートを4条件と3区分で整えて初めてAIに渡せる形になります。フォルダ・タグ・内部リンクの公式の使い分けは存在しないため、自分のvaultのフォルダ構成を「AIに渡す / 渡さない」で切り分けるところから始めるのが安全です。次は、過去資料から結論と理由を抽出する具体例や、LLMナレッジベースという考え方の全体像を扱った関連記事を読んでみてください。




