

ローカルLLMを試してみたけれど、結局どこまで任せていいのか分からない。Mac mini に Ollama を入れて、n8n と組み合わせれば API 費用に縛られずに自動化を量産できる、という期待を持って動かしたのに、いざ自分の業務に当てはめようとすると線引きが曖昧でしんどい。そんな迷いを抱えている個人開発エンジニアに向けた記事です。
クラウドLLM側の進化スピードに対する焦りと、ローカルLLM側のロマンの両方が同時に存在していて、自分の中で判断がぶつかります。API は本当に高いのか、Mac mini で動くサイズはどこまで実用に届くのか、n8n のワークフローでどちらを呼べばいいのか。一律で「クラウドが正解」「ローカルが正解」と決めきれず、結局保留にしてしまう状況です。
この記事は、その判断を「主役 vs 部品」という二分軸でほどき直します。期待 → 現実 → 役割分担の順に経験を並べ、ローカルLLMが部品として残せる場面と、クラウドLLMに寄せたほうがいい場面を、2026年05月10日 時点の数値も交えながら具体化します。
読み終えたとき、自分の業務の中で「ここは部品としてローカルに残す / ここはクラウドの判断に任せる」を切り分ける地図を 1 枚持ち帰ってもらうことを目的にしています。
ローカルLLMに期待していたこと
ローカルLLMをどう運用するかを考えるとき、最初に握っておきたいのは、自分が何を期待してローカルに向かったのかという前提です。ここでは私自身が個人開発の文脈で持っていた 3 つの期待を順に並べます。前提整理として、AI の使い方を 3 形態に分けた入口記事 ChatGPT月額・APIとローカルLLM、何が違うのか:AIの使い方は3種類ある を読了している読者を想定しています。
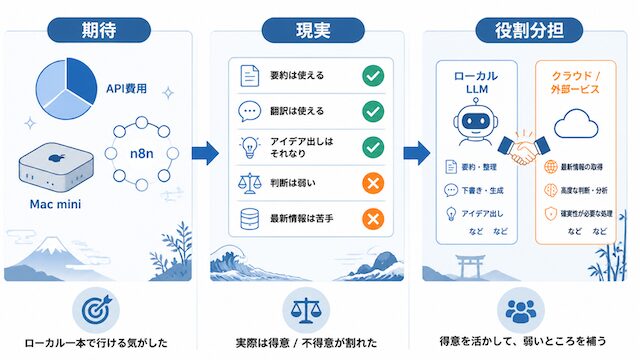
API費用を抑えられると思っていた
クラウドLLMの従量課金に対する読めなさが、ローカルLLMへの動機の中心にありました。月額が固定費で済むなら個人開発の収支が立てやすいという期待を、最初に置いておきます。
n8n のワークフローを増やしていくと、トークン消費量が想像より早く積み上がっていきます。ブログ更新用の要約ノード、SNS 投稿の下書きノード、メール仕分けのノードなどを並列に動かしたくなったとき、API の料金がどこまで請求されるのか・・・。固定費でハードを買い切ってしまえば、ワークフローを増やしても請求が増えない、という発想がローカルLLMへの最初の動機でした。
Mac miniを活かせると思っていた
手元の Mac mini を遊ばせていたこともあり、Ollama でモデルを動かせるのなら使い倒したいという気持ちもありました。新しいハードを買うのではなく、所有資産を活かす発想からスタートしています。
Apple Silicon の Mac mini はメモリ帯域とユニファイドメモリの恩恵で 7B〜27B クラスを動かせる範囲があり、新たに数十万円のハードを足さなくても始められる感覚がありました。手順面では別記事の 探しても友達は増えない。ならAIで作っちゃえ!Mac miniで個人ローカルAI環境を構築 で構築の流れを書いています。本記事は構築後の運用判断側のテーマなので、環境構築の詳細はそちらに譲ります。
n8nと組み合わせれば個人でも武器になると思っていた
n8n のワークフローからローカルLLMを呼べれば、サブスクや API に課金しきれない個人開発でも自動化を量産できると期待していました。「自分の時間を増やす道具になる」という言い方が、当時の動機に一番近いです。
n8n の HTTP Request ノードから Ollama にリクエストを投げれば、ワークフロー全体をローカルで完結できます。トークン課金の上限に怯えずに、自分の業務をどんどん自動化に流し込めるはずだ、というイメージで動き始めました。
実際に使って見えたローカルLLMの現実
期待を持ったまま動かしてみると、得意なところと不得意なところが想定よりはっきり分かれました。ここではユースケース単位で、何が起きたかを書き出します。実機環境は Mac mini 24GB に Ollama を入れ、qwen3.6:27b-q4_K_M を中心に試しています。
要約や分類なら使える
短い入力に対して定型的な出力を返す処理 (短文要約・ラベリング) では、Mac mini で動く 7B 〜 27B クラスでも実用範囲に届く感覚がありました。完璧ではないが、用途次第で許容できる精度に収まります。
例えば公開済み記事を 50〜180 字の短文要約に落とすタスクや、受信メールを少数ラベルに分類するタスクは、出力の癖を 1 度プロンプトに織り込んでしまえば安定して回りました。最終チェックを人がやる前提のタスクなら、品質要件を満たす範囲に収まります。
判断や設計になると弱さが出る
一方、文脈を踏まえて意図を整理するような「判断」「設計」のタスクに振ると、出力の崩れが目立ちました。記事構成を任せたり仕様を整理させたりすると、手戻りのコストが積み上がっていきました。
具体的には、3,000 字を超える記事の見出し設計を任せると、論点の重複・粒度のずれ・対象読者像のブレが起きやすく、結局クラウドLLMで作り直すという二度手間になりました。1 度動かして「これは部品ではなく主役の領域だ」と自分の中で線が引けた瞬間です。
エージェント用途では止まりやすい
ツール呼び出しを連鎖させるエージェント用途では、待ち時間が積み上がり、途中で指示の意図が崩れる場面が増えました。「動く」と「使える」は別軸で評価する必要があるという感覚が、ここで強まりました。
ファイル読み込み・編集・コマンド実行を 5 ステップ以上連鎖させるような使い方では、各ステップで数十秒の待ち時間が乗り、合計で 5〜10 分待つ間に意図が崩れるケースがありました。エージェント実装そのものの解説は本記事の範囲外ですが、現時点ではエージェントの主役にローカルLLMを置く運用は採用していません。
クラウドLLMとの差は知能差として出る
体感した不採用ポイントを少し抽象化すると、コストや速度ではなく「知能差」として説明したほうが筋がいい部分が出てきます。差が出やすい場所を 3 つに分けて並べます。作業種別ごとの効率差という上位フレームについては AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 で詳しく書いていますので、本記事と合わせて読むと境界感覚が補強できます。
長い文脈を扱うほど差が出る
コンテキスト長が長くなる処理ほど、ローカル LLM とクラウド LLM のフラッグシップとの差が顕在化しやすいです。記事全体を踏まえた設計や、長い議論を踏まえた応答ほど、差は広がる印象でした。
短い入力に対する短い出力では差が見えにくくても、入力が数千トークンを超えてくると、ローカル側は「序盤の指示」と「終盤の指示」のどちらに重みを置くかで揺れる場面が出ます。クラウドLLMのフラッグシップでは、その揺れが体感で目立ちにくい範囲に収まりやすい、という感覚です。
指示の解釈力で差が出る
同じプロンプトをどう解釈するかのレイヤーでも差が出ます。クラウド LLM は曖昧な指示の意図を汲んで補ってくれますが、ローカル LLM では表層通りに動きやすい場面が目立ちました。
例えば「読みやすく整えてください」という指示に対して、クラウド側は読者像を推定して文体・段落・リズムを総合的に整える方向に動いてくれます。一方、ローカル側では字面の整形 (改行・記号・敬体への揃え) に止まりやすく、もう 1 段抽象的な指示の補完が必要になりました。
手戻りの少なさで差が出る
一度の出力でどこまで通るかという総合点で、差が積み上がっていきます。手戻りの回数が増えると、節約したはずの API 費用や時間が逆方向に削られます。
ローカルで 3 回試行 → クラウドで仕上げ、という流れになると、ローカルで節約したつもりの時間がトータルで赤字に振れることがあります。「ローカル側の試行回数 × 1 回あたりの待ち時間」を見ると、判断系のタスクは最初からクラウドに寄せたほうが速い、という結論に落ち着きました。
APIは高いという思い込み
期待のうち最初に挙げた API 費用への不安は、2026年05月10日 時点の数値を確認すると、想像より細かい話になっていました。一律「高い / 安い」で語ると判断を間違いやすい場所を、ここでほどいておきたいと思います。
ローカル環境にも見えないコストがある
ハード代・電気代・モデル更新の手間など、ローカル側にも金額に出ないコストが乗っています。東電従量電灯 B 第 3 段階で RTX 4090 を 24 時間回した粗算は月およそ 13,120 円という上限側の数字を、ひとつの目安として置いておきます (2026年05月10 確認)。
これは常時フル稼働を仮定した上限側の試算なので、家庭で個人開発に使う場合の実際の電気代はこれより低くなる前提です。一方、Mac mini で運用する場合は消費電力が小さいため電気代の重みは下がりますが、代わりにモデル選定・量子化フラグの調整・モデル差し替えの手間といった「人件費としての時間」が見えにくいコストとして残ります。
小型APIは自動化の部品として使いやすい
クラウド側の小型 API モデル (gpt-4o-mini / GPT-4.1 Nano / Gemini Flash-Lite など) は input $0.10 〜 $0.15 帯で、自動化の部品として使うときに刺さる単価帯になっています (2026年05月10日 確認)。ただし Anthropic Haiku 4.5 ($1.00 / $5.00) のように同じ「軽量」でも数倍高い例外があるため、一律「激安」と断じることはしません。
「軽量モデル = 全部安い」という前提でワークフローを組むと、特定プロバイダの請求が想定外に膨らむ可能性があります。n8n のノード単位で使うモデルを切り替えるときは、プロバイダごとの単価帯を都度確認することが安全です。具体的な月額試算は次の記事 n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算 で扱っています。
個人開発では先払いより従量課金の方が軽い
月固定費を払う前提でハードを買うより、低頻度の処理を従量課金で回すほうが個人開発のキャッシュフローに優しい場面が多いです。本当に重いのは金額そのものより「読めなさ」だと感じています。
「読めなさ」に対する処方箋は、ハードを買い切ることではなく、ワークフローごとの月間トークン上限を見える化することのほうです。固定費に逃げると、使っていないワークフローの維持費まで払うことになりやすく、個人開発の機動力を落とします。
ローカルLLMが使える場面
「使えなかった」だけで終わらせると判断軸が片側に寄りすぎます。ここでは個人開発・n8n 自動化の文脈で、ローカル LLM を部品として残せた具体場面を 4 つ挙げます。
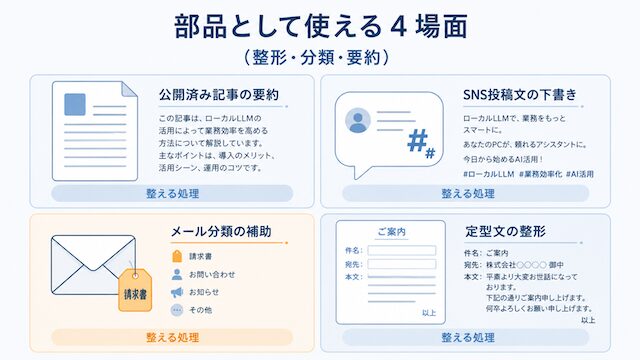
公開済み記事の要約
既に公開した記事を 50 〜 180 字に短縮するような短文要約は、ローカル LLM でも実用ラインに届きやすいです。社外秘でもないので API でやってもいいですが、頻度を上げるならローカル側に寄せて運用負荷を下げられます。
公開済み記事は本文がそのままの長さで残っているので、毎回新規にプロンプトへ流し込んで要約だけ生成する処理は典型的な「整える処理」になります。月に数十本の要約を回す前提なら、ローカル側に置いた方がトークン課金の累積を気にせずに済みます。
SNS投稿文の下書き
記事タイトルや本文の一部を入力して X / SNS 投稿文の下書きを生成する処理も、ローカル LLM で回しやすいです。最終チェックは人がやる前提なら、品質要件は許容範囲に収まります。
下書きは「複数案を並べる」「文字数の制約を満たす」「ハッシュタグを付ける」程度の整形で済むため、判断成分は薄い処理です。最終的に人がチェックして 1 案を選ぶ前提なら、ローカル側で 3 案出してもらうところまで任せられます。
メール分類の補助
受信メールを「最優先 / 請求 / 広告 / 問い合わせ / その他」のような少数ラベルに分けるタスクは、Mac mini で動くサイズでも安定して回りやすいです。実機検証 (Mac mini 24GB + qwen3.6:27b-q4_K_M) でも分類は通りました。
メール分類の典型的なプロンプトは、入力メール本文に対してラベル 1 つだけを返させるテンプレで十分機能します。ラベル候補を限定し、それ以外は「その他」に倒すと出力ブレを抑えられます。
あなたはメール分類器です。
以下のメール本文を読み、次のラベルから 1 つだけ選んで出力してください。
ラベル候補: 最優先 / 請求 / 広告 / 問い合わせ / その他
出力はラベル名 1 語のみとし、説明文・記号・改行を含めないでください。
メール本文:
{{ $json.body }}
n8n の HTTP Request ノードから Ollama (localhost:11434) を呼ぶときの最小構成は、エンドポイントに /api/generate を指定し、JSON ボディに model・system・prompt を 3 行で詰めるだけで動きます。
{
"model": "qwen3.6:27b-q4_K_M",
"system": "あなたはメール分類器です。ラベル名 1 語のみを出力してください。",
"prompt": "{{ $json.body }}"
}
このリクエストを n8n の HTTP Request ノードで POST すれば、後段ノードでラベル別に分岐するルーティングが組めます。判断側 (返信文の作成・優先度の最終判定) はクラウドLLMに渡し、ラベル付けだけをローカル側に置くと、API 課金の発生量を抑えつつワークフロー全体の精度を保てます。
定型文の整形
議事メモや作業記録を整形して見た目を整える処理は、ローカル LLM の得意領域に収まりやすいです。テンプレに乗せて回すだけのタスクは、ここに置いても大きな問題は出にくいです。
「箇条書きに揃える」「敬体に揃える」「日付フォーマットを揃える」のような整形タスクは判断成分が薄く、ローカル側で繰り返し回しても品質が安定します。テンプレ自体を 1 度クラウドLLMで設計しておけば、運用フェーズはローカルに渡す、という分担が現実的です。
ローカルLLMを主役にしない方がいい場面
逆に、本記事の判断軸として「主役にしない」と決めた領域も並べておきます。ここを誤ると、せっかくの試みが手戻りで重くなります。
記事設計
構成を組み立てる作業は、長文の文脈・意図の補完・判断軸の整合が必要で、現時点のローカル LLM では出力が粗くなりやすいです。判断側の作業はクラウド LLM に寄せたほうが、結果的に速く着地します。・・・というか全く機能しません。
H2・H3 の粒度を揃え、対象読者像をぶらさず、論点の重複を避けるという作業は、表層整形ではなく判断の積み重ねです。ここに 27B クラスを当てると、整っているように見えても粒度や論点の整合が崩れる場面が出てきます。
仕様整理
要件・仕様の整理も、行間を読むタスクが多く、ローカル側で回すと意図が落ちやすいです。ここは AI 自動化の出発点になる工程なので、品質を落とすと後段全体に響きます。
仕様整理を間違えると、後段の自動化ワークフロー全体の前提がずれます。最初の段階で意図を取りこぼすと、それ以降のすべてのステップで補正が必要になるため、コスト的にも判断側の品質を最優先にしたい工程です。
重要な返信文
取引先・顧客向けのメール返信のような、文体や礼節が結果に直接効く処理は、ローカル LLM 主役で回すと事故が起きやすいです。下書きとしてローカルを使い、最終はクラウド側で整える運用が現実的です。
返信文の文体ミスは送信後に取り戻しにくいため、許容ラインを高めに置きたい処理です。下書き生成だけローカルに任せ、最終チェック・トーン調整はクラウド側に通す 2 段運用にすれば、リスクを抑えつつコストも下げられます。
失敗すると手戻りが大きい処理
「精度 70 〜 80% で許容できるか」を考えたとき、失敗時の手戻りコストが大きい処理はローカル側に置かない判断をしたいです。許容ラインの設定が、主役 vs 部品を最終的に切り分けるフィルタになります。
精度 70〜80% で問題ないタスクはローカル側に置けますが、失敗 1 件が後段に大きな波及を起こすタスクは、最初からクラウド側に寄せたほうが結果的に手戻りコストが低くなります。判断軸は「平均精度」ではなく「失敗 1 件あたりの波及範囲」で見ると整理しやすいです。
個人がAIを使うなら役割分担で考える
「主役 vs 部品」を実際の運用に落とし込むとき、私はモデル名で考えるのではなく、処理の役割で分けるようにしています。ここではその切り分け方を 3 つに整理します。
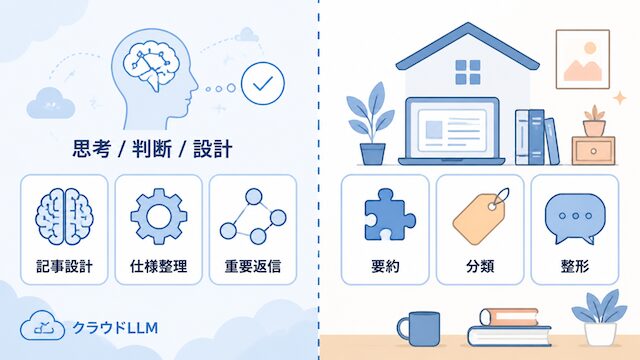
考えさせる処理はクラウドLLMに寄せる
文脈解釈・判断・設計など、考える成分が強い処理はクラウド LLM 側に集約します。ここの品質を落とすと、後段の自動化が連鎖的にズレていきます。
判断側のレイヤーは、ワークフロー全体の前提を作る場所です。ここで削った時間は後段で必ず取り戻されてしまうので、最初からクラウドLLMのフラッグシップに任せる前提で予算を組んだ方が安全です。
整える処理はローカルLLMに寄せる
入出力パターンが決まっている整形・分類・要約などは、ローカル LLM 側に寄せて月額固定費とプライバシー要件を取り戻します。クラウド側に投げる必要が薄い処理を見極めることが、設計の核になります。
業務の中で「入力」「処理」「出力」を分解したときに、入出力パターンが事前に決められる処理はローカル側に倒せます。逆に、入力パターンが毎回違う・出力の判断軸が状況で変わる処理は、ローカルに置くと運用負荷が跳ね上がります。
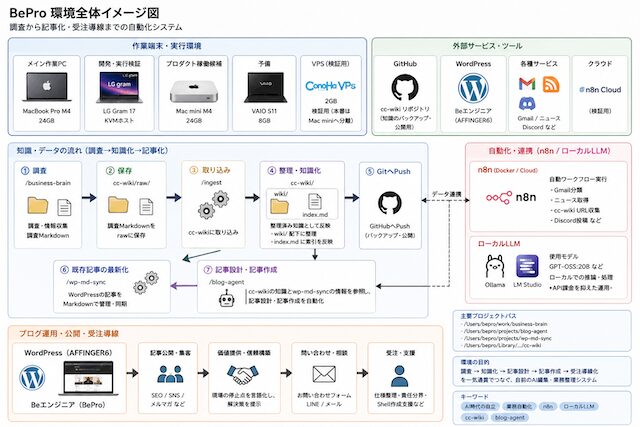
n8nでは処理ごとにモデルを分ける
n8n のワークフローでは、ノード単位でモデルを分けることで、同じパイプライン内に「考える層」と「整える層」を共存させられます。一律一モデルではなく、ノード単位で適材適所を組むのが扱いやすいです。
n8n では HTTP Request ノードの設定をノードごとに変えられるので、判断ノードはクラウドLLMの API、整形ノードは Ollama のローカルエンドポイント、というふうに混在させられます。「ワークフロー全体を 1 モデルで揃えなければならない」という制約は実は無いので、業務分解 (入力 / 処理 / 出力) を済ませた上でノードごとに最適なモデルを当てると、コストと品質のバランスが取りやすくなります。
業務分解 (入力 / 処理 / 出力) と、その先の自動化設計までまとめて伴走してほしい、という場合は Beエンジニアのお問い合わせフォームよりご相談ください。仕様整理・業務整理・自動化設計の依頼として承っています。
まとめ
最後に、ローカルLLMとクラウドLLMの使い分けを整理しておきます。ただ、今回の整理で見えてきたのは、ローカルLLMとクラウドLLMの使い分けだけではありません。
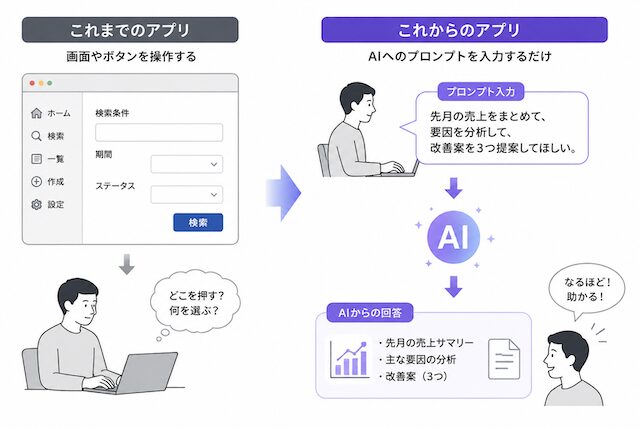
SaaSやアプリの形そのものが、今後は大きく変わっていく可能性があります。
これまでのアプリは、画面、ボタン、メニュー、フォームを人間が操作するものでした。今後は数年以内にAIへのプロンプトを入口して、ユーザーは細かい画面操作ではなく、やりたいことをプロンプトで伝えるようになります。その先の処理手順、判断、出力形式は、AI側が組み立てる方向へ進んでいきます。
つまり、個人開発で本当に見るべきなのは「どんなアプリを作るか」ではなく、「どの業務をAIへの依頼として切り出せるか」です。
ローカルLLMを主役にしなかった理由も、そこにつながります。重要なのはモデル名ではなく、仕事を分解し、AIに渡せる形へ変えることです。
ローカルLLMは主役ではなく部品として使う
「ロマンで終わるのか」という問いに対する自分の回答は、「主役にせず、部品として残す」でした。ここを起点に運用設計を組み直すと、ローカル LLM への希望は消えずに残ります。
要約・SNS下書き・メール分類・定型文整形の 4 場面をローカル側の定位置として確保しておけば、ハードへの初期投資もムダにはなりません。「主役に据えなかった」だけで「使わなかった」わけではない、という言い方が自分の感覚に近いです。
クラウドLLMは判断と設計に使う
判断と設計は、現時点ではクラウド LLM のフラッグシップに任せる前提で組みます。fact-check 由来の数値で見ても、個人がローカルで実行可能な規模で総合性能が継続的にクラウドの最高峰を超えた事例は確認できていません (2026年05月10日 時点)。
将来この前提が変わる可能性は否定しませんが、今日設計するワークフローはあくまで現時点の力関係に合わせて組みます。判断側にお金を払うことに納得できると、自動化全体の設計が安定します。
個人が見るべきなのはモデル名ではなく仕事の分解
最終的に重要なのは「どのモデルが強いか」ではなく、「自分の業務をどう分解して何を任せるか」のほうです。仕様整理・業務整理・自動化設計を一度通すと、ローカル LLM もクラウド LLM も無理なく置けるようになります。
自分の業務を入力・処理・出力に分解しておけば、新しいモデルが出るたびに「全置き換え」を考える必要はなくなります。分解さえ済んでいれば、強くなった部分のモデルだけを差し替えれば済みます。
関連記事
ローカルLLMの判断軸を、別の角度から補強したい場合は以下の記事も合わせてどうぞ。
- 探しても友達は増えない。ならAIで作っちゃえ!Mac miniで個人ローカルAI環境を構築 — Mac mini に Ollama を入れて個人ローカル AI 環境を立ち上げる手順記事です。本記事で扱った「主役 vs 部品」の運用判断の前段として、環境構築側の解説を担います。
- AIで速くなるエンジニア・遅くなるエンジニア|作業種別ごとの効率差 — 作業種別ごとに AI 活用の効率がどう変わるかという上位フレーム記事です。本記事の「クラウドLLMとの差は知能差として出る」H2 の前提として、思考タスクと作業部品の境界感覚を補強します。
次に読む記事
ローカルLLMを部品として残す位置付けが固まったら、次は API 側の課金構造を押さえる回に進めます。
- n8nでAI自動化するとAPI課金が膨らむ理由:構造と用途別の月額試算 — n8n × クラウドLLM API の課金構造を分解し、用途別の月額試算を示す判断分離記事です。本記事で確保したクラウド側の判断・設計レイヤーが、月額でいくらに見えるかを具体化します。




