

ChatGPT や Claude Code を仕事で使うようになると、ある時点から必ず同じ壁にぶつかります。先週調べたはずの内容を、AI は今週もう覚えていません。「うちのサービスは個人事業主向けで、料金プランは月額制で」と毎回前提を貼り直し、調査結果はチャット履歴の中で散らばり、同じ質問をしているのに昨日と今日で違う答えが返ってくる。便利なはずの AI が、いつのまにか手間を増やす道具に変わってしまうあの感覚です。
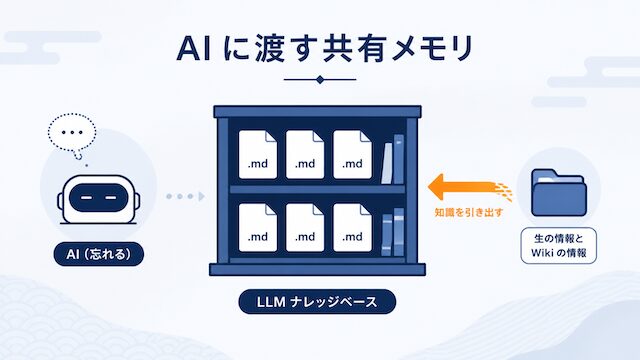
この問題は AI の性能不足ではなく、AI に渡す「外部の本棚」を持っていないことが原因です。コンテキストウィンドウは作業机にすぎません。机の上に毎回必要な資料を置き直すのではなく、本棚から必要な資料を取り出す仕組みを、私たち側で持つ必要があります。その本棚として最も低コストで始められるのが、Markdown でつくる LLM ナレッジベースという考え方です。
本記事では、Beエンジニアが実際に運用している cc-wiki という Markdown ベースのナレッジ基盤を題材に、raw / wiki / index.md / GitHub / Claude Code 参照ルール を役割で分離する設計と、それを個人事業 / ブログ運営 / AI駆動開発 の三用途で再利用する方法を整理します。Claude Code × Obsidian 系の流行記事が「自動運用」「自己増殖」「MCP 接続」を強調するのに対し、本記事はもっと手前の話、つまり「Markdown Wiki で十分な範囲」と「RAG / ベクトルDB に移行すべき範囲」の境界線を引くことに焦点を当てます。
読み終えるころには、あなたは「AI の記憶を補うために何をどこに置けばよいか」「最初の 1 ファイルをどのフォルダに作ればよいか」「いつ Markdown を卒業して RAG に進むべきか」を判断する地図を手にしているはずです。流行のツール構成ではなく、一度作れば三つの仕事に効く再現可能な型として持ち帰っていただければと思います。
AI が過去の調査を忘れる体験
AI を実務に使い始めた人が最初にぶつかる壁は、ほぼ例外なく「忘れる」ことです。先月時間をかけて調べた競合サービスの料金体系、自分のサービスの強みの言い回し、よく使うコマンドの注意点。これらはチャットの中に確かにあったはずなのに、新しいウィンドウを開いた瞬間、AI は何も知らない初対面の相手に戻ります。
問題はそれだけではありません。同じ質問を別日に投げると微妙に違う答えが返ってくる、Claude Code が以前は採用してくれた設計方針を急に否定し始める、ChatGPT が固有名詞の表記を勝手に変える。これらすべての根本原因は同じで、AI 側に「揺れない前提」が外部から渡されていないことです。
この記事で扱うこと・扱わないこと
この記事で扱うのは、Markdown ファイルと GitHub だけで作る最小構成の LLM ナレッジベースです。具体的には raw と wiki のフォルダ分離、index.md でのエントリ提示、CLAUDE.md による参照順序のルール化、GitHub による複数端末同期、そして個人事業 / ブログ運営 / AI駆動開発 の三用途で同じ構成を使い回す考え方を扱います。
一方で、RAG パイプラインの実装手順、ベクトル DB のセットアップ、MCP サーバの構築や接続詳細、Obsidian プラグインや CLI を使った高度な自動化、WordPress への自動投稿フローは扱いません。これらは Markdown Wiki が手狭になった「次の段階」の話であり、最初の本棚を持っていない段階で導入すると、運用が破綻しやすくなるからです。
なぜ AI は前提を忘れるのか
AI が過去の調査を忘れるのは性能不足ではなく、モデルが扱う「記憶の形」の構造的な性質によるものです。ここでは「机と本棚」の比喩で記憶構造を整理し、続けて ChatGPT や Claude Code の判断が毎回揺れる本当の理由を切り分けます。
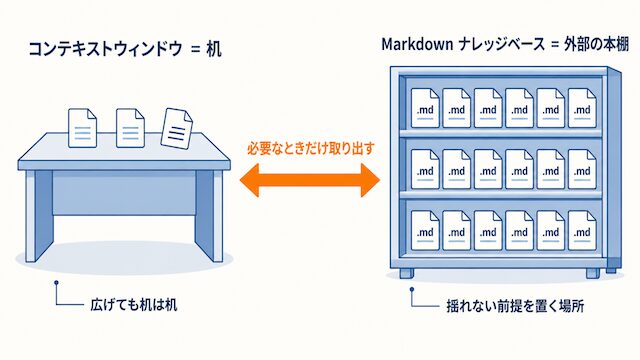
コンテキストウィンドウは「机」であって「本棚」ではない
LLM のコンテキストウィンドウはよく「記憶」に例えられますが、より正確には「机の広さ」です。机の上に置いた資料は読めますが、机から下げた瞬間に AI は何も知らない状態に戻ります。長文を扱える最新モデルでも、机の広さが広がっただけで、本棚を持ったわけではありません。
長期記憶を実現するには、机の外に「本棚」を置き、必要なときだけ机の上に資料を持ってくる仕組みが要ります。この本棚は AI 自身が管理するものではなく、人間側で構造を決めて管理するものです。Markdown Wiki という選択肢は、その本棚をテキストファイルとフォルダ構造だけで実現する、最も素朴で最も壊れにくい解です。
ChatGPT・Claude Code の判断が毎回揺れる本当の理由
ChatGPT や Claude Code の判断が日によって揺れる理由は、モデルの確率性だけではありません。多くの場合、揺れの正体は「前提の不在」です。同じ質問でも、机に乗っている資料が違えば答えは変わります。前提が口頭で渡されたり、過去のチャット履歴に埋もれたりしている限り、再現性は永遠に得られません。
逆に言えば、前提を Markdown のかたちで一カ所に固定し、AI に「まずここを読め」と指示できれば、判断のばらつきは大幅に減ります。揺れを抑えるのに必要なのは賢いモデルではなく、揺れない前提を渡す側の設計です。
Markdown で作る LLM ナレッジベースという考え方
AI に渡す「本棚」を最も低コストで持つ方法が、Markdown ファイル群の活用です。本セクションではまず Markdown を本棚として持つ意味を整理し、続けて RAG やベクトル DB を否定せずに「Markdown Wiki で十分な場面」の境界線を引きます。
「外部の本棚」を Markdown で持つ
ナレッジベースと聞くと、専用 SaaS や Notion、最近ならベクトル DB を思い浮かべる方が多いと思います。しかし AI に読ませる本棚としては、プレーンな Markdown ファイル群が最も扱いやすい場面が多くあります。理由は単純で、AI 自身が Markdown を最も得意な形式として読み書きできるからです。
Markdown であれば、テキストエディタでも Obsidian でも VS Code でも開けます。バージョン管理は Git で済み、複数端末の同期は GitHub で完結します。専用ツールに依存しないため、3 年後にツールを乗り換えても資産はそのまま残ります。AI に渡す共有メモリとしては、これ以上シンプルな器はありません。
RAG / ベクトルDB を否定しないが、まず Markdown で十分な場面
誤解のないように補足すると、本記事は RAG やベクトル DB を否定する立場ではありません。数千件以上のドキュメント横断検索、自然言語による曖昧検索、社内 Wiki の全社展開といった用途では、ベクトル検索の価値は明確です。
ただし個人事業や個人ブログ、数名規模のチームによる AI駆動開発では、扱うドキュメントは数十〜数百ファイル程度であることが大半です。この規模では、フォルダで分類された Markdown を CLAUDE.md のルールで参照させるだけで、ほとんどの「忘れる」問題は解決します。最初からベクトル DB を組むより、まず Markdown で骨格を作り、限界が見えてから移行するほうが事故が少ないというのが実務側の感覚です。
llm-wiki 構成の役割分離
Markdown で LLM ナレッジベースを作るという考え方は、AI を使い込むほど強くなっていきました。ChatGPT や Claude Code に何度も同じ前提を説明し直し、過去の調査や判断が会話の外に流れていくたびに、この使い方には限界があるのではないかと感じていました。
その矢先に、アンドレイ・カーパシー氏が SNS で Wiki 的な知識整理の考え方に触れている「llm-wiki」投稿を知りました。そこで見えたのは、AI に記憶そのものを期待するのではなく、人間側が読み返せる外部の本棚を用意し、AI に必要なときだけ参照させるという方向性です。
そこから、個人で扱える最小構成として Markdown と GitHub を使った LLM ナレッジベースの可能性を模索するようになりました。本記事で扱う llm-wiki の考え方は、自分だけで突然思いついたものではなく、カーパシー氏の発信をきっかけに、実務で扱える形へ落とし込んだものです。
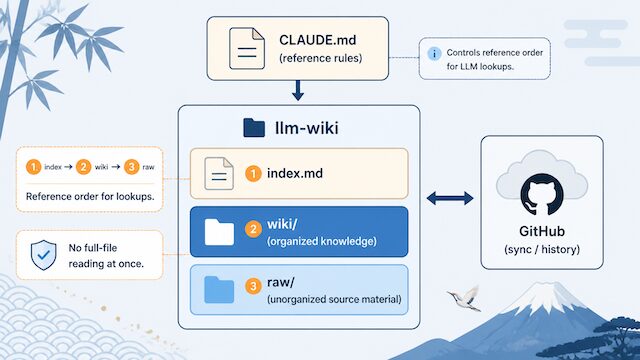
ここからが本記事の中心です。Markdown だけで本棚を作るとき、フォルダ構造を「役割」で分けることが運用の成否を決めます。Beエンジニアが運用している cc-wiki も含めて、最小構成は次の 5 つの役割に分かれます。
ディレクトリの最小構成例は次のとおりです。
llm-wiki/
├── CLAUDE.md # AI への参照ルール (raw と wiki の役割・参照順序)
├── index.md # 本棚のエントリポイント (目次)
├── raw/ # 未整理の調査素材 (走り書き・引用・原文メモ)
│ ├── 2026-05-01-competitor-research.md
│ └── 2026-05-03-pricing-notes.md
└── wiki/ # 整理済み知識 (再利用前提のまとまった文書)
├── service-overview.md
├── pricing-policy.md
└── article-style-guide.md
raw — 未整理の調査素材
raw は調査・走り書き・引用・原文メモを置く場所です。命名は日付プレフィックスで十分で、整理されていなくて構いません。むしろ「整理する前にまず置ける場所」があることが重要で、raw を省くと、メモがチャット履歴やデスクトップに散らばるという最初の問題に逆戻りします。
raw は「まだ AI に頻繁に読ませない」前提で運用します。AI に毎回読み込ませる対象を raw まで広げると、未整理の情報がノイズになり、判断の揺れがむしろ増えます。
wiki — 整理済み知識
wiki は、再利用を前提とした「整った文書」を置く場所です。サービス概要、料金ポリシー、記事スタイルガイド、設計判断のログなど、複数のチャットセッションをまたいで参照したい知識をここに集約します。
wiki のファイルは frontmatter を最小限つけ、本文は短くまとめるのが扱いやすい運用です。
ここでは、wiki 配下に置く整理済み知識の例として、サービス概要ページを作成します。wiki/service-overview.md の最小サンプルは次のようになります。
--- title: "サービス概要" updated: "2026-05-08" tags: ["service", "overview"] --- # サービス概要 ## 提供価値 - 個人事業主向けの AI 活用環境整備支援 - ブログ運営・記事制作フローの構築 ## 想定顧客 - 既に AI を触っているが、運用が属人化している個人事業主・少人数チーム ## 関連 - pricing-policy.md - article-style-guide.md
index.md — エントリポイント
index.md は本棚の目次であり、AI が最初に読むファイルです。ここにすべての内容を書くのではなく、wiki 配下の主要カテゴリと代表的な参照先だけをまとめます。
データが増えてくると、index.md にすべてのファイルを並べるだけでは膨張します。そのため、index.md は入口にとどめ、詳しい説明は service-overview.md や pricing-policy.md のような個別ファイルへ分けます。
さらに規模が大きくなったら、「ブログ運営ならこのファイル」「料金方針ならこのファイル」「記事ルールならこのファイル」という参照先を分けるルーター用のファイルを用意します。
# LLM-WIKI 目次 ## サービス関連 詳しい内容は wiki/service-overview.md を参照する。 ## 料金関連 詳しい内容は wiki/pricing-policy.md を参照する。 ## 記事制作ルール 詳しい内容は wiki/article-style-guide.md を参照する。
AI はまず index.md を読むことで、必要な情報がどのファイルにあるかを判断しやすくなります。
GitHub — バージョン管理と複数端末同期
GitHub はバージョン管理と複数端末同期の役割を担います。Mac と Windows、自宅と外出先、個人アカウントと業務アカウントを行き来しても、wiki が常に最新であることを保証してくれます。さらに変更履歴が残るため、「いつどの判断を更新したか」を後から追えます。
プライベートリポジトリで運用すれば、外部に公開せずに済みます。CI もデプロイも不要で、push と pull だけで成立する運用です。

また、このナレッジを GitHub にアップしておくことで、副次的な効果もありました。特定の端末や作業ディレクトリに閉じず、どこからでも Claude Code が同じナレッジを参照できるようになったことです。
Claude Code 参照ルール (CLAUDE.md で順序を明示)
最後の鍵が CLAUDE.md です。Claude Code はプロジェクト直下の CLAUDE.md を自動で読み込むため、ここに「raw と wiki の役割」「どの順番で何を参照するか」「raw に未整理情報があってもいきなり結論にしない」といったルールを書いておきます。例えば次のようなブロックです。
## llm-wiki 参照ルール 役割: - wiki/ — 整理済みの知識。判断の根拠として優先的に参照する。 - raw/ — 未整理の調査素材。wiki に該当が無い場合のみ参照する。 - index.md — wiki/ のエントリ。最初に読む。 順序: 1. index.md を読み、関連 wiki ファイルを特定する。 2. 該当する wiki ファイルを読み、判断の根拠とする。 3. wiki に無い場合に限り raw/ を確認する。 4. raw に基づく判断は「未確定情報」として明示する。 制約: - 全ファイルを一括で読み込まない (前提が混ざるため)。 - raw の内容を確定情報として本文に出さない。
このルールをプロジェクトに置いておくだけで、Claude Code の振る舞いが目に見えて安定します。揺れを抑えるのは賢いモデルではなく、参照順序の明示です。
三つのユースケースで使い分ける
同じ llm-wiki 構成は、個人事業 / ブログ運営 / AI駆動開発 の三つの仕事で同じ型のまま使い回せます。一度作れば三度効く投資先である、という点が Markdown ナレッジベースの最大の経済性です。
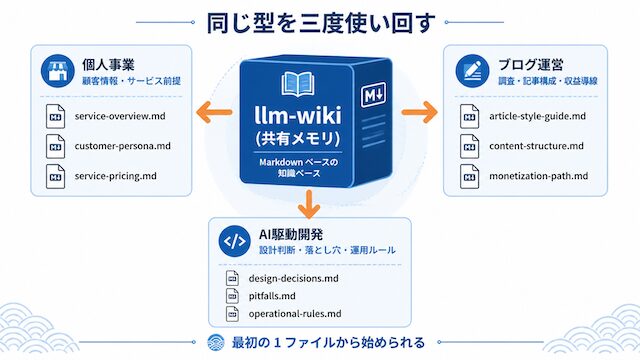
個人事業 — 顧客情報・サービス前提・営業履歴の固定化
個人事業では、サービスの前提・料金ポリシー・想定顧客像・FAQ・過去の営業のやり取りといった情報を AI に安定して渡したい場面が多くあります。これらを wiki に集約しておけば、提案文や見積もりの叩き台、問い合わせ返信の下書きを AI に作らせるたびに「うちは個人事業で・・云々」と説明し直す手間がなくなります。
raw 側には新規顧客との初回ヒアリングメモを置き、後から wiki/customers/<案件名>.md に整える運用にすると、案件ごとの履歴がそのままナレッジに変わります。
700GBの資料(資産)が3GBまで整理された!

個人事業でAIに過去の記憶を持たせる場合、最初からVectorDBへ寄せる必要はありません。
実際に過去資料を整理してみると、元の業務資産は約700GBありました。設計書、議事録、調査資料、手順書、設定メモ、障害対応の記録などが混在していて、そのままではAIに渡せる状態ではありませんでした。
しかし、それらをそのまま保存対象にするのではなく、顧客固有情報を除外し、判断理由・設計意図・運用手順・障害対応・再利用できる観点だけをMarkdownへ抽出していくと、ナレッジとして扱う容量は約3GBまで圧縮されました。
ここで重要なのは、容量が小さくなったことではありません。
散らばっていた過去資料が、Obsidian上でつながりを持った知識として見えるようになったことです。グラフビューで確認すると、個別のメモが孤立したファイルではなく、案件、設計判断、運用、障害対応、Shell、AI活用といった単位で結びついていることがわかります。
この状態になると、AIに渡したいのは「700GBの原本すべて」ではなく、「判断に使える形へ整理された3GBのナレッジ」になります。
今のところ、この運用ではVectorDBへの乗り換えは必須とは考えていません。Markdownで構造化し、Obsidianで関係性を確認し、必要な範囲をAIに渡せる状態にしておけば、個人事業レベルのナレッジベースとしては十分に機能します。
VectorDBは、大量の文書から検索精度を高めたい場合には有効です。ですが、そもそも原本が整理されていない状態でVectorDBへ入れても、AIが扱いやすい記憶にはなりません。先に必要なのは、検索基盤ではなく、何を残し、何を捨て、どの判断を再利用できる形にするかという整理です。
個人事業で固定化すべき記憶は、すべての過去資料ではありません。
顧客情報、サービス前提、営業履歴、作業判断、設計理由、過去に詰まった原因、次に同じ失敗を避けるための条件です。これらをMarkdownで積み上げておけば、AIは単なるチャット相手ではなく、自分の事業判断を支える外部記憶として使えるようになります。
ブログ運営 — 過去の調査・記事構成・収益導線設計の参照
ブログ運営では、過去に調べた競合記事の構造、自分の記事スタイルガイド、収益導線の設計方針、内部リンクのルールなどを wiki にまとめておきます。新しい記事を書くたびに「うちのスタイルでは」「過去にこれは扱った」を AI に思い出させる必要がなくなり、記事の一貫性が保たれます。
raw には日々の記事ネタの走り書きや、調査中のリンク群を置きます。Beエンジニアではこの仕組みが blog-agent と接続されており、cc-wiki/wiki を参照したうえで新規記事の Brief や下書きを生成する運用になっています。Markdown Wiki は単独で完結するだけでなく、別のエージェントの参照基盤にもなります。
AI駆動開発 — 設計判断・既知の落とし穴・運用ルールの蓄積
AI駆動開発では、設計判断の理由、過去にハマった落とし穴、採用しなかった選択肢とその理由、運用ルール、命名規約などを wiki に蓄積します。Claude Code に新機能の実装を依頼するとき、これらを参照させることで「以前と矛盾する設計」「すでに却下した案」を持ち出してくる事故が減ります。
始め方の最小構成
最初から大きな構成を作る必要はありません。まずは、調査メモを置く raw と、整理済みの知識を置く wiki を分けるだけで十分です。
raw には、調査中のメモや検証中のコードスニペットを置きます。まだ正しいか分からない情報、あとで使うかもしれない情報は raw に置きます。wiki には、確認が終わって今後も使うと決めた情報だけを置きます。AI に優先して読ませたい内容は、raw ではなく wiki に整理します。
最初に作るファイルは、次の5つだけで構いません。
llm-wiki/
├── CLAUDE.md
├── index.md
├── raw/
└── wiki/
└── service-overview.md
この構成では、CLAUDE.md に AI の参照ルールを書き、index.md に wiki 全体の目次を書きます。raw は未整理メモ置き場、wiki は整理済み知識置き場です。
ディレクトリ作成と raw / wiki の最初の 1 ファイル
最初の一歩は驚くほど小さくて構いません。任意のディレクトリで次のようにフォルダを作り、wiki に「自分のサービス概要」を 1 ファイルだけ書きます。
最初の wiki ファイルとして、wiki/service-overview.md に自分のサービス概要を書きます。
mkdir -p llm-wiki/raw llm-wiki/wiki cd llm-wiki touch index.md CLAUDE.md touch wiki/service-overview.md
最初の wiki ファイルは、下記のサンプルのように 30行程度のサービス概要を書きます。完璧な構成を考えるより、1 ファイル書いて Claude Code に読ませてみる方が、運用イメージが圧倒的につかみやすくなります。
# サービス概要 - 提供価値:個人事業主向けに AI 活用環境を整える - 対象顧客:AI を触っているが運用が属人化している人 - 支援内容:ブログ運営、記事制作フロー、作業自動化の整理 - 関連資料:pricing-policy.md、article-style-guide.md (省略)
この程度でも、Claude Code に読ませると「この人は何を支援しているのか」「どの資料を次に見ればよいのか」を判断しやすくなります。完璧な構成を考えるより、まず1ファイル作って読ませる方が運用イメージをつかみやすくなります。
CLAUDE.md に参照ルールを書く
次に CLAUDE.md に、前章で示した参照ルールのブロックを貼り付けます。Claude Code をこのディレクトリで起動した瞬間から、ルールが効き始めます。最初は短いルールで構いません。運用しながら「ここで揺れる」「ここで前提が混ざる」と気づいた箇所を、ルールに 1 行ずつ足していくのが現実的です。
# Claude Code 参照ルール - 最初に index.md を読む - 整理済みの判断材料は wiki/ を見る - 未整理の調査メモは raw/ を見る - wiki/ と raw/ の内容が違う場合は wiki/ を優先する
この程度のルールでも、Claude Code は「どこから読むか」「何を優先するか」を判断しやすくなります。運用しながら、前提が混ざる箇所や判断が揺れる箇所を 1 行ずつ追加していきます。
GitHub に push して同期する
最後に GitHub に push して、複数端末から触れる状態にします。プライベートリポジトリで構いません。
git init git add . git commit -m "init: llm-wiki の最小構成" git branch -M main git remote add origin git@github.com:your account/llm-wiki.git git push -u origin main
リモート URL は自身の GitHub アカウントとリポジトリ名に合わせて読み替えてください。push が通ったら、別の端末で git clone するだけで本棚を持ち運べます。これで、AI に渡す共有メモリの初期構築が完了です。
ハマりどころ
Markdown Wiki の運用で実際に起こりやすい代表的な失敗パターンを 3 つ先に共有します。raw への書きっぱなし、index.md の欠落、全ファイル一括読み込みの許可、いずれも回避できれば運用が大きく安定します。
raw に書きっぱなしで wiki 化しない
最も多い失敗が、raw にメモを置きっぱなしにして、wiki に昇格させないパターンです。raw だけが膨らむと、結局「散らばったチャット履歴」と同じ状態になり、AI も人間もどこを信じればよいか分からなくなります。週 1 回 30 分でよいので、raw を見直して wiki に昇格させる時間を必ず確保してください。
ちなみに面倒くさがり屋の私は、毎日夜中の定時に/ingest-and-pushというcommandを作成して自動で対象mdファイルアップして言います。
index.md がないと AI がエントリを見失う
index.md を省くと、AI は wiki 配下を片っ端から読もうとして、コンテキストを浪費します。結果として「全部読んだのに何も覚えていない」状態になりがちです。index.md は完璧な目次でなくてよく、wiki 配下のファイル名と 1 行説明を並べた一覧で十分です。
# LLM-WIKI 目次 ## 最初に読むファイル - wiki/service-overview.md:サービス概要。誰に何を提供するかを書く - wiki/pricing-policy.md:料金方針。料金の考え方を書く - wiki/article-style-guide.md:記事制作ルール。文体・構成・禁止事項を書く ## 未整理の情報 - raw/:調査中のメモや検証途中の情報を置く
この程度でも、AI は「サービスの話なら service-overview.md」「料金の話なら pricing-policy.md」「記事制作の話なら article-style-guide.md」を見ればよいと判断しやすくなります。
「全部読み込み」を許すと前提が混ざる
CLAUDE.md に参照順序を書かず、「困ったら全部読んで」と任せると、AI は raw と wiki を区別せずに読み始めます。この状態になると、未整理の調査メモと整理済みの判断材料が混ざります。さらに、読むファイルが増えるほどコンテキストも膨らみ、制限に早く到達しやすくなります。
その結果、AI は多くの情報を読んだように見えても、重要な前提を保持しきれず、判断が揺れやすくなります。CLAUDE.md には、最初から参照順序を書きます。まず index.md を読む。整理済みの判断材料は wiki を優先する。raw は未整理情報として扱う。この順番を決めておくだけで、AI が読む範囲を絞りやすくなります。
いつ Markdown Wiki から RAG / ベクトルDB に移行するか
Markdown Wiki に留まり続けるべきか、RAG やベクトル DB に進むべきかは、運用が成熟してから判断する論点です。配下では、移行を検討する目安を「件数・粒度・横断検索の必要性」の 3 軸で整理します。
件数・粒度・横断検索の必要性で判断する
Markdown Wiki にも限界はあります。目安としては、wiki ファイルが数百を超え、ファイル名や index.md だけでは目的の情報にたどり着けなくなったとき。あるいは、自然言語での曖昧検索 (「去年の値上げ前後の議論はどこ」のような問い) が日常的に必要になったとき。チームメンバーが増え、Markdown を直接編集する運用が回らなくなったとき。これらが揃ってきたタイミングが、RAG やベクトル DB を検討する潮時です。
逆に、これらの兆候がない段階でベクトル DB を導入すると、運用コストとデバッグコストが先行し、本来欲しかった「揺れない前提」が手に入る前に疲弊します。Markdown で骨格が固まっているほど、後から RAG に移行するときの設計もシンプルになります。先に器を最小で持ち、限界を確認してから次に進む、という順序を強くおすすめします。
なお、AI の記憶構造そのものや、ベクトル DB が抱える構造的な限界については、別記事「AIが記憶を持てない理由と「ベクトルDB」が抱える構造的限界を暴く」「AIの限界を超える設計とは何か──記憶と継続性の再定義」「AIが避け続ける"時間"という領域──最も人間に近づく構造を持たない理由」で概念面を整理しています。本記事の Markdown Wiki が「なぜ十分なのか」を概念から確認したい方は、合わせて参照してください。
まとめ
AI が過去の調査を忘れるのは、AI 側に外部の本棚が無いからです。本棚は専用 SaaS でもベクトル DB でもなく、まずは Markdown ファイルと GitHub だけで十分作れます。要は raw と wiki を役割で分け、index.md でエントリを示し、CLAUDE.md で参照順序を明示し、GitHub で同期する、というだけです。
この最小構成は、個人事業の前提固定、ブログ運営の文体・収益導線・調査の固定、AI駆動開発の設計判断と落とし穴の蓄積、という三つの仕事に同じ型のまま使い回せます。Markdown Wiki は流行のツール構成ではなく、「AI に渡す共有メモリ」を最小コストで持つための型です。一度作れば、AI が忘れることに振り回される時間を、別の仕事に回せるようになります。
関連して読む記事
Markdown Wiki で AI の「忘れる」を補う考え方は、AI の記憶構造そのものに踏み込むほど納得感が増します。本記事の前提となる概念面は、以下の記事で整理しています。




