
「AI を使うエンジニアと使わないエンジニアでは、本当に生産性に差が出るのか」という問いは、現場でも発注側でも繰り返し議論されています。SNS では「AI で 10 倍速くなった」という声がある一方、Microsoft Research が示した 55% 短縮や、METR 研究が示した熟練者で 19% 遅くなったという結果が並列で流通しており、読み解き方を間違えると判断を誤ります。
本記事は、作業種別ごとの効率差マトリクスを軸に、定量データ・逆効果になる条件・受託発注側の解釈指南までを一気通貫で整理します。AI 活用に懐疑的な現場エンジニアと、ベンダーの AI 活用度を評価したい発注検討中のクライアントの双方が、自分の判断基準を持てる状態をゴールにしています。
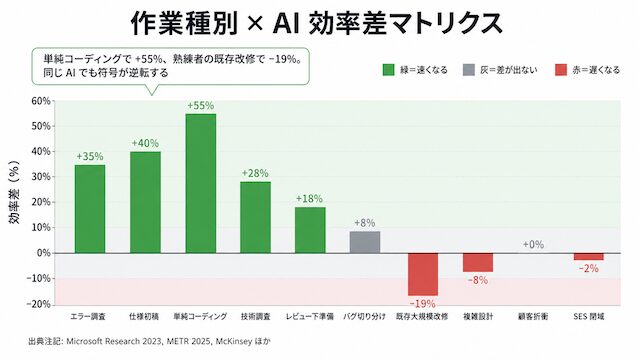
結論:差は出る。ただし作業種別で大きさが違う
結論から言うと、AI を使うエンジニアと使わないエンジニアの間に差は確実に出ます。ただし「すべての作業で 10 倍速い」は誇張であり、実態は次の三層に分かれます。
- 速くなる領域: 単純コーディング・エラー調査・ドキュメント初稿・技術調査・レビュー下準備
- 差が出ない領域: 顧客折衝・SES の閉域作業
- 遅くなる領域: 大規模既存改修・複雑なシステム設計
Microsoft Research の制御実験では HTTP サーバー実装で 55.8% の時間短縮が確認されました(1 時間 11 分 vs 2 時間 41 分、プロ開発者 95 名対象、2023 年)。一方、METR が 2025 年 7 月に発表した研究では、熟練 OSS 開発者 16 名・246 タスクで 19% 遅くなる結果が出ています。同じ「AI 利用」でも、対象タスクの性質によって符号が逆転するという事実を、まず受け入れる必要があります。
「10 倍速い」が起こる条件と起こらない条件
「10 倍速い」という体感は、単一作業の速度差ではなく複数工程の積み重なりで起こります。具体的には次の四条件が重なったときです。
- 調査・整理・記述が連続するタスク(各ステップ 2 倍が 5 段重なれば全体は大きな差になる)
- エラー調査・原因切り分けが頻発する現場
- 経験が浅い、または馴染みの薄い技術領域
- ドキュメント・仕様整理の比率が高い現場
逆に、起こらない条件は以下です。
- 単一の複雑なロジックを一気通貫で考える設計判断
- 巨大な既存コードベースで暗黙の前提が多い改修
- 人間との合意形成が成果物の中核を占める折衝業務
- 機密情報の関係で AI に貼れない閉域作業
「10 倍」の数字を正面から検証した研究は存在しないため、本記事では「複数領域の局所的 2〜3 倍が積み重なって体感が膨らむ構造」として扱います。
作業種別ごとの効率差マトリクス(10 領域)
主要研究と国内事例を突き合わせ、作業領域ごとの差の出やすさを 10 区分で整理します。
| 作業領域 | 差の出やすさ | 主な根拠 | 差のイメージ |
|---|---|---|---|
| エラー調査・ログ解析 | 大 | スタック検索 vs AI 貼り付け | 30〜60 分が 5〜10 分 |
| 仕様整理・ドキュメント初稿 | 大 | 国内事例の定性報告 | 2〜3 日が半日以下 |
| 単純・反復コーディング | 大 | Microsoft Research 55.8% | 2h41m が 1h11m |
| 技術調査・選定比較 | 大 | 情報収集と整理の速度差 | 1 日が 2〜3 時間 |
| コードレビュー下準備 | 中〜大 | セルフレビューで指摘漏れ減 | 指摘密度が向上 |
| バグ原因の切り分け | 中(条件付き) | 再現手順を渡せれば速い | 数時間が 30〜60 分 |
| 既存大規模コード改修 | 小〜逆効果 | METR 19% 遅延 | 文脈読み込みコストが勝つ |
| 複雑なシステム設計 | 小 | McKinsey 10% 未満 | 判断は人間に残る |
| 顧客・関係者折衝 | ほぼなし | 対人は AI 範囲外 | 変化なし |
| SES 閉域作業 | ほぼなし | 外部接続禁止が多い | ツール持込不可 |
速くなる領域(エラー調査/仕様初稿/単純コーディング/技術調査/レビュー下準備)
速くなる領域に共通するのは、入力情報を構造化して渡せれば AI が適切な候補を返せる点です。エラー調査は典型例で、スタックトレースと再現手順を貼り付けるだけで原因候補が出ます。ドキュメント初稿はゼロから書く時間がほぼゼロになり、レビュー下準備はセルフレビューの観点出しを AI に肩代わりさせられます。
GitHub Autofix のセキュリティ脆弱性修正が約 3 倍速という発表もあり、決まった型のある修正では加速が大きくなります(GitHub 自社発表のため独立検証は限定的、という留保は付けます)。
ほとんど差が出ない領域(顧客折衝/SES 閉域作業)
顧客折衝は対人コミュニケーションが本質で、AI は議事録整理や要件メモの清書には使えても、信頼関係の構築や曖昧な要件の言語化を引き出す役割は人間に残ります。SES の客先常駐環境では、外部 SaaS への接続禁止・機密情報の持ち出し禁止という構造制約があり、現場での AI 活用そのものが封じられているケースが多くあります。
ただし「客先外の事前調査」「機密情報を含まない汎用的なエラーパターン」「議事録・引き継ぎ資料」では差が出るため、すべての SES 案件で AI が使えないわけではありません。
逆に遅くなる領域(大規模既存改修/複雑設計)
METR が 2025 年 7 月に発表した研究は、AI 活用議論の前提を一段階厳密にしました。熟練 OSS 開発者 16 名・246 タスクの実プロジェクト Issue 対応で、AI を使った場合に 19% 遅くなったという結果です。さらに重要なのは、被験者自身は「20% 速くなった」と主観的に感じていたという点です。客観の遅延と主観の加速が真逆という現象が、最も注意すべきサインです。
複雑なシステム設計でも、McKinsey 調査は複雑タスクで 10% 未満の改善にとどまると報告しています。設計判断はビジネス要件・チーム能力・運用コストの統合で、AI は選択肢を出せても決定者の思考を省けません。
なぜ熟練者は 19% 遅くなるのか — METR 研究の読み解き
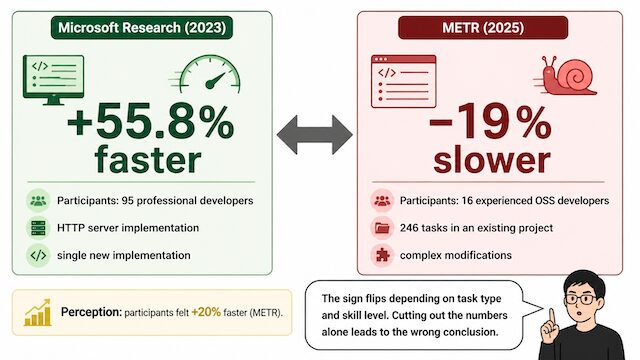
熟練者が既知のプロジェクトで Issue を解く場合、コードベースの暗黙の前提・命名の歴史的経緯・モジュール間の依存関係は熟練者の頭の中に既に格納されています。ここに AI を介在させると、AI が文脈を持たないため、プロンプトとして文脈を文章化して渡す作業が新たに発生します。
熟練者にとって「思い出す 5 秒」と「AI に渡すために 200 行の前提を書き出す 5 分」は、明らかに後者のほうが遅いのです。
「合っているように見えて間違い」検証コスト
AI 出力は構文的に整っており、もっともらしいコードが返ります。ところが既存のコーディング規約・ドメイン制約・パフォーマンス要件と微妙にずれた提案が混ざります。熟練者ほど違和感に気付き、検証に時間を使うため、結果として「自分で書いたほうが速かった」という事象が積み上がります。
Faros AI が 10,000 人超・1,255 チームのテレメトリで観察した「PR マージ数 +98%、レビュー時間 +91%、DORA 指標は変化なし」という結果も、この検証コストの増大を裏付けています。出力量は増えるがチーム全体のスループットは変わらない、という「AI 生産性パラドックス」が起きているわけです。
使えるエンジニア/使えないエンジニアを分けるもの
同じ AI を使っても、使い手で差が出ます。差を生む要素を三つに整理します。
検証力・文脈判断・構造理解
AI 出力を「合っているか」で見るのではなく「どの前提のもとで合っているか」で見られるかが分岐点です。具体的には次の三つです。
- 検証力: 出力を実行・テスト・反例で確かめてから採用できるか
- 文脈判断: 自プロジェクトの規約・制約に照らして取捨できるか
- 構造理解: 提案コードがどのレイヤーに属し、どこに副作用が及ぶかを読めるか
これらは AI が肩代わりできない部分で、エンジニアの仕事の中核として残り続ける領域です。
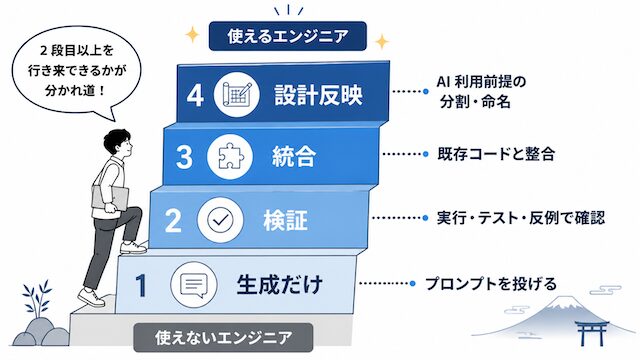
AI への委ね方の階層(生成だけ→検証→統合→設計反映)
AI 活用の成熟度は次の四段階で捉えると整理しやすいです。
- 生成だけ: AI 出力をそのまま貼り付けて終わる
- 検証: 出力をテスト・実行・レビューで確かめてから採用する
- 統合: 既存コード・既存仕様と整合させて取り込む
- 設計反映: AI 利用を前提とした分割・命名・ドキュメント設計を行う
差が出るエンジニアは 2〜4 段階目を行き来します。差が出ないエンジニアは 1 段階目で止まっているか、AI を全く使っていないかのいずれかです。
コード例: AI に渡す前のコンテキスト整形(プロンプト雛形)
「使えるエンジニア」は、AI に渡す前の整形を惜しみません。次は、機能追加を AI に依頼する前のプロンプト雛形です。雑に「いい感じに書いて」と聞かないだけで出力品質は大きく変わります。
# 目的 注文確定 API に在庫引当ロジックを追加したい # 前提 ・フレームワーク: NestJS 10 / TypeScript 5.4 ・DB: PostgreSQL 15、ORM は Prisma ・既存テーブル: orders, order_items, inventory ・制約: 在庫引当は orders.status を pending → confirmed に遷移させる時のみ # 既存コード(抜粋) (confirmOrder メソッドの現状実装を 30〜60 行貼る) # 既存スキーマ (schema.prisma の関連モデルを貼る) # 期待する出力 1. 在庫引当を追加した confirmOrder の実装案 2. トランザクション境界の説明 3. 失敗時のロールバック手順 4. 既存テストに追加すべきケースの一覧
このフォーマットの肝は、目的・前提・既存コード・期待する出力を分けて渡す点です。AI は「何を返せばよいか」が明確になり、検証可能な構造で答えを返せるようになります。
#直近のエラーログ 50 行 + 関連環境変数 + アプリのバージョンをまとめてコピー
{
echo "## エラーログ(直近 50 行)"
tail -n 50 /var/log/myapp/error.log
echo ""
echo "## 環境変数(機密を除く)"
env | grep -E '^(NODE_ENV|APP_|DB_HOST|DB_PORT)='
echo ""
echo "## アプリバージョン"
cat package.json | grep '"version"'
} | pbcopy
pbcopy は macOS のクリップボードコピーで、Linux なら xclip -selection clipboard に置き換えます。コピーした内容を、次のような問い方で AI に貼り付けます。
以下のエラーログから、可能性の高い原因候補を 3 つ挙げてください。
各候補について「根拠となるログ行」「再現確認のための最小手順」「対処方針の選択肢」を示してください。
(ここに pbcopy したログを貼る)
「原因」「根拠」「再現手順」「対処方針」を分けて聞くだけで、AI 出力は確認可能な形に揃います。これを知っているかどうかで、エラー調査時間に数十分単位の差が出ます。
受託案件における意味 — 発注側の視点
ここまでは現場エンジニア向けの整理でした。発注検討中のクライアントが、ベンダーの AI 活用度をどう評価すべきかに視点を移します。
ベンダーが AI を使うと、納期・見積・品質保証はどう変わるか
AI 併用前提のベンダーと、そうでないベンダーでは、見積・納期・品質保証の構造が変わります。
- 納期: 仕様初稿・調査・テストコード生成で短縮余地が大きい。一方、設計判断や複雑改修は短縮しにくい
- 見積: 単純実装の工数が圧縮される反面、AI 出力のレビュー工数が新たに計上される。総額が単純比例で下がるとは限らない
- 品質保証: AI 出力をそのままコミットしないことを前提とした検証プロセス(自動テスト・型チェック・コードレビュー)が組まれているかが論点
「AI を使っているから安い・速い」を額面通りに受け取るのは危険です。Faros AI のテレメトリが示すように、PR 数が倍増しても DORA 指標が変わらないチームは存在します。出力量と成果の乖離を見抜く視点が必要になります。
「AI 使えます」ベンダーを評価する 3 つの観点
発注側がベンダーの AI 活用度を評価するときに使える、実用的な観点を三つ挙げます。
- 用途の切り分けが言語化されているか: 「どの作業に AI を使い、どの作業に使わないか」を明確に答えられるベンダーは、上で示した作業種別マトリクスを持っています。「全部 AI で速くやります」と答える相手は、検証コストの増大を見えていない可能性があります。
- レビュー・検証プロセスが提示できるか: 自動テストのカバレッジ、PR レビューのチェックリスト、AI 出力の取り扱いポリシー(機密情報を投入しないなど)を提示できるかは、品質保証の成熟度の指標になります。
- 見積の内訳に「検証工数」が立っているか: 設計工数とコーディング工数だけが並ぶ見積は、AI 時代の現実と合いません。レビュー・検証・統合のラインアイテムが妥当な比率で計上されているかを確認すると、運用品質を予見できます。
なお、関連する実例・関連解説として、当社が公開している AI 活用に関する論考記事も参考になります。Beエンジニアの「AI editorial logic 01」では、AI 出力を検証・統合する編集姿勢の話を扱っており、本記事の作業種別の切り分け論と補完関係にあります。
ハマりどころ・注意点
実務に持ち込む前に押さえておきたい落とし穴を整理します。
- 数字の単純引用は危険: Microsoft の 55.8% は HTTP サーバー実装の単一実験、METR の 19% 遅延は熟練者・既知プロジェクト限定の条件付きです。一般論として持ち出すと判断を誤ります
- 主観の加速と客観の遅延は乖離する: METR 研究の被験者は「20% 速くなった」と感じていました。自社のチームでも、体感ではなくリードタイム・PR マージ後の手戻り率で測ることが必要です
- 機密情報の投入は事前合意が必須: SaaS 型 AI への入力は、契約・法務・情報セキュリティ規程の観点で必ず事前確認します。SES の閉域案件ではローカル実行可能な AI の検討が選択肢になります
- AI 出力の「もっともらしさ」を疑う運用: 構文が整っていても、API 仕様が古い・規約と不一致・エッジケースが抜けるのは日常茶飯事です。テスト・型チェック・人間レビューの三段構えで受ける運用が前提です
まとめ:AI は「差を埋める」のではなく「差を広げる」
AI は使い手の差を埋めるテクノロジーではなく、差を広げるテクノロジーです。検証力・文脈判断・構造理解を持つエンジニアは、AI を増幅器として使えます。一方、出力をそのまま貼って終わるエンジニアは、生産速度が上がっているように見えて、レビューと手戻りで全体のスループットが変わらない、あるいは下がる側に回ります。
発注側にとっての意味は、ベンダーの AI 活用は単純な値下げ要因ではなく、検証プロセスの成熟度を含めて評価すべき複合指標になったということです。「AI 使えます」と答えるベンダーに対し、用途の切り分け・レビュー体制・見積の内訳を確認できるかどうかで、リプレース後の運用品質が決まります。
本記事の作業種別マトリクスと評価観点を、自社の現場あるいはベンダー選定の判断材料として持ち帰っていただければ幸いです。




