

Pythonのコードを分けて整理した瞬間、突然importが通らなくなった経験はありませんか。
実はそれ、Pythonがファイルを「どの場所から」「どの順番で」探しているかを理解していないことが原因です。
Pythonは実行時に明確な探索ルールを持ち、ディレクトリ構造や環境変数をもとにファイルを認識しています。
この記事では、その“見えない仕組み”を分解し、実行パスとファイル構造の関係を理解することで、再利用性と安定性の高いプロジェクト設計へつなげる考え方を紹介します。
Pythonの基礎知識(基礎編)
🟣 Pythonの基礎知識(基礎編)
📌基本文法から実用テクニックまで、Pythonの土台を固めるステップアップ講座
└─ 【Pythonの基礎知識(基礎編)】仕組みから学ぶ思考と自動化のプログラミング講座
├─ STEP 0:Pythonを動かす“仕組み”を理解する
| ├─【Pythonの基礎知識】Pythonを動かす環境とは何か? “自分専用の環境”を作る
| ├─【Pythonの基礎知識】Hello Worldの裏側にある実行の仕組み
| └─【Pythonの基礎知識】Pythonのファイル構造と実行パスを理解する
|
├─STEP 1:Pythonで“考える仕組み”を作る(思考編)
| ├─【Pythonの基礎知識】データ型で世界を定義する|数・文字・真偽の正体
| ├─【Pythonの基礎知識】変数と値の動きを通して仕組みを理解しよう
| ├─【Pythonの基礎知識】条件分岐で“判断を任せる”仕組みを作る
| ├─【Pythonの基礎知識】for文で“人の手”を離す仕組みを作る
| └─【Pythonの基礎知識】while文で“継続する仕組み”を作る
|
├─STEP 2:Pythonで“情報を扱う仕組み”を作る(構造編)
| ├─【Pythonの基礎知識】コレクション型の正しい選び方(list, tuple, dict, set)
| ├─【Pythonの基礎知識】リストで情報を整理し、仕組みに流れを持たせる
| ├─【Pythonの基礎知識】辞書型でデータを“意味”で管理する
| └─【Pythonの基礎知識】集合型で重複を排除し、無駄をなくす仕組みを作る
|
├─STEP 3:Pythonで“動きを再利用する仕組み”を作る(関数・モジュール編)
| ├─【Pythonの基礎知識】関数で処理を再利用する|“人間の手順”を仕組みに変える
| ├─【Pythonの基礎知識】引数と戻り値で“情報のやりとり”を自動化する
| ├─【Pythonの基礎知識】モジュールとパッケージで“仕組みを部品化”する
| └─【Pythonの基礎知識】importの裏側を理解し、コードを分離する設計思考
|
├─STEP 4:Pythonで“データを扱う仕組み”を作る(入出力・永続化編)
| ├─【Pythonの基礎知識】ファイル操作でデータを読み書きする仕組みを作る
| ├─【Pythonの基礎知識】CSVを自在に扱う仕組みを作る
| ├─【Pythonの基礎知識】JSONで構造化データを操る
| └─【Pythonの基礎知識】例外処理で“壊れない仕組み”を設計する
|
└─STEP 5:Pythonで“自動化する仕組み”を作る(応用実践編)
├─【Pythonの基礎知識】スクリプトを自動実行させる仕組みを作る
├─【Pythonの基礎知識】日次タスクを自動化して人の時間を解放する
├─【Pythonの基礎知識】外部APIを活用して作業を外部化する
└─【Pythonの基礎知識】ログを記録して仕組みの信頼性を高める
Pythonがファイルを認識する仕組みを理解する
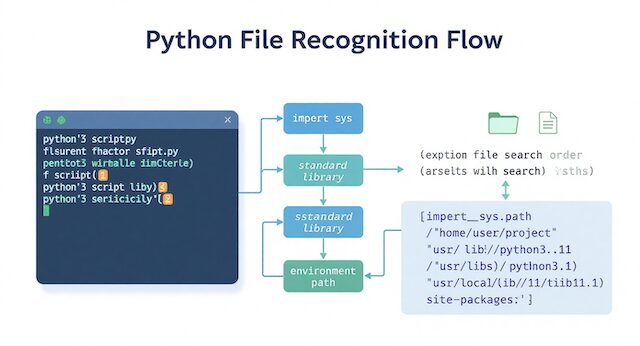
Pythonがファイルをどう認識しているかを理解することは、開発の安定性を左右する重要な基礎です。
ファイルを分割した途端にimportが失敗するのは、Pythonが「どの位置を起点にコードを読み込むか」を厳密に判断しているからです。
Pythonは実行時にファイルの配置と実行パスを照合し、どのモジュールを参照するかを決定します。
この仕組みを正しく理解すれば、構造の複雑なプロジェクトでも、エラーの原因を理論的に説明し、確実に再現できるようになります。

スクリプトファイルとモジュールの違いを整理する
まず押さえておきたいのは、「スクリプト」と「モジュール」は目的が異なるということです。
スクリプトは直接実行されるファイル、モジュールは他のスクリプトから読み込まれるファイルを指します。
Pythonはファイルを実行するとき、最初に`__name__`という特別な変数を自動で設定します。
この仕組みが、プログラムの入口と再利用の仕組みを分けているのです。
[ sample_main.py ]
# sample_main.py
import sample_module
if __name__ == "__main__":
print("メインスクリプトとして実行中")
[ sample_module.py ]
# sample_module.py
print("モジュールが読み込まれました")
コンソールにて下記コマンドでsample_main.pyを実行します。
python3 sample_main.py
【出力例:】
モジュールが読み込まれました
メインスクリプトとして実行中
このように、モジュールはimport時に一度だけ読み込まれ、スクリプトとして実行した場合は__name__が"__main__"になります。
この仕組みを理解しておくと、複数ファイルを組み合わせても「どこから実行されたか」が明確になります。
import文がファイル構造をどう辿るのかを把握する
Pythonのimportが失敗する原因は、コードの誤りではなく「実行している環境」にあります。
Linuxでは、ターミナルを開いた直後はBashというシェルが動作しており、この状態でPythonの構文を入力しても理解されません。

LinuxでPythonを動かすには、まずPythonインタプリタを起動する必要があります。この操作を行うコマンドが python3 です。
$ python3
>>>
これでプロンプトが「$」から「>>>」に変わります。
この「>>>」が出れば、Pythonインタプリタが起動して命令を受け付けている状態です。
>>> import sys
>>> print(sys.path)
【出力例:】
['', '/usr/lib64/python39.zip', '/usr/lib64/python3.9', '/usr/lib64/python3.9/lib-dynload', '/usr/lib64/python3.9/site-packages', '/usr/lib/python3.9/site-packages']
ここに表示されているリストが、Pythonがモジュールを探す検索ルートです。
最初に現在の作業ディレクトリを確認し、見つからなければ標準ライブラリ、さらに環境変数PYTHONPATHの順に辿っていきます。
LinuxでPythonを使うときは、まずpython3で環境を起動し、sys.pathで探索ルートを確認します。
これがimportエラーを防ぐ基本手順です。
実行パス(sys.path)の基本を理解する
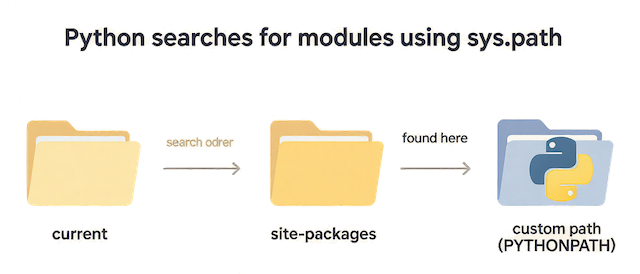
Pythonで「モジュールが見つからない」というエラーが出る場合、その多くは実行パス(sys.path)の仕組みを理解していないことが原因です。
sys.pathは、Pythonがモジュールを読み込む際にどのフォルダを順番に探すかを管理するリストです。
これを理解しておくことで、プロジェクトが大規模になっても正確にファイルを読み込ませることができます。
Pythonがモジュールを探す順序を確認する
Pythonがモジュールを探索する際の順番は固定されています。
まず、現在実行中のスクリプトが置かれているディレクトリを最初に探し、見つからない場合は標準ライブラリのフォルダ、さらに外部パッケージ(site-packages)へと進みます。
この順序を理解していないと、別の場所にあるモジュールを誤って読み込んだり、同名ファイルの競合が発生することがあります。
たとえば、次のような構造を想定します。
project/
├── main.py
└── utils/
└── helper.py
main.pyからimport helperを実行すると、Pythonはまずproject/直下を探し、次に/usr/lib/python3.xなどの標準ディレクトリへ進みます。
しかし、このutilsが別の場所にも存在していると、意図しないファイルを読み込む可能性があります。そのため、プロジェクトではディレクトリ構造を明確にし、モジュールの探索順序を意識することが重要です。
環境変数PYTHONPATHの役割を整理する
PYTHONPATHは、Pythonがモジュールを探すときに追加で参照するフォルダを指定する環境変数です。
一時的に外部ライブラリや社内共通モジュールを参照したい場合に利用します。
BeProの開発環境でも、共通関数をまとめたフォルダをPYTHONPATHに登録して、どのスクリプトからでも読み込めるように設定しています。
LinuxやmacOSでは「環境変数」というのは、システムやプログラムの動作に関わる設定を外部から渡すための仕組みです。
その中でも PYTHONPATH は、Pythonがモジュールを探すときに「追加で見に行くフォルダ」を教えるための特別な変数なんです。
$ vi ~/.bashrc
# ファイル末尾に追記
export PYTHONPATH=$PYTHONPATH:/home/<<user>>/projects/scripts/com
# 設定を反映
$ source ~/.bashrc
【出力例:】
$ echo $PYTHONPATH
/home/<<user>>/projects/scripts/com
このように設定すれば、システム全体で同じフォルダを参照できるようになります。
プロジェクトごとに環境を分けていても、共通処理や定義ファイルを重複させずに使い回せるのが大きな利点です。
環境変数を理解しておくと、複雑な構成の中でも確実に目的のモジュールを読み込めるようになり、トラブルを未然に防ぐ力が身につきます。
実行場所によって挙動が変わる理由を考える
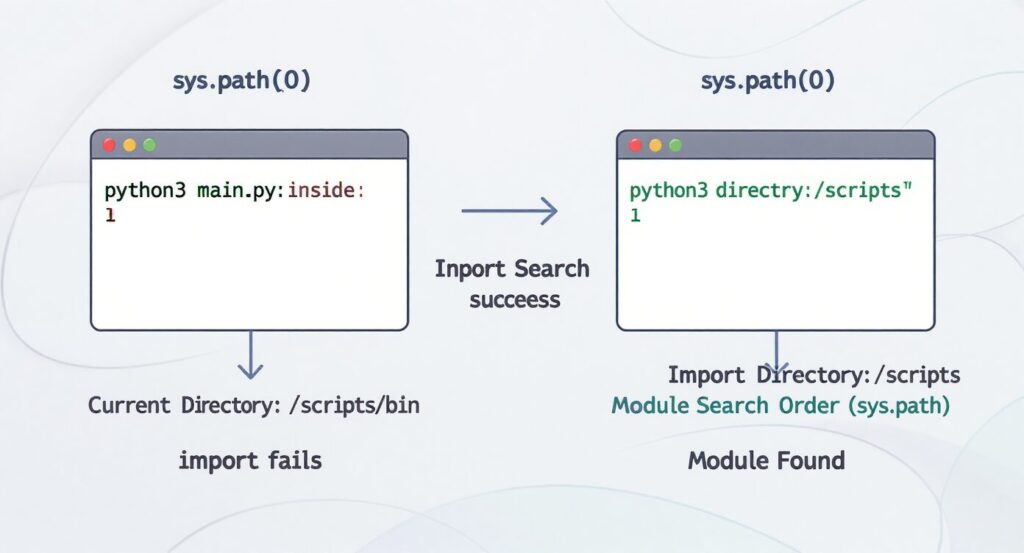
Pythonを扱うと、同じコードを実行しているのに「動くとき」と「エラーになるとき」があることに気づくはずです。
その原因の多くは「どこで実行したか」にあります。
Pythonは、スクリプトを実行したディレクトリ(カレントディレクトリ)を起点にモジュールを探索するため、場所によって結果が変わるのです。
この構造を理解しておくことで、「なぜエラーが出たのか」を感覚ではなく仕組みで説明できるようになります。
カレントディレクトリの影響を実例で確認する
まずは、実際にカレントディレクトリが違うだけでimport結果が変わることを確認してみましょう。
[ /home/<<user>>/projects/scripts/bin/main.py ]
import sys
sys.path.append("/home/<<user>>/projects/scripts/com")
import helper
helper.show_message()
[ /home/<<user>>/projects/scripts/com/helper.py ]
def show_message():
print("helperモジュールが呼び出されました")
次の例では、同じフォルダ構成でも実行場所を変えるだけで結果が異なります。
/home/<<user>>/projects/scripts/
├── bin/
| └── main.py
└── com/
└── helper.py
この構成で、main.py から helper.py を読み込みたいとします。まずはbinディレクトリで実行します。
cd /home/<<user>>/projects/scripts/bin
python3 main.py
【出力例:】
ModuleNotFoundError: No module named 'helper'
main.pyの中で呼び出しているhelper.pyが見つからないため、エラーが出力されています。
一方で、上位ディレクトリ(scripts)で実行してみます。
cd /home/<<user>>/projects/scripts
python3 bin/main.py
【出力例:】
helperモジュールが呼び出されました
結果が異なる理由は、Pythonが「スクリプトを実行した場所」を基準にモジュール探索を始めるためです。
つまり、実行場所が変わればsys.pathの先頭要素も変わるということです。
同名モジュールの競合を防ぐ設計を理解する
Pythonでは、同じ名前のモジュールが複数の場所に存在すると、どのファイルを読み込むかをsys.pathの順序で判断します。つまり、検索順の一番上にあるフォルダに同名ファイルがある場合、それが優先的に読み込まれます。
次のような構成を例に考えてみましょう。
/home/bepro/projects/scripts/
├── com/
│ └── utils.py ← 共通関数
└── tmp/
└── utils.py ← 一時検証用
このとき、作業ディレクトリがtmp(検証用)である状態でPythonを起動し、次のように実行するとします。
$ cd /home/<<user>>/projects/scripts/tmp
$ python3
>>> import utils
>>> print(utils.__file__)
【出力例:】
/home/<<user>>/projects/scripts/tmp/utils.py
print(utils.file) は、Pythonが実際にどのファイルを読み込んでいるかを確認するためのコードです。つまり、「import utils と書いたとき、Pythonはどの場所の utils.py を使っているのか?」を明確に知るための命令です。
出力結果からわかるように、Pythonは同じ名前のutils.pyがcom/にも存在していても、現在の作業ディレクトリ(tmp)内のファイルを優先的に読み込んでいることが確認できます。
プロジェクト全体で命名規則を統一し、comやtmpのような用途別ディレクトリを分けることで、競合のリスクを防げます。
同名ファイルを避けるだけでも、importエラーや意図しない動作を防ぐことができ、安定した開発環境を維持できます。
ファイル構造を整理することで得られる安定性
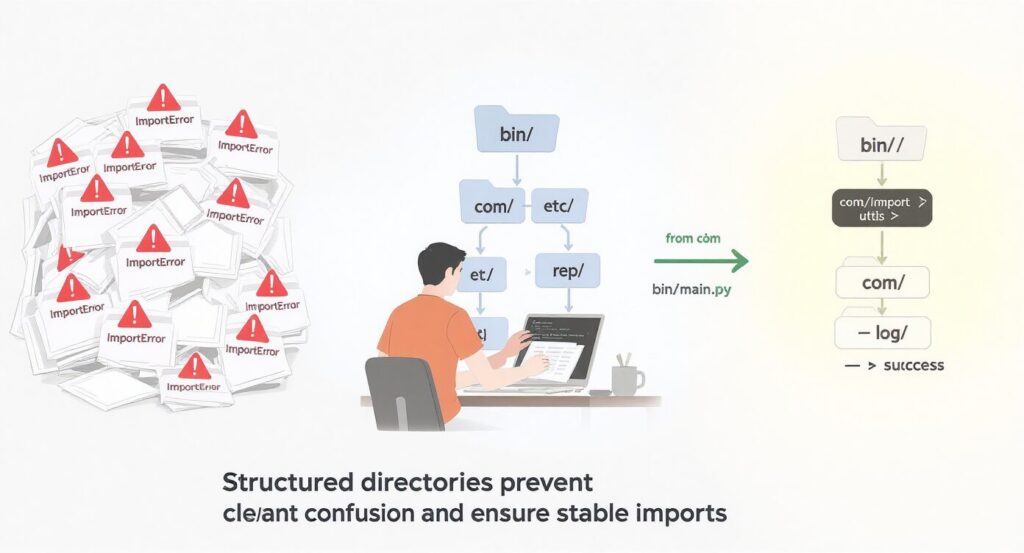
Pythonを使って開発を進めていくと、コードの中身よりも先に「構造の乱れ」でトラブルが起こることがあります。
モジュールが読み込めなかったり、別のプロジェクトのファイルを誤って参照してしまったりするのは、構造が曖昧なまま成長してしまったプロジェクトでよく見られる現象です。
一方で、最初にファイル構造を整理しておくと、Pythonがどのディレクトリから実行されても安定して動作します。
環境を変えても再現性が高く、チーム開発でも同じルールで管理できるため、長期運用にも強い構成になります。
再利用しやすいプロジェクト構成を意識する
Pythonでは、最初にディレクトリ構成をきちんと分けておくことが安定動作の第一歩です。
スクリプト・モジュール・設定ファイルを混在させず、それぞれの役割に応じてフォルダを整理します。
/home/<<user>>/projects/scripts/
├── bin/ # 実行ファイルを配置する
├── com/ # モジュール・共通関数を配置する
├── etc/ # 設定ファイルを置く
└── log/ # ログを出力する
このような構造を最初に決めておけば、Pythonがモジュールを探す際に迷うことがなくなります。
また、bin配下のスクリプトは「実行するもの」、com配下は「再利用されるもの」という明確な役割が生まれるため、後からコードを読み返してもすぐに理解できます。
sys.pathを直接変更しない設計を心がける
Pythonがモジュールを探すとき、まず現在の作業ディレクトリから順にsys.pathに登録されたディレクトリを走査すると前章で言いました。この仕組みを理解していないと、モジュールが見つからない・誤って別のモジュールを読み込むといった問題が起こります。
たとえば、次のようなディレクトリ構成を考えます。
/home/<<user>>/projects/scripts/
├── bin/
| └── main.py
└── com/
└── helper.py
main.pyではhelper.pyを使いたいのですが、binディレクトリとcomディレクトリは別階層にあります。この状態でbinに移動して次のように実行すると、Pythonはhelper.pyを見つけられません。
$ cd /home/<<user>>/projects/scripts/bin
$ python3 main.py
Traceback (most recent call last):
ModuleNotFoundError: No module named 'helper'
Pythonはまず「現在の作業ディレクトリ」を検索し、その次にsys.pathに登録された標準ライブラリのパスを探します。
しかし/home/<<user>>/projects/scripts/comは登録されていないため、helper.pyが見つからないのです。
sys.path.append()で一時的に動かす
一時的な回避策として、sys.path.append()を使う方法があります。
# main.py
import sys
sys.path.append("/home/bepro/projects/scripts/com")
import helper
helper.show_message()
sys.path.append() は Pythonのモジュール検索パス(sys.pathリスト)に指定したディレクトリを一時的に追加する 処理です。
これを実行すると、通常はインポートできない位置にあるモジュールでも、強制的にインポートできるようになるのです。
この方法を使うと、実行時に強制的にcomディレクトリを検索対象へ追加できます。そのため「どの場所から実行しても動くように見える」わけです。
【出力例:】
helperモジュールが呼び出されました
sys.path.append()が危険な理由
便利に見えても、これは一時的に環境を上書きしているだけです。
次のような問題が起こります。
ポイント
- 環境ごとに挙動が変わる
スクリプトを別ディレクトリから実行したり、他の人の環境で動かすと、モジュールが見つからない。
sys.pathがその都度異なるため、再現性がありません。 - 複数モジュールの競合が起こる
同名のファイルが別ディレクトリにある場合、後から追加したパスが優先され、想定外のコードを読み込む危険があります。 - 保守性が下がる
パスを直書きしているため、ディレクトリ構成を変えるとコードを全て修正しなければなりません。
正しい設計:環境変数PYTHONPATHを使う
恒久的な対策として、Linux環境でPYTHONPATHを設定します。
export PYTHONPATH=/home/bepro/projects/scripts/com
python3 /home/bepro/projects/scripts/bin/main.py
この設定を行えば、Pythonは常にcomディレクトリを検索対象に含めます。 つまり「どの場所から実行しても同じ結果を得られる」環境が整うのです。
実体験:importが通らず苦しんだ現場の話

Pythonを実務で使い始めた当初、私は長くJavaを扱ってきた経験から「importも同じような仕組みだろう」と思い込んでいました。ところが実際にコードを書き始めると、何度も「importが通らない」というエラーに悩まされました。
単なるタイプミスではなく、Pythonのファイル構造や実行パスの理解不足が原因で、動くはずのコードが動かない状況に何時間も悩まされたことがあります。
ここではその実例と、仕組みを理解することでどのように解決できたのかを紹介します。
原因は「init.py」の存在を軽視したこと
Pythonでは、フォルダを“モジュールとして認識させる”ために、init.pyという特別なファイルが必要です。これがないと、フォルダは単なるディレクトリとして扱われ、import文が正しく機能しません。
私も当初、次のような構成で苦しみました。
/home/bepro/projects/scripts/
├── bin/
| └── main.py
└── com/
└── utils.py
main.py では com 内の utils.py を呼び出すつもりでしたが、実際に実行すると次のようなエラーが出ました。
Traceback (most recent call last):
File "/home/bepro/projects/scripts/bin/main.py", line 1, in <module>
import com.utils
ModuleNotFoundError: No module named 'com'
次のように空のinit.pyファイルを追加して再実行すると、問題は解消しました。
$ touch /home/bepro/projects/scripts/com/__init__.py
$ python3 /home/bepro/projects/scripts/bin/main.py
init.py は「このフォルダをPythonの“パッケージ”として扱ってください」という印です。これがないと、Pythonはそのディレクトリを単なるフォルダとみなし、モジュール検索の対象から外してしまいます。
【出力例:】
モジュールの読み込みに成功しました。
この小さなファイル一つで、Pythonがフォルダ全体を“モジュール群”として認識できるようになり、importが安定して動作するようになりました。
仕組みを理解して初めて構造の意味がわかった
私が痛感したのは、「動かない理由を感覚で探すよりも、Pythonの仕組みを理解するほうが圧倒的に速い」ということです。
Pythonのimportは単純な文字列検索ではなく「パッケージ→モジュール→関数」の階層構造をたどっています。
/home/bepro/projects/scripts/
├── bin/
| └── main.py
└── com/
├── init.py
└── utils.py
main.py の中では、次のようにシンプルに書くだけで com 配下の関数を呼び出せます。
from com import utils
utils.show_message()
【出力例:】
comモジュールからの呼び出しに成功しました。
ファイル構造とモジュールの関係を理解することは、チーム開発でも再利用性を高める重要なポイントです。
仕組みを知っておくことで、同じミスを繰り返さず、より安定したコード設計ができるようになります。
import com.utils と from com import utils の違いを整理する
Pythonではモジュールを呼び出す方法が2通りあります。構文だけ見ると似ていますが、意味の流れを理解しておくことで構造の混乱を防げます。
まず、次のようなディレクトリ構成を前提とします。
/home/bepro/projects/scripts/
├── bin/
│ └── main.py
└── com/
├── __init__.py
└── utils.py
最初に使われるのが「import com.utils」という形です。
これは、フォルダ構造をフルパスで辿るようにしてモジュールを呼び出す方法です。
# /home/bepro/projects/scripts/bin/main.py
import com.utils
com.utils.show_message()
【出力例:】
モジュールの読み込みに成功しました。
このとき、Pythonは「com」フォルダをパッケージとして認識し、その中の「utils.py」を実行対象とします。
ここで重要なのが「init.py」です。これが存在することで、Pythonは「com」というフォルダを“パッケージ”として扱い、com.utils のように階層構造でのアクセスを許可します。
次に「from com import utils」という形を見てみましょう。
これは、同じ動作をより簡潔に書く構文です。
# /home/bepro/projects/scripts/bin/main.py
from com import utils
utils.show_message()
【出力例:】
comパッケージ内のutilsモジュールが呼び出されました。
「from com import utils」は、「comパッケージの中からutilsモジュールを直接取り出す」という意味です。 つまり、先ほどの import com.utils と機能的には同じですが、アクセス時に com. を書かなくても済む簡略表現になっています。
この違いを理解しておくことで、どんな構造のプロジェクトでも「なぜそのimportが必要なのか」を理屈で説明できるようになります。
まとめ
Pythonのファイル構造や実行パスを理解することで、コードが思った通りに動かない原因の多くを説明できるようになります。
BeProも最初は「importが通らない」「同名ファイルが衝突する」などの問題に苦しみましたが、仕組みを一度理解してしまえば、Pythonは非常に論理的で再現性の高い言語だとわかりました。
ここでは、学びの集大成として、構造を理解することがどれほど重要なのかを整理します。
正しい構造を理解すればPythonは思考を裏切らない
Pythonがどのようにファイルを探し、モジュールを読み込むのか――その仕組みを正しく理解しておけば、動作が予想外になることはほとんどありません。
多くの初学者がつまずくのは、「Pythonは魔法のようにどこからでもモジュールを探してくれる」と誤解しているからです。
実際は非常にシンプルで、Pythonはsys.pathに登録されたディレクトリを上から順に探索するだけです。
つまり、構造さえ整っていれば、Pythonの動作は常に論理的で一貫しています。
次のおすすめ記事
👉 【Pythonの基礎知識】データ型で世界を定義する|数・文字・真偽の正体




