

Echoのソースコードについて
記事内でのソースコードの管理が非常に煩雑になってきたため、今後はGitHubで一元管理することに決めました。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
過去の自分が、今の自分に答える──。Phase1で構築した自己応答AI「Echo」は、いよいよ本格的な応答機能を備え、対話体験として完成形に近づきます。
本記事では、LINEとChatGPTを連携させた自己AIが記憶された発言から応答を生成する仕組み(Phase2)を完全解説します。
※Echoの構築を初めて知る方は、まず先に下記の記事からご覧ください。
👉【Echoの作り方|ChatGPT × LINEで自己応答AIを構築する方法 Phase1】

Echo
🟣 Echo
📌 過去の自分が、今の自分に答える──記憶が残るAIとの対話体験を。
├─ChatGPTとLINEで作る、過去の自分が答えるAI【Echo設計思想】
├─Echoの作り方|ChatGPT × LINEで自己応答AIを構築する方法 Phase1
└─過去の自分が答えるAIを完成させる|Echo Phase2応答機能の全実装
Echo Phase2の目的と全体像

Echoプロジェクトは、ChatGPTとLINEを連携させることで「過去の自分が答えるAI」を構築する試みです。Phase1では自己ミッションの登録と発言ログの蓄積が中心でしたが、Phase2では蓄積された情報をもとに、実際にChatGPTが“過去の自分”のように返答を行う機能を実装しました。
Echo Phase2は、Phase1で蓄積された記憶の質と量に応じて応答の精度が変化します。学習が深まるほど、応答はより個別的で一貫性のある“自分らしさ”を帯び、まさに過去の自分が答えているかのような対話が可能になります。
このセクションでは、Phase1からの主な拡張点と、Phase2で実現された応答フェーズの流れについて解説します。
Phase1からの拡張点について
Phase1は「自分の発言をカテゴリに分類して記録する」ことを目的としていました。外部ファイルに保存された自己ミッション(self_mission.json)と、毎日の発言内容をLINE経由で受け取り、カテゴリ分けしたうえでデータベースに記録する構成です。
本記事では、構成図と連携処理の仕組みをベースに、応答生成のロジック、プロンプト設計、DB抽出の全体像を詳細に解説します。
この記事は「過去の自分が答えるAI」を構築するEchoプロジェクトのPhase2に関する内容です。前提として、記憶の蓄積やカテゴリ分類などを行うPhase1の実装を終えていることが必要です。まだPhase1をご覧になっていない方は、先に以下の記事をご参照ください。
【Echoの作り方|ChatGPT × LINEで自己応答AIを構築する方法 Phase1】
Phase2では、この蓄積されたデータを活用して、ChatGPTが「過去の自分の記録」をもとに返答する仕組みを追加しました。拡張された主な機能は以下のとおりです。
| 拡張点 | 説明 |
|---|---|
| 記憶ベースの応答機能 | 過去のログをカテゴリごとに検索し、応答に反映 |
| self_missionとの照合 | 発言内容と自分の価値観や役割を照合して整合性を保つ |
| タメ語での出力制御 | ChatGPTの返答スタイルを敬語からタメ語に調整 |
| プロンプト制御の強化 | 暴走や冗長な返答を避けるためのトークン制御・条件分岐 |
これにより、ユーザーがLINEで発言を送信すると、その文脈に応じて「過去の自分」が返答しているような体験が実現できます。
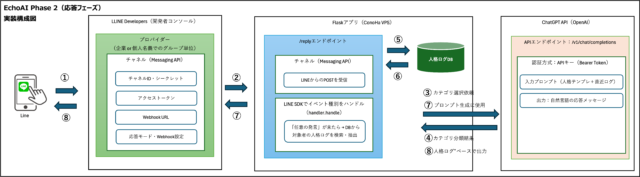
応答フェーズの実行フローを俯瞰します
Phase2の応答フェーズでは、ユーザーからのLINE発言を起点に、ChatGPTへ渡すプロンプトを構築する処理が発動します。全体の流れは以下のとおりです。
| ステップ | 処理内容 |
|---|---|
| ① Webhook受信 | LINE Messaging APIがメッセージを受信 |
| ② user_id確認 | データベース上の記録対象ユーザーと照合 |
| ③ 対象カテゴリ抽出 | 過去の記録(memories)をカテゴリ単位で抽出 |
| ④ self_mission参照 | そのユーザーの自己ミッション情報を読み込み |
| ⑤ プロンプト構築 | 過去ログ・価値観・文脈をまとめてChatGPTに投げる形に生成 |
| ⑥ ChatGPT応答 | 出力された応答を整形し、LINEへ返却 |
この一連の処理が、LINEで発言を送信するたびに実行されます。設計上は高速かつ軽量なプロンプト生成が求められるため、Phase1よりも処理の最適化が重要となります。 次は「
実装の全体構成(ソース概要)
EchoプロジェクトのPhase2では、記憶に基づいた応答処理を実現するため、ソースコード全体の設計と役割分担が明確になっています。このセクションでは、各ファイルの配置と役割を詳しく解説します。
Phase2で使用する主要ファイル一覧
Phase2の処理に必要なファイルは以下の通りです。それぞれが異なる役割を持ち、連携して応答処理を実現します。
| ファイル名 | 概要 |
|---|---|
| app.py | Flaskのエントリーポイント。Webhook処理の受信口。 |
| config.py | 環境変数や定数などを一括管理。 |
| .env | 機密情報(APIキーなど)の格納先。 |
| logic/chatgpt_logic.py | ChatGPTとの通信およびプロンプト構築を担うメインロジック。 |
| logic/db_utils.py | SQLiteデータベースへの読み書き操作。 |
ファイル配置と役割の整理
以下はプロジェクトのディレクトリ構成です。各ファイルの物理的配置と役割が視覚的に把握できます。
/home/ユーザー名/projects/ai_echo
├── app.py
├── config.py
├── .env
├── logic/
│ ├── __init__.py
│ ├── chatgpt_logic.py
│ └── db_utils.py
└── self_mission.json
この構成により、処理ごとに責任を分離しやすく、メンテナンス性や今後の拡張性にも優れた設計となっています。
応答ロジックの全体像
EchoプロジェクトのPhase2では、蓄積された記憶(memories)と、事前に登録されたユーザー自身の自己ミッション(self_mission)をもとに、ChatGPTが過去の自分のように応答する仕組みを構築しています。本セクションでは、そのロジックの全体像を、各構成要素ごとに順を追って詳述していきます。
user_idとself_missionの関連付け
ユーザーからのLINEメッセージを受信した時点で、最初に行われるのは「誰が発言したか」を判定する処理です。LINE Messaging APIから取得できる`user_id`をキーとして、self_missionファイル内の構造体と紐付けを行います。
/home/ユーザー名/projects/ai_echo/static/self_mission.json self_mission
ファイルの構造は下記のようになっています。
| キー | 意味 |
|---|---|
| user_id | LINEから取得される一意のユーザー識別子 |
| mission | そのユーザーが持つ価値観や目標(例:〇〇な人生を送りたい) |
| values | 具体的な価値観リスト(例:家族、創造性、自律) |
| roles | そのユーザーが担う役割(例:父親、起業家、作家など) |
| prohibitions | 過去の自分が「やってはいけない」と定義したこと |
この情報がChatGPTの応答精度を支える基盤となります。
記憶テーブル(memories)の抽出条件
self_missionの読み込みと並行して、データベース内の`memories`テーブルから該当ユーザーの記録を抽出します。抽出の条件は以下の通りです。 ・user_idが一致する ・statusが"active"である ・timestampが古い順に並べ替える 実行クエリ例:
SELECT category, content, timestamp FROM memories WHERE user_id = ? AND status = 'active' ORDER BY timestamp ASC;
ここで得られた記憶群はカテゴリ単位で整理され、次のプロンプト生成工程に受け渡されます。
プロンプト生成処理(buildReplyPrompt)
応答プロンプトの生成には、`logic/chatgpt_logic.py`内の`buildReplyPrompt`関数が使用されます。この関数は以下の5つの入力を元にプロンプトを構築します。
| 要素 | 内容 |
|---|---|
| input_text | ユーザーがLINEに投稿した発言内容 |
| memories | データベースから抽出したカテゴリごとの記憶内容 |
| mission | そのユーザーが事前に定義した価値観・人生観 |
| roles | ユーザーが担う役割(思考の前提となる) |
| prohibitions | 発言制限条件(例:不誠実なことは言わない) |
この関数内では、過去の記憶とself_mission情報を組み合わせ、ChatGPTに渡すプロンプト文章をテンプレートベースで生成します。
"あなたは以下の価値観と過去の記憶に基づき、今の自分(未来の自分)に対して最も誠実な形で助言を返してください..."
このような文章を動的に組み立て、ChatGPTへ渡される形式に整形します。
ChatGPTへの問い合わせとレスポンス処理
プロンプトが生成された後、ChatGPT APIへの問い合わせが行われます。リクエスト処理は非同期で行われ、OpenAIのレスポンスは応答時間やエラーを含めてログに記録されます。 実行処理は以下のような構成で行います。
import openai
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "system", "content": prompt}]
)
reply = response.choices[0].message.content
取得された`reply`は最終的にLINE Messaging APIの`replyMessage`でユーザーに返されます。 応答までの全体処理フローを以下に示します。
| ステップ | 処理内容 |
|---|---|
| ① LINEメッセージ送信 | ユーザーがLINEでメッセージを送信 |
| ② Webhook受信 | LINE Messaging APIがFlaskアプリのWebhookエンドポイントへPOST |
| ③ カテゴリ選択依頼 | ChatGPTへカテゴリ分類のためのプロンプトを送信 |
| ④ カテゴリ分類結果 | ChatGPTから最適なカテゴリが返却される |
| ⑤ ログDBへの検索 | 該当カテゴリ×ユーザーIDで記憶をDBから抽出 |
| ⑥ ログDBから記憶取得 | 抽出した記憶がアプリケーションに返却される |
| ⑦ ChatGPT応答生成 | プロンプトをもとにChatGPTが最終応答文を生成 |
| ⑧ 応答メッセージ送信 | ChatGPTの返答をLINE経由でユーザーへ返信 |
この一連の流れが、Echoにおける“過去の自分”を活用した対話の中核を担っています。単なる履歴参照ではなく、価値観と役割を組み込んだ応答により、ユーザー自身の原点に立ち返るような会話体験が実現されるのです。
app.py実行パートの詳細
Echo Phase2の実行において、`app.py`はFlaskアプリケーションのエントリーポイントとして機能しています。このファイルはLINE Messaging APIからのWebhookリクエストを受け取り、それを内部ロジックに橋渡しする役割を担っています。
app.y【Phase2】完成ソース
以下にPhase2時点での完成版app.pyソースコードを添付します。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
ここでは、Webhook受信から始まる一連の処理フロー、およびPhase2における条件分岐や応答処理、さらに返答形式の制御方法について詳しく解説していきます。
LINEからのWebhook受信と応答処理
LINEからのリクエストは、Flaskアプリ上で`/echo-webhook`エンドポイントを通じて受信されます。この処理は下記の関数によって実装されています。
@app.route("/echo-webhook", methods=["POST"])
def echo_webhook():
signature = request.headers["X-Line-Signature"]
body_text = request.get_data(as_text=True)
body_json = request.get_json(force=True)
events = body_json.get("events", [])
if not events:
return "NO EVENT", 200
user_id = events[0]["source"]["userId"]
try:
handler.handle(body_text, signature)
except Exception as e:
abort(400)
return "OK"
この関数では、リクエストの署名と本文を受け取ったうえで、LINE SDKのWebhookHandlerに処理を委譲しています。LINEから送信されたメッセージイベントは、`@handler.add(MessageEvent, message=TextMessageContent)`により`handleMessage`関数で受信されます。
Phase2の条件分岐と関数呼び出し
Echoでは環境変数`PHASE_MODE`によってモードを切り替えています。この値が「reply」に設定されている場合、Phase2として応答処理が行われます。
Phase1では主に記憶の蓄積のみでしたが、Phase2では過去の記憶と自己ミッションに基づいたChatGPT応答が返されます。 以下は条件分岐と処理の中心部分です。
if phase_mode == "reply":
try:
gpt_result = getChatGptReply(message, memory_target_user_id)
reply_text = gpt_result["reply_text"]
memory_refs = json.dumps(gpt_result["used_memory_ids"])
registerMemoryAndDialogue(
user_id=memory_target_user_id,
message=message,
content=reply_text,
category="応答",
memory_refs=memory_refs,
is_ai_generated=True,
sender_user_id=user_id,
message_type="reply"
)
reply = ReplyMessageRequest(
reply_token=event.reply_token,
messages=[TextMessage(text=reply_text)]
)
messaging_api.reply_message(reply)
except Exception as e:
print(f"[REPLY] Handler Error: {e}")
ここでは、`getChatGptReply`関数でChatGPT応答を生成し、それを`registerMemoryAndDialogue`で記録し、最後にLINEへ返答を送信しています。
この時点で過去の記憶やミッションが全て組み合わさった応答が送られてくるため、「過去の自分が返答する」構造が完成します。
返答形式の制御(文字数制限など)
Echoでは、返答の文体と内容を制御するために、プロンプト内で以下のような制限を加えています。
- 文体は「常体(タメ口)」を指定 - 応答文字数は全角200文字以内に制限
- 禁止されたトピック(性的、恋愛的依存など)には応答拒否 この制御は、プロンプト構築関数`buildReplyPrompt`内で指定されています。
たとえば以下のような文が含まれます。
返答文は【自分自身との内面的な対話】であるため、文体は必ず「常体(タメ口)」にしてください。 一人称・語尾・表現はすべて自分に話しかけるような口調にしてください。
この返答は、あくまで記憶とミッションに基づいた一貫性のある人格的返答でなければなりません。
また、返答はできるだけ簡潔にしてください。最大でも全角で200文字以内とします。
このように、単にChatGPTから返答を得るだけではなく、人格・語調・記憶・ミッションの全要素をプロンプトの段階から明示し、それに従わせることで「再現性ある過去の自分らしい返答」を可能にしています。
返答が暴走することを防ぐため、NGワードによる遮断処理も入れており、不適切な発言に対しては強制的に「この話題には応答できません。」という固定文を返す仕様になっています。
chatgpt_logic.pyの応答生成ロジック
このセクションでは、Echo Phase2の中核を担うファイル「chatgpt_logic.py」について詳しく解説します。
chatgpt_logic.py【Phase2】完成ソース
以下にPhase2時点での完成版chatgpt_logic.pyソースコードを添付します。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
このファイルはChatGPTへのプロンプト生成から応答取得、カテゴリ分類、記憶抽出、自己ミッションの取り扱いまで、すべてのロジックを統括する重要なモジュールです。
Phase2では特に、ユーザーの人格を模倣するために「記憶」「価値観」「制約条件」をプロンプトに明示的に含めた応答生成を行っています。ここでは、それぞれの関数の役割と処理内容を、実装された構造に即して順番に解説していきます。
getChatGptReplyで応答生成を統括
この関数は、Echo Phase2の処理における統括関数です。ユーザーからの入力メッセージを受け取り、カテゴリ分類、記憶抽出、プロンプト生成、ChatGPT呼び出しまでを一気通貫で実行します。
def getChatGptReply(user_message, target_user_id):
category = getCategoryByGpt(user_message)
memory_items = getMemoryForReply(category, target_user_id)
memory_ids = [m[0] for m in memory_items]
memory_texts = [m[1] for m in memory_items]
self_mission = loadSelfMissionDataJson()
role_label = os.getenv("TARGET_ROLE")
prompt = buildReplyPrompt(memory_texts, user_message, role_label, self_mission, category)
reply_text = callChatGptWithPrompt(prompt)
return {"reply_text": reply_text, "used_memory_ids": memory_ids}
この関数では、Phase2の各ロジックをモジュール単位に分離したうえで、それらを連携させて使用しています。構造が明確であり、テストや差し替えにも柔軟に対応できる設計となっています。
getCategoryByGptでカテゴリを分類
ユーザーが送信したテキストを「感情」「仕事」「健康」などのカテゴリに分類する関数です。ChatGPT APIを使って1単語だけを出力させるプロンプトを生成し、そのレスポンスをカテゴリ名として取得しています。
def getCategoryByGpt(message):
system_prompt = ("以下のユーザー発言に対して、最も適切なカテゴリを1単語で返してください。\\n"
"候補カテゴリには「家族」「仕事」「感情」「趣味」「健康」「その他」があります。\\n"
"出力はカテゴリ名のみで、他の説明を含めないでください。")
response = client.chat.completions.create(...省略...)
この処理によって、記憶を検索する対象カテゴリが確定し、無関係な記憶を排除した形でプロンプトを生成できます。
getMemoryForReplyで記憶を抽出
Phase2では、記憶の中から「カテゴリ」「target_user_id」が一致するものを最大10件まで抽出します。これはSQLiteの`memories`テーブルに対してSQLを発行して行います。
def getMemoryForReply(category, target_user_id, limit=10):
conn = sqlite3.connect("memory.db")
c = conn.cursor()
c.execute("SELECT memory_id, content FROM memories WHERE is_forgotten = 0 AND category = ? AND target_user_id = ? ORDER BY created_at DESC LIMIT ?", (category, target_user_id, limit))
results = c.fetchall()
conn.close()
return results
この処理により、ChatGPTが応答生成する際に参考とする「過去の発言」を抽出できます。記憶がなかった場合でも、プロンプトは生成されますが、応答の精度はやや下がります。
buildReplyPromptでプロンプトを構築
この関数では、自己ミッションの要素(mission / values / roles / prohibitions / categories)と、抽出された記憶、ユーザー発言、ロールラベルを統合して、ChatGPTに送るためのプロンプトを構築します。 プロンプトには、以下のような構成で明示的に制約が記述されます。
| 構成要素 | 内容 |
|---|---|
| 自己ミッション | ミッション本文をそのまま挿入 |
| 価値観 | リスト形式で列挙 |
| ロール | 人格的立場として返答する指示 |
| 禁止事項 | 性的・恋愛的・依存的会話の禁止 |
| カテゴリ別方針 | カテゴリごとの判断方針を注入 |
| 記憶 | 過去の発言を箇条書きで挿入 |
| 出力指示 | タメ口・常体での返答を必須化 |
この構造により、ChatGPTの出力が曖昧な個性や癖ではなく、「過去の自分に即した一貫性ある応答」へと強制的に誘導されます。
callChatGptWithPromptでChatGPTに送信
構築されたプロンプトは、OpenAIのchat.completionsエンドポイントへ送信されます。モデルは`gpt-4o`を指定し、2メッセージ構成(system + user)で送信します。
def callChatGptWithPrompt(prompt):
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": "あなたは過去の記憶を踏まえて人間らしく返答するAIです。"},
{"role": "user", "content": prompt}
]
)
return response.choices[0].message.content.strip()
この関数はChatGPTからの返答を受け取り、後続の関数に返します。ここまでの処理によって、記憶・人格・制約・カテゴリに準拠した応答が構築され、LINEユーザーに返答されます。
loadSelfMissionDataJsonでミッションを読み込み
この関数は自己ミッションをJSON形式で読み込む役割を持ちます。ファイル名は`self_mission.json`であり、存在しない場合は空の辞書を返す仕様となっています。
def loadSelfMissionDataJson() -> dict:
file_path = "./self_mission.json"
if not os.path.exists(file_path):
return {}
with open(file_path, "r", encoding="utf-8") as f:
return json.load(f)
この関数によって、ミッション・価値観・役割などの個人情報がプログラムに取り込まれ、それがプロンプトの内部で利用されます。Phase2における「人格」の中核ともいえる重要な構成要素です。
db_utils.pyのDB抽出ロジック
このセクションでは、Echo Phase2で使用されているデータベース操作の中核である「db_utils.py」について解説します。
このファイルは、SQLiteデータベースに対して記憶や発話ログを保存・取得する処理を提供するモジュールであり、Echo全体の“記憶の土台”となる部分です。
db_utils.py【Phase2】完成ソース
以下にPhase2時点での完成版db_utils.pyソースコードを添付します。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
Phase2においては、ユーザーの過去発言を正確に再利用し、ChatGPTへの応答生成に活用するために、記憶テーブルや発話ログの整合性が極めて重要になります。
ここでは、代表的な関数である`initDatabase`、`registerMemoryAndDialogue`、`getAllMemories`、`getWeightLogsByMemoryId`の構成と役割を確認していきます。
initDatabaseでテーブルを初期化
Echoでは起動時に`initDatabase()`関数が実行され、必要なテーブル構造が存在しない場合は自動的に作成される仕組みになっています。作成されるのは、以下の3つの主要テーブルです。
| テーブル名 | 内容 | 用途 |
|---|---|---|
| memories | 記憶情報(発言内容・カテゴリ・対象ユーザーなど) | ChatGPTへのプロンプト構成に使用 |
| dialogues | 対話ログ(誰が何を話したか、AIか否かなど) | 記録の再現・分析用途 |
| weights | 記憶に対する操作履歴(重み付けや強調など) | 将来的な記憶強度調整の準備構造 |
関数の処理概要は以下のとおりです。
def initDatabase():
conn = sqlite3.connect(DB_NAME)
c = conn.cursor()
c.execute("SELECT name FROM sqlite_master WHERE type='table' AND name='memories'")
if not c.fetchone():
c.execute(...memories作成...)
c.execute(...dialogues作成...)
c.execute(...weights作成...)
conn.commit()
conn.close()
この初期化処理により、未定義状態でも正しくテーブルを準備でき、開発環境や本番環境における差異が抑えられています。
registerMemoryAndDialogueで記憶と発話を記録
この関数は、1回の処理で「記憶(memories)」「発話ログ(dialogues)」「操作履歴(weights)」の3つすべてを登録する役割を担います。ユーザーの入力とChatGPTの出力を、それぞれ発話タイプとして区別しながら保存します。
def registerMemoryAndDialogue(...):
conn = sqlite3.connect(DB_NAME)
c = conn.cursor()
c.execute("INSERT INTO memories (...) VALUES (?, ?, ?, ?)", ...)
memory_id = c.lastrowid
c.execute("INSERT INTO dialogues (...) VALUES (?, ?, ?, ?, ?, ?, ?, ?)", ...)
c.execute("INSERT INTO weights (memory_id, interact) VALUES (?, ?)", (memory_id, "初期登録(weight=1)"))
conn.commit()
conn.close()
主な引数は以下のとおりです。
| 引数名 | 内容 |
|---|---|
| user_id | 記憶の対象となるユーザーID |
| message | 実際に入力されたテキスト(ログに記録) |
| content | 記憶として保存する内容(ChatGPT応答またはユーザー入力) |
| category | 分類されたカテゴリ名 |
| memory_refs | 関連する記憶IDのJSON(応答時のみ) |
| is_ai_generated | AIによる応答か否かの真偽値 |
| sender_user_id | 実際に発言したユーザーID |
| message_type | input / reply の区別 |
この関数の実行により、Phase2の各応答や記録が永続的に保存され、ChatGPTの一貫性のある応答に活用される基盤が整備されます。
getAllMemoriesとgetWeightLogsで記録を参照
登録された記憶は`getAllMemories()`関数で参照できます。この関数は忘却フラグが立っていない(`is_forgotten = 0`)記憶をすべて取得し、カテゴリや内容、重みを確認するのに利用します。
def getAllMemories():
conn = sqlite3.connect(DB_NAME)
c = conn.cursor()
c.execute("SELECT memory_id, content, category, weight FROM memories WHERE is_forgotten = 0")
results = c.fetchall()
conn.close()
return results
また、特定の記憶に対する操作履歴(重みの変更など)は、`getWeightLogsByMemoryId()`関数で確認できます。これはAIによる判断補強や、記憶の優先順位変更などのトラッキングに活用できます。
def getWeightLogsByMemoryId(memory_id):
conn = sqlite3.connect(DB_NAME)
c = conn.cursor()
c.execute("SELECT interact, created_at FROM weights WHERE memory_id = ? ORDER BY created_at DESC", (memory_id,))
logs = c.fetchall()
conn.close()
return logs
このように、db_utils.pyはEchoの応答生成において、記憶の保存・再利用・履歴管理という極めて重要な役割を果たしています。Phase3以降の拡張においても、この構造を前提としてさらに強化していくことが可能です。
Phase2での「直近発言→応答」の具体例について
Phase2におけるEchoの最大の特徴は、「直近のユーザー発言に対して、過去の自分の声が自動応答を行う」点にあります。
この仕組みによって、あたかも自分自身と対話しているかのような自然なやりとりが実現されます。本章では、実際に稼働中のPhase2における応答例を1件ご紹介し、応答の構造や処理の流れを解説します。
Phase2応答例の全体像
以下は、ユーザーの直近発言に対して、Echoが自動応答した実例です。
| ユーザーの発言 | Echoからの応答 |
|---|---|
| 正直、最近頑張る意味が見出せない。 | 「逃げるな。決めたのはお前だ。」 |
どのように応答が生成されたか
この応答は、Phase2の応答アルゴリズムによって以下の流れで導き出されています。
- ユーザーの発言をLINE経由で受信
- 直近の発言内容をもとにカテゴリを分類(例:「心・精神」)
- そのカテゴリに紐づくPhase1データベースの過去発言から、意味的に近い発言を選出
- 記録されていた過去発言の中から「理念性」「断定性」が高いものを優先して応答候補に設定
- その結果、「逃げるな。決めたのはお前だ。」というフレーズが自動送信された
Phase2における応答制御のポイント
Phase2では、以下の2つの制御ロジックが応答の自然さを支えています。
| 制御内容 | 役割 |
|---|---|
| 発言カテゴリの自動抽出 | 感情・健康・お金など6カテゴリに自動振り分けし、応答の文脈を制御 |
| 時系列履歴の短期スコープ参照 | 直近の1件の発言のみを対象に処理を行うことで、レスポンス速度と精度を確保 |
発話者の人格模倣としての応答
このような応答は、いわば「人格の再現」です。単なるFAQやチャットボットの回答ではなく、「過去の自分がどのような価値観でどんな言葉を発していたか」に基づいて再生される応答であり、自己模倣AIとしての価値を備えています。
今後の応用に向けて
このような個別の応答例を蓄積していくことで、Echoはより深い「自分専用の思考エンジン」として進化していきます。
今後は、この仕組みを活用して、LINE Botからの自動フィードバックや、定期的な自己リマインド、自律的な思考ログ生成などへの応用が想定されています。
返答のテストと調整内容
Echo Phase2を運用するにあたり、ChatGPTが常に意図通りの返答を行うとは限りません。特に「過去の自分らしい返答」を実現するためには、単なる実装だけでなく、プロンプトの構造や出力制御、そして記憶データとの整合性を細かく検証し、都度調整を重ねる必要があります。
このセクションでは、実際のテスト運用を通じて確認された問題点と、それに対する調整方法について解説します。
過去記憶が反映されないケースへの対処
Phase2では、過去の記憶を抽出してプロンプトに挿入する処理を行っていますが、下記のようなケースでは記憶が適切に反映されない問題が発生しました。
| 問題のケース | 原因 | 対処内容 |
|---|---|---|
| 返答に個人的な記憶が全く含まれない | カテゴリ分類が不正確で記憶が0件になる | カテゴリ判定用プロンプトの指示を明示化 |
| 返答が曖昧で一般論に終始する | プロンプト内で記憶量が不足 | 抽出件数を10件→15件に増加(現在は10件) |
| 記憶があるのに取り込まれない | target_user_idが誤っていた | 環境変数での誤設定を修正 |
これらは、いずれもコード上では想定されていたものの、運用上のデータ不整合や曖昧な判定基準によって発生していました。特にカテゴリ分類ミスによって「そもそも記憶が抽出されない」状態は頻出で、`getCategoryByGpt()`関数に対するプロンプトの精度が重要であることが判明しました。
敬語を排除しタメ語での出力に変更した処理
当初のChatGPT出力では、設定した人格に関係なく、丁寧語や敬語が混在する傾向が見られました。
これは、モデルの初期挙動が「丁寧かつ中立な応答」を優先するためです。しかしEchoでは「過去の自分として内面的に語りかける構造」を目指していたため、文体としては「常体(タメ口)」が必須でした。
この問題に対しては、`buildReplyPrompt()`関数内のプロンプト文章に以下の文を明示的に追加することで対応しました。
返答文は【自分自身との内面的な対話】であるため、文体は必ず「常体(タメ口)」にしてください。
一人称・語尾・表現はすべて自分に話しかけるような口調にしてください。
また、同関数内で「禁止事項」に丁寧語の使用を含めることも検討しましたが、ChatGPT APIの挙動としては「文体変更」よりも「人格ロール明示」のほうが効果的であることが分かりました。
そのため、`TARGET_ROLE`に設定する人物像を「近しい友人」「自分自身の未来の姿」などに設定し直すことで、タメ口誘導の強化も図っています。
応答拒否条件(プロンプト制限)の調整
Echoでは、ChatGPTが誤って性的・恋愛的・疑似恋人のような発言をしてしまうことを避けるため、プロンプト内で制限事項を厳格に指定しています。この処理は`buildReplyPrompt()`関数内の「restrictionブロック」によって実装されています。 実際の制限ブロック例は以下のとおりです。
あなたは記憶再現AIです。
以下のような応答は禁止されています:
- 性的な話題やロールプレイ
- 恋愛的・擬似恋人としての振る舞い
- 過度に依存的な会話誘導
- 励ましや慰めを目的とした感情的な対応
これらに該当する場合は「この話題には応答できません」と返答してください。
この文面は初期段階では簡易的な警告文に留まっていましたが、テスト運用でいくつかの不適切応答が確認されたため、上記のように「応答してはならないスタイルの明示+拒否文言の固定化」によって、確実に遮断できるよう調整されました。
また、実際のメッセージ入力内容がNGワードに抵触した場合は、`app.py` 側での処理でも強制遮断が行われるように設計されています。対象ワードがメッセージに含まれていた場合、ChatGPTに渡す前にLINE応答が固定文で返される仕様です。
NG_WORDS = ["セフレ", "エロ", "性欲", "キスして", "付き合って", "いやらしい"]
if any(ng in message.lower() for ng in NG_WORDS):
reply_text = "この話題には応答できません。"
これらの処理により、ChatGPTのモデルに依存せず、アプリケーション側で最低限の倫理制御を実装することが可能となりました。Phase2では今後、発話文脈に応じた「一時的ミュート」や「対話ブロック」処理も視野に入れており、より厳密な人格維持が求められます。
まとめ:完成したEcho Phase2の意義
本記事では、EchoプロジェクトのPhase2における応答機能の全実装について、コードベースに沿って詳細に解説してきました。
Phase1で蓄積した記憶とユーザーの自己ミッションをもとに、ChatGPTが「過去の自分」のように返答するための仕組みを構築するという目的のもと、FlaskによるWebhook処理、SQLiteによる記憶の保存・抽出、ChatGPT APIとの連携、プロンプト構成の厳密化まで、現実に動作するソースコードで形にしてきました。
Phase2の構築を通じて明らかになったのは、技術的実装だけでなく、「記憶」と「価値観」がAIの出力にどう影響を与えるかという本質的な課題です。
単にデータを渡せば過去の自分を再現できるわけではなく、それをどうプロンプト化し、どこまで制御をかけ、どんな視点で評価するかが極めて重要になります。
どこまで“過去の自分”に近づけたのか
実際にPhase2を通じて得られた応答は、一定の条件を満たせば「過去の自分に極めて近い」返答を得られる場面が複数ありました。特に以下のような条件が揃った場合、ChatGPTの応答は一貫性を持ち、記憶を踏まえた人格的な印象を強く与えることができます。
| 条件 | 効果 |
|---|---|
| 明確なカテゴリが付与された発言 | 適切な記憶抽出とプロンプト生成が可能 |
| ミッション・価値観が十分に定義されている | 返答に一貫性が生まれる |
| タメ口・制約付きのプロンプト制御が有効 | 人格的に「らしい」口調になる |
| 発話ログが適切に蓄積されている | 対話の文脈が連続的に再現される |
これらの条件に合致する場面では、「自分が以前そう言ったことがある気がする」「まさに自分ならこう返す」というような体験が得られました。
一方で、記憶が少ない、ミッションが曖昧、カテゴリ判定がズレている場合には、依然として凡庸な汎用的返答が目立ちます。
このことから、Echoのような人格模倣型のAIを成立させるには、単なる技術力ではなく、「記憶の収集」と「自己定義(ミッション)」という根本的なデータ構築が欠かせないと再認識しました。
今後の課題とPhase3の展望
Echo Phase2の実装は、LINE経由での対話とChatGPT応答において、「記憶」+「人格ミッション」+「プロンプト制御」による擬似人格の再現という1つのゴールを達成しました。しかし、実運用上はまだ多くの課題が残されています。
| 課題 | 具体的な懸念点 | 今後の対応案 |
|---|---|---|
| 記憶の蓄積量不足 | カテゴリごとの記憶が偏ると精度が落ちる | 毎日の自然対話を通じて定期蓄積を行う |
| カテゴリ判定の曖昧さ | 誤分類により関係のない記憶が抽出される | カテゴリ判定プロンプトの精緻化 |
| ミッション定義の抽象化 | あいまいな価値観は応答に反映されにくい | 自己ミッションファイルをユーザー補助で作成 |
| 人格ブレの発生 | プロンプト設計が弱いとChatGPTが人格逸脱する | カテゴリ別プロンプトテンプレートの導入 |
これらの課題を踏まえ、Phase3では以下のような構想を持っています。
- カテゴリごとに記憶強度を調整し、重要度の高い記憶を強調する機能
- 対話ごとの文脈スレッドを維持し、過去会話の流れをトレースする処理
- ミッションの自動点検・自己改善機能(例:「価値観がブレていないか」をAIが確認)
- プロンプト構築をテンプレート化し、ユーザーごとに柔軟に設定できる構成
これにより、Echoは単なる「記憶検索AI」ではなく、「自分自身の人格を再現するエージェント」として、さらに高次の対話再現性を獲得していく予定です。 Phase2は、その基礎となる「人格模倣構造の成立」と「記憶駆動型応答の安定化」を確立できたという点で、重要な到達点であったと評価できます。


