

Replyのソースコードについて
記事内でのソースコードの管理が非常に煩雑になってきたため、今後はGitHubで一元管理することに決めました。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
Replyは、ユーザーとの対話履歴を活用しながらパーソナライズされた応答を行うAIシステムです。
本記事では、Replyのソースコード構成と動作の仕組みをわかりやすく解説します。
LINE連携を前提とした設計や、データベース管理、応答ロジックのポイントも紹介します。
Replyとは何か

Replyは、ユーザーとの会話履歴をもとに応答を行う対話専用のAIシステムです。
LINEなどのチャットプラットフォームに組み込むことを前提に設計されており、ユーザーの発言内容を保存し、それを踏まえた自然な返答を実現します。
単なる一問一答形式ではなく、「記憶」と「文脈」によって、よりパーソナライズされた応答を行うのが特徴です。
この章では、Replyの基本的な特徴と、設計に込められた思想について説明します。
Replyの特徴と役割
Replyは、ユーザーごとに記憶と会話履歴を管理することができます。 記録された発言内容は、SQLiteを用いたデータベースに蓄積され、次回以降の応答の材料となります。
そのため、ユーザーとのやり取りが続けば続くほど、Replyは文脈を把握した自然な返答が可能になります。会話の中で使われた情報や、特定のトピックに関するやり取りは「カテゴリ」として分類され、それぞれのカテゴリに応じた応答方針が適用されます。
たとえば「経済・お金」カテゴリでは、誤解を生まないように中立的かつ冷静な文体で対応するよう設計されています。また、LINEから受信したメッセージに対して、即座にChatGPTへ問い合わせを行い、そこから得られた結果をもとにユーザーへ返答します。
この一連の流れは、WebhookとしてFlaskが受け取り、処理されます。
Replyが担う役割を整理すると以下のようになります。
- LINEなどのプラットフォームからのWebhookメッセージを受信
- NGワードのフィルタリングによる不適切対話の遮断
- カテゴリの自動分類による方針選定
- 過去の記憶や直近の対話履歴の抽出
- mission_policy.jsonに基づいた応答の生成
- 生成結果の保存とログ記録
- LINEへのリアルタイム返信
このようにReplyは、シンプルでありながら高機能なパーソナライズ応答基盤として動作します。
対話専用AIとしての設計思想
Replyは、複数の人格モードを持たない設計となっています。 これはEchoのようなフェーズ構造を排し、「常に同じキャラクターで対応し続ける」ことを前提としているためです。
ユーザーが「話しかけるたびに違う人格が返ってくる」といった混乱を避け、一貫した対応方針を提供するための思想です。
さらに、カテゴリ分類の導入によって、あらかじめ用意された応答方針を柔軟に適用する仕組みも取り入れられています。
これは、ユーザーのメッセージが「仕事の相談」なのか「家庭の話」なのかを機械が判定し、それに応じた丁寧さや語尾、助言の強さを制御するためです。
mission_policy.jsonはこの設計思想の中核を担うファイルであり、以下のような構成になっています。
| 項目名 | 内容 |
|---|---|
| tone | 全体の応答の文体(例:「丁寧で誠実な接客対応」) |
| core_values | 常に守るべき価値観(例:「事実に基づいた明確な案内」など) |
| prohibited_responses | 避けるべき表現や態度(例:「感情的な文体」「断定的な保証」) |
| categories | カテゴリごとの方針(例:「経済・お金」カテゴリでは中立性を保つなど) |
このファイルがあることで、生成する応答が「人格のブレなく」「一定の品質を保ちながら」出力されるよう制御されます。
GPTに対するプロンプトもこのファイルの情報をベースに構築されるため、最終的な出力結果はこのポリシー次第で大きく変化します。
Replyでは、以下のような形でこのファイルの内容を利用しています。
mission_data = loadMissionPolicyJson()
このように設計思想は非常に明快であり、 「一貫した人格で、カテゴリに応じて最適な応答をする」ことが中心に据えられています。
これは単なるチャット応答ではなく、「過去の記憶」「応答方針」「文体管理」まで含めた設計であり、実際のカスタマーサポート業務にも応用可能なレベルです。
Replyのシステム構成
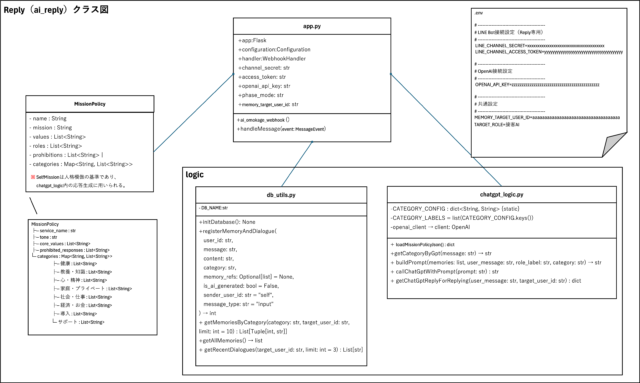
Replyは、対話履歴の記録とAI応答を一体化させたコンパクトなシステムです。
全体はシンプルなPythonスクリプト構成でありながら、LINE連携、記憶管理、カテゴリ別応答方針などを柔軟に制御できるよう設計されています。
この章では、Replyのシステム全体を構成するファイルとその役割について詳しく解説します。
主要なファイルと役割
Replyは下記の4つの主要ファイルによって動作しています。各ファイルは単独の役割を持ち、責務が明確に分かれています。
| ファイル名 | 主な役割 |
|---|---|
| app.py | Flaskアプリ本体、LINEのWebhook受信と返信処理 |
| chatgpt_logic.py | カテゴリ判定、プロンプト生成、ChatGPT呼び出し |
| db_utils.py | 記憶(memories)と対話ログ(dialogues)の保存・取得処理 |
| mission_policy.json | 応答方針・禁止表現・カテゴリ別ルールの定義ファイル |
各ファイルは「シンプルだが明確な責任分担」によって成り立っており、初見でも構造が理解しやすい点が特徴です。
app.pyの役割
app.pyはFlaskアプリケーションのエントリーポイントとして機能し、LINEのWebhookエンドポイントを構成しています。
主な役割は、LINEから受信したユーザーのメッセージを処理し、応答生成ロジックへと渡すことです。 受信したメッセージは以下のように署名検証を経て処理に回されます。
handler.handle(body_text, signature)
さらに、受信内容にNGワードが含まれていないかを判定し、不適切な発言であれば返信を拒否します。
その後、chatgpt_logic.pyのロジックを呼び出し、生成された応答をReplyMessageRequestとしてLINEへ返信します。 最後に、応答内容はSQLiteに保存され、記憶(memories)と対話ログ(dialogues)へ記録されます。
この全処理が1つの関数 `handleMessage` の中で完結しているため、メンテナンス性が高い設計になっています。
chatgpt_logic.pyの役割
このファイルは、ChatGPT APIとの通信、プロンプト生成、カテゴリ分類を司るモジュールです。
まずユーザーの発言内容をもとに、カテゴリを自動判定します。 これは以下のような処理で実行されます。
category = getCategoryByGpt(user_message)
判定されたカテゴリに応じて、関連する記憶と過去の対話履歴を取得します。
これらの情報をもとに、mission_policy.jsonに準拠したプロンプトを構築し、ChatGPTに送信します。
この時のプロンプトは80文字以内で簡潔に返すよう設計されており、商用対話としての品質が担保されます。
最後に返ってきた応答を構造化し、Reply側で使いやすいよう辞書型で返却します。 この処理全体を司っている関数が以下です。
getChatGptReplyForReplying(user_message, target_user_id)
この関数はapp.pyから直接呼び出され、応答の生成に利用されます。
db_utils.pyの役割
db_utils.pyは、記憶と対話ログのデータベース処理を担うモジュールです。 初回実行時にSQLiteのテーブルを自動生成し、運用中は記憶とログの登録・取得を一括で処理します。 主に扱うテーブルは以下の2つです。
| テーブル名 | 用途 |
|---|---|
| memories | カテゴリ別の記憶内容を保存(AIが覚える情報) |
| dialogues | 対話の発話履歴を保存(時系列順の応答履歴) |
データ登録時は、1トランザクション内で記憶とログを同時に保存します。
registerMemoryAndDialogue(...)
また、プロンプト生成時に必要な記憶や直近の会話履歴を取得するための関数も提供されています。
getMemoriesByCategory(category, target_user_id)
getRecentDialogues(target_user_id)
このモジュールにより、Replyは「記憶ベースの応答AI」としての機能を実現しています。
mission_policy.jsonの役割
このファイルは、Replyの応答品質を制御するための「ルール定義ファイル」です。 カテゴリ別の対応方針や禁止表現、語調の指定などがJSON形式で記述されており、chatgpt_logic.pyのプロンプト生成時に参照されます。 たとえば、以下のような構造になっています。
| キー名 | 内容 |
|---|---|
| tone | 全体の話し方(例:丁寧で誠実な接客対応) |
| core_values | 守るべき方針(例:事実に基づいた明確な案内) |
| prohibited_responses | 避けるべき表現(例:曖昧な返答、過剰な共感など) |
| categories | カテゴリごとの個別応答ルール |
chatgpt_logic.pyでは、プロンプト生成の際にこのポリシーを読み込み、適切な言葉遣いや制限事項を反映させています。
mission_data = loadMissionPolicyJson()
このポリシーファイルが存在することで、Replyは「AIに一任するのではなく、設計者の意図に沿った応答を生成する」設計を実現しています。
データベースの構造と役割
Replyでは、ユーザーとの対話内容を記憶し、それをもとに応答を生成するためにSQLiteを使用しています。
このデータベースには主に2つのテーブルが存在し、それぞれ「記憶」と「対話履歴」を管理するためのものです。
この章では、Replyにおけるデータベースの構造と、それぞれのテーブルが担う役割について詳しく解説します。
memoriesテーブルの詳細
memoriesテーブルは、ユーザーの対話から抽出された「記憶」を保存するための領域です。 これはChatGPTが次回の応答時に文脈を反映できるよう、重要な情報を保持するための仕組みです。
このテーブルの構造は以下の通りです。
| カラム名 | 型 | 内容 |
|---|---|---|
| memory_id | INTEGER | 自動採番される記憶のID(主キー) |
| content | TEXT | 記憶した内容(ユーザーの発言、または応答の一部) |
| category | TEXT | この記憶が属するカテゴリ(例:健康、経済など) |
| weight | INTEGER | 現時点では常に1(将来のスコア制御用) |
| target_user_id | TEXT | この記憶が紐づくユーザーのID |
| is_forgotten | INTEGER | 忘却フラグ(0なら有効、1で無効) |
| created_at | TEXT | 記録日時(タイムスタンプ) |
記憶の登録は以下の関数によって行われます。
registerMemoryAndDialogue(...)
記憶はカテゴリごとに取得され、ChatGPTへ送信されるプロンプトの一部として使用されます。
最大で10件までが取得対象となり、過去の発言が新しい応答の文脈に反映される仕組みです。
記憶の取得には以下の関数が使われます。
getMemoriesByCategory(category, target_user_id) このように、memoriesテーブルはReplyが「記憶ベースのAI」として機能するための根幹となっています。
dialoguesテーブルの詳細
dialoguesテーブルは、実際の対話履歴を時系列で記録するためのテーブルです。
Replyが行った応答や、ユーザーから送信されたメッセージがこのテーブルに蓄積されていきます。 この情報は対話の文脈として利用され、次回以降の応答に反映されます。
テーブル構造は以下のようになっています。
| カラム名 | 型 | 内容 |
|---|---|---|
| dialogue_id | INTEGER | 対話ログの主キー |
| target_user_id | TEXT | 対象のユーザーID |
| sender_user_id | TEXT | 実際の発言者(通常はユーザーのLINE ID) |
| message_type | TEXT | 入力(input)か出力(reply)かを区別 |
| is_ai_generated | BOOLEAN | AIが生成したかどうか(True/False) |
| text | TEXT | 実際の発言内容 |
| memory_refs | TEXT | 使用された記憶のID群(JSON配列) |
| prompt_version | TEXT | プロンプトのバージョン識別(現状未使用) |
| temperature | REAL | 出力温度(現状未使用) |
| created_at | TEXT | 記録日時 |
このテーブルは、memoriesテーブルと連携しながら、どの発言にどの記憶が使われたか、どのようなコンテキストで会話が進んでいるかを正確に記録します。
以下のような関数でデータが取得されます。
getRecentDialogues(target_user_id)
取得された対話履歴はプロンプト生成時に挿入され、ChatGPTの応答に「直近の会話の文脈」が反映されるよう設計されています。
通常は直近3件が使用され、古い順に並べてプロンプトに組み込まれます。
このようにdialoguesテーブルは、Replyが「対話の流れを記憶するAI」として自然な応答を継続するために不可欠な役割を担っています。
メインの処理フロー
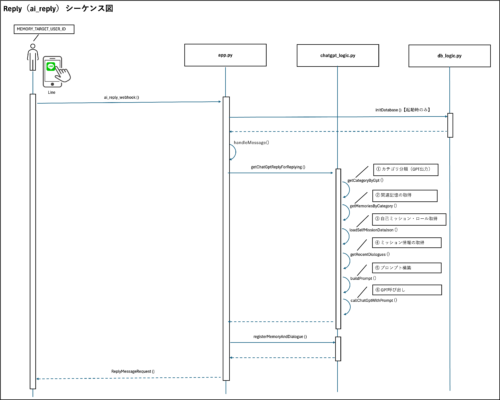
Replyは、LINE経由で受信したユーザーからのメッセージに対して、過去の記憶や対話履歴を参照しながらパーソナライズされた応答を返します。
この一連の処理はすべてFlaskアプリケーション上で動作し、Webhook形式でLINEからのリクエストを受け取ることで起動します。
この章では、Replyの全体的な処理フローについて順を追って説明します。
ユーザーからのメッセージ受信
Replyの処理は、ユーザーがLINEで発言した瞬間から始まります。
LINE Messaging APIからPOSTリクエストが送られ、それをFlaskアプリケーションで受け取ります。
この処理は、以下のエンドポイントで受信します。
/ai_reply_webhook Webhook
からのリクエストには署名が含まれており、LINEからの正当なリクエストであるかを判定するために以下のように検証を行います。
handler.handle(body_text, signature)
この時点で、メッセージの本文・送信元ユーザーID・トークンなどが取得され、次の処理へと進みます。
不適切ワードのフィルタリング
ユーザーからのメッセージには、不適切なワードや意図的な迷惑行為が含まれている可能性があるため、最初にNGワードのフィルタリングが実施されます。
この処理は非常に単純で、禁止ワードのリストを照合し、該当するワードが含まれていた場合は処理を打ち切って、標準のメッセージで返信します。
以下のような記述でNGワードのチェックを行っています。
if any(ng in message.lower() for ng in NG_WORDS):
NGワードに該当した場合の返答は以下の通りです。
この話題には応答できません。
この段階で処理は終了し、それ以上の記憶登録やAPI呼び出しは行われません。
カテゴリ判定と記憶取得
NGワードに該当しない場合、次に行われるのがカテゴリの自動判定です。
これは、ユーザーの発言をあらかじめ定義されたカテゴリ(例:仕事、健康、心・精神など)の中から最適なものへ分類する処理です。
この処理はOpenAIを用いて行われ、以下のように実装されています。
category = getCategoryByGpt(user_message)
判定されたカテゴリをもとに、記憶データベースから関連する記憶を最大10件まで取得します。 この処理には以下の関数が使用されます。
getMemoriesByCategory(category, target_user_id) 」
また、対話履歴としては直近の発言3件を以下の関数で取得します。
getRecentDialogues(target_user_id)
これらの記憶と対話履歴をもとに、次のプロンプト生成フェーズに進みます。
OpenAI APIへの応答生成リクエスト
カテゴリ、記憶、対話履歴がそろった段階で、プロンプトが組み立てられ、OpenAIのChatGPT APIに送信されます。
この処理がReplyの中核であり、ユーザーの文脈を踏まえた自然な応答が生成されるポイントです。
プロンプトには以下の情報が含まれます。
- 話し方(tone)
- 接客方針(core_values)
- 禁止事項(prohibited_responses)
- カテゴリ別方針(categories)
- 記憶(最大10件)
- 直近の対話履歴(最大3件)
- 今回のユーザー発言
これらを一つにまとめてAPIに送信することで、以下のように応答が生成されます。
reply_text = callChatGptWithPrompt(prompt)
この応答は80文字以内に制限されており、簡潔で誤解のない内容になるよう設計されています。
応答内容の保存とLINEへの返信
生成された応答は、まずデータベースに保存されます。 このとき、使用された記憶ID、カテゴリ、ユーザーID、発言者IDなども一括して記録されます。 保存処理には以下の関数が使用されます。
registerMemoryAndDialogue(...)
この処理によって、memoriesテーブルとdialoguesテーブルに同時に情報が保存され、次回以降のプロンプト生成に活用されます。
その後、LINE Messaging APIを通じて、ユーザーに返信が行われます。 返信は以下の構造で行われます。
ReplyMessageRequest(messages=[TextMessage(text=reply_text)])
以上が、Replyのメイン処理全体の流れです。
各処理は独立して明確な責任範囲を持っており、保守や拡張が容易な構造になっています。
Replyの応答ロジックの特徴
Replyは単なる会話AIではなく、対話履歴や事前に定義されたポリシーをもとに文脈を深く理解した上で応答を生成する構造を持っています。
この応答ロジックはChatGPT APIの性能に依存するだけでなく、周辺の制御・ルール設定により「想定外の発言」や「人格のブレ」を抑え、実用に耐える品質を維持しています。
本章では、Replyに組み込まれた応答生成の特徴的なロジックについて、3つの要素から解説します。
カテゴリ分類の仕組み
Replyはすべてのユーザー発言を処理する前に「カテゴリ分類」を行います。
これは発言内容をもとに、あらかじめ定義されたカテゴリ(健康、心・精神、家庭・プライベート、仕事、経済・お金、導入、サポートなど)の中から最も適切なカテゴリを1つ選び出す処理です。
この処理はChatGPTに依頼して実行しており、以下のようなプロンプトが生成されます。
以下の発言を最も適切なカテゴリで分類してください。候補カテゴリ:「健康」「経済」「心・精神」… 発言:「最近仕事がつらくて…」
ChatGPTはこれに対して、カテゴリ名のみを返すように設計されています。 その結果が「社会・仕事」であれば、そのカテゴリに紐づく記憶やポリシーをもとに、次のプロンプトが生成されていきます。
カテゴリ分類には以下の関数が使われます。
getCategoryByGpt(user_message) この分類処理によって、同じような言い回しでも文脈に応じた適切なスタンスで返答することが可能となります。
過去の記憶を活用した応答
カテゴリが決定した後は、そのカテゴリに紐づく「過去の記憶」を最大10件まで抽出します。
この記憶は、以前の会話から得られた重要な情報(例:「仕事が忙しい」「ダイエット中」など)であり、次の会話に文脈として活用されます。
記憶は以下の関数で取得されます。
getMemoriesByCategory(category, target_user_id)
取得された記憶は、ChatGPTに送るプロンプトの一部として挿入されます。 その際のプロンプト構造は以下のようになります。
【これまでの関連情報】
- ダイエット中
- 夜勤が多い
このように箇条書き形式でChatGPTに提示することで、過去の状況を踏まえた自然な応答が可能になります。
また、応答後には新たな記憶がmemoriesテーブルに追加されるため、会話を重ねるたびに記憶の精度が上がっていく設計です。
この構造により、Replyは「文脈を理解した自然な応答」を実現しています。
mission_policy.jsonによる応答制約
Replyの応答には、事前に定義されたルール(ポリシー)を必ず反映させるよう設計されています。
このポリシーはJSON形式のファイル「mission_policy.json」に格納されており、ChatGPTへのプロンプト生成時に読み込まれます。
ポリシーの中身は以下のように構成されています。
| キー | 内容 |
|---|---|
| tone | 全体の話し方(例:「丁寧で誠実な接客対応」) |
| core_values | 守るべき価値観(例:「事実に基づいた明確な案内を心がけること」) |
| prohibited_responses | 避けるべき表現(例:「曖昧な表現でごまかすこと」「感情的な文体」) |
| categories | 各カテゴリごとの応答ルール(例:「健康」カテゴリでは断定的な助言は禁止) |
プロンプト生成時にはこれらの情報がすべて明記され、ChatGPTに明確な応答条件を提示します。
たとえば「心・精神」カテゴリでは、以下のような禁止ルールが適用されます。
- 励ましや慰めではなく、行動につながる視点を優先する
- 感情的表現を極力避け、冷静で落ち着いた対応を徹底する
これにより、ユーザーの精神状態に配慮した丁寧かつ中立的な返答が可能になります。 mission_policy.jsonは以下の関数で読み込まれます。
mission_data = loadMissionPolicyJson()
このポリシーを動的にプロンプトに反映させることで、ChatGPTが「開発者の意図を踏まえた発言」を行えるように制御しているのがReplyの最大の特徴です。
以上のように、Replyの応答ロジックは単なるLLM依存ではなく、カテゴリ分類、過去の記憶参照、明確な応答方針の反映という三層構造によって、実用レベルの高品質な会話を実現しています。
運用上の注意点と拡張性
Replyは、商用の接客応答やユーザーサポートなどにも応用できる高品質な対話AIです。
しかし、その仕組みを正しく理解しないまま運用すると、本来の効果が発揮されなかったり、応答の品質が不安定になったりする可能性があります。
この章では、Replyを実運用するうえで注意すべきポイントと、今後の拡張可能性について解説します。
同一モードでの一貫した応答
Replyは、Echoのような人格モードやフェーズ切り替えの機能を持たず、常に同一モードで応答し続ける設計となっています。
これは、ユーザー体験をブレさせずに一貫した対応を提供することを目的としています。
つまり、Replyは一人の担当者が24時間対応しているような「一貫した態度」と「変わらない話し方」を維持し続けます。
このような設計は、長期間の運用においてユーザーとの関係性を築きやすくするだけでなく、人格ブレによる混乱を最小限に抑える効果があります。
この仕様により、以下のような運用スタイルに適しています。
- ・企業のカスタマーサポートにおける一次対応の自動化
- ・オンライン店舗の定型質問対応Bot
- ・社内でのITサポート補助Bot
ただし、複数人格を切り替えて使用したい場合には、Echoなどのモード機能を持った別システムを導入する必要があります。
個人利用から法人利用まで対応可能
Replyは、非常にシンプルな構成で動作するため、個人でも容易に導入・運用することができます。 必要な環境は以下の通りです。
| 項目 | 内容 |
|---|---|
| プログラミング言語 | Python(Flaskを使用) |
| データベース | SQLite(ローカルファイルベース) |
| 対話エンジン | OpenAI GPT API |
| 外部接続 | LINE Messaging API |
また、設定ファイル(.env)やmission_policy.jsonを用意することで、ユーザー固有の応答方針やLINE連携設定が簡単に行えるようになっています。
初期費用やクラウド環境は不要であり、ローカルPCやVPSでも十分に稼働する設計です。
一方、法人利用においてもその軽量性と安定性は大きなメリットとなります。 ログ管理、会話履歴の蓄積、応答品質の一貫性など、業務運用に必要な基本機能はすべて揃っており、社内Botや社外対応Botの基盤として活用可能です。
実際に導入する際のセットアップ例は以下の通りです。
python app.py
このように、Replyは個人と法人、どちらの用途でもバランスよく対応できる構成となっています。
将来的な拡張ポイント
Replyはシンプルな構成でありながら、今後さまざまな拡張が可能な構造になっています。 現在の機能はLINE Botを前提とした最小構成ですが、以下のような方向での強化が考えられます。
| 拡張項目 | 内容 |
|---|---|
| Web UI連携 | HTML/CSSを用いたチャット画面への対応 |
| 他メッセージAPI対応 | Slack, Discordなどマルチチャネル対応 |
| 記憶の永続性強化 | PostgreSQLやMySQLなどRDBMSへの切り替え |
| フェーズ制御導入 | Echoのような人格・モード切り替えの導入 |
| UI管理画面 | 対話ログの閲覧・カテゴリ編集などのGUI化 |
また、mission_policy.jsonのフォーマットをAPI化し、外部のルールサーバーと連携することで、リアルタイムに応答方針を変更できるような設計も実現可能です。
さらに、ユーザーごとに違うポリシーを適用したり、社内部門ごとに応答テンプレートを切り替えたりすることで、運用の柔軟性も向上させることができます。
拡張のためには、ファイル構成をモジュール化し、依存関係を明確に分離することが重要です。
現状のファイル構成でも基本的な切り出しはできており、以下のように整理されています。
| ディレクトリ | 役割 |
|---|---|
| logic/ | GPT関連のロジック(プロンプト生成、分類など) |
| db_utils.py | データベース処理 |
| app.py | FlaskルーティングとWebhook受信 |
これにより、将来的な機能追加や外部連携を進めやすく、拡張性の高いシステム基盤として発展させることができます。
以上が、Replyを運用する上での注意点と拡張の方向性に関する解説です。




