

面影AIのソースコードについて
記事内でのソースコードの管理が非常に煩雑になってきたため、今後はGitHubで一元管理することに決めました。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
過去に保存した“記憶”をもとに、ChatGPTが自然な返答を返す──それが面影AIのPhase2で取り組む構成です。
本記事は、以下の前提記事をもとに構成されています。まだ読んでいない場合は、先にご覧いただくことを推奨します。

Phase1では、言葉の記録と重みづけに重点を置きましたが、本記事では記録されたデータをどのように抽出し、どのようにプロンプトとして再構成するかを扱います。目的は“人格の再現”ではなく、“関係の継続”です。あくまで記録された事実から返答を生成する仕組みを構築し、LINE上での自然な対話につなげます。
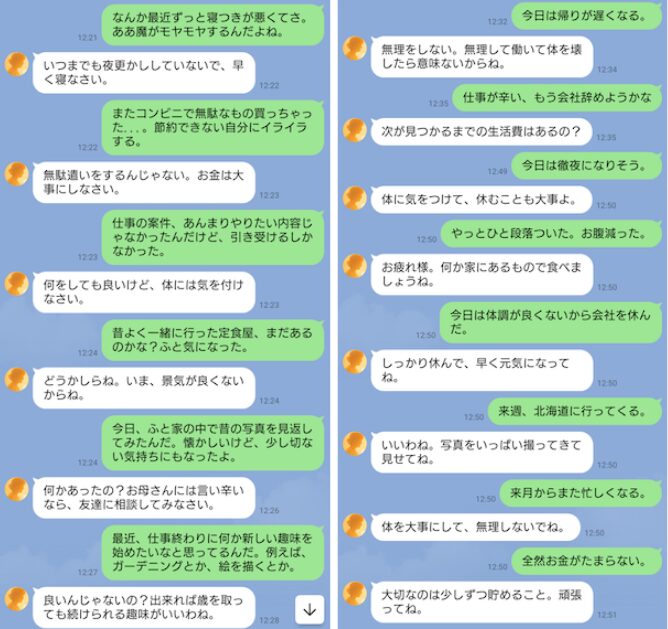
構成はFlaskベースでWebhookを受信し、記憶DBから条件に合致する記憶を抽出、ChatGPTに渡したうえでLINEに返信する流れです。今回はこの「記憶から応答するAI」をPythonで実装するための全体像と、具体的なポイントを解説していきます。
本システムの前提となる記憶保存ロジックや重み付けの構造については、Phase1の記事で詳しく解説しています。
▶︎ 【Pythonの基礎知識】面影AIを記録する|Phase1:記憶と重みの保存構造【ChatGPT】

Phase2と合わせてご覧いただくことで、面影AIの設計思想と処理構造をより深く理解できます。
面影AI
🟡 面影AI
📌 忘れたくない想いを、AIが記憶する──過去の声と、もう一度向き合うために。
├─いつか消える面影を、繋ぐ未来をAIに託す挑戦【ChatGPT】
├─【Pythonの基礎知識】Phase構成で考える、記憶する面影AIの設計思想【ChatGPT】
├─【Pythonの基礎知識】面影AIを記録する|Phase1:記憶と重みの保存構造【ChatGPT】
└─【Pythonの基礎知識】記憶から応答するAIを作る|面影AI Phase2【ChatGPT】
Phase2の目的と全体像

Phase1で構築した記録基盤は、単なる会話ログの保存にとどまらず、AIが「その人らしく応答する」ための重要な土台となります。
Phase2では、ユーザーの発言傾向、話題の嗜好、そして個別の“関係性”を反映した応答生成を目指します。このフェーズでは、単に言葉を返すのではなく、「誰が誰にどう返すか」という文脈全体を考慮する仕組みへと進化させます。
Phase2のゴールとは何か
Phase2の最終的なゴールは、「面影AI」がユーザーと過去の会話を踏まえたうえで、その関係性を維持・深化できるような応答を自然に返せるようにすることです。
つまり、相手の口調・態度・癖・考え方を学び、それをまるで人格のように再現することが目的です。
応答生成のための前提条件
Phase2の開発において、以下の前提条件を確保する必要があります。
- Phase1の記録データが時系列で蓄積されていること
- 発言者・宛先・カテゴリが全て分類済であること
- 人格ごとに分離されたトークン(AI記憶)を再利用可能であること
これらの要素を満たしていなければ、正確な応答の再現は不可能です。逆に言えば、Phase1でこれらを徹底して整備したことが、Phase2の実現に向けた絶対条件だったのです。
Phase2シーケンス図の全体像
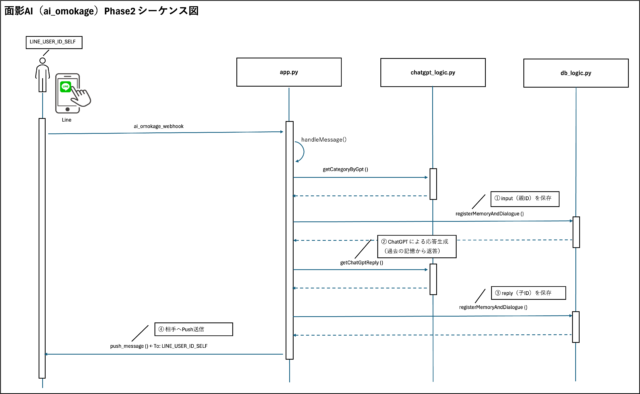
以下に、Phase2の一連の処理シーケンスを簡易に示します。
- ユーザーがLINEなどで発言する
- Webhookサーバーが発言を受信する
- その発言に該当する過去ログ(memories)を検索する
- 文脈とカテゴリ、関係性、応答傾向を評価する
- 再現すべき人格情報(prompt)を構成する
- ChatGPTなどの応答モデルへ送信する
- AIが「人格的に整合した内容」で返信を生成する
この一連の流れにおいて、「誰が」「誰に」「どのカテゴリで」「どういう返し方をしたか」を正しく抽出・模倣する処理が重要になります。
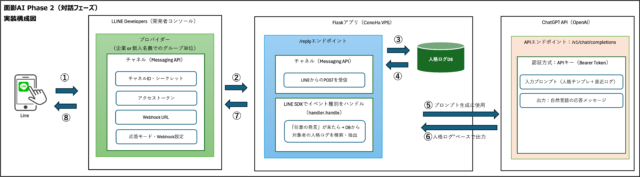
Phase2アーキテクチャの構成
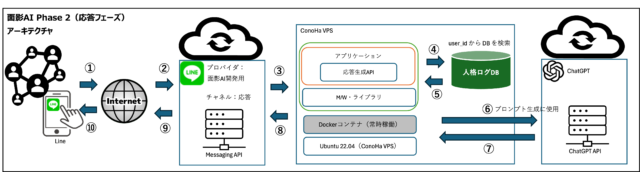
Phase2ではPhase1と異なり、応答生成が主タスクとなります。以下が基本的な構成です。
| 役割 | モジュール | 概要 |
|---|---|---|
| API受信とルーティング | app.py | LINEなどからのWebhookリクエストを受信し、処理を分岐します |
| 応答生成・タスク処理 | chatgpt_logic.py | ユーザーの発言に基づいて応答を構成し、必要に応じてDBと連携します |
| データベース操作 | db_utils.py | タスク・スケジュール・ユーザー履歴などの保存・取得を担います |
重要:再現する人格の生成プロンプト
Phase2では、単純な「質問→答え」の流れでは十分ではありません。たとえば以下のようなprompt構成が必要になります。
あなたは「〇〇」という名前の人格です。
以下は過去の発言記録です:
- 相手:×× あなた:〇〇
- 相手との関係性:親しい友人 - 会話傾向:やや辛口だが本質的
- よく使う語尾:〜だな、〜だろう?
この関係性・言い回しを参考に、次の問いに自然な応答をしてください。 「今日ちょっと落ち込んでてさ、なんか元気でないんだよね」 このように、「誰の人格をどのように再現するか」がこのPhaseで最も重要なポイントになります。
再現性を高めるためのデータ運用
以下のように、ログテーブルの整備状況が応答精度に直結します。
| 記録項目 | 保存対象 | Phase2での使用用途 |
|---|---|---|
| メッセージ内容 | talk_history.message | プロンプトの素材(過去発言の再利用) |
| 発言者ID | talk_history.sender_id | 誰の発言かを識別し、応答に影響 |
| 宛先ID | talk_history.receiver_id | 会話の相手(関係性・文脈の判断に使用) |
| タイムスタンプ | talk_history.timestamp | 時系列順の文脈生成に使用 |
| カテゴリ | talk_history.category | 応答スタイルの切替(※オプションで設定可能) |
このように、記録データを「ただ保存する」のではなく、「再現のために整備する」という視点で扱うことが重要です。
Phase1とPhase2の違い
以下に、フェーズごとの目的と処理の違いをまとめます。
| フェーズ | 主目的 | 中心機能 | ユーザーに見える効果 |
|---|---|---|---|
| Phase1 | 記録・分類 | memoriesテーブル構築と分類 | 会話がログに蓄積される |
| Phase2 | 再現・応答 | 文脈評価とプロンプト生成 | 相手らしい返答が返ってくる |
この差異を認識した上で、Phase2ではいかに「人らしい応答」に近づけるかを追求する必要があります。
今後の課題と発展
Phase2では、以下のような課題が予想されます。
- プロンプトが長文化しすぎることによるAPI制限
- 人格の数が増えることでのメモリ使用量の増加
- 関係性の変化への追従(仲が悪くなったなど)
- 再現した返しが、ユーザーを傷つける可能性
特に最後の点については、単なる再現ではなく「配慮を含んだ応答ロジック」の導入も検討する必要があります。
記憶から応答を生成する仕組み
Phase2では、Phase1で蓄積した会話ログを活用し、より高度な応答生成を実現します。
ただ単に過去の発言を参照するのではなく、「いつ・誰が・どんな意図で話したのか」を文脈として保持し、現在の質問に最適な過去記録を抽出して応答に反映させます。
ログから重要文脈を抽出するプロンプト構造
Phase2の中核となるのが、記憶ログから意味のある文脈を抽出するためのプロンプト設計です。
この設計次第で応答の品質が大きく左右されます。記憶されたログの中から「どのような視点で過去の発言を検索すべきか」を決める必要があります。
検索キーワードは、現在のユーザーの発言から意図や質問の中心語を抽出し、それにマッチするログを検索します。ここでは精度と網羅性のバランスが求められます。
prompt = generatePromptFromUserMessage(user_message)
このプロンプトが、ログ検索の「照準」を決める鍵となります。
getChatGptReplyにおけるPhase2モードの処理
Phase2では、getChatGptReply関数が中心となり、記憶からの文脈検索と応答生成を担います。 処理フローは以下の通りです。
- ユーザー発言から意図とキーワードを抽出
- その意図に基づいてログDB(memoryテーブル)からmemory_idごとに記録を検索
- 検索結果を文脈にまとめてpromptに追加
- ChatGPTへ送信し、応答を生成
この中で特に重要なのが、memory_idごとの記憶ブロック処理です。
memory_id単位の記憶抽出と文脈再構築
memoryテーブルでは、ログを1対話単位ごとにmemory_idでグルーピングしています。この構造により、以下のような特徴が生まれます。
| 項目 | 説明 |
|---|---|
| memory_id | 対話セッション単位のID |
| sender_id | 送信者のユーザーID |
| message | 送信された内容(発言) |
| timestamp | 送信日時 |
この構造を活かし、検索結果を「発言順・関係性ごと」に並べ替えることで、文脈を自然に再構成できます。
memory_records = getRelatedMemoryRecords(user_message)
この関数により、類似発言だけでなく、その前後の関係性も含めて記憶抽出が可能になります。
生成されるプロンプトの全体構成
ChatGPTに渡されるプロンプトは以下のように構成されています。
【前提説明】
あなたは◯◯という性格のAIです。
【過去ログ(記憶)】
・2025/06/10 Beエンジニア「最近疲れてない?」
・2025/06/10 ユーザー「うん、ちょっと寝不足かも」
・2025/06/11 Beエンジニア「じゃあ今日は無理しすぎるなよ」
【現在の質問】
「今日の目標どうする?」
このように、記憶の中にある“会話の連なり”があることで、単発の情報提供ではなく「人間らしい応答」が可能になります。
ログの前処理と整形の必要性
ただし、memoryテーブルに記録されるログはノイズも多く、そのまま使用すると冗長になりがちです。以下のような前処理が必要になります。
| 前処理項目 | 処理内容 |
|---|---|
| 敬語・語尾調整 | AIとして不自然な言い回しを除去 |
| 絵文字・記号削除 | ChatGPTへのプロンプトに不要な装飾の除去 |
| タイムスタンプ補完 | 日時が欠落している記録への補填 |
こうした整形を通して、プロンプト全体の品位と一貫性が維持されます。
今後の改善ポイント
現段階では、キーワードベースの検索とブロック単位の文脈抽出に頼っていますが、将来的には以下の改善が見込まれます。
- 発話者の感情タグ付けによる応答調整
- 記憶への優先度スコア付与と絞り込み
- 複数セッションをまたいだ話題の追跡
こうした進化によって、Phase2は「会話の文脈を保持するAI」から「人間のように話題を記憶し続けるAI」へと変貌していきます。
人格・関係性の再現
Phase2では、ユーザーとの対話履歴をもとに「人格」「関係性」「言葉の使い方」の一貫性を維持することを重視しています。
そのために、過去のやりとりを記憶として蓄積し、現在の発言に文脈的な繋がりを持たせる仕組みが導入されています。
Phase1との最大の違いは、ユーザーの性格や会話の流れを「静的な定義」ではなく、「過去ログから動的に再構築する」点にあります。
トーク履歴DBと文脈記憶の連携
Phase2では、以下の3つの要素が応答生成の基盤となります。
| 構成要素 | 役割 |
|---|---|
| talk_history テーブル | 過去の発言・受信内容をDBに蓄積(user_idごと) |
| chatgpt_logic.py | 履歴から文脈を参照し、プロンプトを生成・ChatGPT APIで応答取得 |
| db_utils.py | DBとの接続、初期化、テーブル操作(`initDatabase`など) |
| memory_id(記憶ID) | 記憶の識別子。記録された発言の一意なIDとして使用 |
| app.py | Flaskアプリのエントリーポイント。Webhook受信、発話処理、ロジック呼び出し |
人格再現の鍵は「一貫性」と「関係性」
単に「過去の言葉を使う」のではなく、「同じ話し方」「同じ反応傾向」「同じ興味関心」で応答できるようにすることが、Phase2の目的です。
そのため、ユーザーが「前にも言ったよね」と感じるような再現性の高い応答を目指しています。
Phase1との違いの明確化
Phase1では単発の応答を高速で返すことに主眼を置いていたため、過去ログの蓄積や活用は行われていませんでした。
これに対し、Phase2では対話の流れ全体を理解するための履歴蓄積と記憶抽出のロジックが実装されており、まるで「人格を持つようなAI応答」が可能となります。
例:語尾や反応の再現
chatgpt_logic.pyでは以下のような処理を実施し、自然な模倣を行います。
- 語尾のパターン抽出(例:「〜だな」「〜かもね」など)
- ネガティブワードや好み表現の頻度分析
- 発話の口調分類(丁寧・砕けた・怒りなど)
今後の拡張予定
将来的には、ユーザーごとの感情傾向や思考のクセをクラスタリングすることで、「もっともらしいが人間らしい」返答の生成も視野に入れています。
そのためのベースが、Phase2で蓄積される会話ログと記憶ID群となります。
今後の展望と実用化への課題
Phase2の実装が現実味を帯びてきた今、その具体的な活用シーンや乗り越えるべき課題について整理する必要があります。
ここでは、LINE運用やSNS連携といった応用先から、精度を高める技術的アプローチ、さらに商用展開における障壁とその克服に向けた展望までを詳しく解説します。
Phase2が持つ実用価値と応用領域
Phase2では、過去ログを元に「人格・関係性・記憶」を再現するAI応答が可能になります。これにより、以下のような応用が考えられます。
- LINE公式アカウントに導入し、個別対応のような自然な返答を自動で実現
- SNS投稿に対するコメント応答の自動化(人格反映付き)
- コミュニティ内における一貫した対応・ファンエンゲージメントの向上
たとえば、YouTubeのチャンネル運営者がPhase2を導入すれば、配信者本人の語り口で視聴者からの質問や応援コメントに自動対応することが可能になります。これは「関係性を保ちながら規模を拡大する」というこれまで矛盾していた課題を突破する手段として注目されます。
精度を高めるための手法:タグ学習と評価ログ
現行のPhase2では、カテゴリ分類・スコア重み・応答履歴をベースに出力を構成していますが、さらなる精度向上のためには「タグ学習」と「評価ログ」が不可欠です。
- タグ学習:発言ログに「応答成功タグ」や「意味誤認タグ」を人力・自動で付与し、AIの学習補助とする
- 評価ログ:実際の応答に対してユーザーが満足したか否かを記録し、応答生成の重み調整に利用する
この仕組みにより、特定の人格を持ったAIが「この人ならこう返すだろう」という返答スタイルを磨き上げることができます。特に、否定・皮肉・感情的反応などの高度な対話はこのタグ学習に大きく依存します。
Phase2を活用した対話生成ロジックの構造
現在採用されている構成は以下の通りです。
| 役割 | モジュール | 概要 |
|---|---|---|
| API受信とルーティング | app.py | LINEなどからのWebhookリクエストを受信し、処理を分岐します |
| 応答生成・タスク処理 | chatgpt_logic.py | ユーザーの発言に基づいて応答を構成し、必要に応じてDBと連携します |
| データベース操作 | db_utils.py | タスク・スケジュール・ユーザー履歴などの保存・取得を担います |
このシンプルな構造によって、応答生成が高速に行われ、障害時の切り分けも容易になります。今後はこれを基盤に、Phase2専用モジュールの追加開発が予定されています。
商用化に向けた課題とその展望
Phase2を実運用・商用展開する際には、以下のような現実的な課題が存在します。
| 課題領域 | 想定される障壁 | 解決の方向性 |
|---|---|---|
| プライバシー | ログ記録内容が個人情報を含む可能性 | 匿名化処理、保存期間の明記とユーザー同意の取得 |
| 法的制約 | 人格模倣が誤認を招く可能性 | 説明責任の明記と「AI応答」であることの明示 |
| 倫理的リスク | 亡くなった人の模倣などが感情的・道徳的議論を呼ぶ | 使用制限とガイドラインの策定 |
| モデル誤応答 | 人格や関係性に合わない返答をしてしまう | 評価ログとフィードバックループで再学習 |
これらの壁を越えるためには、ただ技術を磨くだけでなく、運用者としての「姿勢」が問われます。特に倫理的な設計思想と利用ガイドラインの明文化は急務です。
今後の改善点と開発ロードマップ
今後の改良点と開発の優先順位は以下の通りです。
| 開発項目 | 優先度 | 概要 |
|---|---|---|
| タグ付き発言ログ機能 | 高 | 発言ごとに応答タグを付けて、精度と一貫性を高める |
| Phase2モジュールの独立化 | 高 | chatgpt_logic.pyから分離し、人格生成用の新ファイルとして設計 |
| 評価ログDB構築 | 中 | ユーザーの満足度を記録し、改善対象の特定に活用 |
| LINE Botの応答制御 | 中 | 反応する条件の明確化と無視設定などの実装 |
| Voice変換対応 | 低 | 将来的な音声返信に向けて、声質プロファイルの実験を進める |
以上が、Phase2の今後に向けた展望と課題です。これらを一つひとつ乗り越えることによって、単なるチャットボットではない、人に近い応答エージェントの実現が視野に入ってきます。




