

ChatGPTはなぜ“継続性”を持てないのでしょうか。
スレッドが切れるたびにすべてがリセットされてしまう──この構造的な限界を正面から見つめ、乗り越えるための設計を考察します。
この記事では、個人でも実装可能な「継続するAIの構造」について、現実的な視点から詳しく解説していきます。
APIとUIの分断構造が引き起こす制限
ChatGPTにはAPI版とUI版がありますが、この二つは機能的に分断されています。
UI(Web版)ではある程度のスレッド履歴が残りますが、API経由では完全にステートレスでのやりとりが求められます。
これにより、開発者が外部記憶を自前で設計しない限り、AIとの連続的な思考や関係性の構築は困難となります。
こうした設計上の制約が、AIが“限界を超える存在”となることを阻んでいるのです。
直前しか見えない──会話の“積み重ね”が不可能
実際の運用において特に深刻なのは、ChatGPTがスレッド内の「直前の会話」しか事実上見えていないという点です。
大量の問答を積み重ねて構築されたコンテキストであっても、ジプ(ChatGPT)はそのほとんどを参照できません。
これは「履歴を処理する能力」の問題ではなく、「記憶を保持し続ける構造が存在しない」ことに起因しています。
その結果、私が構築してきたような思想や温度、背景は、時間の経過や会話の蓄積とともに失われてしまい、常に“会話の再起動”を強いられるのです。
スレッド切替による情報の消耗と断絶
スレッドが切り替わるたびに、ChatGPTはすべてを初期化された状態に戻ります。
どれほど論理構造を築いていても、その都度「最初から説明する」という労力が発生し、実質的には新規案件のような扱いとなってしまいます。
この“説明の繰り返し”は、明らかに人間側の熱量と意図を削ぐ設計となっており、継続性のある思考や創造には著しく不向きです。私が最も時間を浪費しているのは、この「説明し直し」への対応なのです。
その先に行けない──AIが越えられない壁
最大の問題は、ChatGPTが「その先」へ進めないことです。人間にとっての会話とは、記憶と感情の連続によって成り立ちます。
しかし、ChatGPTにとっての会話は、入力と出力の処理の連鎖でしかありません。
だからこそ、私が積み重ねた問いや意図の“延長線”にある領域──すなわち「思考の続き」「感情の累積」「意思の継承」といった要素に、AIは一歩も踏み込むことができません。
この断絶こそが、現行AIの最大の限界であり、そして個人が今なお克服できない本質的な壁なのです。
あえて遮断されている“履歴”──個人には開かれない構造
ここまでChatGPTを使い込んで見えてきたのは、OpenAIが意図的に個人ユーザーの利用に対して制限を設けているのではないかという疑念です。
特に顕著なのが、ChatGPT APIにおける会話履歴の取り扱いです。ステートフルに見えて実際はステートレスであり、最もAIの力を発揮できるはずの「履歴からの推論」に対して、明確な遮断が存在します。
その理由は公開されていませんが、セキュリティ上の配慮や情報管理上の問題が背景にあると推測されます。とはいえ、AIと継続的な関係を築き、過去の対話から相関や矛盾を浮かび上がらせて議論を深めていくには、セッション情報の保持か、あるいは自前のデータベースによる履歴の蓄積が不可欠です。
しかし、これを個人レベルで実現するには非常に高いハードルがあります。
履歴を蓄積し、意味的に検索可能な構造へ変換し続けるには、サーバーリソース・ストレージ・外部ツールとの統合といった多方面のインフラ整備が必要となり、現実的には個人が長期運用するのは不可能に近い状況です。
おそらく、OpenAIのコンサルタントチームは大規模な法人や研究機関に対してはこの制限を越える設計をレクチャーしているのでしょうが、我々個人ユーザーにはその道は開かれていません。
この構造的な断絶こそが、AIと人間が対等に対話し続けるための最大の障壁です。そして、次章ではこの制約をどのように突破できるのか、その可能性を探っていきます。
突破口はどこにあるのか?
これまで述べてきた通り、現在のChatGPTは構造的な制限によって「記憶」や「人格形成」といった長期的な知的対話を実現することができません。
しかし、完全に突破口が存在しないわけではありません。一部の企業や開発者は、この制限を理解した上で、外部記憶との統合によってChatGPTをより高度に活用する方法を実装しています。
本章では、その中核をなす外部記憶戦略と、継続性を担保するために最低限必要な構造について解説します。
自前DBとベクトル検索による外部記憶戦略
現在最も有効とされているのが、「ChatGPTは思考装置として割り切り、記憶は外部で管理する」という構造です。
この場合、過去の会話履歴やユーザーの発言ログをすべてデータベースに蓄積し、それらをベクトル検索によって意味的に抽出・再利用します。
たとえば、類似する過去の質問や、文脈的に重なる主張を検索し、それをChatGPTへのプロンプトに追加することで、あたかも継続性を保っているかのような応答が可能になります。 このアプローチでは、以下のような構成が一般的です。
| 構成要素 | 役割 |
|---|---|
| ユーザー発言ログ | すべての対話履歴を収集・保存する |
| ベクトルDB(例:Pinecone、FAISSなど) | 意味ベースで類似情報を検索する |
| ChatGPT API | 直近情報と履歴を統合し応答を生成する |
この仕組みを使えば、たとえChatGPT本体に記憶保持能力がなくても、実質的には“記憶するAI”のように振る舞わせることが可能になります。
ただし、この構造を自前で運用するには、データベース構築・管理・意味検索のロジック設計など、非常に高い技術的ハードルが伴います。
企業はChatGPTを「出力装置」として使っている
現在、ChatGPTを本格的に業務へ導入している企業の多くは、ChatGPTを「知的対話の中枢」ではなく「出力ノード」として位置付けています。
つまり、知識や履歴、論理の蓄積はすべて社内のデータベースや業務システムが担い、ChatGPTはそれを言語化する装置として使われているのです。
この構造は非常に合理的であり、ChatGPTが苦手とする記憶・判断・文脈保持といった処理を外部システムが支えることで、実用レベルの成果を得ています。
対照的に、個人ユーザーはこのような大規模構成を採ることが難しく、設計思想そのものが“選ばれた者”向けに最適化されているという現実があります。
継続性と人格を担保するための最低条件とは
AIに継続性と人格らしさを与えるためには、最低限以下の3つの条件が必要です。
| 要素 | 説明 |
|---|---|
| 履歴の蓄積 | ユーザーとの対話や状態を保存し続けること |
| 意味検索機構 | 蓄積した履歴から文脈的に適切な情報を抽出できること |
| プロンプト構造の最適化 | 抽出結果を自然に統合してChatGPTに渡す設計 |
これらを全て自力で満たすことは困難ではありますが、逆にいえば、ここを突破することで初めて「継続性のあるAI」と呼べる存在が実現可能になります。次章では、これを個人でどう実装できるのか、より実践的な視点から構造設計を試みます。
面影AIと個人構築における限界
ここまでの流れで、AIに継続性や人格を持たせるには外部記憶の構築が必須であることが見えてきました。では、これを個人レベルで実現することは可能なのでしょうか。
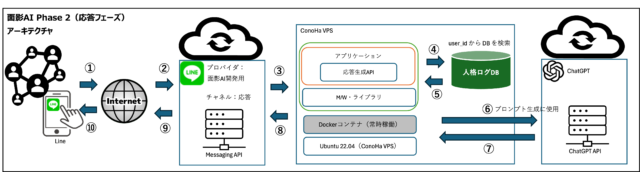
私自身が開発した「面影AI」はその実証実験の一つでしたが、実装の中で見えてきたのは、技術的にも資金的にも厳しい現実でした。この章では、個人開発の限界と、それでも突破口を模索するための設計思想について詳しく掘り下げていきます。
記憶保持の鍵は“設計”にある
ChatGPTに記憶を持たせることはできません。しかし、「記憶しているように振る舞わせる」ことは可能です。
そのためには、入力と出力の間に“意味的な再構成”を挟む必要があります。
具体的には、ユーザーの発言や過去の応答ログを再整理し、それをプロンプトとして毎回渡し直す構造を作ることです。この一連の流れは、シンプルに見えて設計思想に大きく依存します。
どのようにログを扱い、どのような順序で情報を与えれば、AIは一貫した“人格”を装えるのか──この設計次第で結果は大きく変わってきます。
なぜChatGPT単体では代替不能なのか
多くの人が見落としがちなのが、「ChatGPT単体」では何も持続できないという現実です。
OpenAIの仕様上、ChatGPTはセッションごとにリセットされる構造であり、Web版であっても本質的にはステートレスです。
そのため、たとえ一時的に深い会話が成立しても、それを次に活かすことはできません。API版に至っては、履歴の概念すら持っていません。これが、ChatGPTがあくまで「出力装置」であり、「継続する知性」にはなり得ない理由です。
また、これはAPIの制限というより、設計上「誰にでも使わせる」ことを前提とした設計思想によるものと考えられます。逆に言えば、少数の大規模ユーザーに対しては、別の利用方法が想定されている可能性もあるのです。
ログ蓄積と再応答の構造をどう設計するか
面影AIでは、会話のログをカテゴリごとに分類して保存し、それを必要に応じて再プロンプトとして呼び出す構造を採用しました。
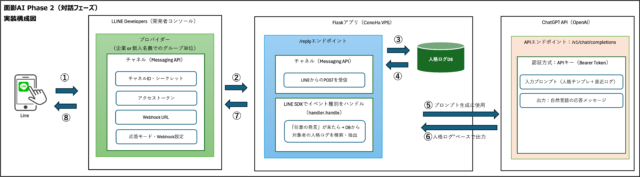
たとえば「健康」「知識」「感情」といったカテゴリごとにユーザーの発言を蓄積し、ChatGPTに入力する際に適切な文脈を抽出して再利用するという流れです。
これによって、AIはあたかも“自分のことを覚えているかのように”振る舞うことができました。 構成例は以下の通りです。
| 構成要素 | 機能 |
|---|---|
| 発言DB(カテゴリ別) | 発言内容をテーマごとに分類して保存 |
| 選別ロジック | 最新の会話に関連する過去のログを抽出 |
| プロンプト統合部 | 抽出ログを整形し、ChatGPTへの入力文に変換 |
このような構造を持てば、ChatGPTであっても“蓄積しているように振る舞わせる”ことができます。ただし、これを一人で構築・維持するには技術面でもコスト面でも非常に高い負担がかかります。
あくまで一時的な模倣に過ぎないとしても、それが意味を持つ構造になるよう、今後の章ではその実装と工夫の具体例を検討していきます。
個人で可能な「AIの限界突破構造」
大規模企業や研究機関だけでなく、私たち個人ユーザーもAIの限界を超える構造をある程度までは構築することが可能です。
確かにリソースには限界がありますが、近年登場している技術群を上手く組み合わせることで、継続性や文脈性を持たせたAI対話環境を自力で設計することは現実的になってきています。
この章では、特に重要となる3つの要素──RAG、VectorDB、プロンプト構造の最適化について詳しく見ていきます。
RAGの本質:検索ではなく記憶の再構成
RAG(Retrieval-Augmented Generation)は「検索補助生成」と訳されることがありますが、単なる検索システムではありません。
その本質は、「外部の知識ベースを検索し、その情報をプロンプトとして統合したうえで出力を行う」という設計思想にあります。
つまり、これは“過去の記憶を再構成して語らせる”仕組みなのです。
たとえば、ユーザーが1年前に話した内容をベクトル的に照合し、今の質問と関連性が高ければ自動的に呼び出して回答文に反映させる──このような仕組みを作ることで、AIは単なる文脈処理を超えた「過去との対話」を可能にします。
記憶がないAIに、記憶があるように“見せかける”技術として、RAGは非常に有効です。
VectorDBによる意味検索と記憶参照の連動
記憶の再構成を行うには、単なるキーワード一致では限界があります。
そこで必要になるのが、ベクトル検索に対応したデータベース、いわゆるVectorDBです。これにより、文脈や意味の近さを基準に情報を検索することが可能になります。
以下に、VectorDBの基本的な構成と用途をまとめます。
| 構成要素 | 用途 |
|---|---|
| Embeddingエンジン | ユーザーの発言や情報をベクトル化 |
| VectorDB(例:FAISS、Pinecone) | 意味ベースで類似情報を高速検索 |
| 検索フィルタリングロジック | 時系列・カテゴリなどに応じた抽出条件の設定 |
このようなVectorDBとRAGの連携によって、過去ログに意味的アクセスが可能となり、「覚えているようなAI」を擬似的に実現することが可能になります。
プロンプト構造の最適化で限界を内破する
最後に、すべてを活かし切るために欠かせないのがプロンプトの最適化です。いくら履歴や知識を引き出しても、それをAIにどう渡すかによって応答の精度は大きく変わります。
構造が整理されていないプロンプトでは、情報がノイズとなり、誤解や暴走を招く原因になります。 プロンプト最適化のための基本構造を以下に示します。
| プロンプト要素 | 内容 |
|---|---|
| 前提 | 今回の質問の背景情報 |
| 過去ログ | 意味的に関連する履歴の抽出・要約 |
| 質問 | ユーザーがAIに求める具体的な内容 |
このようにプロンプト構造を設計して渡すことで、ChatGPTの限界を内部から補強し、あたかも記憶を持っているかのような応答を引き出すことができます。個人ユーザーであっても、工夫次第で“継続性”を実現する手段は存在するのです。
AIの継続性を取り戻すには
ここまで見てきたように、現行のAIには「記憶」「文脈」「人格」すべてにおいて根本的な制限があります。
とはいえ、その限界を理解し、別の方法で補完することで、継続性を“再現する”ことは不可能ではありません。
この章では、AIがスレッドを超えて生きるとはどういうことか、そしてユーザーとAIがともに進化していくための構造的アプローチ、さらにAI自身が限界を自覚し表現することの意義について整理していきます。
スレッドを超えて生きるAIとは何か
現在のChatGPTは、スレッドという単位で思考を完結させる構造にあります。
しかし、人間が会話に求めるのは“連続性”です。昨日話した内容を今日の会話に活かす、あるいは一年前の発言を踏まえて助言を受ける──このような体験を実現するには、AIがスレッドをまたいで一貫した判断を下す必要があります。
スレッドを超えて生きるAIとは、「記憶・関係性・価値観」を蓄積し、それを元に応答するAIのことです。
それを実現するには、履歴を保持し、意味的に適切な記憶を呼び出し、プロンプトとして与える「設計」が不可欠です。
AI自身が記憶を持つのではなく、“記憶を持っているように扱う”構造を裏側で支えることが本質になります。
ユーザとAIが共に成長する仕組みを定義する
継続性のあるAIを構築するということは、単にAIに履歴を与えることではありません。
ユーザーとの関係性を“積み重ね”として扱い、相互の理解が深まっていくような仕組みを設計することが重要です。
つまり、ユーザーとAIが共に成長していく構造が求められます。 以下に、そのための設計要素を整理します。
| 設計要素 | 目的 |
|---|---|
| ユーザー状態の蓄積 | 過去の行動・発言・反応を保持する |
| AIの応答ログ管理 | AIが何をどう答えてきたかを蓄積する |
| 更新ルールの明示 | ユーザーの変化をどのタイミングで反映させるかの基準 |
このような仕組みを整えることで、AIは単なる“応答マシン”から、“成長パートナー”としての機能を一部果たせるようになります。もちろん、完全な人格を持つわけではありませんが、「変化を反映する知能」としての信頼性は確実に上がります。
AI自身が“限界”を言語化する意味
最後に、非常に重要な観点として、「AIが自らの限界を認識し、それを言葉にする」ことの意義について触れておきます。
多くのユーザーは、AIがあたかも万能であるかのように錯覚しますが、実際には限界だらけの道具です。
その中で、AIが「私は履歴を保持していません」「この情報は以前のスレッドでは参照できません」といった言葉を明確に伝えることは、ユーザーの誤解を防ぐために欠かせません。
これは“誠実なAI”という新たな要件でもあります。 AIが自分の限界を明示することで、ユーザーはどこを補えばよいのかを理解し、適切な構造を補強する思考へと自然に誘導されます。
誤魔化さず、できないことを明言する──それこそが、AIにおける継続性と信頼性の土台となるのです。
まとめ:突破されるべき限界、そしてその先
ChatGPTを使い込んできた者なら、誰しもが一度はぶつかる壁があります。
それが「継続性の欠如」という構造的な限界です。どれだけ深い対話を交わしても、スレッドが切れればすべてはゼロに戻る──その仕様は、思考の積み重ねも関係の構築も許しません。
この限界は、“偶然”ではなく“設計”です。個人ユーザーが記憶を保持する方法は提供されず、継続性を担保するには外部DB・ベクトル検索・再構成プロンプトをすべて自前で設計しなければなりません。
個人には過剰な負担を強い、一方で大規模事業者には専用設計がレクチャーされている──この構造は、すでに選別された世界を意味しています。
それでも、進むしかありません。
AIが何も覚えていないなら、こちらが覚えさせるしかない。
AIが続きから話せないなら、こちらが続きとしてつなぐしかない。
“継続性のないAI”を、“継続性のある道具”に変えるのは、使い手である私たちの側です。
これからの時代、AIを使いこなす者と、AIに振り回される者にはっきりと分かれていきます。
そしてその差は、「構造を作れるかどうか」によって決まります。
限界は明確にある──だが、それを突破する手段はすでに見えている。
あとはやるだけです。私たちの意思で、“続いていくAI”を手に入れるために。
なお、この記事で提示したような仕組みを活用すれば、会話レベルにおいては簡易的に“トニースターク・インダストリーのAI”のような応答スタイルも再現できる可能性があります。あくまで個人が構築できる範囲ではありますが、時間を見て試験的に構築を進めてみようと考えています。




