

JavaでJDBCを使ってDBアクセスを行う場合、毎回 DriverManager.getConnection() を呼び出して接続・切断を繰り返す構成をよく見かけます。
しかしこのやり方は、アプリケーションの規模や接続頻度が高くなるほど、パフォーマンスのボトルネックになっていきます。
本記事では、シリーズ第3回として、共通DBアクセスクラス内で採用している DBConnectionPoolクラス の設計と仕組みにフォーカスします。このクラスは、自前で構築した簡易的な接続プール機構を用いることで、アプリケーションの中で 1つのDB接続を複数回使い回すことを目的としています。
また、外部設定ファイル(system.xml)から接続情報を読み込む構成や、シングルトンパターンによるインスタンスの一元管理についてもあわせて解説します。
ORMのような重厚な設計ではなく、軽量でシンプルな自前ロジックを好む方にとって、実用的なヒントになるはずです。接続の再利用、設定の外出し、そして共通化。この3つのキーワードで、無駄なDBアクセス処理から抜け出す仕組みを紐解いていきます。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを想定しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
DB接続を最適化する必要性と背景
アプリケーションがデータベースとやり取りを行う際、その接続の管理方法はシステム全体のパフォーマンスと安定性に大きな影響を与えます。
特にJDBCを用いたシンプルな構成では、都度接続・切断を繰り返す設計が散見されますが、これが原因で発生する処理コストや非効率性を放置したままでは、将来的にシステムの負荷や障害リスクを高める結果になりかねません。
本セクションでは、DB接続に関する基本的な課題を洗い出し、接続の最適化がなぜ重要なのかを具体的に掘り下げていきます。
単発接続のコストが生む問題点
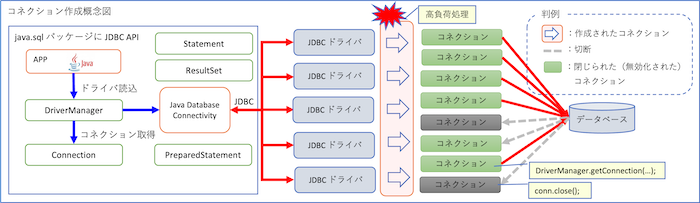
JDBCによる単発接続の構成では、SQLの発行ごとに以下のような流れが繰り返されます。
Connection conn = DriverManager.getConnection(…); // SQL発行処理 conn.close();
この流れを毎回繰り返すと、コネクションの生成とクローズ処理がオーバーヘッドになります。特にPostgreSQLやOracleのようなエンタープライズ系のDBでは、接続初期化にそれなりの時間とリソースが必要です。
これが、1トランザクションごと、あるいは1リクエストごとに実行される場合、想像以上にパフォーマンスを損なう結果となります。
また、ネットワーク越しのDB接続では、わずかでも物理層の待ちが発生する可能性があるため、接続の再利用を行わない構成は本質的に非効率です。
これらの細かいオーバーヘッドは、リクエストの増加に比例して全体システムの遅延要因となっていきます。
バッチ処理や連続実行時の非効率性
連続して大量のデータを処理するバッチ処理やETL系のタスクでは、数百~数千回のDBアクセスが1ジョブ内で発生することがあります。
こうした処理においても、都度接続を取得・切断する構成のままでは、ジョブ全体の実行時間が何倍にも膨らむ恐れがあります。
例えば、1000レコードを個別に更新するループ処理があったとします。
以下のような構成になっていた場合、それだけで1000回の接続・切断が発生することになります。
for (DataBean data : dataList) {
Connection conn = DriverManager.getConnection(...);
// 更新処理 conn.close(); }
このような構成は一見安全に見えますが、実際には明確な非効率であり、CPUやネットワーク帯域を無駄に消費する結果となります。
また、DB側の接続制限(max_connections)に達してしまうと、新たな接続ができなくなる可能性もあるため、安易な単発接続はシステム全体の安定性を損なう要因になります。
なぜコネクションプールを採用するのか
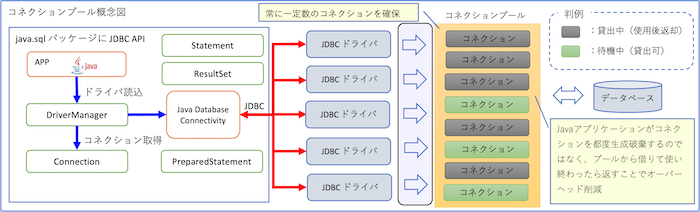
共通DBアクセスクラスでは、こうした単発接続の課題を解決するために、DBConnectionPoolクラスを実装しています。
このクラスは、接続を毎回生成・破棄するのではなく、既存の接続を保持し、必要に応じて再利用するための簡易的なコネクションプールの役割を担います。
外部のフレームワークに依存せず、軽量でメンテナンス性の高い構成とするために、Apache Commons DBCP や HikariCP のようなサードパーティ製ライブラリはあえて使用していません。
その代わり、内部的には「接続がnullまたは閉じられている場合にのみ再接続を行う」というシンプルな設計思想に基づいて動作します。
この仕組みにより、次のようなメリットが得られます。
| 項目 | 効果 |
|---|---|
| 接続生成の回数削減 | パフォーマンスの向上とDB負荷の軽減 |
| 接続エラーの抑制 | DB側のmax_connections制限を回避 |
| アプリケーションの安定化 | 大量アクセス時でもスムーズな処理が可能 |
このように、DBConnectionPoolの導入は単なる技術的な選択ではなく、アプリケーション全体の健全性を支える重要な設計判断となります。
DBConnectionPoolクラスの設計意図
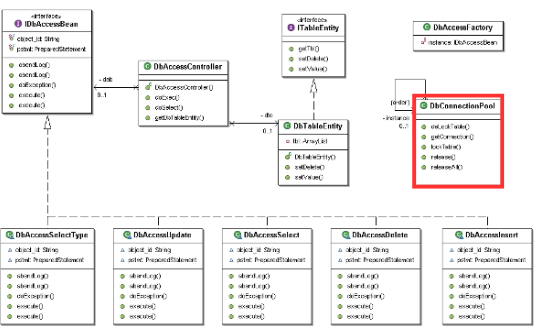
共通DBアクセスクラスにおける核となる仕組みの一つが、DBConnectionPoolクラスによる接続の一元管理です。
このクラスは、JDBCによるDB接続の構築・解放処理を統一的に制御することで、アプリケーション全体の安定性とパフォーマンスを担保しています。 その基本思想は「使える接続は再利用し、無駄な接続生成を行わないこと」です。
複雑なフレームワークを使わずに、独自でシンプルな接続管理機構を実現することで、学習コストや依存性を抑えつつ、安全で再利用性の高い設計にしています。
ソース全体はこちら
👉 GitHub – db-access-core / data ディレクトリ
接続の再利用に特化したシンプルな構造
DBConnectionPoolクラスは、内部に1つのConnectionオブジェクトを保持し、必要に応じてこの接続を返すという構造になっています。
ライブラリベースのコネクションプールのように複数の接続インスタンスを管理するのではなく、「1つの接続を大事に使い回す」というシンプルな構成です。
そのため、アプリケーションが同時に多数のスレッドからDB接続を要求するような場面ではなく、単一のスレッドまたは少数のバックグラウンド処理を対象とした設計になっています。
この構成は、処理の構造を理解しやすく、バグの発生を抑えるうえでも効果があります。
getConnectionメソッドの役割と再接続判定
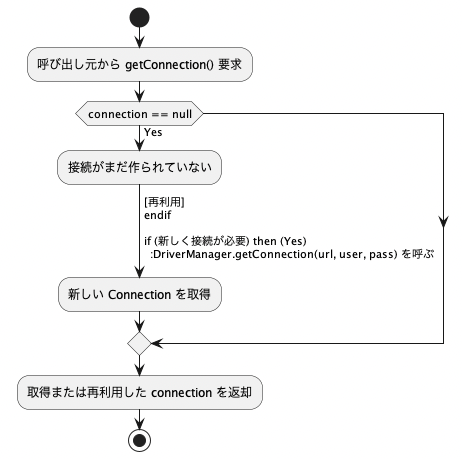
接続を外部に提供する役割を担うのが、 getConnection() メソッドです。呼び出し元がこのメソッドを使うたびに、DBConnectionPoolは次のような条件で接続を判断します。
public Connection getConnection() throws SQLException {
if (this.connection == null || this.connection.isClosed()) {
this.connection = DriverManager.getConnection(…);
}
return this.connection;
}
このように、接続がnullまたは閉じられているかを判断し、必要であれば再接続します。
isClosed() を事前に確認することで、接続切れや障害時に自動的に再接続する仕組みを持たせています。
なお、障害からの復旧処理を簡潔に済ませることができるのも、この設計のメリットです。
インスタンス変数としてのConnectionの扱い方
DBConnectionPoolクラスでは、 private Connection connection; のように、接続をインスタンス変数として1つだけ保持しています。これはクラス内で一元的に接続を管理するという設計ポリシーに基づいています。
呼び出し元が何度 getConnection() を呼んでも、既存の接続が使える場合は新たに生成されることはありません。これにより、意図しない接続の増加や接続数オーバーを防ぎます。
また、意図的に明示的な close() を行う必要がないように、全体の処理系では try-finally 構文により自動的なクローズ処理が構成されています。
この接続のスコープを明確にすることで、システム設計者がどのタイミングで接続が生きているかを把握しやすくなり、リソースリークのような問題を未然に防ぐ効果があります。
接続管理の処理フローと例外時の対策
DB接続はアプリケーションにとって生命線ともいえる重要なリソースです。そのため、コネクションの生成・再利用・クローズ処理までの一連のフローを明確に設計し、障害発生時にも耐えられるような構成が求められます。
このセクションでは、DBConnectionPoolクラスが担っている接続ライフサイクルの管理ロジックと、障害発生時の再接続処理やリソース確保の方針について整理していきます。
nullチェックと閉じられた接続の自動再生成
DBConnectionPoolクラスの接続提供処理では、常に「接続が使える状態か」を判定してから返却します。主なチェックは `null` 判定と、`isClosed()` の結果によるものです。
if (this.connection == null || this.connection.isClosed()) {
this.connection = DriverManager.getConnection(...);
}
このように、現在の接続インスタンスが無効と判定された場合は、新しい接続を生成して置き換えるという仕組みになっています。 これにより、以下のようなトラブルを回避できます。
| 想定される状態 | 自動再接続による効果 |
|---|---|
| 接続がGCでクローズされていた | 常に再接続を行うことで復旧可能 |
| DB再起動によるコネクション切断 | 新しい接続で再開しエラー回避 |
| プログラム側で明示的にcloseされていた | 切断後でも再接続により正常復旧 |
特に、深夜のバッチ処理や非アクティブな時間帯のタイムアウトによって、DBとの接続が意図せず切断される場面では、この再接続処理が大きな安定要因となります。
try-finallyによるクローズ処理の徹底
再利用可能な接続であっても、明示的なクローズ処理がなければリソースリークの原因になります。そこで、クエリ実行後の `ResultSet` や `Statement` のクローズ処理を必ず実行するために、以下のような構造を徹底しています。
Connection conn = null; Statement stmt = null; try {
conn = DbConnectionPool.getInstance().getConnection();
stmt = conn.createStatement();
// SQL実行処理
} finally {
if (stmt != null) stmt.close();
}
上記のように、クローズ処理を finally 節に配置することで、正常系・異常系を問わず確実にリソースを解放することができます。
さらに、接続自体を完全に破棄しないことで、DbConnectionPool 側で保持されているインスタンスはそのまま再利用可能な状態を維持します。
このような処理構成により、**「クローズしているように見えて、実は接続を維持している」**という軽量な運用が実現できます。
障害発生時に備える簡易な冗長構成
DB接続の際には、ネットワーク断やDB再起動など、外部要因でコネクションが切断されるケースを常に想定しなければなりません。
DBConnectionPoolクラスでは、接続が不可であった場合にも例外を握りつぶすことなく、確実に呼び出し元に `SQLException` をスローする設計としています。
if (this.connection == null || this.connection.isClosed()) {
this.connection = DriverManager.getConnection(url, user, pass);
}
この接続取得部分で例外が発生した場合は、Loggerクラスを通じてログに記録され、SystemExceptionでラップされる形で上位層へ伝播されます。
この設計により、呼び出し元では処理の再試行やフェイルオーバー切り替えなどを柔軟に設計することが可能になります。
また、障害が頻発するDB環境では、以下のような冗長化対応を組み合わせることで信頼性を向上させることができます。
| 手法 | 効果 |
|---|---|
| セカンダリDBへの切替処理 | メインDB障害時の代替アクセス確保 |
| リトライ回数の設定 | 一時的な接続断への自己復旧 |
| ログレベルによる障害通知 | 問題発生時に即時検知が可能 |
このように、DBConnectionPoolの内部構造は非常に簡素でありながらも、障害時の復旧処理を最小限で実装できる拡張性を確保しています。
SystemInfoを介した接続設定の外部化
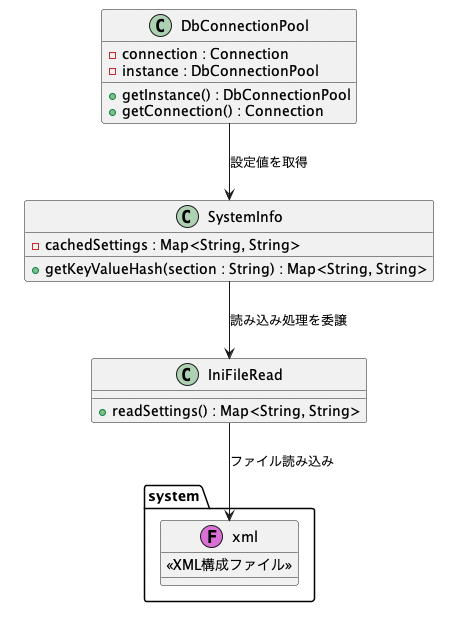
データベースの接続先情報は、アプリケーションの実行環境によって異なるのが常です。
開発環境・テスト環境・本番環境などで接続情報が異なるにも関わらず、プログラム内部にハードコードされたままでは、切り替えのたびに再ビルドが必要となり、保守性に大きな問題を残すことになります。
この課題を解決するため、共通DBアクセスクラスでは「system.xml」ファイルを使用して接続先設定を外部化し、それを `SystemInfo` クラス経由で取得する設計を採用しています。
ここでは、その処理構成と取得方法について解説していきます。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
system.xmlからの読み込み手順と構成ファイルの役割
system.xmlは、アプリケーションの起動時に一度だけ読み込まれる外部構成ファイルです。
ここに、データベース接続やログ出力のパラメータなど、環境に依存する情報を集中して定義します。
このファイルは、設定変更のたびにプログラムのビルドや再配置を必要とせず、運用時の柔軟性を保ったままシステムの振る舞いを制御することができます。
設定ファイルの読み込みは、内部的には IniFileRead クラスでXMLを解析する処理として実装されています。
その結果はメモリ上にキャッシュされ、複数回のアクセスでもファイルを再読み込みすることはありません。
IniFileRead経由でHashMapとして取得する仕組み
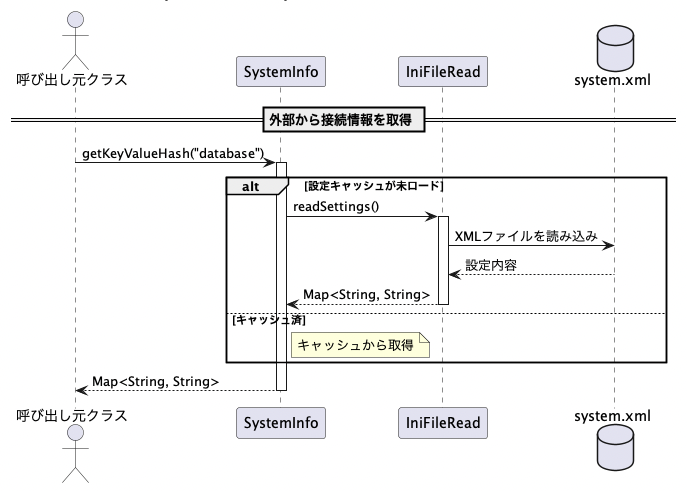
設定ファイルの内容は、Javaの `HashMap<string, string="">` 型に変換され、各セクション単位で管理されます。
ファイルを直接パースして扱うのではなく、一度ハッシュマップに展開しておくことで、以後のアクセスが高速化されるとともに、シンプルなAPIで必要な設定値を取得できるようになっています。
この機能は SystemInfo.getKeyValueHash("database") のように呼び出すことで実現され、必要なセクション(ここでは "database")の設定キーと値が全て返却される形となります。
Map<String, String> dbSettings = SystemInfo.getKeyValueHash("database");
String url = dbSettings.get("url"); String user = dbSettings.get("username");
String pass = dbSettings.get("password");
このように、DBConnectionPoolクラスなどでは直接ファイルを読むことなく、SystemInfo を通じて値を取得するだけで済むため、処理が非常に簡潔になります。
接続設定情報のキー構成と利用例
system.xml に記述される各項目は、キー名とその値で構成され、セクション名でグルーピングされます。ここでは、接続設定に関係するセクションとその具体的な構成例を紹介します。
接続設定の構成例(system.xml)
以下は、system.xml における `` セクションの実例です。 この構成を使うことで、接続先情報を変更する際はこのファイルを修正するだけで済み、アプリケーション側のソースコードには一切手を加える必要がありません。
| キー名 | 説明 | 例 |
|---|---|---|
| username | データベースのユーザー名 | postgres |
| password | データベース接続に使用するパスワード | P@ssW0rd |
| url | 接続先URL | jdbc:postgresql://localhost:5432/postgres |
| connect | 最大接続数や接続試行回数の目安 | 20 |
| driver | 使用するJDBCドライバのFQCN | org.postgresql.Driver |
| object_id | システム内で使用するオブジェクト識別子 | OID |
getKeyValueHashで取得するキーと値のマッピング例
system.xmlの構成が前述のようになっている場合、`SystemInfo.getKeyValueHash("database")` を呼び出すと、次のようなマッピングが得られます。
| 取得されるキー | 取得される値 |
|---|---|
| username | postgres |
| password | P@ssW0rd |
| url | jdbc:postgresql://localhost:5432/postgres |
| connect | 20 |
| driver | org.postgresql.Driver |
| object_id | OID |
この形式で返却されることで、どのクラスからでも必要な接続情報を即座に取得でき、また環境切り替え時にも柔軟に対応できます。 </string,>
シングルトンによる接続管理の一元化
共通DBアクセスクラスでは、アプリケーション全体を通じて同一のDB接続管理インスタンスを再利用するために、**シングルトンパターン**を採用しています。
この設計により、各コンポーネント間で接続の状態を共有しながら、一貫性のある接続管理が可能になります。
ここでは、DBConnectionPoolがどのようにシングルトンで設計されているか、またそのメリットと注意点について詳しく解説していきます。
シングルトンとは
シングルトンとは、GoF(Gang of Four:デザインパターンを体系化した4人の著者陣)が提唱した23種類の基本デザインパターンのうちの1つであり、最初に紹介される「パターン1番」でもあります。
このパターンの目的は、アプリケーション内でただ1つのインスタンスだけを生成し、どこからでも同じものを参照できるようにすることです。つまり、接続プールのように「共通で使いまわしたい資源」がある場合に非常に相性が良いのです。
Javaでは以下のように書くことで、初回だけインスタンスを生成し、2回目以降はそれを返すという仕組みを簡単に実現できます。
private static DbConnectionPool instance = null;
public static synchronized DbConnectionPool getInstance() {
if (instance == null) {
instance = new DbConnectionPool();
}
return instance;
}
特に今回のように「DB接続は複数箇所で使うが、同じ設定で動かしたい」というケースでは、わざわざ毎回インスタンスを作るのではなく、1つのものをずっと使い続ける方が安全で効率的です。
インスタンス生成を1回に限定する実装設計
DBConnectionPoolクラスでは、以下のようにインスタンスの生成が1回だけ行われるよう設計されています。
private static DbConnectionPool instance = null;
public static synchronized DbConnectionPool getInstance() {
if (instance == null) {
instance = new DbConnectionPool();
}
return instance;
}
このように、getInstance() メソッド内でインスタンスの有無を確認し、存在しない場合のみ生成するという「遅延初期化型」のシングルトンになっています。
この設計によって、必要になるまでインスタンスを生成せず、かつ複数の箇所から呼び出されても常に同一のインスタンスが返却されることが保証されます。
このパターンを導入することで、アプリケーション全体の中で1つのDBConnectionPoolが使い回されるようになり、無駄なインスタンス生成を抑制できます。
getInstanceによる共通インターフェースの確立
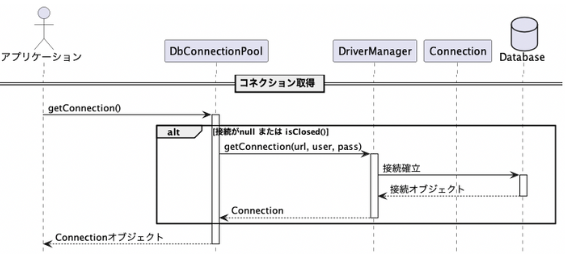
シングルトンとして設計された `DbConnectionPool` は、呼び出し側からは常に次のように統一された形で使用されます。
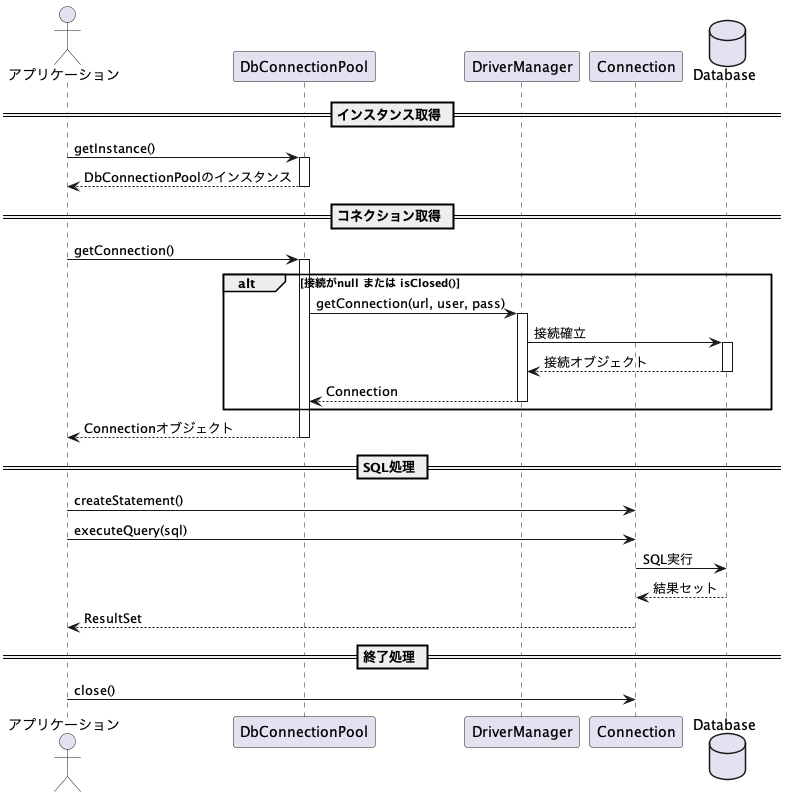
Connection conn = DbConnectionPool.getInstance().getConnection();
この記述がすべてのDAOクラスやバッチ処理内で共通して使用されるため、開発者は接続生成に関する実装を一切意識せず、同じインターフェースを通じてDBアクセスを行うことができます。
また、共通インターフェースである getConnection() の中に接続チェックや再接続処理が含まれているため、呼び出し元のロジックにエラー対策や接続状態の考慮を持ち込まずに済むという利点があります。
このように、統一された呼び出し口を設けることで、アプリケーション全体の接続管理をシンプルかつ堅牢に保つことができます。
スレッドセーフにする設計上の注意点と割り切り
シングルトンパターンを採用する上で避けて通れないのが「スレッドセーフ性」の問題です。
共通インスタンスに複数のスレッドが同時にアクセスする環境では、競合やリソースの一貫性に関する設計が必要になります。
DBConnectionPoolクラスでは、インスタンスの初期化を synchronized によって排他制御していますが、getConnection() の実行自体はシングルスレッドである前提に立っています。
そのため、大量同時接続や並列処理を前提としたWebアプリケーションやマルチスレッドバッチ処理には適していません。 以下に、用途と制約を表で整理します。
| 利用シーン | 評価 |
|---|---|
| スタンドアロンのバッチ処理 | ◎ 安定して使用可能 |
| 業務アプリのサーバー常駐処理 | ○ 制限付きで使用可能 |
| マルチスレッドのWebアプリ | △ サードパーティ製プールの導入を推奨 |
もし並列処理環境での使用が想定される場合は、Apache Commons DBCP や HikariCP といったコネクションプールライブラリの導入が検討されるべきです。
一方で、共通DBアクセスクラスの目的は「複雑なライブラリ導入なしで簡潔にDBアクセスを扱いたい」という点にあります。
そのため、シングルトンによるシンプルな設計が、開発者の学習負荷を軽減し、保守性を高める効果を生んでいます。
第4回へのつなぎと処理全体の補足
ここまで、共通DBアクセスクラスにおけるDBConnectionPoolの構造、設定ファイルによる外部化、接続の最適化について解説してきました。
しかし、実際の業務アプリケーション開発においては、「接続が確立されたら終わり」ではなく、さらにその上で、**障害に対する例外処理**や**ログ出力による可視化**などが不可欠となります。
このセクションでは、次回の記事につなげる形で、共通基盤として動作している例外ハンドラやログクラスの存在について簡単に整理しておきます。
例外処理クラス(SystemException)の存在について
共通DBアクセスクラスには、すべてのDB操作に共通して適用できる**例外処理クラス SystemException** が用意されています。
このクラスは `RuntimeException` を継承しており、発生した例外に付加情報(クラス名、メソッド名、ユーザー名、ログレベルなど)を追加した状態で throw できるように設計されています。
この共通例外クラスは、次のような目的で使用されます。
| 目的 | 効果 |
|---|---|
| SQL例外のラップ | DB障害のトレースとメッセージ統一 |
| 想定外の例外補足 | アプリの異常終了防止 |
| 例外レベルに応じたログ出力 | ログの粒度制御と判別が可能 |
呼び出し例は以下のようになります。
try {
conn = DbConnectionPool.getInstance().getConnection();
// DB処理
} catch (SQLException e) {
throw new SystemException(Logger.ERROR, "UserDAO#selectUser", userId, e.getMessage());
}
このように、例外の補足・ラップ・再送出までを共通クラスで一元化することで、開発者はエラーメッセージの構築やログ出力方法に悩む必要がなくなります。
なお、SystemExceptionクラス自体はLoggerクラスを内部的に利用しており、エラー発生時にはそのままログ出力まで自動で行われる設計となっています。
ログ出力処理(Logger)との連携は次回で解説予定
共通DBアクセスクラスのすべての操作には、内部的に**Loggerクラスによるログ出力処理**が組み込まれています。
これにより、DB操作の開始・終了・エラーなどのタイミングが全てログファイルに自動記録され、障害発生時のトラブルシュートを大幅に簡素化することができます。
ログ出力は、次のようなシグネチャで行われます。
Logger.out(Logger.INFO, "DbAccessSelect#execute", userId, "SELECT処理を開始します。");
このログ出力には、次のようなルールが徹底されています。
| 構成要素 | 説明 |
|---|---|
| ログレベル | INFO / ERROR / DEBUG などを指定可能 |
| 呼び出し元 | クラス名#メソッド名の形式で記録 |
| ユーザーID | 誰が実行した処理かを明記 |
| メッセージ | 実際に何が行われたのかを記録 |
このように、SystemExceptionとLoggerの連携により、例外処理と障害通知がシームレスに行われる仕組みとなっています。
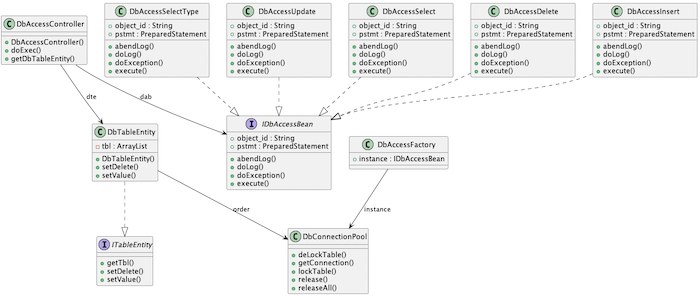
この共通DBアクセスクラスは、SELECT / INSERT / UPDATE / DELETE をそれぞれ個別のクラスに分離し、処理の責務を明確にしたシンプル構造で構成されています。
SQLをJavaコードに直接埋め込まず、DataBeanとFactoryクラスで動的に操作を切り替える設計のため、業務ロジックとSQL処理の分離、テスト性、再利用性に優れた作りとなっています。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
次の第4回では、開発効率と保守性を高めるために不可欠な「ログ出力」と「例外処理」の共通化について解説します。処理ごとにバラバラだったログ記述やエラー対応を統一的に管理し、実運用に強いアプリケーションを支える設計手法を紹介します。現場で役立つ実践的な運用ノウハウを知りたい方は、ぜひご覧ください。
▶︎ORMにはうんざり!第4回:ログ出力と例外処理の共通化でJava開発効率を上げる


