

ORMや巨大なDBアクセスクラスに、正直うんざりしていませんか?
カラムを1つ追加するだけで、エンティティ、DTO、マッピング、設定ファイル……と何か所も修正が必要になる今のDBアクセス構造に限界を感じている人も多いはずです。
「もっと簡単に、それでいて本番でも使えるDBアクセスクラスは作れないのか?」という疑問から、今回、設定不要・高汎用性・保守性重視のシンプルなクラス構造を実装しました。
エンジニアとして複数の現場でORMを使ってきましたが、「設定の複雑さ」「動作の見えづらさ」に対する違和感はずっと抱えていました。特に自作の社内ツールや小〜中規模の業務システムでは、そこまで高度な抽象化は不要で、むしろ原理が見えて保守しやすい構造が望まれると感じていました。
この共通DBアクセスクラスを作った理由は、部下の研修の負担を減らすためでもあります。Javaの基本文法や構造に集中してもらいたくて、トランザクション処理やロールバックなどのデータベース固有の説明に、毎回数週間も費やすのが精神的に厳しかったのです。
そこで「DBアクセス部分はこう使えば良い」と提示できる仕組みを用意して、学習や開発のコストを最小化しました。
このシリーズでは、そうして作成した共通DBアクセスクラスの構造と意図、使い方を段階的に解説していきます。
なお、大規模案件を見据えた抽象設計ではありませんが、実運用で必要なポイントには対応しています。
この記事では、ORMを使わずにJavaだけで柔軟なDBアクセスを実現する方法と、具体的な実装例を紹介します。
本シリーズで使用する共通DBアクセスクラスの検証には、PostgreSQLを想定しています。ソースコード一式はGitHubに保管しており、テーブル構成やクラス構造を含めてすべて確認可能です。再現性のある実装環境を前提として設計されています。
👉 GitHubリポジトリ: https://github.com/bepro-engineer/db-access-core
DBアクセス処理を簡単にしたい理由
毎回、DBアクセスの実装を始めるたびに思っていました。
「たった1カラム追加するだけで、なんでこんなに面倒なんだ?」と。 エンティティクラス、マッピング定義、DTO、SQL、場合によっては変換用のユーティリティまで…。
一つ追加するたびに、関係するファイルをいくつも開いて手を加えないと動かない。 馬鹿馬鹿しいと思ったことはありませんか?
本当に必要なのは「柔軟な拡張性」や「自動マッピング」ではなく、 「いまこのテーブルに対してSQLを1発投げて結果を取りたい」だけのときだってあるはずです。
毎回ORMを導入して、設定と定義で半日消える作業に、疲れてしまった方も多いのではないでしょうか。
ORMで毎回つまずくポイント
アノテーションの書き方を忘れて、ググる。XMLファイルにマッピング書いたつもりが、微妙に型が合わなくて実行時エラー。 構文的にはOKでも、なぜか詰まる。そういう経験、何度もしてきました。
JPAでもMyBatisでも、機能としては優れているのですが、それ以前に“正しく書けないとまともに動かない”という障壁があります。それが、時間のない案件や、とにかく早く動かしたいときの足かせになります。
しかも、ブラックボックスになりがちです。 裏側で何をしているのか把握できないまま、動いたり動かなかったりする。
結局、SQLを素で書いたほうが早いと思ったことは一度や二度ではありません。
カラム追加で何ファイルも修正する現実
DBのテーブルにカラムを1つ追加しただけで、なぜ5ファイルも修正しなければならないのでしょうか。エンティティ、DTO、マッピングファイル、Serviceの処理、テストデータ…。 忘れてはいけない場所が増えるほど、ミスも増えます。
この流れに毎回付き合うのが、本当に嫌になりました。だからこそ、もっとシンプルで、見ればすぐに理解できて、使い回しもしやすい仕組みが欲しかったのです。
今回の構成では、明示的にSQLを書く方針にして、必要な情報の受け渡しにはMapやシンプルなエンティティクラスを使うことで、柔軟性と省力化を両立できるように設計しています。
いちいち定義を増やさずに、テーブル構造の変更にも耐えられる構成を目指しました。
シンプルな仕組みで十分なケースもある
すべての案件で巨大なフレームワークが必要なわけではありません。
「要件は簡単」「使うテーブルも少ない」「納期は明日」。 そんな現場では、わざわざORMを導入して構築するよりも、素直に自前のDBアクセスクラスを書いた方が早くて正確です。もちろん、設計の自由度や移植性を考えるならORMも有効です。
しかし、そこまでの設計が求められていない場面では、過剰な構成は“やりすぎ”になります。
動けばいい、ではなく、すぐに動いて、あとから読んでもわかる構造。これを意識して、必要最小限の部品とシンプルな書き方でまとめました。
今回作ったDBアクセスクラスの要件
ここでは、今回自作したDBアクセスクラスがどういう使い方を想定していて、どこに向けた設計なのか、あえて何を省略しているのか、そして何を残しているのかを明確にしておきます。
すべてのフレームワークを否定するわけではありません。 ただし、限られたリソース・納期・工数の中で、余計な調整や学習コストを抑えたい状況は確実に存在します。
このクラスは、そういった場面で**「とりあえず接続して実行して結果返す」ことに集中するための最小構成**として設計しています。
想定する使い方と対象プロジェクト
今回のクラスは、企業システムのような巨大な構造を意識したものではありません。
主目的
- 社内ツール
- バッチ処理
- 中間DB操作
- 管理画面
簡単なSQLの投入と結果の取得が主目的の軽量アプリケーションに向けています。
特に、JDBCレベルでの制御が必要な現場や、「とりあえずMySQLで動けばOK」というような環境において、構成を最小限に保ちつつ本番レベルに近い安定性を確保することを重視しています。
また、Javaがメイン言語であり、SpringBootなどのDIやBean定義に慣れていないエンジニアでも、すぐに使える構成になっています。
省略したかった処理や仕組み
省略した処理や仕組みについても、あえて明確にしておきます。このクラスは“なんでもできる”ことを目的にしていません。
「それ、今回いらないよね?」と割り切れる要素を極力そぎ落とすことで、手間と複雑さを避けた構成にしています。
以下は今回、意図的に削った代表的な機能と、その代替の考え方です。あなたの環境に必要かどうかを判断する参考にしてみてください。
| 省略した機能 | 理由と代替方針 |
|---|---|
| トランザクション制御 | 明示的にConnectionを管理すれば代替可能と判断 |
| マッピング(DTO, Mapper) | MapとEntityで直接扱う構成にしたため不要 |
| ログ出力 | 呼び出し元で制御できるように排除(共通クラスで対応可) |
| 例外の統一処理 | プロジェクトごとにハンドリング方針が異なるため除外 |
| アノテーションベースの定義 | シンプルな処理にアノテーションは過剰と判断 |
まず、トランザクション制御のような「抽象化された仕組み」はすべて排除。 必要であれば呼び出し元でConnectionを明示的に管理すれば済む話ですし、それすら不要なケースの方が多いと感じたからです。
また、MapperクラスやDTO変換ロジックもありません。そもそも、Mapや汎用エンティティで受け取れば、データ構造の大半は用が足りるという判断です。 マッピングの整合性や命名の一貫性よりも、即時性と簡便さを優先しました。
さらに、ログや例外処理の統一もこのクラスでは行っていません。それぞれのプロジェクト方針に委ねる形で、最小限のtry-catchと、呼び出し側に任せる柔軟性を確保しています。
最小限で満たしたかったポイント
何を重視したのかというと、以下の3点です。
重視した項目
- Factoryパターンでの統一的なアクセス
- 明示的SQL指定と戻り値のMap/Entity統一
- コネクションプールの再利用による実用性
この3つさえ押さえておけば、「最小限でも本番利用に耐える」構成になると判断しました。
とくにFactoryを使ったのは、SQL種別ごとの呼び出しを明確に分離できるからです。insert・update・delete・selectなどの処理クラスを統一的に生成することで、コード上の迷いがなくなります。
さらに、戻り値の構造をMapと汎用Entityに限定することで、動的な構造にも固定的な構造にも対応できるようにしました。1行だけ返したいとき、複数行をListで返したいとき、どちらでも対応できるように調整しています。
このDBアクセスクラスは、特定の業務要件に縛られず、幅広い開発現場で“今すぐ使えること”を目指して構成しました。
機能を絞った分、必要な仕様は最初にしっかり明示しておく必要があります。
以下に、本クラスが満たす基本仕様と想定している利用シーンをまとめました。「どんな環境で使えるのか?」という視点でご確認ください。
| 項目 | 内容 |
|---|---|
| 使用言語 | Java(JDK 8 以上) |
| DB対応 | MySQL(JDBC準拠) |
| 構成方針 | Factoryパターンによるクラス分離 |
| 接続方式 | JDBC + コネクションプール |
| 戻り値形式 | Map または 独自Entity(DbTableEntity) |
| ログ機能 | なし(別クラスで制御) |
| 例外処理 | 基本的に呼び出し側で処理 |
| 導入対象 | 小規模・短納期・バッチ・社内ツールなど |
設計ポリシーとクラス構造の意図
ここでは、このDBアクセスクラスがどういう考えで設計され、なぜこの構成になっているのかを整理して紹介します。
目指したのは「使い捨てで終わらない軽量な基盤」です。単発の開発でも、毎回ゼロから書き直すのではなく、使い回せて修正もしやすいことを最優先にしました。
そのために取った設計ポリシーや、あえて入れなかった要素など、判断の根拠を明示します。
依存関係を減らすための方針
クラス設計の初期段階で一番に考えたのが「外部に依存しない」ことでした。 ライブラリを増やせば一時的には便利になりますが、バージョン不整合や保守対象が増えるだけの結果になりがちです。
そのため、本クラスではJDK標準ライブラリとJDBC以外の外部依存は完全に排除しています。フレームワークに強く依存する設計を続けていると、「フレームワークの都合で仕様が決まる」という本末転倒な状況になりやすくなります。
今回の設計では、JDBCレベルの明確なAPIのみで構成し、どのJavaプロジェクトにでも差し込める形を目指しました。
Factoryパターンの採用理由
DBアクセス系の処理では、「select用の処理クラス」「insert用の処理クラス」など、ロジックの内容に応じて呼び出す処理が異なります。この分岐を呼び出し元で毎回書くのは明らかに冗長であり、保守性も下がります。
そこで、処理ごとの具象クラスをFactoryで生成することで、呼び出し側は型や構造を意識せず、必要な操作を最小限のコードで呼び出すだけの形にしました。
また、Factoryパターンを使うことで、将来的に別のDBや別の処理方針に対応したクラスを追加するのも容易になります。すでにinsert・update・delete・selectに加え、selectType(型指定付き)も用意しています。
データ受け渡しの柔軟性と制約
戻り値や引数の型についても、最小限の制約で柔軟に扱えるよう配慮しています。 ただし、無制限な構造にすると今度は整合性が取れなくなるため、2つのアプローチに絞り込みました。
Mapベースによる柔軟な構造
最も柔軟なのがMap形式による受け渡しです。 selectの戻り値を List<map<string, string="">>で返せば、列数や構造を問わずにデータを扱うことができます。
たとえば、1行だけ取りたい場合はListの先頭を取ればいいですし、画面表示用の汎用ループ処理でも使い勝手は良好です。Mapベースは柔軟性に優れ、画面出力や動的なカラム処理などにも対応しやすい構造です。
決まった型が不要な用途では特に威力を発揮し、小規模や変化の多い業務処理にも適しています。
DbTableEntityによる制限付き汎用性
一方で、汎用Entityである DbTableEntity クラスを使えば、Map よりも型的な扱いがしやすくなります。
このEntityは中身をキー・バリューで保持しますが、インスタンス化して使うことで「1行のデータ」という明確な意味を与えることができます。
たとえば getString("user_name") のように、意図的にカラム名を指定して取り出すことで、読みやすさと意図の明示を両立できます。開発規模や現場のスタイルに応じて、Map と Entity のどちらでも選べるようにしている点が、このクラスの柔軟性の肝になります。
ただし、あくまでこの DbTableEntity は「1行=1オブジェクト」という用途に特化しており、明確にカラム数・データの列構造が分かっている場面での利用が前提です。
テーブルの構造が動的すぎるケースでは Map のほうが適していることもあり、“単純すぎず、複雑すぎない” レイヤーを狙って設計されています。
クラス構成と処理の流れ
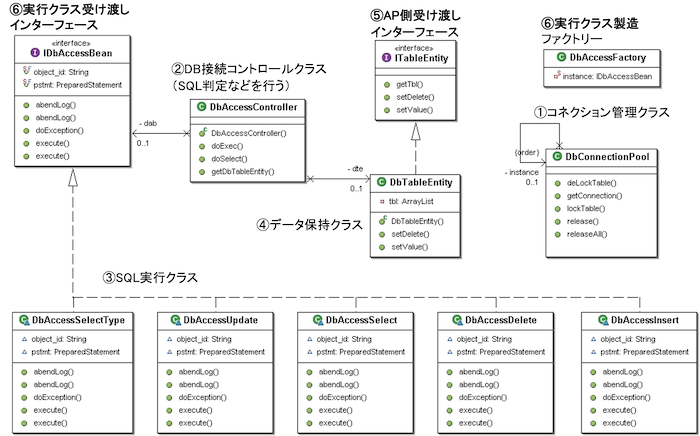
このセクションでは、今回作成したDBアクセスクラスの全体構成と、その中での処理の流れを具体的に説明します。
煩雑な設定や冗長な手続きは極力排除し、「必要なものだけを使い切る」ことにこだわった設計です。
各クラスの役割は明確に分け、責務ごとに独立した構成にすることで、再利用や保守のしやすさを担保しています。
前提となる実行環境
共通DBアクセスクラスを使用するためには、JavaおよびJDBC接続を前提とした開発環境が必要です。大規模なフレームワークには依存せず、最小限のライブラリで動作することを意識しています。ここでは、使用を想定しているJavaバージョンやDB接続仕様、パッケージ構成に触れておきます。
ソースコードの配置場所について
本クラス群は、業務ロジックと明確に分離できるよう、パッケージ構成を意識して作成されています。
以下に、すべてのクラスファイルを含めた配置構成を記載します。
ec
└── common
├── DataBean.java
├── IniFileRead.java
├── ITableEntity.java
├── package-info.java
├── SystemInfo.java
├── exception
│ └── SystemException.java
├── log
│ ├── Logger.java
│ └── LogWriter.java
└── data
├── DbAccessController.java
├── DbAccessDelete.java
├── DbAccessFactory.java
├── DbAccessInsert.java
├── DbAccessSelect.java
├── DbAccessSelectType.java
├── DbAccessUpdate.java
├── DbConnectionPool.java
├── DbTableEntity.java
└── IDbAccessBean.java
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
各処理クラスの役割と責務分離
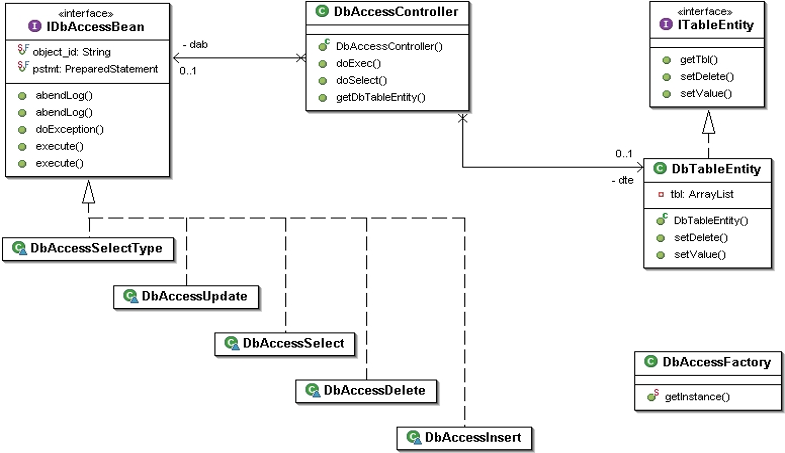
最初に、このDBアクセスクラスを構成する各クラスの役割について整理します。
すべての処理は1つの大きなクラスに詰め込むのではなく、処理種別ごとにクラスを分離し、それぞれが明確な責任を持つように設計しています。
たとえば、データの追加・更新・削除・取得といった処理は、以下のようにそれぞれの専用クラスに分けて実装しています。
| 分類 | クラス名 | 主な役割 |
|---|---|---|
| 共通DB | DbAccessInsert | INSERT処理のSQLを組み立てて実行します。フィールドと値のマッピングも担当します。 |
| DbAccessUpdate | UPDATE処理のSQLを組み立てて実行します。条件指定や更新対象の判定も含みます。 | |
| DbAccessDelete | DELETE処理のSQLを組み立てて実行します。主に主キーや条件句を元に削除します。 | |
| DbAccessSelect | SELECT文を構築し、結果をMap形式で返却します。柔軟性重視の汎用取得処理です。 | |
| DbAccessSelectType | 型を指定してSELECT結果を取得する特殊処理クラスです。Enum等に応じた処理に適します。 | |
| DbAccessController | 呼び出し元からの要求に応じて、各DB処理クラスを統括・実行する中核クラスです。 | |
| DbAccessFactory | 要求された処理種別(SELECT/INSERTなど)に応じて、適切なDB処理クラスを生成します。 | |
| DbConnectionPool | JDBCによるDB接続を管理します。再接続や接続保持のロジックも含まれます。 | |
| DbTableEntity | 1レコード分のデータ構造を表すEntityクラスで、テーブルと1対1で対応します。 | |
| 補助 共通 | IDbAccessBean | DBアクセスに必要なパラメータ(SQL種別、テーブル名、値マップなど)をまとめるインタフェースです。 |
| DataBean | データ処理に使う汎用的なBeanクラスです。キーと値のMap操作を簡潔にします。 | |
| IniFileRead | ini形式の設定ファイルから接続先情報やパスを読み込むユーティリティです。 | |
| ITableEntity | DbTableEntityのインタフェース定義です。汎用的なエンティティ操作を可能にします。 | |
| SystemException | アプリケーション内で発生する独自例外を一元的に管理する基底クラスです。 | |
| SystemInfo | 環境・サーバー・ユーザー情報などを保持する補助クラスです。 | |
| Logger | ログ出力処理のメインクラスで、ログ種別(INFO、ERRORなど)に応じた処理を行います。 | |
| LogWriter | Loggerから呼び出され、ログファイルへの出力処理を実行する下位クラスです。 | |
| Constants | 定数管理クラスです。全体で共通的に使われる定義値(環境、設定値など)を集中管理します。 | |
| FieldsConstants | DBフィールド名に関する定数定義を集約したクラスで、ハードコーディングを防ぎます。 | |
| SqlConstants | 頻出SQLの一部(SELECT句やORDER句など)を定数化したクラスで、可読性と再利用性を高めます。 |
このように、機能ごとにクラスを分割することで、1つの機能を修正しても他への影響を最小限に抑えることができます。 また、それぞれのクラスは独立してテストしやすく、システム全体の安定性向上にもつながります。
DbAccessController
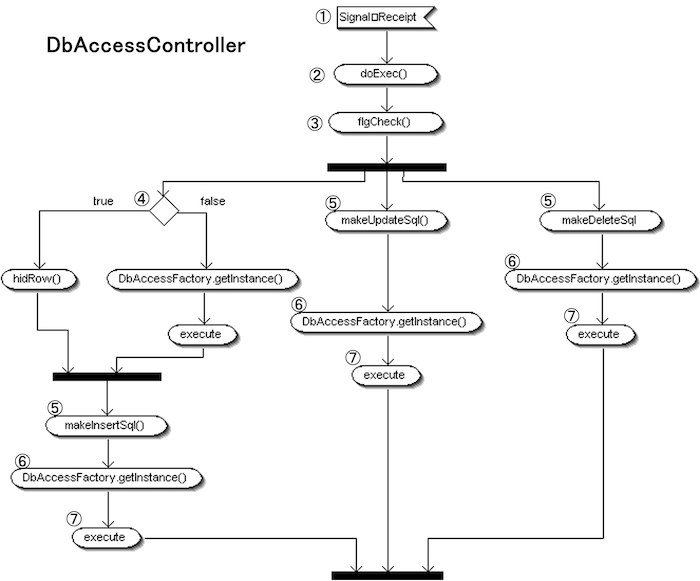
- DbAccessCtl(APP) 側より、要求信号を受信
処理のエントリポイントとなる信号を受け取り、以降の制御処理が開始されます。 - doExec() メソッドをコール
クラス外部から呼び出され、処理の起点となる公開APIです。 - flgCheck() による処理種別の判定
エンティティの内部状態をもとに、「登録」「更新」「削除」のどの処理を行うかを判定します。 - 登録判定時のSELECTチェック
登録処理では、まず該当データの有無を確認する必要があります。
・セレクトフラグ false → SELECT構文を実行
・セレクトフラグ true → hidRow() を実行し object_id を除去 - SQL構文の自動生成
判定結果に応じて、INSERT / UPDATE / DELETE の各SQL構文を動的に生成します。 - DbAccessFactory を用いた処理クラス呼び出し
Factoryパターンにより、対応する処理クラスを取得し、SQLを実行します。 - 実行後、件数チェックとエラーハンドリング
処理結果に応じて、更新0件などの異常時はエラーハンドリングが行われます。
DbAccessInsert
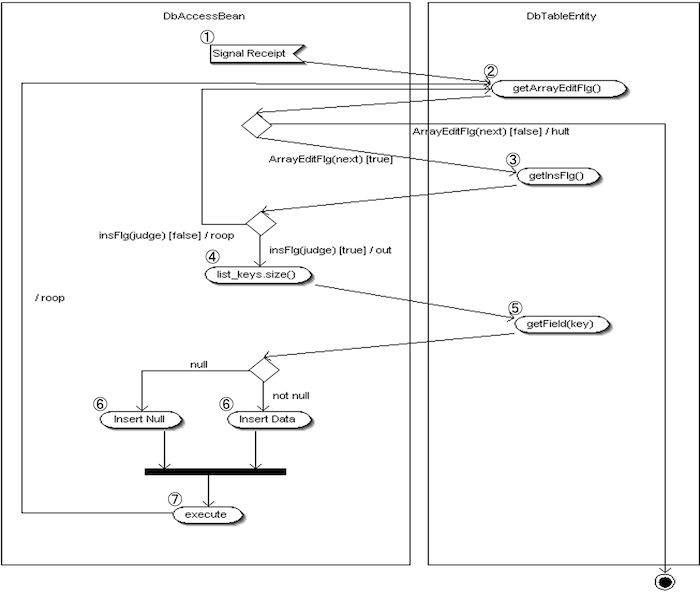
- SQL実行要求を受け取る
DbAccessController から INSERT処理の実行指示が届き、DbAccessBean の処理が開始されます。 - 変更フラグ配列(ArrayEditFlg)を取得しループ処理
配列の各要素に対して順次処理を行います。次要素が存在すれば③へ進み、存在しなければ処理を終了します。
※この処理は DbAccessBean 内で完結します。 - 登録フラグ(InsFlg)の判定
該当インデックスの InsFlg を確認し、
・ true であれば登録処理へ進みます。
・ false であれば再度ループ②へ戻ります。 - キー一覧(list_keys)を取得してループ処理
登録対象のすべての項目キーについて、順次処理を行います。 - 各キーをもとに値を取得
該当キーのデータを getField() で取得します。
・取得時に NullPointerException が発生した場合は空文字に変換します。 - 値をセット
・⑤で空文字になったデータは NULL として登録します。
・それ以外はそのままの値をセットします。 - 値をDBへ登録
INSERT処理を実行します。次の変更対象が存在すれば ② に戻り、存在しなければ終了します。
SystemException の可能性がある事象:- 一意制約違反(例: プライマリキー重複)
- NOT NULL制約違反(必須項目の欠落)
DbAccessUpdate
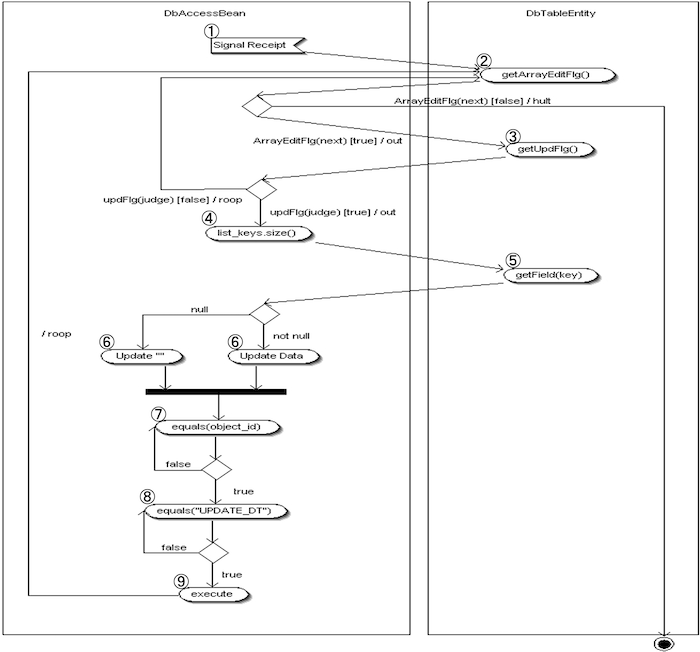
- SQL実行要求を受け取る
DbTableController から更新処理の指示が届き、DbAccessBean の処理が開始されます。 - 変更フラグ配列(ArrayEditFlg)を取得しループ処理
各変更対象データに対して、順次処理を実行します。
・次件数が存在すれば ③ へ進みます。
・存在しなければ処理を終了します。 - 更新フラグ(UpdFlg)の判定
該当インデックスの UpdFlg を確認します。
・ true なら更新処理へ進みます。
・ false なら再度ループ(②)に戻ります。 - 項目キー配列を取得し、ループ処理
更新対象の全項目キーに対して、順次処理を行います。 - 各キーをもとに値を取得
該当キーのデータを getField() で取得します。
・取得時に NullPointerException が発生した場合は空文字に変換します。 - 値をセット
・⑤で空文字になったデータは NULL として登録します。
・それ以外はそのままの値をセットします。 - Object_ID の確認
Object_ID フィールドが対象であれば後続の判定へ進みます。
それ以外のフィールドならばループ処理に戻ります。 - 排他チェック
データ取得時点の UPDATE_DT(更新日時)と現在の UPDATE_DT を比較します。
・一致すれば次に進みます。
・不一致の場合は排他エラーとして SystemException を発生させます。 - 更新実行
DBに対して UPDATE 処理を実行します。
SystemException の対象となるエラー:- 一意制約違反
- NOT NULL 制約違反
- 更新件数0件(更新対象が見つからなかった)
DbAccessDelete
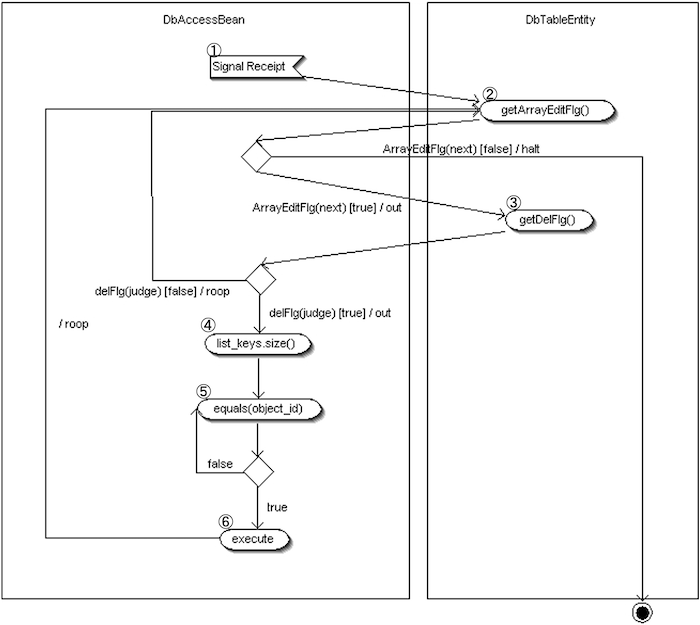
- SQL実行要求の受信
DbAccessController より削除処理の要求を受信し、`DbAccessBean` 内の処理が開始されます。 - 変更フラグ配列(ArrayEditFlg)の取得とループ処理
各データの編集対象かどうかを判定しながら、インデックスごとに順次処理を行います。
・次のデータが存在すれば ③ へ進みます。
・存在しなければ処理を終了します。 - 削除フラグ配列(DelFlg)の確認
該当インデックスの削除対象かどうかを判定します。
・ true なら削除処理へ進みます。
・ false ならループ(②)に戻ります。 - 項目キー配列の取得とループ
削除対象のデータに関連する全項目キーを取得し、1つずつ処理を進めます。 - Object_ID 判定
④で取得した各キーに対して、Object_ID かどうかを判定します。
・Object_ID であれば ⑥ へ進みます。
・Object_ID でなければ再度ループを続行します。 - 削除処理の実行
判定された Object_ID の値をパラメータにセットし、該当レコードを削除します。
SystemException の対象となる削除エラー:- 削除件数 0 件(対象が見つからなかった場合)
・次件数が無ければ処理は終了します。
DbAccessSelect
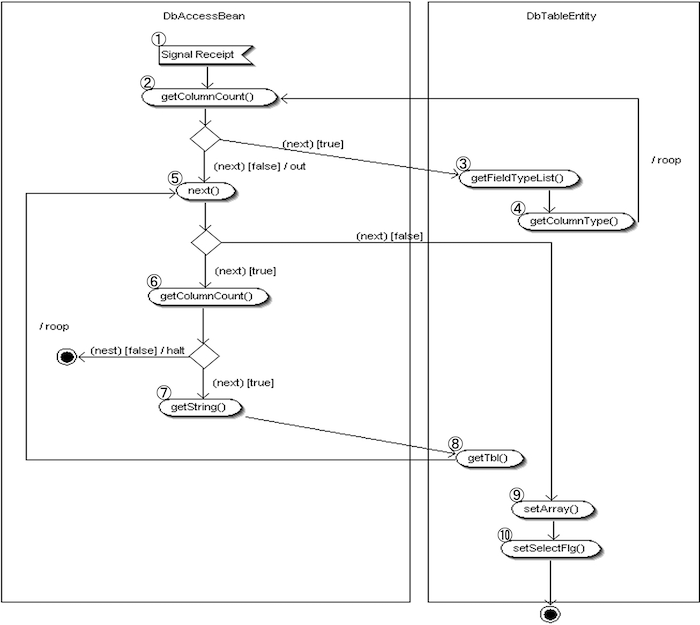
- SQL実行要求の受信
DbAccessController から SQL 実行の要求信号を受信し、処理が開始されます。 - メタデータから列数取得
ResultSetMetaData からデータベースの列情報(カラム数)を取得し、型の取得ループに入ります。
・項目があればループを継続します(③へ)。
・無ければ⑤へ進みます。 - DbTableEntityからデータ型配列を取得
現在のインデックスに対応するデータ型格納先配列を取得します。 - カラムの型情報を取得し配列に格納
ResultSetMetaData から取得したデータ型を、DbTableEntity 側の配列に格納します。
・次の項目が存在する限り、②に戻ってループ処理を続行します。 - 検索結果セットを取得
SQL結果セット(ResultSet)から実データを取得するループに入ります。
・行データが存在すれば⑥へ進みます。
・無ければ⑨へジャンプします。 - 再びカラム数を取得して値の抽出ループへ
取得したレコードの列情報をもとに、各項目値を1つずつ取得していきます。
・次の項目があれば⑦へ進みます。
・無ければ SystemException をスローします。 - データ値の取得
現在のカラムの値を取得します。 - 取得した値をDbTableEntityに格納
取得した各データをDbTableEntity内の値格納配列にセットします。
・次のレコードが存在する限り、⑤へ戻ってループを継続します。 - データ格納配列をDbTableEntityに統合
上記⑧で集めた全データ行をまとめ、DbTableEntityのテーブル構造格納配列にセットします。 - 検索済みフラグのセット
このテーブルは検索処理済みであることを示すため、`setSelectFlg()` を実行してフラグを立てます(Insert処理時に型取得元として使用されるため)。
今回紹介したDBアクセスクラスでは、ログ出力処理を外部クラスに委譲しています。ログ出力には、以下の記事で解説している「共通ログ出力クラス」を利用しています。併せてご確認いただくことで、より理解が深まります。
【Javaの基礎知識】設定地獄はもう嫌!シンプルな共通ログ出力クラスを作ってみた

接続管理と再利用の設計
DB接続の管理には、`DbConnectionPool`という専用クラスを用いています。
このクラスは、JDBCを用いた接続取得の統一管理を行い、必要に応じて使いまわせる形で実装しています。
従来のように毎回接続を開くのではなく、1回の起動時に接続情報を取得して再利用することで、パフォーマンス低下を防ぎつつ、コードの記述も簡潔にできます。
Connection conn = DbConnectionPool.getConnection();
このように、接続は共通の静的メソッドを通じて取得します。 トランザクション制御や接続の明示的なクローズ処理も、処理クラスの中で完結しており、呼び出し側では特に意識せずとも動作するようになっています。
また、設定値(JDBC URLやユーザーID、パスワード)はpropertiesファイルなどに逃すのではなく、最小限の記述でハードコーディングされており、システム構成の柔軟さよりも「今すぐ使えること」を優先した設計です。
呼び出しコードの簡素さと一貫性
このDBアクセスクラスのもう一つの特徴は、呼び出しコードの一貫性です。
通常、INSERT、UPDATE、SELECT、DELETEなどで、それぞれ異なるメソッドを呼び出す必要があり、引数の形式や戻り値もバラバラになることが多くあります。
しかし本構成では、すべての処理がDbAccessController経由で統一されており、呼び出し方は非常にシンプルです。
たとえば、SELECT処理は以下のようになります。
DbAccessController controller = new DbAccessController();
Map<String, String> where = new HashMap<>();
where.put("status", "active");
List<Map<String, String>> result = controller.select("user_table", where);
INSERTやUPDATEでも同様の形式で記述できるため、開発者は個別のクラス名やSQL構造を意識せずに、業務処理のロジックに集中できます。
また、結果の受け取り形式はすべてMapまたはEntity(DbTableEntity)で統一されており、整合性の取れた設計となっています。
特に、型に縛られないMap形式は、動的なカラムの取り扱いや、固定設計されていない業務システムとの相性も良好です。
こうした仕組みによって、呼び出し側のコードが非常に読みやすく、メンテナンス時のストレスも軽減されています。
ソースコード全体の動作確認
このセクションでは、今回作成したDBアクセスクラス一式を使用して、実際にどのように動作するのかを検証します。
構成ファイルや外部フレームワークを必要とせず、Java単体で簡潔に実行できるため、確認作業も非常にスムーズです。
開発環境はEclipse、またはIntelliJ IDEAなどの標準的なJava IDEで問題ありません。検証対象はMySQLに接続し、データを挿入、更新、取得する一連の流れとなります。
共通DBアクセスクラスのサンプルコード
本記事で紹介した共通DBアクセスクラスの全ソースコードは、下記のGitHubリポジトリにて公開しています。記事内ではコードの一部しか掲載していませんが、GitHubでは各クラスの実装詳細やサンプルSQL、簡単な実行手順まで含めています。
読者自身のプロジェクトへ組み込みたい場合や、自前でカスタマイズしたい場合などに活用してください。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
実行例と出力結果の確認
以下に、典型的な実行コードの例を示します。 ユーザー情報を持つテーブルにデータを登録し、その後SELECTで取得してコンソールに出力する流れです。
DbAccessController controller = new DbAccessController();
Map<String, String> data = new HashMap<>();
data.put("user_id", "test001");
data.put("user_name", "山田太郎");
data.put("status", "active");
controller.insert("user_table", data);
Map<String, String> where = new HashMap<>();
where.put("user_id", "test001");
List<Map<String, String>> result = controller.select("user_table", where);
for (Map<String, String> row : result) {
System.out.println(row);
}
出力結果は以下のようになります。
{user_id=test001, user_name=山田太郎, status=active}
このように、SQL文を意識することなく、Map形式でデータを扱うことができるのが大きな特徴です。
また、INSERTやSELECT、UPDATEなどは基本的に同じパターンで呼び出せるため、構文の記憶や書き換えの負担も軽減されます。
よくあるエラーとその対処法
実行環境や初期設定によっては、いくつかのエラーに遭遇する場合があります。 ここでは、実際に発生しやすいエラーとその回避策を整理します。
| エラー内容 | 原因 | 対処方法 |
|---|---|---|
| java.sql.SQLException: No suitable driver | JDBCドライバがクラスパスに含まれていない | mysql-connector-java.jar をプロジェクトに追加してください |
| java.sql.SQLSyntaxErrorException | SQL構文エラー。カラム名のミスや予約語の誤使用 | カラム名やテーブル名の誤字を確認してください |
| NullPointerException | 接続オブジェクトが null のまま使用された | DbConnectionPool で取得できているか事前に確認してください |
| java.lang.ClassNotFoundException | JDBCドライバクラスが見つからない | DriverManager.registerDriver の処理漏れを確認してください |
実行エラーの大半は、環境構築や初期設定の不足に起因します。
特にMySQLドライバの追加忘れや、プロパティファイルの書き間違いは初心者がつまずきやすいポイントです。
今回の設計では極力プロパティファイルを使わず、定数やクラス内定義で完結するようにしてありますが、JDBCドライバの追加だけは必須です。 また、トラブルシューティングの際には、ログを適切に出力できるようにしておくと原因の特定がしやすくなります。
ログ出力処理はこのクラスとは独立して実装する想定となっており、任意でlogger.shrcなどのシェルベースや外部ログクラスと連携して運用できます。
今後の拡張方針と制限事項
このセクションでは、今回作成したDBアクセスクラスの今後の拡張の可能性と、あえて搭載していない仕様、つまり意図的に制限している内容について整理します。
目的は「小規模プロジェクト」「一人開発」「メンテ性の高さ」にあります。複雑化を防ぐために、何を搭載していないのか、どこまでなら対応できるのかをはっきりさせておくことが重要です。
トランザクション制御の対応可能性
トランザクション処理については、現段階では明示的な管理は行っていません。
つまり、autoCommitが有効な状態で、各SQL処理は単独で即時反映される設計です。
一方で、今後のニーズとして「複数テーブルにまたがる操作」「更新→確認→確定の一連処理」などが求められる場合に備え、以下のような拡張が可能です。
Connection conn = DbConnectionPool.getConnection();
conn.setAutoCommit(false);
try {
// 複数操作を記述
DbAccessUpdate.exec(conn, ...);
DbAccessInsert.exec(conn, ...);
conn.commit();
} catch (Exception e) {
conn.rollback();
} finally {
conn.close();
}
このように、接続オブジェクトを呼び出し元で明示的に操作することで、現在の仕組みでもトランザクション対応は可能です。 将来的に、DbAccessController側でトランザクション制御メソッドを拡張することも想定していますが、あくまで「求められたときに拡張する」方針です。
SQLバリエーションへの対応方針
現在の設計は、標準的な`INSERT`、`SELECT`、`UPDATE`、`DELETE`の4操作に限定しています。 JOIN句やIN句、サブクエリなど、SQLの高度な構文はあえて非対応にしています。理由は以下の通りです。
- WHERE条件が複雑になるとMapでは表現しにくくなる
- JOIN対応を入れるとテーブル設計との依存性が高まる
- 汎用性を高めると一気に複雑化し、書く量が増える
た本クラス群には、任意のSQL文を直接発行できる汎用メソッドも含まれており、JOINやサブクエリなどにも対応可能です。
String sql = "SELECT u.name, r.role_name FROM users u JOIN roles r ON u.role_id = r.id WHERE r.active = ?";
List<Object> params = Arrays.asList("1");
List<Map<String, String>> result = db_access.execute(sql, params);
このような形であれば、あくまで例外的に生SQLを許容する設計にできます。 自動化の範囲を割り切って運用することが、このクラスの思想でもあります。
シンプルさを維持するための指針
シンプルな設計を保つことを前提に、次のような方針を明確に設定しています。
| 対象項目 | 方針 |
|---|---|
| ログ出力 | Loggerクラスなど別モジュールで制御 |
| SQL構文チェック | 自動解析などは行わず、SQL文の責任は呼び出し側 |
| 型変換 | 基本はString型で統一。必要に応じて呼び出し側でキャスト |
| バリデーション | サーバーサイドではなく、入力前処理で実施する設計 |
| SQLファイル | 外部ファイルの読み込みは非対応。コード内に記述 |
このように、「便利にしすぎない」ことをあえて制約とすることで、迷いのない設計と運用が可能になります。 フレームワークやORMでありがちな、「拡張性のための冗長性」に対する反発が、このクラス設計の原点です。
本クラスは、たとえば社内業務ツールや一人で運用するバッチ処理、小規模なWeb APIの裏側などに最適です。
何もかも自動化してくれる巨大なライブラリより、必要な処理だけを的確にこなす小さな仕組みのほうが合っている場面は、まだまだ多く存在します。
まとめ
ここまで、既存のORMに頼らず、自分たちでシンプルなDBアクセスクラスを設計・実装した背景や狙いについて紹介してきました。
この記事の目的は、フレームワークに背を向けることでも、全てを手動に戻すことでもありません。 必要最小限の実装で、現場のニーズに即した「ちょうどいい」構成を提案することにあります。
最後に、今回のアプローチの意義と、読者に伝えたい実務的な視点を整理して締めくくります。
この共通DBアクセスクラスは、小規模〜中規模の社内システムを主な対象として設計されています。SpringやMyBatisのような汎用的なORMフレームワークとは異なり、プロジェクトごとの要件に柔軟に対応しつつ、極力シンプルで保守しやすい構造を意図しています。
再発明ではなく最適化の提案
今回のような仕組みは、どこかで見たことのあるような「再発明」に見えるかもしれません。 実際、DAOパターンや、軽量なJDBCユーティリティはすでに多く存在します。
しかしそれでも自分で作る意義があるとすれば、それは「どの機能が必要で、どこまで省略できるか」を自分で線引きできることに尽きます。
どんなに有名なフレームワークでも、「それが自分たちの開発環境に合っているか?」という視点が抜け落ちていれば、結局のところ宝の持ち腐れになります。
フルスタックなライブラリで大規模なWebアプリを構築するのであれば、もちろんHibernateやSpring Data JPAは選択肢になり得ます。
しかし、一人で1ヶ月以内に構築する業務バッチ、顧客向けの社内API、または3ヶ月でフェードアウトするプロトタイプに対して、毎回同じような重厚な設計が本当に必要でしょうか。
今回のようなクラス構成を持ち込むことで、無駄に悩む時間、記述の冗長さ、設定ファイルの肥大化といった負担を大幅に削減できます。 それは「再発明」ではなく、「必要なものだけに集中する」という現実的な最適化です。
むしろ、現代のフルスタック化された開発環境に対して、シンプルなコードベースを取り戻すという意味で、逆に今求められている考え方かもしれません。
現場のストレスを減らすという目的
現場でよく聞くのは、「設定が多すぎて挙動が読めない」「アノテーションが多くて何をしているのかわからない」「一行直すために五箇所触る」など、開発者の心理的な負担に直結する不満です。
とくに、短納期や限られた人員で開発を行う現場では、「正しい設計」よりも「楽に回る仕組み」のほうが重視されることがあります。
今回の実装は、まさにそういった現場で求められている、シンプルで分かりやすく、保守しやすい構造を意識して設計しました。 とくに重要視しているのは、以下のような点です。
| 観点 | 意識したこと |
|---|---|
| 視認性 | クラス構成が一覧で把握でき、役割が一目でわかる |
| 修正性 | 特定の処理は特定のクラスに閉じている |
| 移植性 | 依存が少なく、他プロジェクトに流用しやすい |
| 初期学習コスト | 新人や非Java開発者でも理解できる構成 |
「難しいことを簡単にする」ではなく、「簡単なことを難しくしない」。その姿勢を守り続けることが、結果的に現場のストレスを減らし、バグや属人化を防ぐ最大の武器になります。
その場しのぎのコードではなく、仕組み化された使い捨てクラスとして割り切ること。 それが、この仕組みに込めた意図です。
この共通DBアクセスクラスは、SELECT / INSERT / UPDATE / DELETE をそれぞれ個別のクラスに分離し、処理の責務を明確にしたシンプル構造で構成されています。
SQLをJavaコードに直接埋め込まず、DataBeanとFactoryクラスで動的に操作を切り替える設計のため、業務ロジックとSQL処理の分離、テスト性、再利用性に優れた作りとなっています。
ただし、ソースコードの分量が多いため、全クラスはGitHub上にまとめて保管しています。処理全体の流れやクラス間の関係を確認したい方は、以下のリポジトリをご覧ください。
Java共通DBアクセスクラスの全ソースコードはこちら
👉 GitHub – db-access-core / data ディレクトリ
次の第2回では、本シリーズの中核であるDbAccessControllerクラスについて詳しく解説します。このクラスは、SQLの実行制御やデータアクセスの統一インターフェースとして機能し、ORMに頼らずに直感的なSQL操作を可能にする仕組みです。共通DBアクセスクラスの実践的な構造や、実際の使い方を理解するための基礎として、ぜひご覧ください。
▶︎ORMにはうんざり!第2回:共通DBアクセスクラスでSQLを直感的に操作するJava設計


