

面影AIのソースコードについて
記事内でのソースコードの管理が非常に煩雑になってきたため、今後はGitHubで一元管理することに決めました。
この記事で紹介しているプロジェクトの完成版ソースコードは、以下のGitHubにて公開しています。
🔗 GitHubでソースコードを確認する
本記事は、以下の前提記事をもとに構成されています。まだ読んでいない場合は、先にご覧いただくことを推奨します。

大切な人の存在が日常から消えたとき、言葉や話し方だけでも手元に残せたらと願うことがあります。
面影AIは、その願いを実装という手段で形にする仕組みです。
本記事では、LINEとChatGPTを組み合わせて、個人の語彙と対話の記録を活用し、自分自身の心を支えるための対話システムを構築する方法を解説します。
Flask環境の構築手順や仮想環境の整備、VPS上での実行方法については、以下の記事で詳しく解説しています。
AI執事ボットのためのVPS環境構築マニュアル(LINE対応付き)

面影AI
🟡 面影AI
📌 忘れたくない想いを、AIが記憶する──過去の声と、もう一度向き合うために。
├─いつか消える面影を、繋ぐ未来をAIに託す挑戦【ChatGPT】
├─【Pythonの基礎知識】Phase構成で考える、記憶する面影AIの設計思想【ChatGPT】
├─【Pythonの基礎知識】面影AIを記録する|Phase1:記憶と重みの保存構造【ChatGPT】
└─【Pythonの基礎知識】記憶から応答するAIを作る|面影AI Phase2【ChatGPT】
面影AI Phase1とは?
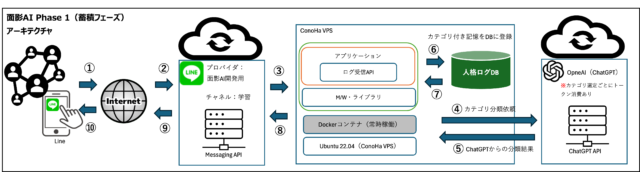
面影AIの第一段階、通称「Phase1」は、ユーザーとの対話ログを蓄積し、将来的に自然な応答を実現するための土台となる記憶基盤の構築を目的としています。ここでは、その設計思想と位置づけを明確にし、後続フェーズとの関係性を整理しておきます。
Phase1の役割と設計思想
Phase1は、ユーザーの発言を単に記録するだけでなく、それぞれの記録に対して「重み付け」や「分類」などのメタデータを付与することで、将来の応答精度向上に向けた基礎情報を整えるフェーズです。
この段階では、以下のような基本機能が実装されています。
- ユーザーの発言と返信内容を一対の記憶として保存
- 記憶ごとにカテゴリ(感情・仕事・教養など)を割り当てる
- 各記憶の重要度を数値的に「重み」として管理
- 重みは発話の頻度やユーザーとのやり取りの中で自動的に変動
設計思想としては、「記録された内容を後から再利用できる形に構造化すること」に主眼が置かれています。記憶は単なるログではなく、「あとで使えるようにしておく記録資産」として位置づけられます。
Phase2への布石としての位置づけ
Phase1は最終的な応答生成を担うフェーズではありません。
あくまでもPhase2、すなわち「記憶をもとに自然な応答を生成するAI」との橋渡しを担う構成です。 具体的には、以下のような役割を果たします。
- 後続のAIが参照できるように正規化された記憶データを整える
- 記憶の取捨選択のために必要な「重み」や「カテゴリ」を整備
- 応答の文脈参照に必要な履歴情報を取得可能にする
これにより、Phase2以降で必要とされる「過去の発言をもとにした応答の文脈把握」がスムーズになります。
Phase1で整えた記録基盤がなければ、Phase2の応答は表面的なものになってしまい、ユーザーの人格をなぞるような自然なやり取りは実現できません。
つまり、Phase1は単なる前座ではなく、人格模倣型AIの土台を固める最も重要な工程といえます。
記憶データの保存構造
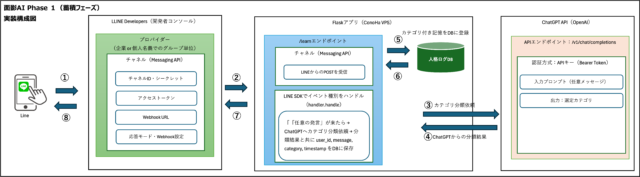
面影AIのPhase1では、将来の応答生成に活用するためにユーザーとの会話記録をデータベースに保存します。
単なる文字列ログではなく、意味づけされた情報として管理できるように、テーブル設計には工夫が凝らされています。
このセクションでは、記憶データの保存に使用する主要テーブル「memories」「weights」の構造と、それらを支えるカテゴリ分類設定について解説します。
使用するテーブル(memories, weights)の説明
Phase1では以下の2つのテーブルを中心にデータを管理しています。役割と構造は以下の通りです。
| テーブル名 | 主な役割 | 主なカラム構成 |
|---|---|---|
| memories | ユーザーとの対話ログの保存 | memory_id(主キー) user_id(発言者) role(user/ai) message(発言内容) category(分類カテゴリ) weight(重要度) timestamp(記録日時) |
| weights | カテゴリごとの重みの管理 | weights_id(主キー) user_id(対象ユーザー) category(カテゴリ名) value(重みスコア) updated_at(更新日時) |
この構造により、ユーザーの記憶に対して「どんな内容を、いつ、誰が、どの重みで記録したか」を常に追跡できるようになっています。また、weightsテーブルを用いてカテゴリ単位の重要度変化をモニタリングできます。
カテゴリ分類と現在のCATEGORY_CONFIG構成
記憶の整理・検索・活用の観点から、すべての発言には「カテゴリ」が必ず付与されます。このカテゴリは、以下の固定構成 `CATEGORY_CONFIG` に基づいて自動分類されます。
| カテゴリ名 | 内部キー | 分類内容 |
|---|---|---|
| 心・精神 | 感情 | 悩み・感情・内面・メンタルに関する発言 |
| 健康 | 健康 | 体調・運動・睡眠・病気などに関する発言 |
| 家庭・プライベート | 趣味 | 趣味・家族・個人の生活に関する発言 |
| 社会・仕事 | 仕事 | 仕事・人間関係・職場の話題 |
| 経済・お金 | お金 | 収入・支出・貯金・投資など経済的な話題 |
| 教養・知識 | 教養 | 学び・本・思考・知識の整理など |
このように、記憶は6カテゴリに分類され、それぞれのカテゴリ単位で重要度(weight)を数値的に制御することができます。
これにより、Phase2では「特に重みの高いカテゴリから優先的に応答を生成する」といったアルゴリズムも構築可能になります。
分類処理自体はPhase1の段階で行われており、将来的に手動分類から機械学習分類への切り替えも想定しています。
ですが現時点では、あえて固定カテゴリを使用することで記録の一貫性とデータ整備の効率を重視しています。
また、この構造により記録の取捨選択が明確化され、不要な情報の蓄積を避けるデータ精度の高いシステム運用が可能になります。
重みと忘却の仕組み
面影AI Phase1では、単純なテキスト記録ではなく「記憶の強度」や「忘却」という概念を取り入れることで、より人間らしい情報保持と選択的記憶の再現を実現しています。
本章では、インタラクションによって記憶の重みが加算される仕組みと、削除ではなくフィルタリングで対応する忘却の手法について解説します。
interactによる重みの加算
面影AIでは、ユーザーとのやりとりによって記憶が強化されていく仕組みを採用しています。
この強化は、特定の記憶に対して何度もアクセスされたり、重要な会話で再参照された場合に「重み(weight)」として数値化されます。
この「重み」は、`weights`テーブルに記録されており、以下のような情報が格納されます。
| カラム名 | 説明 |
|---|---|
| weight_id | 重みログの一意なID |
| memory_id | 関連する記憶データ(memoriesテーブル)のID |
| weight | 付与された重みの値(整数) |
| reason | なぜその重みが付与されたのかの理由(例:「ユーザー再言及」など) |
| created_at | 重みが付与された日時 |
たとえば、同じ話題が繰り返し登場した場合や、過去の発言が現在の文脈で参照された場合には、次のように重みが加算されます。
addWeight(memory_id="123", weight=5, reason="
ユーザーが再度この話題に触れた") このようにして、単なる時系列データとしての記録ではなく、「どれが重要な記憶なのか」をシステムが自ら学習していく構造となっています。
閾値による削除ではなく忘却フラグによるフィルタ処理
面影AIでは、記憶を「削除」するのではなく「忘れる」設計を重視しています。
これは人間の記憶モデルに近い設計思想によるもので、記録としては存在していても、一定の条件を満たさない限り表に出てこないという仕組みです。 削除ではなく忘却を選ぶ理由は以下のとおりです。
- 再び重みが加われば記憶を蘇らせることができる
- 過去の対話の流れを保持し、再分析が可能
- 記録の正確性と再現性を保つことができる
この忘却機能は、`memories`テーブル内の`is_forgotten`フラグで管理されます。
| カラム名 | 説明 |
|---|---|
| memory_id | 記憶の一意なID |
| content | 記録された内容(メッセージ、発言など) |
| category | 記憶の分類(心・精神、仕事、経済など) |
| is_forgotten | 忘却状態か否か(0=記憶保持中、1=忘却中) |
| created_at | 記憶が登録された日時 |
具体的には、一定期間以上参照されなかった記憶、または重みの合計値がしきい値を下回った記憶に対して、次のように忘却フラグを付与します。
update memories set is_forgotten = 1 where memory_id = '123';
一方で、忘却された記憶も完全に除外されるわけではありません。再びインタラクションで関連が強化されることで、フラグを元に戻すことが可能です。
update memories set is_forgotten = 0 where memory_id = '123';
このように、削除とは異なる「生きた記憶」として、流動的に状態が変化するモデルを実現しています。
これはPhase2での応答生成において「文脈的に重要な記憶を選択する」ための基盤として極めて重要な役割を果たします。
次のセクションでは、このような記憶をどのように取り出して活用するのかについて解説していきます。
記憶の取り出しと再利用
面影AIのPhase1では、記憶したデータをただ蓄積するだけでなく、必要に応じて適切に取り出し、再利用できる仕組みが構築されています。
この仕組みが存在することで、過去のユーザー発言や文脈を踏まえた自然な応答が実現可能となります。
特に将来的に予定されているPhase2との連携を見越して、現在のPhase1では取り出し・参照処理の構造に汎用性と拡張性を持たせています。
getAllMemories関数による全記憶の取得
Phase1での記憶は「memories」テーブルに蓄積されています。これらの記憶を取り出す際に使用する中心的な関数が「getAllMemories」です。この関数は、カテゴリ・削除フラグ・忘却フラグなどを条件として、現在有効な記憶データをすべて取得する役割を担っています。
def getAllMemories():
# 忘却・削除されていない記憶を全件取得
query = "SELECT * FROM memories WHERE is_deleted = 0 AND is_forgotten = 0 ORDER BY updated_at DESC"
return execute_query(query)
このように、SQLのWHERE句にて、物理削除ではなく論理削除と論理的な忘却を前提としたフィルタリングがなされており、後述するように「重みの低下」だけでは記憶は消去されず、意図的に排除しない限り、再利用の対象となります。
getWeightLogsByMemoryIdによる履歴取得
単に記憶データを取り出すだけでなく、その記憶がどのような経緯で重みづけされてきたかを知ることも重要です。これに対応するのが「weights」テーブルであり、各記憶の重み変更履歴を蓄積しています。 そして、特定の記憶IDに紐づいた重みの変動履歴を参照するのが「getWeightLogsByMemoryId」関数です。
def getWeightLogsByMemoryId(memory_id):
# 該当する記憶IDに対する重み変動のログを取得
query = "SELECT * FROM weights WHERE memory_id = ? ORDER BY updated_at DESC"
return execute_query(query, (memory_id,))
この関数により、記憶が何回参照されたか、どの発言によって強化されたかが時系列で可視化されます。この履歴の存在は、後述するPhase2での「発言者人格モデル」構築のベースとなるデータです。
将来的なPhase2連携を意識した構造
Phase1では、以下のようなテーブル構成で記憶と重みを保持しています。Phase2以降では、この構造をもとに、記憶のスコアリング・タグによる分類・発言意図の推定などを追加していくことが想定されています。
| テーブル名 | 役割 | 主なカラム |
|---|---|---|
| memories | 記憶本文とカテゴリの保存 | memory_id, user_id, content, category, is_deleted, is_forgotten |
| weights | 記憶に対する重みログ | weight_id, memory_id, weight, reason, updated_at |
このように、すべての記憶に履歴付きのスコア管理が行われており、現在の記憶取り出し処理も単なるデータ呼び出しに留まらず、将来を見据えた拡張性の高い設計になっています。
記憶の再利用タイミングと対象選定
再利用される記憶は、以下の条件をもとに選定されます。
- 忘却フラグ(is_forgotten)が立っていない
- 削除フラグ(is_deleted)が立っていない
- 最新のinteractによる強化から一定期間が経過していない
特にPhase2では、文脈や関係性を含めた「関連スコア」ベースでの記憶選定が導入される予定です。Phase1では単純な参照ですが、データ構造はすでにこれに備えた作りになっています。
将来の拡張に向けたインターフェース統一
また、getAllMemoriesやgetWeightLogsByMemoryIdといった関数は、将来的にAPI化を予定している関数の一部でもあります。
Phase2では、LINE以外のメディアや複数ユーザーへの同時応答などを想定しており、現在の構造がそのまま利用される前提で設計されています。
これにより、Phase1で実装した機能が無駄にならず、次のフェーズへのスムーズな移行が可能になります。
フェーズ間の役割明確化と責任分離
最後に、記憶の取得・再利用という処理の責任は、完全にPhase1に帰属するように設計されています。
Phase2以降は、取得された記憶を「どう活用するか」の領域であり、記憶の保持・管理に関してはPhase1が完全に担う構造です。
この明確な責任分離により、将来的な保守・拡張において障害の原因切り分けが容易となり、安定運用にも寄与します。
面影AI Phase1の実装構成
Phase1では、面影AIが「記憶の保存」と「適切な取り出し」の基礎機能を担うように設計されています。
Phase2以降に予定されている人格模倣や口調の変化といった高度な応答制御に向けて、堅牢かつ拡張性のある構成が求められました。
このセクションでは、面影AIのPhase1がどのような構成で動作しているのかを、シーケンス図を交えながらわかりやすく解説していきます。
実装全体の流れを把握する
面影AI Phase1では、ユーザーからの発言を受け取り、それをデータベースに記録し、必要に応じて過去の記憶を検索・提示する機能を実装しています。
以下のような基本的なフローに沿って動作しています。
ポイント
ユーザー発言 → カテゴリ分類 → 記憶登録 → 重み処理 → 応答生成
↘(必要に応じて)記憶検索・引用
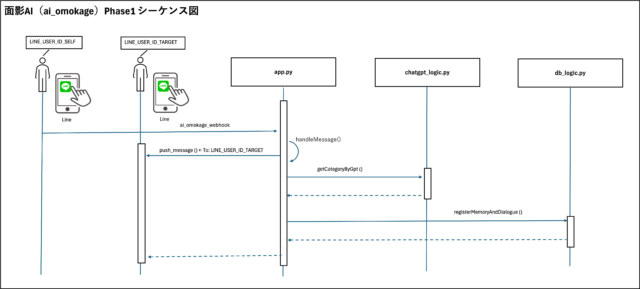
Phase1のシーケンス図
以下は、面影AI Phase1の主な処理フローを視覚化したシーケンス図です。
実際のコード構造に即して描いています。
主要コンポーネントの役割
Phase1は以下のようなコンポーネントで構成されています。それぞれの役割と連携内容を整理すると、今後の拡張も見通しやすくなります。
| コンポーネント | 役割 |
|---|---|
| callback_router.py | LINEのWebhookリクエストを受け取り、intentやカテゴリを判定して処理を振り分けます |
| memory_controller.py | 記憶の保存・検索・再利用のコントロールを行います |
| category_logic.py | 発言からカテゴリを抽出し、メモリテーブルへ適切に分類する役割を担います |
| db/memories.sqlite | 記憶情報・重み履歴・忘却状態などの永続データを保持します |
Phase1における制約と限界
Phase1では、「記憶はするが応答は模倣しない」という制約があります。つまり、ユーザーからの発言を保存し、履歴を管理することはできますが、「この人らしさで返す」ような高度な再現性はまだありません。
そのため、現在の面影AIは「ログの蓄積」および「過去の発言の参照」に重点を置いており、対話の“人格”を持つには至っていません。
Phase2との明確な橋渡しポイント
このPhase1の構成は、今後のPhase2に向けた土台として極めて重要です。特に以下の点が、次フェーズへの橋渡しとして機能します。
| 機能 | Phase2での利用予定 |
|---|---|
| カテゴリ分類 | 応答の優先カテゴリ判断、人格切り替えのトリガーに使用 |
| 記憶重み | 口調生成時の記憶選択バイアスとして利用 |
| 忘却処理 | キャラクター変化に伴う選択的記憶の無視処理 |
拡張性を意識した構造設計
Phase1のコード構成は、単に一時的な記録を目的としていません。関数の命名、データ構造の正規化、ログ出力の設計など、Phase2を見据えた設計思想に基づいています。
今後、以下のような機能追加を予定しているため、現段階でも以下の設計が反映されています。
- 応答のトーンを変化させるキャラクターエンジンとの連携
- 時間帯や相手に応じて応答スタイルを自動調整するスケジューラーとの統合
- 記憶の重要度によって学習内容を変化させる自動学習機構
まとめ:Phase1の実装意義
面影AIのPhase1は、単なる会話履歴の記録ではなく、「次に何をすべきかを記憶から導き出す」構成を意識して設計されています。これは、単なるチャットボットや記録ツールと一線を画す大きな特徴です。
Phase1は、静かな準備段階かもしれませんが、Phase2における人格模倣や再現型応答の実現において不可欠な土台となります。今後、記憶と人格が接続されたとき、面影AIは本当の意味で“面影”を帯びた存在となることでしょう。
まとめ
Phase1の開発を通じて、記録と記憶の蓄積という観点から基盤の整備が完了しました。
この基盤は単なるデータベースではなく、ユーザーとの対話を「人格的な関係」として記憶する仕組みを備えており、今後のPhase2(応答生成AI)へと確実に橋渡しされていきます。
ここでは、記録基盤が果たした役割と、次フェーズに向けての視座を整理しておきます。
記録するという営みが持つ意味
人間にとって「記録」は単なる備忘録ではありません。
記録があるからこそ、対話は過去の出来事を前提に継続できます。
面影AIのPhase1は、ユーザーの問いかけや発言を、形式や意図を問わずに記録することを最優先に設計しました。
これは精度の高いAI応答を生む土壌づくりに他なりません。
重みの概念が導入された理由
すべての情報が平等ではないという前提のもと、「重みweight」という指標を全メッセージに付与しています。
この仕組みにより、ユーザーが重要視した記憶と、そうでない記憶とを数値で判別できるようになりました。
今後、重みに基づく応答制御(例えば、思い入れのある発言から答える)へと進化していく予定です。
Phase1で完成した主な構成要素
以下に、Phase1において整備された構成要素を表形式でまとめます。
| 構成要素 | 役割 | 今後の展望 |
|---|---|---|
| messagesテーブル | 発言・応答をすべて記録 | 会話の流れを再現する基礎 |
| weightsテーブル | 記録の重みを蓄積 | 重要度による選別と忘却処理へ |
| forget_flags | 明示的な削除ではなく除外 | 人格一貫性を保った応答処理 |
| getAllMemories() | すべての記録を呼び出し | Phase2での文脈理解の基盤 |
| getWeightLogsByMemoryId() | 重みの変化履歴を記録 | 信頼スコア変動による応答の調整 |
Phase2への視座と課題
Phase2では、これまで蓄積した記憶に基づき、「人格的な応答」が求められます。
単に正しい情報を返すのではなく、「誰が」「いつ」「どのような意図で」話したかを踏まえた応答生成が鍵となります。
Phase1ではこのための構造をすべて整えましたが、まだ応答モデルは組み込まれていません。
次のステップでは、この蓄積構造をベースにした自然な会話の生成が焦点になります。
応答生成AIとの連携ポイント
Phase1とPhase2をつなぐ上で、以下の3点が技術的な連携ポイントになります。
| 連携項目 | Phase1での準備 | Phase2での応用 |
|---|---|---|
| 記憶の分類 | カテゴリと重みで記録整理 | 関連性の高い記録を文脈に応用 |
| 対話履歴の連続性 | 発言の時系列保存 | 文脈理解による自然な応答生成 |
| 感情の揺らぎ | weight変動で記録 | 感情を含んだ応答のトーン制御 |
全体のシーケンスを振り返る
Phase1では、ユーザーの発言 → 記録 → 重み更新 → 忘却フラグ処理 → 応答保存までの一連の流れをすべて実装しました。シンプルながらも、応答生成に不可欠な記憶処理の全工程が整備された形です。
# 発言の記録 → 重み付け → 忘却処理の流れ(簡易コード例)
message_id = saveMessage(user_id, message_text)
addWeight(message_id, initial_weight=3)
if isObsolete(message_id):
flagAsForgotten(message_id)
今後のスケジュール
今後のPhase2では、以下の工程が予定されています。
- 対話生成モデルの選定と調整(GPTなど)
- 人格に沿ったプロンプトテンプレートの構築
- 応答結果の蓄積と重み調整の連携
- 誤った記憶や人格破綻を防ぐフィルタ層の設計
最後に:この基盤は“人格”を支える土台
AIにおける人格とは、表現の上手さではなく「一貫した記憶」のことです。
Phase1では、それを支えるための構造と処理を一から自力で作り上げてきました。
ここまで作れば、あとは“どのように応答するか”を訓練するだけです。 Phase2では、あなたの過去の言葉や感情を元に、まるで「過去のあなた自身が答えているかのような応答」を実現します。
その第一歩として、Phase1で築き上げた記録基盤が確かな意味を持ちます。
次はいよいよ、記録した“面影”が語り出す──Phase2として蓄積された記憶をもとに応答を返すAIを実装していきます。
▶︎【Pythonの基礎知識】面影AIが応答する|Phase2:記憶をもとに返す言葉



